










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
El uso de ontologías es cada vez más requerido por aquellos sistemas computacionales que necesitan procesar la semántica asociada al contenido. Este es el caso de los Sistemas de Recuperación de Información Geográfica (SRIG), aplicaciones que requieren representar y describir semánticamente datos espaciales de zonas geográficas del mundo real (ciudades, países, etc.). En este escenario se hace imprescindible utilizar ontologías de gran tamaño que ofrezcan la posibilidad de describir el significado de los datos espaciales y sus relaciones, faciliten la generación de nuevo conocimiento espacial y permitan mejorar la toma de decisiones (Ulutaş Karakol et al., 2018). El uso efectivo de las ontologías no solo requiere de la codificación del conocimiento representado en un lenguaje formal, sino también de un soporte computacional adecuado para su administración y la realización de procesos de inferencia sobre el conocimiento formalmente representado. En este sentido han surgido los sistemas DBBO (Databases Based on Ontologies) y los sistemas OBDB (Ontology Based Data Bases), muy parecidos entre sí, pero con sus diferencias en cuanto a las características de la fuente de datos que administran: bases de datos relacionales para los DBBO y ontologías para los OBDB.
Los sistemas DBBO también conocidos como OBDA (Ontology-Based Data Access), se han convertido en un popular paradigma para acceder a una o varias fuentes de datos mediante el uso de ontologías (Nikolaou et al., 2019), aprovechando las ontologías para incrementar su capacidad semántica de administrar información. . En los sistemas DBBO los usuarios acceden a los datos a través de una capa conceptual (abstracción de los aspectos específicos relacionados con las fuentes de datos) que proporciona un cómodo vocabulario de consulta. Esta capa se representa generalmente mediante una ontología en RDF u OWL y se conecta a las bases de datos relacionales subyacentes utilizando asignaciones R2RML . Cuando se realiza una consulta SPARQL sobre la ontología, el sistema DBBO explora las asignaciones representadas para recuperar elementos de las fuentes de datos y construir las respuestas (Calvanese et al., 2016). Una de las limitaciones que presentan actualmente los sistemas DBBO tiene que ver con la imposibilidad de hacer cambios en la BDR a través de la ontología debido, generalmente, a la existencia de asignaciones complejas y arbitrarias entre la ontología y la BDR. Este problema se conoce como el “view update problema” (Franconi y Guagliardo, 2012) y se produce porque, debido a las asignaciones, no existe una manera única de propagar una actualización específica del nivel de la ontología a la base de datos subyacente. Otra limitación de los sistemas DBBO es que no están diseñados para soportar ontologías en cualquier perfil OWL2, debido a que su función principal es acceder a grandes BDR. Por este motivo utilizan lenguajes que proporcionan un menor poder de expresividad, como es el caso de OWL2-QL. Algunos ejemplos de sistemas DBBO son GraphDB (Güting, 1994), OntoDB (Dehainsala, Pierra y Bellatreche, 2007), Optique (Calvanese et al., 2013), RDFox (Nenov et al., 2015), Ontop (Calvanese, Rezk y Xiao, 2016), OptiqueVQS (Soylu et al., 2018), Squerall (Mami M.N et al., 2019).
Por otra parte, los sistemas OBDB, permiten almacenar y consultar ontologías con una gran cantidad de instancias. Una ventaja de estos sistemas tiene que ver con su capacidad para utilizar algunas de las funcionalidades que proporcionan los Sistemas de Gestión de Bases de Datos Relacionales (RDBMS, siglas en inglés), tales como rendimiento en las consultas, almacenamiento eficiente de los datos, administración de transacciones, entre otras. Ejemplos de estos sistemas son: Database-Based Sesame (Lantica Software LLC., 2017), DLDB-OWL (Pan y Heflin, 2003), OWLIM (Kiryakov, Ognyanov y Manov, 2005), InstanceStore (Horrocks et al., 2004), Minerva (Zhou et al., 2006a), DBOWL (García y Montes, 2012), OntoMinD (Al-Jadir, Parent y Spaccapietra, 2010), OwlOntDB (Faruqui y MacCaull, 2013) y FGOLD (Bakhtouchi, 2015).
Son varios los autores que reconocen la existencia de limitaciones a la hora de combinar administración de grandes volúmenes de información y poder especificar determinadas características de los datos, como ocurre en el caso del dominio geográfico (Faruqui y MacCaull, 2013), (Gu y Zhang, 2015), (Maria Keet, 2018), (Eine, Jurisch y Quint, 2017), (Koutsomitropoulos y Kalou, 2017). Una posible solución al problema planteado anteriormente pasa por utilizar lenguajes ontológicos con un mayor poder de expresividad (por ejemplo OWL, Ontology Web Language), la cual es requerida en este dominio para poder inferir de forma automática un mayor número de relaciones espaciales (Faruqui y MacCaull, 2013), (Jerry R. Hobbs y Feng Pan, 2017).
Una limitación relacionada con la gestión de grandes volúmenes de información está relacionada con los propios editores de ontologías. La mayor parte de los editores disponibles actualmente (Protégé es de los más utilizados, así como los razonadores Pellet, FaCT++, HermiT, TrOWL, RACER, entre otros), requieren cargar previamente toda la ontología en memoria principal para poder llevar a cabo tareas de administración y ejecutar mecanismos de inferencia, no permitiendo su gestión en memoria externa cuando la capacidad en memoria principal es limitada (Dentler et al., 2011), (Alatrish, 2013). Este aspecto constituye un problema cuando se gestionan ontologías geográficas con millones de datos (instancias) y se tienen recursos hardware limitados debido a la elevada complejidad espacial y temporal de los algoritmos utilizados por los razonadores basados en memoria principal (Faruqui y MacCaull, 2013). En este sentido OWLAPI es una API (Application Programming Interface) de alto nivel muy utilizada para trabajar con ontologías codificadas en OWL que ofrece mecanismos para la manipulación de estructuras ontológicas y el uso de motores de razonamiento. Según varios autores (Horridge y Bechhofer, 2011) (Bechhofer y Matentzoglu, 2018), su mayor limitante está en la necesidad de cargar el fichero OWL en memoria principal, siendo esto una inconveniente importante cuando el tamaño de la ontología es similar al de la memoria principal disponible en el computador.
Por otro lado existe un compromiso entre la expresividad lógica de una ontología y la complejidad computacional: cuanto más expresivo es el lenguaje de la ontología, mayor es su complejidad computacional (Dentler et al., 2011), (Zhou et al., 2006b). Como consecuencia, la mayoría de herramientas ontológicas capaces de trabajar con memoria externa y grandes volúmenes de datos optan por disminuir la expresividad del lenguaje para garantizar tiempos computacionales aceptables.
Teniendo en cuenta este escenario, el diseño de un modelo de representación basado en la integración de ontologías y Bases de Datos Relacionales (BDR) está resultando ser una alternativa prometedora (Aguiar, Falbo y Souza, 2018), (Jean et al., 2012) ya que, por un lado, la ontología podría describir la semántica asociada al modelo de datos utilizado en una BDR y, por otro lado, una BDR podría ser utilizada para almacenar parte del conocimiento que normalmente se representa en la ontología como, por ejemplo, las instancias.
En este trabajo se desarrolló un modelo de representación de conocimiento en el dominio geográfico y se propone un mecanismo de administración y razonamiento aplicable a dicho modelo. La propuesta se basa en los principios de un sistema OBDB y se dirige fundamentalmente a la gestión de ontologías geográficas de gran tamaño, ya que soluciones actuales como OWLAPI no ofrecen soporte cuando todo el conocimiento de la ontología no se puede almacenar en memoria principal debido a limitaciones hardware. Las principales contribuciones del enfoque propuesto son:
Utilización de un esquema de representación de conocimiento compartido entre la ontología y una BDR, incluyendo mecanismos de administración y razonamiento necesarios para este tipo de esquema. Como novedad este esquema permite hacer cambios en la BDR a través de la ontología, aspecto que no contemplan los sistemas DBBO actuales debido a que estos solo permiten realizar operaciones de consulta sobre la BDR.
Disminución del uso de memoria principal al permitir cargar solo una parte de la ontología y no todo el fichero OWL, consiguiendo así facilitar la administración y el razonamiento sobre ontologías de gran tamaño en el dominio geográfico cuando los recursos hardware son limitados.
Soporte de ontologías escritas en cualquier perfil OWL2. Esta es otra limitación de los sistemas DBBO actuales debido a que su objetivo principal es el acceso a grandes BDR, optando por utilizar lenguajes con menor poder de expresividad que OWL2.
MÉTODOS O METODOLOGÍA COMPUTACIONAL
La solución propuesta pretende extender OWLAPI en dos dimensiones fundamentales para trabajar con ontologías de gran tamaño: por un lado, la administración de la ontología y por otro el razonamiento o inferencia, incrementando así las potencialidades de dicha herramienta. Esta solución se basa en los principios de un sistema OBDB donde la estructuración y almacenamiento de la conceptualización a formalizar en la ontología y los datos son compartidos entre el fichero OWL y una BDR. En la Figura 1 se ilustra de forma gráfica la asignación de responsabilidades entre OWL API y la BDR en el momento de gestionar los componentes de la ontología.
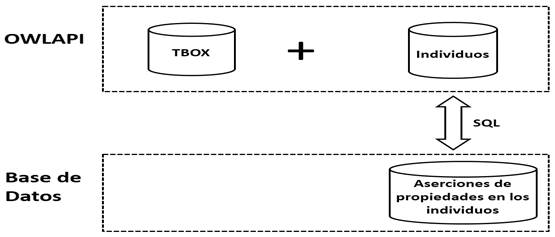
Administración de la ontología
En la solución propuesta se decidió extraer del fichero OWL gestionado por OWL API algunos datos pertenecientes al ABOX (Assertion box, data) y mantener íntegramente el TBOX (Terminological box, schema) de la ontología, de forma similar a los sistemas OBDB analizados. Esto se hizo con el objetivo de poder utilizar los razonadores en memoria interna en algunas tareas específicas y así mantener la capacidad de razonamiento sobre la ontología. Los razonadores existentes están diseñados para realizar procesos de inferencia solo sobre lo incluido en el fichero OWL de la ontología, fundamentalmente sobre el TBOX. Los datos pertenecientes al ABOX que se decidieron almacenar en la BDR fueron principalmente dos: las relaciones de objeto expresadas entre pares de individuos (Object Property Assertion Axioms) y la asignación de valores a las propiedades de datos (Data Property Assertion Axioms).
Inicialmente, debido a la simplicidad estructural de la información a almacenar, se decidió utilizar simples ficheros como medio de almacenamiento en memoria externa. Sin embargo, al hacer varias pruebas los autores se percataron de que el tiempo de acceso a la información era demasiado elevado y la frecuencia con la que se debía acceder a los mismos también, sobre todo si consideramos que el tamaño del fichero sobrepasó los 15 GB para la región de Marianao. Por tal motivo, se optó por utilizar una base de datos relacional.
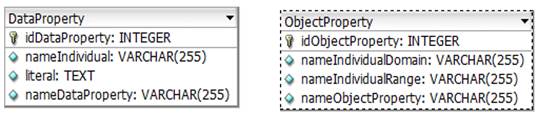
Entre utilizar un modelo de Base de Datos Relacional (BDR) y No Relacional (BDNR) se decidió por el primero porque las BDNR no son adecuadas cuando existen relaciones entre los datos. En esta investigación, aunque los individuos no se almacenaron en la BDR, sí se plantea esta opción como mejora en el futuro, por lo que se decidió apostar desde un principio por utilizar una BDR. Dejar los individuos en el fichero OWL tiene la ventaja de reutilizar toda la eficiencia de OWLAPI en relación a los individuos y sus clases, almacenarlos en la BDR implicaba el esfuerzo de implementar toda esa lógica desde cero. El modelo físico de la BDR utilizada en la solución propuesta se ilustra en la Figura 2.
Para la tabla “DataProperty”, los tres últimos campos conforman una restricción de campo único, es decir, no pueden existir dos tuplas con los mismos valores en estos campos. Lo mismo sucede con los tres últimos campos de la tabla “ObjectProperty”. La comunicación entre el fichero OWL y la información que se almacena en la base de datos se realiza a través de consultas SQL. Por ejemplo, si se necesita conocer todos los literales de un individuo para una propiedad de datos en particular, se ejecuta una consulta de selección que dado el nombre del individuo y el nombre de la propiedad de datos seleccione todos los literales.
En la solución desarrollada se implementaron los mecanismos necesarios para que las instancias de propiedades pudieran ser integradas nuevamente en el fichero OWL en su forma tradicional, siempre y cuando la memoria interna del hardware utilizado soportara dicho crecimiento.
Razonamiento sobre la ontología owl2 usando OWLAPI
Una vez cargada la ontología en OWLAPI fue necesario desarrollar algunas operaciones que exigían el uso de razonadores en la manera tradicional, lo cual continuaba siendo una limitación a pesar de las modificaciones realizadas. En este sentido se implementaron diferentes operaciones necesarias sin utilizar razonadores y apoyándose únicamente en recursos facilitados por OWLAPI. Estas operaciones, a diferencia de las desarrolladas por un razonador profesional sobre una ontología estándar, no validan la totalidad de las situaciones presentes en el expresivo lenguaje OWL2, pero permitieron dar soporte a las necesidades que planteaba la gestión de una ontología en el dominio geográfico. El total de operaciones implementadas sin utilizar razonadores se enumeran a continuación:
Buscar las subclases directas e indirectas de una clase.
Identificar los individuos directos e indirectos de una clase, teniendo en consideración la equivalencia entre clases y entre individuos.
Identificar las “clases topes”, es decir, las clases que no son subclases de ninguna clase.
Identificar todas las clases equivalentes a una clase, considerando que la relación de equivalencia es transitiva.
Identificar el conjunto de superclases de una clase.
Obtener el conjunto de individuos que están relacionados con otro a través de una propiedad de objeto, teniendo en consideración las características de la propiedad de objeto expresada en OWL2: simetría, reflexividad, funcional, transitividad, inversa, equivalencia.
Obtener el conjunto de literales asociados a una propiedad de datos para un individuo en particular.
Similitud entre individuos pertenecientes al dominio geográfico.

En las Tabla 1 y Tabla 2 se muestra el algoritmo definido para inferir las subclases directas o indirectas de una clase. La Tabla 2 muestra un procedimiento auxiliar que apoya al mostrado en la Tabla 1.
La solución propuesta soporta cualquier perfil OWL2 y permite la gestión de datos geográficos, modelándolos en la ontología como una cadena de texto en el formato WKT . La gestión de la ontología se hace mayormente a través de OWL API, mientras que solo las aserciones de propiedades son administradas desde la BDR.

RESULTADOS Y DISCUSIÓN
Para demostrar la viabilidad de la solución propuesta se administraron dos ontologías geográficas de gran tamaño (OntoMarianao y OntoAcapulco) , que fueron previamente generadas utilizando el método reportado en (Puebla-Martínez et al., 2018). Con un hardware estándar en cuanto a capacidad de cómputo y memoria, estas ontologías no podrían haberse gestionado con herramientas actuales como OWL API, Protégé, JENA o HERMIT, entre otras, debido al tamaño de las ontologías y al elevado uso de memoria principal pro parte de las herramientas antes mencionadas. Sin embargo, la solución propuesta en esta investigación permitió reducir el consumo de memoria principal y garantizó las operaciones de razonamiento básicas en una ontología del dominio geográfico. Los experimentos llevados a cabo se realizaron sobre un hardware con una CPU Mobile DualCore Intel Core i5-2430M, 2800 MHz (28 x 100) y 4 GB de memoria principal.
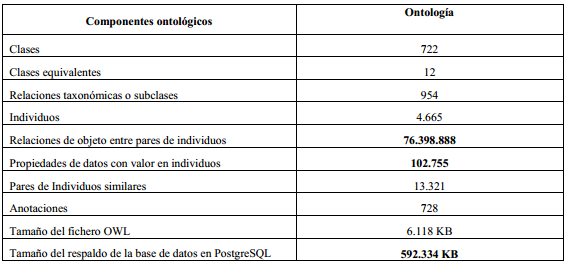
En la Tabla 3 se muestran las características de la ontología OntoMarianao, que está relacionada con la zona geográfica correspondiente al municipio de Marianao (Cuba). Los datos de OntoAcapulco no se exponen por cuestiones de espacio, pero se han puesto a disposición de la comunidad científica los ficheros OWL (sin las aserciones de propiedades) y la base de datos con las aserciones de propiedades de ambas ontologías geográficas, para que los investigadores interesados pueden disponer de ellas.
Los datos mostrados en la Tabla 3 evidencian la viabilidad de la propuesta, pues una ontología con esas características no podría haber sido administrada por OWL API (o herramientas similares) en una computadora con un hardware estándar como el utilizado en la experimentación llevada a cabo. Los dos primeros datos que aparecen en negritas en la tabla 3 (fila 5 y 6) son almacenados en la base de datos. Noten el tamaño del respaldo de la base de datos (última fila), a pesar de todas las técnicas de compactación de la información que utilizan los gestores de bases de datos tradicionales. Ese volumen de información para una ontología no es posible administrarlo con las herramientas tradicionales.
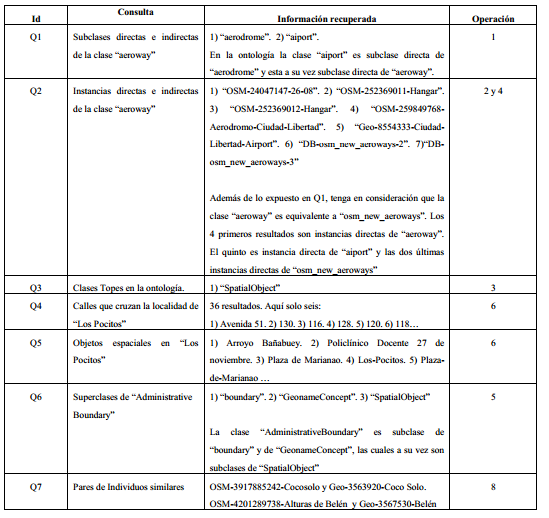
Por otro lado, aunque no es el principal objetivo de este trabajo, la Tabla 4 muestra los resultados obtenidos para la ontología de Marianao en algunas de las funcionalidades de inferencia desarrolladas. La columna “Operación” hace referencia al número de la operación de razonamiento mostrada en la Sección 3. La información recuperada para cada consulta realizada demuestra también la viabilidad de las operaciones de razonamiento desarrolladas a pesar del tamaño de la ontología y el alto nivel de expresividad utilizado.
Es válido resaltar que, sin la solución de segmentación que se propone en este artículo, no hubiera sido posible obtener las dos ontologías de experimentación que aquí se abordan: OntoMarianao y OntoAcapulco. De las siete operaciones mostradas en la tabla 4, cuatro de ellas se pueden implementar usando solo OWLAPI (Q1, Q2, Q3 y Q6) y en tres se necesita utilizar el enfoque de segmentación propuesto (Q4, Q5 y Q7). No obstante, es válido una aclaración, normalmente para implementar las operaciones Q1, Q2, Q3 y Q6, se utilizan razonadores que infieren información a partir de lo expresado en la ontología. Pero en este caso no es posible debido al gran tamaño de la ontología, por lo que fue necesario implementar funcionalidades similares a las que desarrollan los propios razonadores, ya explicadas en la sección III.
CONCLUSIONES
En este trabajo se desarrolló una extensión de OWLAPI que permite administrar ontologías de gran tamaño utilizando un hardware con recursos estándar. La solución propuesta soporta el lenguaje ontológico OWL2, con lo que se eleva el nivel de expresividad que se puede utilizar al desarrollar operaciones de inferencia sobre la ontología. Este aspecto es fundamental cuando se administran ontologías del dominio geográfico, pues permite incluir algunas capacidades de razonamiento sobre el ABOX de la ontología que son difíciles desarrollar con otros lenguajes menos expresivos. Además de la extensión de OWL API se desarrollaron varias operaciones de razonamiento básicas en una ontología del dominio geográfico sin utilizar otros razonadores existentes.
Para demostrar la viabilidad de la solución propuesta se administraron dos geo-ontologías de gran tamaño correspondientes a diferentes áreas geográficas. Las características de las ontologías administradas en cuanto a clases, instancias, relaciones ontológicas o tamaño en memoria confirmaron el éxito de la solución propuesta. Además de reducir el consumo de memoria principal, se garantizó el funcionamiento de las operaciones de razonamiento básicas desarrolladas, siempre bajo el marco de experimentación utilizado. Por último, se comprobó que las ontologías utilizadas en la experimentación no podrían haberse administrado con herramientas actuales como OWL API utilizando el mismo marco de trabajo, debido al elevado uso de memoria principal que requieren.
El resultado obtenido puede ser aplicado a grandes ontologías de otros dominios de información, lo que aumentaría las posibilidades de aplicación y el impacto de la investigación.
Como trabajo futuro se propone aumentar las capacidades de razonamiento desarrolladas, así como almacenar los individuos de la ontología en la base de datos relacional para disminuir aún más los requisitos de memoria principal.

