










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
El volumen de datos que se genera diariamente ha crecido de manera drástica hasta alcanzar cotas superiores a los 2.5 billones de bytes diarios (Taluja, 2020). De igual forma el impacto de los datos en la sociedad y la economía es cada vez más significativo. La necesidad de procesar los datos para convertirlos en ventajas competitivas es un factor clave para el éxito de las organizaciones.
La minería de datos forma parte de las tecnologías utilizadas para analizar los datos y convertirlos en información útil que pueda ser transformada en acciones concretas que permitan potenciar el éxito. Dentro de la minería de datos una de las tareas más estudiadas y aplicadas es la minería de Reglas de Asociación (RA) quizás debido a que son muy similares a como los seres humanos representan el conocimiento.
El minado de reglas de asociación se define sobre una base de datos D que almacena las transacciones relevantes para un dominio particular. El dominio es representado a partir de un conjunto de elementos 𝐼. De modo que toda transacción 𝑡∈𝐷 satisface que 𝑡⊆𝐼. Una RA es una implicación de la forma 𝑋→𝑌 donde 𝑋 se denomina antecedente mientras que 𝑌 es el consecuente de la regla. Al mismo tiempo satisfacen las siguientes condiciones 𝑋∪𝑌⊆𝐼 y comúnmente pero no necesariamente, 𝑋∩𝑌=∅.
Las RA pueden interpretarse como reglas de la forma 𝑠𝑖 𝑋 𝑒𝑛𝑡𝑜𝑛𝑐𝑒𝑠 𝑌 con la semántica asociada de que la aparición de 𝑋 en una transacción de 𝐷 implica la aparición de 𝑌 en la misma transacción. El problema del minado de RA consiste en encontrar todas las reglas 𝑋→𝑌 que están presentes en las transacciones de 𝐷. De manera formal se expresa como 𝑋→𝑌 ∃𝑡, 𝑡∈𝐷∧𝑋∪𝑌⊆𝑡}. Para 𝑚=|𝐼| la cantidad de subconjuntos de 𝐼 que pueden aparecer en las transacciones sería 2 𝑚 −1 y para cada subconjunto de 𝐼 con cardinalidad 𝑛 la cantidad de reglas de asociación que pueden ser generadas es 2 𝑛 −2.
Las condiciones previas establecen dos grandes dificultades para el minado y utilización de RA.
La primera está dada por la complejidad exponencial lo que hace necesario la utilización de heurísticas para lograr algoritmos eficientes que permitan podar el espacio de búsqueda. En este sentido se ha establecido que las reglas interesantes deben ocurrir en la base de datos con una frecuencia mínima definida por el usuario. Esta frecuencia recibe el nombre de soporte y es la base de la heurística Apriori la cual utiliza la propiedad de clausura descendente del soporte (si un conjunto de ítems no satisface la frecuencia mínima cualquier super conjunto del mismo tampoco satisface esta condición) para podar el espacio de búsqueda. El desarrollo de algoritmos eficientes para el minado de RA es un campo activo en el que aún se desarrollan muchas investigaciones y que tiene margen de mejora. Sin embargo, se han alcanzado resultados que permiten el minado de reglas en aplicaciones prácticas.
La segunda gran dificultad para la utilización de las RA radica en la alta cardinalidad de los modelos minados, que resulta inmanejable para los usuarios. Utilizar la frecuencia de ocurrencia de los patrones para disminuir la cantidad de reglas no es práctico debido a que las reglas que tienen frecuencias de aparición cercanas al 100% son usualmente conocidas por los especialistas o triviales y por tanto no tienen valor real.
Lo común es que las reglas realmente interesantes aparezcan con frecuencias mucho menores. En muchos casos se definen valores inferiores al 10% como umbral de frecuencia a la hora de considerar válida una regla. De esta forma los modelos contienen demasiadas reglas para poder ser tratadas por los especialistas, a este problema en la literatura científica (Bastide, 2000), (Balcazar, 2010) se le conoce como el problema de exposición de las reglas y es reconocido como el principal obstáculo para la utilización en la práctica para los modelos de reglas de asociación (Tirnauca, 2020).
En este trabajo se propone una revisión sistemática de la literatura de las técnicas utilizadas para reducir el tamaño de los modelos de Reglas de Asociación. La intención es identificar el estado del arte en esta temática y explorar sus potencialidades con vistas a facilitar la utilización práctica de las RA.
El resto del artículo se estructura de la siguiente forma: en la siguiente sección se discute la metodología seguida para la investigación. La sección 3 aborda los resultados y la discusión de los mismos. Finalmente se presentan las conclusiones en la sección 4.
DESARROLLO
La revisión sistemática de la literatura sigue un protocolo preciso con vistas a obtener resultados contrastados desde el punto de vista científico. En este trabajo se utilizó la propuesta metodológica de (Keele, 2007) que define un proceso para identificar, analizar e interpretar los estudios relevantes disponibles en un área de conocimiento específica. El mismo cuenta con tres fases fundamentales:
Fase 1: Planificación de la revisión: en la que se define el protocolo que es utilizado para conducir la revisión.
Fase 2: Conducción de la revisión: en este momento se identifican y seleccionan los estudios relevantes, se evalúa la calidad de los estudios encontrados y se sintetiza la información.
Fase 3: Reporte de la revisión: En esta fase se crea el documento de revisión que presenta los resultados alcanzados (añadir un grupo de referencias).
Preguntas de investigación
La principal pregunta de investigación a responder en esta investigación es:
¿Cuál es el estado del arte en las publicaciones relacionadas con la reducción del tamaño de los modelos de reglas de asociación?
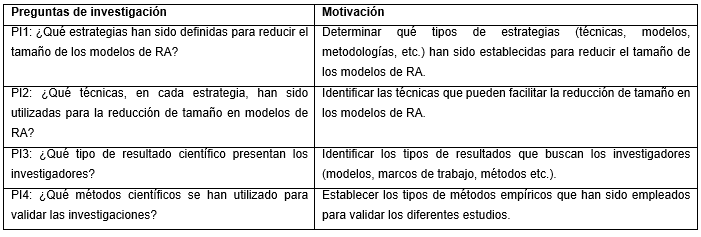
Dada la complejidad intrínseca de esta pregunta y con vistas a alcanzar una visión más específica de los estudios primarios más relevantes, fueron definidas otras cuatro preguntas de investigación. Con ello se pretende facilitar la tarea de responder la pregunta central. En la Tabla 1 se presentan las preguntas de investigación adicionales, así como las razones que motivan cada una.
Fuentes de datos y estrategia de búsqueda
Las fuentes a partir de las que se consideraran los estudios primarios son las bases de datos de la IEEE, la base de datos de Elsevier y la base de datos de Springer. Estas fuentes fueron seleccionadas ya que contienen la mayoría de las más importantes revistas y conferencias para diferentes áreas del conocimiento incluyendo el área en la que se centra esta investigación.
Para diseñar la cadena de búsqueda se utilizan operadores OR para enlazar elementos alternativos mientras que se utilizan operadores AND para enlazar los términos fundamentales. Los términos fundamentales de búsqueda pueden establecerse con facilidad y se seleccionó la expresión: Associacion Rules size reduction techniques los términos alternativos son más complejos debido a la variedad de formas en que puede ser expresado el problema del tamaño en los modelos de reglas de asociación. En la Tabla 2 se presentan los términos utilizados para construir la cadena de búsqueda.

Finalmente, la cadena utilizada fue: (“Association Rules” AND (“large number” OR “immense quantity” OR “huge number” OR “too much” OR “huge size” OR “so large” OR “huge amount” OR “often huge” OR “overwhelming” OR “too many” OR “representative rules” OR “alternative for all rules”))
Adicionalmente se aplicaron los siguientes filtros para refinar los resultados y obtener los de mayor calidad posible: 1- idioma: “English”, 2- tipo de documento: (“Conference Paper and Article and Article in Press”), 3- Fecha: entre 2010 y febrero 2021.
Selección de los trabajos
La selección de los trabajos se realizó a través de un proceso de tres fases:
Fase 1: Selección de los trabajos potenciales aplicando la cadena de búsqueda e inspeccionando en cada uno título, resumen y palabras claves.
Fase 2: Seleccionar los trabajos candidatos realizando el análisis de texto completo de los trabajos potenciales y aplicando los criterios de exclusión.
Fase 3: Aplicación de los criterios de calidad a los trabajos candidatos.
Como parte del protocolo se establecieron los siguientes criterios de inclusión y exclusión:
Criterios de inclusión (CI):
CI1- Artículos escritos en inglés referentes al tratamiento del tamaño en modelos de reglas de asociación.
CI2- Artículos con texto completo publicados en revistas o congresos y revisados por pares entre el 2010 y el 2021.
Criterios de exclusión (CE):
CE1- Artículos asociados a las reglas de asociación, pero no enfocados en la reducción del tamaño de los modelos o que la tratan de manera muy somera.
CE2- Artículos duplicados, dando preferencia a los más recientes y de mayor claridad.
CE3- Artículos que presentan revisiones de la literatura y meta análisis en reglas de asociación.
CE4- Artículos sin texto completo.
Criterios de calidad
Para evaluar la calidad de cada uno de los artículos se definieron dos objetivos. El primero, aborda la relevancia de lo reportado en el estudio con respecto al objetivo de la revisión sistemática; a estos objetivos corresponden los criterios de evaluación C1 y C2. El segundo objetivo está asociado a la credibilidad de los resultados teniendo en cuenta los métodos de evaluación y la diseminación de la investigación; a este objetivo corresponden los criterios C3, C4 y C5. Cada estudio puede alcanzar una evaluación entre 0 y 6 puntos y representa solamente un indicador que permite valorar la calidad del artículo, pero no constituye un criterio de exclusión.
Criterios de calidad:
C1- ¿El artículo contiene una descripción detallada de la estrategia y propiedades que soportan el proceso de reducción de tamaño? Las posibles respuestas son: Si (+1), No (+0).
C2- ¿El artículo describe los dominios o situaciones en los que es factible utilizar el proceso de reducción? Las posibles respuestas son: Si (+1), No (+0).
C3- ¿Se valida el estudio de acuerdo al tipo de propuesta realizada? Las posibles respuestas son: Validación empírica por medio de caso de estudio o experimento (+1), no validado (+0)
C4- ¿El estudio presenta un plan de validación? Las posibles respuestas son: tiene un plan completo (+1), tiene un plan parcial (+0.5), no tiene plan de validación (+0)
C5- ¿Está el artículo publicado en una revista o conferencia prestigiosa? Se utilizó como referencia para las revistas el ranking JCR (JCR, 2019) y para las conferencias el CORE (CORE, 2020). Las posibles respuestas son: Q1 o A* (+2), Q2 o A (+1.5), Q3 o B (+1), Q4 o C (+0.5), no rankeado (+0).
RESULTADOS Y DISCUSIÓN
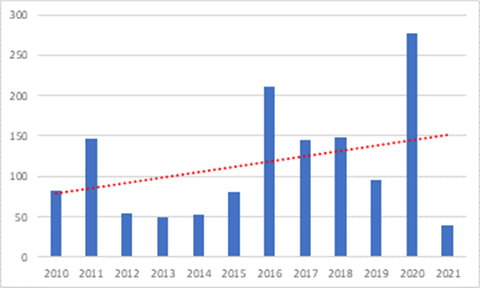
Luego de la aplicación de la cadena de búsqueda se encontraron más de 1383 artículos. En la Figura 1 se presenta la distribución temporal de los artículos encontrados, el grueso de los artículos se concentra en los últimos años y se aprecia un pico de producción científica en el año 2020 que reafirma el interés en la temática.
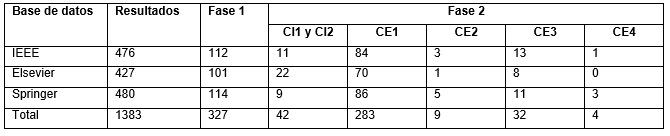
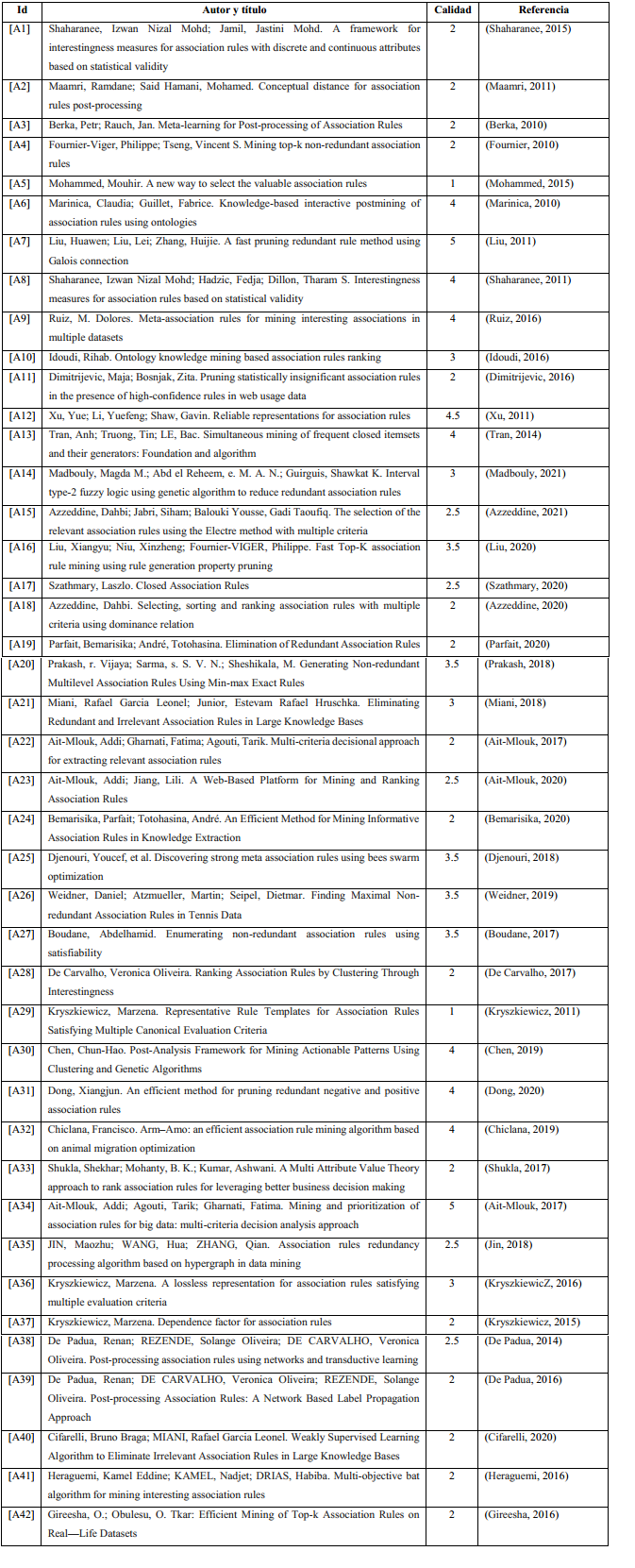
En la Tabla 3 se muestra el resumen consolidado de los artículos estudiados y los seleccionados para la revisión. El total de artículos obtenidos al aplicar la cadena de búsqueda fue reducido a 327 al finalizar la fase 1. El análisis de cada uno de los artículos utilizando los criterios de inclusión y exclusión durante la fase 2 arrojó la selección de 42 artículos tal como puede observarse en la tabla 3. En la Tabla 4 se listan los artículos finalmente seleccionados para la revisión identificándolos con el patrón [A + #] de esta forma se evita confundir los artículos que forman parte de la revisión con el resto de las referencias utilizadas en este trabajo.
Resultados de las preguntas de investigación
En este acápite se reportan los resultados de la investigación en función de las preguntas planteadas luego de analizar cada uno de los trabajos seleccionados.
PI1: ¿Qué estrategias han sido definidas para reducir el tamaño de los modelos de RA?
Se han utilizados varias estrategias asociadas a la reducción de tamaño en los modelos de RA:
Representación concisa: enfocada en la obtención de grupos de reglas reducidos a partir de los que se puede generar u obtener el conjunto total de las reglas.
Reducción de redundancia: explota determinadas propiedades y relaciones entre las reglas que permitan excluir del modelo reglas que no aportan nueva información.
Post-procesamiento: una vez obtenido el modelo de reglas realiza tareas de ordenamiento, filtrado y eliminación de reglas atendiendo a diferentes criterios. Dentro de esta categoría se han utilizado varias técnicas diferentes e incluso la combinación de varias.
Métricas de interés: se enfocan en proponer nuevas variantes para evaluar el interés de una regla con vista a entregar a los usuarios aquellas que tengan mayor valor para él.
Top k rules: una variante de obtención de reglas que se enfoca en la obtención de las mejores k reglas de acuerdo a la confianza, pero sin especificar un nivel de soporte. Logran una reducción de tamaño considerable pero no pueden garantizar que no exista perdida de información sensible producto de la reducción.
En la Tabla 5 se agrupan los artículos de acuerdo a las estrategias utilizadas mientras que en la Figura 2 se puede apreciar la distribución de los trabajos por cada una de las categorías. Claramente se aprecia que las estrategias que realizan post-procesamiento de las reglas minadas son las más favorecidas por los investigadores.


PI2: ¿Qué técnicas, en cada estrategia, han sido utilizadas para la reducción de tamaño en modelos de RA?
En la Tabla 6 se presentan las diferentes técnicas que han sido utilizadas en los artículos. Es necesario precisar que varios artículos utilizan más de una técnica en su desarrollo y en esos casos se utilizó la clasificación dentro de la técnica considerada predominante.
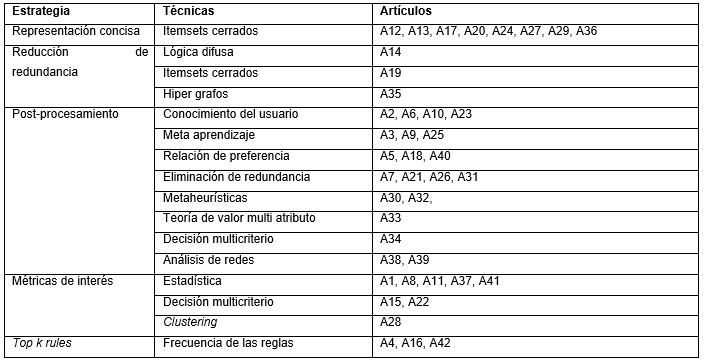
En la Tabla 6 puede observarse que la técnica más utilizada en la reducción del tamaño en modelos de RA está asociada a la eliminación de redundancia ya sea directamente o en la fase de post-procesamiento. Este detalle se acentúa si se considera que todos los trabajos que abordan las representaciones concisas a partir de ítemsets cerrados clasifican a las reglas que son eliminadas como reglas redundantes. Un total de 15 trabajos que representan el 35.71% de los estudiados siguen este enfoque.
Las definiciones de redundancias utilizadas en los artículos analizados comparten una misma base (BASTIDE, 2000). Semánticamente plantea que una regla de asociación es redundante si cubre la misma información o una información más específica que la cubierta por una regla de la misma utilidad y relevancia. Mientras que formalmente la define como: Una regla de asociación 𝑅 1 : 𝑋 1 → 𝑌 1 es no redundante si no existe una regla de asociación 𝑅 2 : 𝑋 2 → 𝑌 2 tal que 𝑠𝑜𝑝𝑜𝑟𝑡𝑒 𝑅 1 =𝑠𝑜𝑝𝑜𝑟𝑡𝑒( 𝑅 2 ), 𝑐𝑜𝑛𝑓𝑖𝑎𝑛𝑧𝑎 𝑅 1 =𝑐𝑜𝑛𝑓𝑖𝑎𝑛𝑧𝑎( 𝑅 2 ) y 𝑋 2 ⊆ 𝑋 1 ∧ 𝑌 1 ⊆ 𝑌 2 .
Algunos de los artículos estudiados introducen algunas variaciones a la definición de redundancia.
(XU, 2011) propone que una regla 𝑅 1 : 𝑋 1 → 𝑌 1 es redundante con respecto a 𝑅 2 : 𝑋 2 → 𝑌 2 si 𝑋 2 ⊆ 𝑋 1 ∧ 𝑌 1 ⊆ 𝑌 2 y además 𝑐𝑜𝑛𝑓𝑖𝑎𝑛𝑧𝑎 𝑅 1 ≤𝑐𝑜𝑛𝑓𝑖𝑎𝑛𝑧𝑎( 𝑅 2 ).
(PARFAIT, 2020) utiliza una métrica denominada 𝑀 𝐺𝐾 = 𝑃 𝑌 𝑋)−𝑃 𝑌 1−𝑃(𝑌) 𝑠𝑖 𝑃 𝑌 𝑋 >𝑃(𝑌) 𝑃 𝑌 𝑋)−??(𝑌) 𝑃(𝑌) 𝑠𝑖 𝑃 𝑌 𝑋)≤𝑃(𝑌) y a partir de ella define que una regla 𝑅 1 : 𝑋 1 → 𝑌 1 es redundante con respecto a 𝑅 2 : 𝑋 2 → 𝑌 2 si 𝑋 2 ⊆ 𝑋 1 ∧ 𝑌 1 ⊆ 𝑌 2 y además 𝑠𝑜𝑝𝑜𝑟𝑡𝑒 𝑅 1 =𝑠𝑜𝑝𝑜𝑟𝑡𝑒( 𝑅 2 ) y 𝑀 𝐺𝐾 𝑅 1 = 𝑀 𝐺𝐾 𝑅 2 .
(MIANI, 2018) plantea que una regla 𝑅 1 : 𝑋 1 → 𝑌 1 es redundante con respecto a 𝑅 2 : 𝑋 2 → 𝑌 2 si 𝑌 1 = 𝑌 2 ∧ 𝑋 2 ⊆ 𝑋 1 .
(WEIDNER, 2019) propone que una regla 𝑅 1 : 𝑋 1 → 𝑌 1 es redundante con respecto a 𝑅 2 : 𝑋 2 → 𝑌 2 si 𝑋 2 ⊆ 𝑋 1 ∧ 𝑌 1 ⊆ 𝑌 2 y además 𝑐𝑜𝑛𝑓𝑖𝑎𝑛𝑧𝑎 𝑅 2 =1.
(DONG, 2020) plantea que una regla 𝑅 1 : 𝑋 1 → 𝑌 1 es redundante con respecto a 𝑅 2 : 𝑋 2 → 𝑌 2 si 𝑋 1 = 𝑋 2 ∧ 𝑌 2 ⊂ 𝑌 1 .
La capacidad de reducción del tamaño de los modelos de reglas de asociación siguiendo este tipo de definición de redundancia fue estudiada en (BALCAZAR, 2010) demostrando que su límite teórico coincide con el de las reglas representativas. Estos modelos aún son demasiado complejos teniendo en cuenta la cantidad de reglas que contienen. Para continuar trabajando en este sentido se necesitan nuevas nociones de redundancia.
Otra de las técnicas que ha sido explotada con éxito es la incorporación de conocimiento del usuario para descartar aquellas reglas que no sean relevantes. Sin embargo, ninguno de los trabajos ha intentado combinar ambas estrategias con el fin de alcanzar niveles de reducción más elevados o en última instancia simplificar la complejidad de los algoritmos involucrados en el proceso de reducción.
Los trabajos enfocados en las métricas de interés intentan decidir la mejor métrica a utilizar, pero sus resultados no han sido conclusivos. No se ha podido determinar una métrica que supere al resto en todos los casos e incluso los modelos de evaluación de la calidad de las métricas demuestran que estas no cumplen todas las propiedades deseables (Sudarsanam, 2020). Por ello el interés en este tipo de investigación se ha desplazado hacia la obtención de modelos de reglas que satisfagan al mismo tiempo varias métricas de calidad. De esta forma se logra minimizar los problemas asociados a la calidad de las métricas y al mismo tiempo se alcanzan grados de reducción del modelo que si bien no son suficientes pueden considerarse un punto de partida para continuar las investigaciones.
PI3: ¿Qué tipo de resultado científico presentan los investigadores?
Como puede observarse en la Tabla 7 la mayoría de los trabajos han sido clasificados como métodos por parte de los investigadores. Este término, unido al de marco de trabajo, proyecta la intención del investigador de proyectar el trabajo sobre varias de las actividades del proceso de extracción de reglas de asociación. En contraste de las investigaciones clasificadas como algoritmos o bases representativas que se concentran en una etapa muy concreta del proceso de extracción. De esta forma la tendencia seguida por los investigadores se conduce a la presentación de un modelo de proceso y la descripción de las actividades y herramientas necesarias para culminar con éxito cada etapa.

PI3: ¿Qué métodos científicos se han utilizado para validar las investigaciones?
Solo el 7% de los artículos en el estudio no tienen alguna forma de validación, lo que puede considerarse como evidencia del grado de maduración en esta temática. En la tabla 8 se muestra en detalle la clasificación de los métodos de validación utilizados en los artículos. El método más empelado es el experimento, utilizado en más del 70% de los casos. Sin embargo, solo en (LIU, 2020) cuentan con un plan de validación lo que permite inferir que la temática precisa de definir protocolos de validación con vistas a incrementar el rigor y la credibilidad de los resultados alcanzados. Tabla 8

CONCLUSIONES
Este trabajo ha presentado una revisión sistemática de la literatura asociada a la reducción de tamaño en modelos de Reglas de Asociación; con vistas a identificar, analizar y describir el estado del arte de esta temática. Luego de realizar la búsqueda de los trabajos potenciales y de seleccionar los trabajos relevantes, se identificaron las estrategias utilizadas en los diferentes artículos siendo la estrategia de post-procesamiento la más utilizada por los investigadores. Los trabajos también fueron clasificados atendiendo a la técnica utilizada para alcanzar el objetivo planteado. En este apartado se destaca la eliminación de redundancia que fue utilizada en el 35% de los trabajos tanto en la etapa de minado como en el post-procesamiento. Las acotaciones realizadas por los autores se encaminan a manejar definiciones de redundancia que se aparten de la clásica y que en la medida de lo posible incorporen conocimiento de los usuarios con vistas a entregar modelos que satisfagan en mayor grado sus expectativas.
La mayoría de los autores presentan sus resultados como métodos y generalmente están diseñados para manejar más de una actividad en el proceso de extracción de reglas de asociación y para incluir técnicas de otras áreas del conocimiento para mejorar los resultados. Sin embargo, se detectaron carencias metodológicas a la hora de establecer la definición de método como resultado de una investigación. Ninguno de los autores establece cuáles son las características metodológicas asociadas a la propuesta realizada en su investigación.
Los resultados muestran la existencia de interés alrededor de la temática y la madurez y rigor científico de la misma que se puede constatar a partir de que más del 90% de los artículos han sido validados mediante experimentos o casos de estudio. Aunque no se logró apreciar la existencia de un protocolo de experimentación estándar reconocido dentro de la temática.

