










 Servicios personalizados
Servicios personalizados
 Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introduction
In an interview with Baeza Yates by Marcos1 he states that the main insufficiency that persists in search engines is trying to understand the intention after the search, that is, what is the informational need of people and customize their searches to that task. This involves predicting the intention and adapting the interface to the whole task. This is one of the challenges that IRSs (Information retrieval Systems) face at present, each user has characteristics that make them distinctive in the IR (Information Retrieval) process, so the personalization of the results they receive as answers to their search queries should be the essence of the internal functioning of a search engine.
These aspects are valued by companies such as Google that recognizes how the update of their algorithm for the calculation of relevance (Maccabees) takes into account the update focuses on the quality of the content, the links pointing to the site and the experience of the user.2)
This change represents a revolution in the way in which the websites are positioned in this IRS, since the quality of the content given to the users and the relationship it has with their interests are prioritized. Although search engines can offer millions of results for a single search, in reality this is not important. From the point of view of the final user, it is indifferent that, for a key word, the search engine has either a few tens or several million results, since it will only examine the firsts.3 For this reason, it is important to develop relevance calculation algorithms so that a response which satisfies the user's query is provided in the minimum number of results. In order to get a better response, in this work we propose an algorithm which includes and integrates user preferences and document categories.
This paper is divided into a related work section, where the state of the art about the calculation of relevance is exposed; the section methods, where it is explained an algorithm which integrates document categories; and user profile to calculate the relevance of a document, the results section, where the results obtained in an experiment with the algorithm are shown.
Related work
The personalization models in search engines have the goal of bringing to the users personalized results, decreasing the amount of irrelevant documents.4 Several researches have shown how they are used as sources to define user preferences, queries, documents consulted, user browsing history, interaction with social networks, the nature of documents, or concepts associated with documents, among others; recognizing as impact factors the history of queries inserted by users and the nature of the documents in the collection. The most referred techniques in the previously discussed researches are focused on re-ranking methods, Bayesian classifiers, ontology design, terms frequency, agent technology, methods based on inferences, greedy algorithms, stemming algorithms, among others.4,5,6,7,8,9,10,11,12 Despite the fact that positive results have been demonstrated in some of these methods, it is difficult to find an algorithm explained in detail to integrate the user profile variables and the nature of the documents in the relevance calculation process.
According to Fransson,13 in the case of Google, its administrators say they use more than 200 variables in their algorithm; however, they are not explained in depth in order to develop similar forms of calculation. Some of the most important updates since 2011 are the following table: (14
Table 1 Updates of the Google algorithm
| Name | Panda | Penguin | Hummingbird | Pigeon | Mobile | RankBrain | Possum | Fred |
|---|---|---|---|---|---|---|---|---|
| Date | February 2011 | April 2012 | August 2013 | July 2014 | April 2015 | October 2015 | September 2016 | March 2017 |
Source: 8 major Google algorithm updates, explained. Available from: https://searchengineland.com/8-major-google-algorithm-updates-explained-282627
In the limited bibliography referring to the specificities of the Google algorithm, it is possible to recognize the importance played by the calculation of the relevance of the user's profile definition and the nature of the query, but there is no specific information on how these variables are integrated in the implementation of their algorithm.15,16,17
Methods
The proposal presented allows to solve the problem described above, by designing and implementing an algorithm1 that integrates the categories of the user's search profile (USP) and that of the documents (DC) to retrieve relevant and personalized information. These categories can be defined prior to the execution of the algorithm, usually calculated statically. A dynamic version could be defined; however, it is not the goal of the present work. The USP is defined as a set of pairs category-index, where indexes are selected by users in the interface registration and in the thematic search interface, in both interfaces the form to select the index are the same (Fig. 1).

The query categories (QC) is defined as the relation of the categories to which the query belongs with its percentage of predominance after executing the process of categorization of the query. In the example shown in table 2, the query is categorized with a 60% predominance belonging to the environment category, 20% to politics and 20% to culture. To store the QC, is proposed a matrix that relates the categories to which the query belongs and their membership percentages.
The expression (1) is applied to two scenarios in which the relevance  differs in its values:
differs in its values:
 (1)
(1)
where ts is the relation category-index defined in the thematic search, rp is the relation category-index defined in the registration form, q is the query inserted by the user, d is a document to calculate the relevance, SCD (q, d) in (0,1), RCD (q) in (0,1), RPUD ≤ 1 and α + β + γ = 1. Notice that R (d) ≤ 1, being 1 the maximum relevance value for a document.
The parameters used in (1) are the following:
SCD: Similarity between the user’s query q and the document d. To calculate this value, it is proposed to use the cosine formula considering in the Vector Space Model.
RCD: A matching function between the user’s query q and the document d, expressing the relevance with regard to the relation category-index defined in the thematic search.
RPUD: A matching function between the user’s query q and the document d, expressing the relevance with regard to the relation category-index defined in the registration interface.
In case of table 2, we are facing a user who focuses his search preferences on topics related to the environment with 60% percent prevalence, about culture 20% and politics about 20%. With this information, the IRSs must be able to enhance in the calculation of relevance the documents belonging to these categories, prioritizing those related to the environmental category. Another parameter that the algorithm uses is the categories (DC) to which each document stored belongs. To execute this task, an automatic categorization mechanism must be guaranteed that allows, once the documents are tracked and indexed, to assign in the data structure that represents each document in the collection, the category field with the calculated value. To solve the problem of a document belonging to more than one category, it is decided to proceed as with the user's profile and create an arrangement with the proportion of predominance of each category to which the document belongs, see an example in table 3.
Table 3 Assignment of categories to a particular document (DC)
| Category | Sports | Environment | Culture | Politics | Sciences |
|---|---|---|---|---|---|
| Index | 0,1 | 0,2 | 0,6 | 0,05 | 0,05 |
The two scenarios which could be considered are the following:
Scenario 1. Users need objective results wich do not depend on the profile defined in the registration interface; in this case the value of
 = 0,5, α = 0,5 and
= 0,5, α = 0,5 and 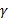 = 0. In this scenario, it is assumed that the most relevant documents are those that have a greater degree of similarity with the query, when applying the cosine formula and also that they belong to the categories of greater predominance in the thematic search.
= 0. In this scenario, it is assumed that the most relevant documents are those that have a greater degree of similarity with the query, when applying the cosine formula and also that they belong to the categories of greater predominance in the thematic search.Scenario 2. Users need results that vary only taking into their preferences selected in the registration form, in this case
= 0, = 0,5 and α = 0,5. In this scenario, it is assumed that the most relevant documents are those that have a greater degree of similarity with the query when applying the cosine formula and also that they belong to the highest scored categories in the user’s search profile defined in the registration form interface.
These two scenarios are selected in automatic way by the IRS, if the user select the thematic search, then scenario 1 is selected in other case scenario 2 is selected. The relevance calculation for every document is defined by the execution of a series of steps shown in two procedures (rule 1 and rule 2) which are exemplified below. In case the results are framed in scenario 1 described above, then the USP value is replaced by the QC in the rules, if the results respond to scenario 2 then the value of the USP is used instead QC:
Rule 1
Input:
USP - Set of (category, value) of the user profile.
DC - Set of (category, value) associated to a document.
Output: RPUD
1: 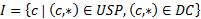 Ø
Ø
2: If  then RPUD = 0
then RPUD = 0
3: else
4: 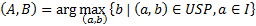
5: 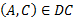
6: If B ˃ C then RPUD = C // first case study
7: else RPUD = B
// second case study
Two case studies are designed to test the operation of the algorithm. In the first case study the percentage index of the categories of the user profile environment (0,6), politics (0,2), culture (0,2) and the categories of the document sport (0,1), environment (0,2), culture (0,7) are defined. For the first case rule 1 applies and the following values are defined: I = {Environment, Culture}, A = Environment, B = 0,6, C = 0,2, B > C ( RPUD = 0,2. In the second case study, the percentage index of the categories of the user profile environment (0,3), politics (0,6), culture (0,1) and the categories of the document sport (0,1), environment (0,9) are defined. For the second case, rule 1 applies and the following values are defined: I = {Environment}, A = Environment, B = 0,3, C= 0,9, B < C ( RPUD = 0,3 (rule 2, table 4).
Rule 2
Input:
USP - Set of (category, value) of the user profile.
DC - Set of (category, value) associated to a document.
Output: RPUD.
1: 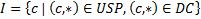
2: if then RPUD = 0
3: else// Example 3
4: 
5:
6: 
7: if then RPUD = C
8: else RPUD = B
Table 4 Example 3: categories of the user's search profile and that of the documents
| User's search profile | Category | Environment | Politics | Culture |
|---|---|---|---|---|
| Percent index | 0,45 | 0,45 | 0,1 | |
| Documents | Category | Environment | Politics | - |
In example 3, considering the USP and the DC of table 4 for a particular document, and applying rule 2, the values defined are the following: I = {environment, politics}, A = {environment, politics}, B = 0,45, D = {0,9, 0,1}, C = 0,9, B < C ( RPUD = 0,45.
An experiment was carried out to evaluate the precision and recall metrics obtained before and after applying the algorithm in a Real Information Retrieval System (called Orión, developed by de University of Informatic Sciences) which uses as algorithm for the calculation of relevance a hybrid between the Probabilistic Model and the Vector Model based on the formula of cosine. Also, a second version of Orión was implemented according to expression (1). The experiments were conducted using a population of 23 users who have more than 5 years of experience in the use of information retrieval systems. In addition, 100 documents were selected, categorized according to the 6 categories defined in the Orión search engine. Each user selected a query of 3 proposals; experts, in IR and user profile modeling, annotated the documents that are considered relevant in relation to the selected query and the user's USP. The USP was obtained from the registration form as a relation category-index defined by users.
Results
The calculation of the relevance was executed for the two scenarios defined in the research but, due to lack of space in this paper, only scenario 2 of (1) will be addressed, using β = 0, α = 0,5 and γ = 0,5; thus SCD (q, d) and 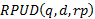 functions are equally valued. Other scenarios and combinations of values of α, β and γ should be analyzed in further works. The results obtained can be seen in table 5.
functions are equally valued. Other scenarios and combinations of values of α, β and γ should be analyzed in further works. The results obtained can be seen in table 5.
Table 5 Experimental results when applying the algorithm to calculate the relevance of the information
| Average precision before applying the algorithm | Average precision after applying the algorithm | Average recall before applying the algorithm | Average recall after applying the algorithm |
|---|---|---|---|
| 0,34 | 0,86 | 0,30 | 0,70 |
In both metrics there is a significant difference in the values obtained before and after applying the proposed algorithm, improving the quality of the results provided to users who interact with this search engine. In addition, these results shown that the preferences of the users and the categories of the stored documents play an important role in the calculation of the relevance of the documents returned in response to the questions of the users.
Conclusions
The analysis of the literature allowed to identify that there are inadequacies in the use of user preferences and document classifications to provide relevant and customized search results on information retrieval systems.
The design, scientific substantiation and implementation of the proposed algorithm integrates user profile preferences and document categories to retrieve relevant information.
The results obtained from applying the precision and recall metrics to the proposed algorithm allowed to corroborate that it improves the quality of the search results provided to users.

