










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
El análisis de sentimientos o minería de opiniones es una rama de la computación que permite analizar opiniones, sentimientos y emociones en ciertas áreas de interés social como productos, servicios, organizaciones, compañías, eventos y temas de interés actual. Se realiza mediante la aplicación del Procesamiento de Lenguaje Natural (PNL, por sus siglas en inglés), Aprendizaje Automático e Inteligencia Artificial (IA), dado que dichas opiniones pueden ser expresadas mediante tweets, clasificadas en emociones o polaridades.1
Relacionados específicamente con la salud, se han realizados estudios sobre el impacto de la pandemia COVID-19,2 su efecto en la salud mental,3 acerca del aislamiento social;4,5,6,7,8 otros que además incorporaron la detección de temas de conversación9,10,11,12,13,14) y en relación con el uso del dióxido de cloro como tratamiento de la enfermedad.15 También se identificó una investigación sobre la farmacoterapia.16 En Cuba solo se halló un trabajo sobre el diálogo en Twitter acerca de las brigadas médicas cubanas en el contexto de la pandemia, pero en el año 2021.17
Entonces, el evento de interés resultó ser la campaña de vacunación masiva vivida en Cuba como parte del enfrentamiento a la enfermedad de la COVID-19, la cual comenzó como intervención sanitaria en mayo del 2021 para grupos y territorios de riesgo y en junio se inició su uso de emergencia para la totalidad de la población cuando el país atravesaba por un empeoramiento de la situación epidemiológica, debido al aumento sin precedentes de las tasas de incidencia y mortalidad y el riesgo de muerte, para abril de esa fecha.18 Los candidatos vacunales más avanzados en aquel momento, de acuerdo con el cumplimiento de las diferentes etapas del ensayo clínico, eran Abdala y Soberana 02. Según el cronograma divulgado habían concluido la última fase en mayo y contaban con la aprobación del Centro para el Control Estatal de Medicamentos, Equipos y Dispositivos Médicos (CECMED),18 que es la entidad rectora y reguladora de este proceso.
Por tanto, debido al impacto mediático que tal suceso generó, se indagó en las redes sociales, específicamente en Twitter, con el objetivo de identificar los sentimientos y los tópicos presentes en los tweets que hicieron mención a las vacunas cubanas Soberana 02 y Abdala. Teniendo en cuenta que esta red social es la tercera más usada en Cuba19) y, además, es de las más flexibles para el acceso a la información de sus usuarios con fines investigativos. Los estudios en las redes sociales favorecen el acceso a la producción ideográfica de los sujetos en condiciones de total espontaneidad, inmediatez y simultaneidad por lo que es factible de convertirse en un medidor con alta sensibilidad para indagar en cómo reaccionan las personas a los acontecimientos sociales.
Métodos
Se realizó un estudio de análisis de sentimientos y tópicos sobre los tweets que hicieron mención a las vacunas cubanas Soberana 02 y Abdala en el período del 11 de julio al 21 de septiembre del 2021. Para la realización de la investigación se optó por los lenguajes de programación Python y R con sus librerías específicas para la ciencia de datos. Para Python se escogió como entorno de desarrollo integrado el Visual Studio Code y, en el caso de R, el RStudio. La primera parte del estudio, que abarcó desde el web scraping hasta la cuantificación de las palabras más usadas, se realizó con Python; mientras que la segunda, el análisis de sentimientos y detección de tópicos, se implementó con R.
El primer paso y condición necesaria para iniciar la investigación es ser usuario de Twitter. Esto permite la habilitación de una cuenta de desarrollador20) y el ulterior registro de una aplicación a la que se nombró “Proyecto análisis” para obtener el acceso a su API (Interfaces de Programación de Aplicaciones), el cual proporciona unas credenciales de acceso y uso de uno sus servicios como es la búsqueda de contenido. Teniendo en cuenta el tipo de API de las que provee la red social, se usó el API rest para acceder a los tweets que se han generado desde el pasado reciente hasta el presente: los últimos siete días, de acuerdo con sus restricciones.
A través de tweepy21) se inició con la conexión y autenticación a la API rest de Twitter para dar lugar a la extracción de los tweets. Se estableció como query o término de búsqueda los hashtags #Soberana02 y #Abdala. La recolección de tweets ocurrió entre el 11 de julio y el 21 de septiembre. En este período se realizaron capturas dentro de un rango máximo de 15 minutos, limitación impuesta por Twitter. Los tweets recolectados fueron cargados en un archivo json y se organizaron en un dataframe, a través de pandas.22 La estructura de metadatos quedó formada por un dataset, cuyos campos fueron el id del tweet, autor, fecha/hora y texto del tweet.
Para iniciar la etapa de minería de texto con la aplicación de las herramientas del NLP se creó un nuevo dataframe en formato csv a partir del filtro aplicado al campo “texto del tweet”, ya que en lo adelante sería la unidad de análisis. Posteriormente, se realizó el preprocesamiento que no es más que la limpieza de datos. En las tareas 1 y 2 se empleó la librería re23 y en la 3 y 4 con nltk;24 esta última es imprescindible para pasar de un objeto de estructura oracional a uno de bag of words o bolsa de palabras. Una vez concluida la normalización del texto, se calculó la frecuencia de las palabras más usadas y se graficó con matplotlib.25
Eliminación de saltos de líneas, signos de puntuación, hashtags, menciones, hipertextos, emoticones, palabras incompletas y caracteres sueltos.
Conversión de todas las palabras a minúsculas.
Eliminación de stopwords (palabras enlace) y palabras derivadas.
Tokenización: división del texto en palabras.
Para el análisis de sentimientos se implementó el siguiente procedimiento de acuerdo con las librerías elegidas. Con tokenizers26 se tokenizaron nuevamente las palabras para permitir la vectorización. En la identificación de sentimientos se usó la librería syuzhet,27,28 que opera con un diccionario de términos en español como parte del NRC Word-Emotion Association Lexicon, compuesto por una lista de palabras y sus asociaciones con ocho emociones (ira, miedo, anticipación, confianza, sorpresa, tristeza, alegría y disgusto) y dos sentimientos (negativo y positivo).27 Esto genera una matriz que está integrada por un vector de palabras, las ocho emociones y la polaridad negativa y positiva, donde 0 indica que la palabra del listado no existe en el diccionario y ≥ 1 su correspondencia-valencia con las emociones; a esto se le calculó el porcentaje.
También se abordó la polaridad a nivel longitudinal para identificar su evolución a lo largo de todo el conjunto de términos; según sea negativa se le asigna - 1 y si es positiva 1. Se emplean tres procedimientos estadísticos para su realización: la media móvil, la regresión ponderada localmente y la transformación de coseno discreta.27 En uno y otro caso el ploteo se hizo con barplot29 y simple_plot,27 respectivamente. Para mostrar la distribución de los términos por tipo de emoción y polaridad se optó por hacerlo a través de una gráfica de nubes de palabras con wordcloud.30 Esto requirió de tm31 para para la conversión del dataset tokenizado en un vector de palabras, posteriormente, a un corpus y de este a una matriz de término-documento.
El modelado de tópicos para la identificación de temas en los tweets se realizó con topicmodels, que es un método de aprendizaje no supervisado que opera con el algoritmo matemático LDA (Asignación Latente de Dirichlet).32 Este se fundamenta, como parte de las características básicas de los algoritmos sobre la detección de temas, en que cada documento se compone de varios temas o topics y que cada tema supone un conjunto de palabras que lo representa,32 a partir de la coocurrencia de las palabras. De esta manera se puede medir la distancia semántica entre ellas en una estructura de bag of words, por lo que se prioriza el aspecto conceptual del lenguaje en detrimento del sintáctico.
Por tanto, su agrupamiento está delimitado por la presencia de tópicos que esperan sean descubiertos, porque son la estructura del discurso. Se sigue una lógica inversa en la generación de temas, al plantear que no son las palabras las que los determinan sino al revés y, en consecuencia, cada palabra tiene distinto peso en dichos tópicos; de lo que se deriva que sean más relevantes en uno que en otros. Cada palabra es el resultado de un encadenamiento de distribuciones y luego se realiza la inferencia hacia atrás para calcular la distribución más probable, dada las palabras y los documentos.33 El algoritmo calcula la proporción de palabras en cada documento asignado a tema, es decir, [p (tema T|documento D)] y después la proporción de las palabras que se asignaron a un tema sobre todos los documentos, o sea, [p (palabra W|tema T)].34 Su implementación se realiza sobre la matriz de término-documento que, a través de tidyverse,35 se convirtió en un objeto tidy y se seleccionó el Gibbs32 como método de muestreo y la beta, el tipo de distribución. La elección de la cantidad de tópicos se prefijó en cinco. La visualización se realizó con ggplot2.36 No se requiere del uso de etiquetas a posteriori para identificar los tópicos.
El código y los datasets pueden ser consultados de forma pública.37 Únicamente no está presente en el código las claves de acceso provistas por la API de Twitter por advertirse de su uso privado. Y en el caso del dataset de tweets, en estos no se divulga información que comprometa la privacidad de los usuarios investigados, en correspondencia con el cumplimiento de los requerimientos de Twitter acerca del uso responsable de los datos personales de sus usuarios. Lo anterior quedó refrendado en el formulario de obligatorio llenado que debía ser completado para la asignación de la cuenta de desarrollador.
Resultados
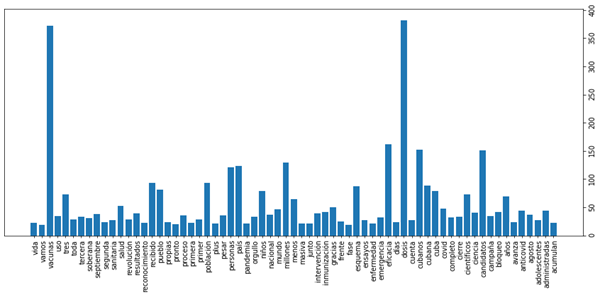
En el período establecido para las capturas de los tweets con los hashtags #Soberana02 y #Abdala se obtuvo una muestra de 3251 entre retweets (2133) y tweets (1118). En función de la representación gráfica se excluyeron aquellas con frecuencia ≤, lo que dio como resultado 67 palabras con mayor frecuencia.
Entre los términos con que más se dialoga en Twitter, por solo mencionar los 10 primeros, se encuentran: dosis (383), vacunas (373), eficacia (163), cubanos (153), candidatos (152), millones (131), país (125), personas (122), recibido (95) y población (94). Como es de apreciar se refleja el contexto que se vivió el país acerca de la campaña de inmunización, el cual es representado en el discurso digital como un proceso colectivo (fig. 1).
En cuanto a los sentimientos, según los términos que formaron el contexto semántico, se identificaron aquellos que expresaron emociones como la confianza (12 %) y el miedo (10 %), que también se aprecia en la polaridad, donde predominan tweets con una polaridad positiva (25 %) (fig. 2).
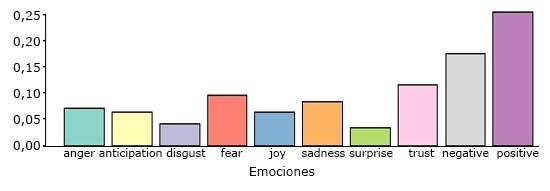
A continuación, se muestran algunos de los términos más frecuentes, según las emociones representadas, así como la polaridad. Se identificó tristeza a partir de términos como: emergencia, pandemia, cierre; en tanto que la confianza fue en las palabras: solidaridad, esperanza, presidente y la polaridad positiva de los tweets en: eficacia, recibido, orgullo, completo (fig. 3).

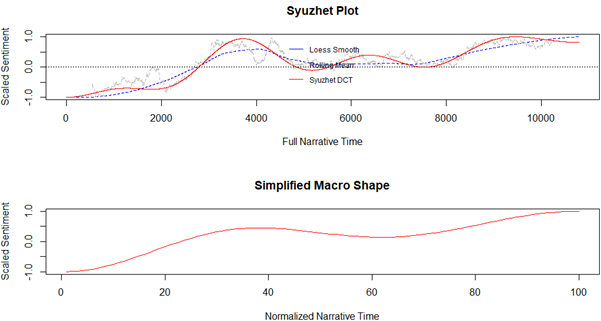
De manera longitudinal se puede apreciar que en los primeros tweets la polaridad del sentimiento comienza siendo negativo hasta que se va estableciendo una tendencia hacia una polaridad positiva (fig. 4).
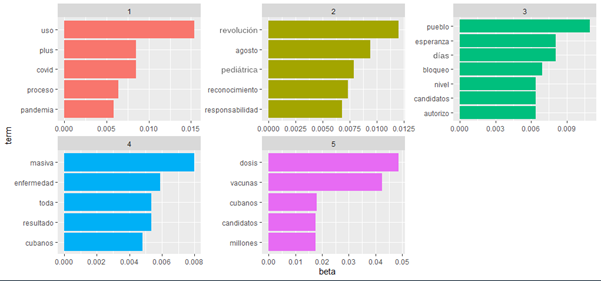
En cuanto a los tópicos se identificó que los temas están compuestos por los siguientes términos:
Tema 1: uso, plus, COVID, proceso, pandemia.
Tema 2: revolución, agosto, pediátrica, reconocimiento, responsabilidad.
Tema 3: pueblo, esperanza, días, bloqueo, candidatos, autorizo.
Tema 4: masiva, enfermedad, toda, resultado, cubanos.
Tema 5: dosis, vacunas, cubanos, candidatos, millones (fig. 5).
Discusión
La medida de confinamiento social como respuesta a la pandemia de la COVID-19 precipitó la presencia de la Internet en la población cubana. Entre el 2021 y el 2022 hubo un incremento del 5,1 % de celulares conectados y una penetración de la Internet del 68 %.38 Por lo tanto, el escenario digital, como entorno donde también se desarrolla la conversación pública, es susceptible de ser abordado por las Ciencias Sociales computacionales para dar cuenta de cómo se interactúa con los acontecimientos colectivos. En este estudio se abordó lo relativo a un evento de salud, la vacunación masiva ocurrida en el país, al ser la estrategia más democrática para producir inmunidad biológica colectiva y afrontar en mejores condiciones el virus.
Rodríguez y otros39 en su estudio con 38,034 tweets, recopilados entre el 12 de mayo y el 30 de septiembre del 2020 de usuarios colombianos, mostraron que un 42 % manifestó miedo, el 38 % ira, el 15 % alegría y el 5 % tristeza, en relación con la vacuna. Aunque en este caso las reacciones estudiadas se corresponden, teniendo en cuenta la fecha, con el anuncio de la vacuna en sus distintas fases de ensayo clínico, por lo que aún se desconocía su eficacia y efectividad en los seres humanos. Por lo tanto, los resultados responden a las anticipaciones que se generan en contextos de incertidumbre, además de la fuerte polarización política vivida en ese país en torno a la gestión gubernamental de la pandemia. En este mismo país Arias García y Doria Pérez40 estudiaron el impacto de la vacunación durante el período del 15 de marzo hasta el 25 de abril de 2021 con una muestra de 1504 tweets. Se clasificaron 612 tweets positivos, 486 negativos y 407 neutrales con un porcentaje del 40,66 %, 32,29 % y 27,04 %, respectivamente.40
Vallejo41 en su estudio sobre el Ecuador y tres provincias específicas, como parte de la primera parte del plan de vacunación entre los meses de enero y julio del 2021, encontró que en la polaridad de los tweets predominó la positiva y, en menor medida, la neutral; la negativa fue más baja. Lo anterior también se reflejó en el análisis temporal realizado, aunque no llegó a determinar si la polaridad de los tweets se relacionaba, de forma estadísticamente significativa, con la pertenencia a alguna de las provincias.
Rodríguez y otros42 con una muestra de 1 millón de tweets correspondientes a países y regiones, cuya lengua es el inglés o español, halló un 35 % de polaridad, tanto positiva como negativa. A través de la técnica de clustering encontraron que una mayor polaridad negativa se encuentra en temas como la desigualdad en el acceso a las vacunas y el mantenimiento de las medidas sanitarias a pesar de la vacunación. Entre tanto la polaridad positiva fue predominante en la inoculación en figuras públicas, la gratuidad de las vacunas y los efectos sobre la salud. La polaridad neutra fue mayor en temas como las fake news y la presión política sobre la vacunación.
Liu y Liu43 caracterizaron los sentimientos en 2 678 372 tweets provenientes de los Estados Unidos entre el 20 de noviembre del 2020 y el 31 de enero del 2021. Se obtuvo que el 42,8 % fueron positivos, 26,9 % neutrales y el 30,3 % negativos. La polaridad positiva se relaciona con tópicos como los resultados de los ensayos, la administración, la vida, la información y la eficacia. Mientras que en los de orientación negativa se coincidió, con relación a los temas que también generaron sentimientos positivos, en los resultados de ensayos y la administración; en tanto que se difirió en los siguientes temas: conspiración, confianza y efectividad.
Povedano y otros44 realizaron un estudio en 4 000 000 de tweets geolocalizados, en su mayoría, en los Estados Unidos entre el 15 de noviembre y el 16 de diciembre del 2020. Reportan un porcentaje importante de tweets negativos, pertenecientes a los usuarios de estados del centro y sur;44 mientras que los de sentimiento positivo se ubicaban en el este. Entre los tópicos que se detectaron como los principales temas y preocupaciones relacionados con la vacuna fueron: la efectividad de la vacuna, la seguridad de la vacuna, los efectos secundarios (en especial como puede influir la vacuna en la fertilidad y las posibles reacciones alérgicas), la distribución de la vacuna y qué grupo de población será el primero en recibir las dosis iniciales.44
Con una muestra de 2 970 tweets Carrasco-Polaino y otros45 investigaron acerca de la polaridad de los sentimientos hacia las primeras vacunas durante el tiempo en que fueron anunciados sus resultados de eficacia. Los autores refieren que, de manera general, la polaridad fue positiva, aunque por vacunas hubo diferencias estadísticamente significativas en el gradiente de positividad: la Pfizer y Moderna tuvieron más alto nivel de positividad, seguido de las vacunas chinas y la Oxford-AstraZeneca con nivel medio y la Sputnik V en medio bajo. También reportaron que las vacunas occidentales, dígase Oxford-AstraZeneca, Pfizer y Moderna en ese orden, tuvieron mayores índices de favorabilidad, en contraste con el alto índice de polémica que tuvieron las vacunas chinas y la rusa.
Roe y otros46 detectaron la polaridad del sentimiento en una muestra de 137 781 tweets del continente europeo entre el 1ro y el 21 de julio del 2021. Los resultados indican que 53 899 fueron negativos, 53 071 positivos y 30 811 neutrales. Según el análisis temporal reportado de las tres semanas, la polaridad negativa predominó en las dos últimas. Entre los términos que identificaron asociados a la polaridad se encuentran: el hashtag #covid19 y la palabra persona; ambos vinculados, tanto a los sentimientos negativo, como positivo y neutral; en tanto que con una polaridad diferente, asociada a la positiva están las palabras: obtener, ayuda y vacuna, respectivamente.
Es válido resaltar que en todos los trabajos citados se refiere la polaridad del tweet, mientras que en los resultados hallados en el presente estudio se identificó la polaridad y varias emociones. Además, se mostraron aquellos términos que las representaban, por lo que se parte de esta distinción para contrastar la evidencia. Se aprecia diferencias con los hallazgos de Povedano y otros44) y Roe y otros,46) quienes describen tópicos relacionados, fundamentalmente, con la inseguridad ante las distintas circunstancias en el contexto de la enfermedad, de la que forma parte la vacunación; mientras que en el presente estudio predominó la polaridad positiva y los temas detectados están vinculados con la aplicación de las vacunas como proceso colectivo y de consenso
En relación con el contenido de los tópicos se han encontrado coincidencias con Rodríguez y otros42 y Liu y otros,43 aunque el primer estudio reporta una igualdad en la polaridades positivo-negativo, en tanto el segundo muestra que predominó del sentimiento positivo. Por tanto, la evidencia refleja varias contradicciones. Se debe tener en cuenta que en el hemisferio occidental es donde más influencia poseen los grupos antivacunas y las redes sociales emergen como espacios de intercambio comunicativo con ciertas desregulaciones que han conducido a que las grandes empresas de redes sociales implementen algoritmos para detectar información falsa. Sin embargo, en el estudio de Rodríguez y otros39) y Vallejo41 existieron semejanzas en el predominio de la polaridad , pues analizaron tweets geolocalizados en Latinoamérica y fue mayoritario el sentimiento positivo hacia las vacunas.
Conclusiones
En el estudio se identificaron cinco tópicos que reflejan el contexto de la vacunación como un proceso colectivo. De manera ligeramente predominante hay presencia de emociones como la confianza y el miedo con una polaridad positiva. Los términos empleados se corresponden con el contexto vivido en el cual se desarrolló la campaña de vacunación. En sentido general, de acuerdo con los términos más frecuentes empleados para referirse a las vacunas, los tópicos identificados, los términos que se relacionaron con las emociones predominantes, así como por la polaridad, se apreció consenso en torno a las vacunas Soberana 02 y Abdala.

