Y a la epidemiología, como una fuerza poderosa en seis grandes áreas para el abordaje de los problemas de salud: etiología, eficacia, efectividad, eficiencia, evaluación y educación.20
Epidemiología clínica
Es uno de los productos de las corrientes integradoras que han caracterizado a la ciencia durante las últimas décadas. Fruto de estas corrientes, donde se rescata el valor de lo sintético, de lo global y del todo, por los años 60, es que surge la llamada epidemiología clínica.25
La Epidemiología Clínica, por su parte, es la disciplina que se ocupa del estudio de las determinantes y los efectos de las decisiones clínicas, de las estrategias de diagnóstico y tratamiento; así como del abordaje de los problemas clínicos, a partir de la aplicación de indicadores cuantitativos, epidemiológicos y estadísticos.26 Ella evalúa el comportamiento clínico, el conocimiento y su aplicación, la actuación médica.
La epidemiología clínica actúa como una disciplina básica con respecto a la medicina clínica, que ofrece herramientas muy útiles a esta última para evaluar el comportamiento clínico. Es el fruto del acercamiento o interpenetración de ambas disciplinas, así como de la aplicación de los conceptos e indicadores propios de la epidemiología -y de la bioestadística- a la evaluación de la práctica médica.
Uno de los pilares de la investigación y la práctica clínica es tratar de reducir la incertidumbre del médico frente a un problema de salud de un individuo en particular. 25 Dicho fundamento sirve de base para el surgimiento de la epidemiología clínica, que viene al rescate de la clínica como ciencia, con instrumentos y razonamientos acordes a los nuevos tiempos y exigencias.27 Más que un camino hacia la verdad, la clínica buscaría un camino hacia la menor probabilidad de error.25 ]]>
La incertidumbre de la clínica apoya la búsqueda de instrumentos de mayor precisión. Tres afirmaciones respaldan esta búsqueda: la práctica de la medicina es inexacta y permanecerá así; los datos disponibles son, a menudo, indirectos, incompletos y hasta contradictorios y la mejor decisión puede alcanzarse sólo por aproximaciones sucesivas.28
El reto que enfrenta la epidemiología consiste en transformar los datos -signos síntomas, resultados de las pruebas, aplicación de un tratamiento- en información para contribuir a la formación de un nuevo conocimiento que favorezca la toma de decisiones adecuadas en la acción y que se alcance el impacto deseado en la atención clínica de los individuo.20
Por último, no debe dejar de destacarse el impacto positivo de las propuestas teóricas y metodológicas de la epidemiología clínica en el desarrollo del pensamiento crítico en las ciencias clínicas, así como en la creación de normas para la evaluación de la literatura médica según tipo de trabajo y en general.
Epidemiología genómica9
En 1988, la fundación de Human Genome Organization (HUGO) para coordinar mundialmente todos los esfuerzos individuales en el campo de la investigación genómica, constituyó, si dudas, un hito para el verdadero inicio de la "Era de la revolución genómica", cuya primera etapa culminó con la publicación del genoma humano en el año 2003. Paralelamente, nació una nueva disciplina cuya misión es comprender la influencia de los factores genéticos en la ocurrencia de enfermedades en las poblaciones: la epidemiología genética o epidemiología genómica.
La epidemiología genómica es una subdisciplina de la epidemiología cuyo axioma fundamental es que la mutua interacción entre factores genéticos y entre factores genéticos y ambientales -estilos de vida, agentes sociales, físicos, químicos y biológicos- es la causa de las enfermedades humanas. ]]>
Los enfoques metodológicos que incorpora provienen de la genómica y se basan en la extracción, genotipado y secuenciación de ADN y ARNm de los individuos que forman parte de los estudios epidemiológicos. Las técnicas asociadas se soportan en un sofisticado y complejo instrumental de laboratorio que permite la generación de ingentes cantidades de datos genéticos, pero que también, plantea serios problemas de gestión y análisis.
La epidemiología genómica, aunque no surgió directamente como resultado de la realización "Genoma Humano", se enriqueció significativamente con los datos aportados por este proyecto, debido a la posibilidad de estudiar directamente las variaciones en el ADN de cada uno de los individuos.
A partir de este momento, adquirió la disciplina el calificativo "molecular". Aunque durante toda la década de los años 90, se utilizó la denominación de epidemiología genética y molecular, el avance y la posibilidad de detectar interacciones gen - ambiente, han hecho que, a principios del siglo XXI se prefiera la denominación de epidemiología genómica.
El futuro: la genómica funcional y la proteómica
Si la genómica estructural es la rama de la genómica orientada a la caracterización y localización de las secuencias que conforman el ADN de los genes, la genómica funcional consiste en la recolección sistemática de información sobre la función de los genes, mediante la aplicación de aproximaciones experimentales globales que evalúen la función de los genes a partir de la información y elementos de la genómica estructural.29
Con la genómica funcional, el objetivo es llenar el hueco existente entre el conocimiento de las secuencias de un gen y su función, para de esta manera develar el comportamiento de los sistemas biológicos. Se trata de expandir el alcance de la investigación biológica desde el estudio de genes individuales al estudio de todos los genes de una célula al mismo tiempo en un momento determinado.29 ]]>
La proteómica, por su parte, estudia los proteomas -un proteoma puede definirse como el conjunto de las proteínas expresadas por un genoma-, así como la genómica estudia los genomas. Configura una disciplina fundamental de la era post-genómica que trata de descubrir la constelación de proteínas que otorgan a las células su estructura y función. Distintas tecnologías permiten obtener y comparar "instantáneas" de las proteínas que se expresan en un momento determinado en una célula -robótica, electroforesis 2D, espectrometría de masas, chips, bioinformática.29
La proteómica puede definirse como la genómica funcional a nivel de las proteínas. Es la ciencia que correlaciona las proteínas con sus genes, estudia el conjunto completo de proteínas que pueden obtenerse de un genoma.30
Ella intenta caracterizar el conjunto de las proteínas -más de 200 000) que se expresan en una célula para una condición determinada o situación biológica.7
La proteómica intenta contestar preguntas como: ¿qué proteínas determinan los genes que existen en el genoma humano? y ¿qué función tienen las proteínas?30
Conocer el proteoma de un organismo es tener una imagen dinámica de todas las proteínas que expresa ese organismo, en un momento determinado y bajo condiciones concretas de tiempo y ambiente. Las células expresan varios miles de proteínas diferentes y cada una de ellas puede experimentar numerosas modificaciones en respuesta a microambientes diferentes.30 ]]>
Cuando un virus ataca una célula, ésta produce anticuerpos. Esos anticuerpos son proteínas. Esos anticuerpos sólo aparecen si hay virus. Lo mismo ocurre con otras condiciones como el calor, o el frío, o múltiples circunstancias distintas. Todas las proteínas que se producen en un momento determinado y bajo ciertas condiciones se llaman proteomas.30
La proteómica es parte esencial de la transición de la "Era genómica" a la "Era pos-genómica", en la que se analizarán y compararán los genomas, así como las relaciones existentes entre su estructura y función. Como sucedió con el genoma humano, la investigación posgenómica, sin dudas, se convertirá en una fuente de conocimientos con un enorme potencial de aplicación en el entorno clínico.13
Bioinformática7, 29
El análisis de un microconjunto (microarray) de ADN puede generar en un solo ensayo decenas de miles de datos sobre la actividad de los genes o sobre las diferentes mutaciones que presentan. Los estudios de farmacogenética tratan de asociar perfiles de mutaciones o polimorfismos de grupos poblacionales o individuos con la respuesta que estos presentan a la ingestión de un fármaco. Se calcula que el número de variaciones en una sola posición del ADN en el genoma humano podría superar los 4 millones -0,1% de diferencias genéticas entre diferentes individuos.
Nuevas aproximaciones experimentales como los chips de ADN o la proteómica y los métodos de investigación como la farmacogenética o la farmacogenómica abren nuevas vías de avance para la práctica sanitaria. Sin embargo, todos estos estudios generan indefectiblemente la necesidad de procesar grandes cantidades de información muy compleja.
En este caldo de cultivo, la bioinformática ha encontrado su nicho de desarrollo. ]]>
Ella ofrece modelos, métodos y técnicas a la comunidad investigadora para ordenar esta avalancha de datos y extraer conocimientos útiles al campo de la biomedicina. Los centros de investigación, la industria farmacéutica y las empresas biotecnológicas han realizado un gran esfuerzo para la adaptación a estos nuevos enfoques.
Y ante esta perspectiva, la comunidad de especialistas en informática médica ha asistido, un tanto perpleja, a esta explosión del interés generalizado por la bioinformática.
Los expertos en informática clínica miran hacia la genómica como una nueva fuente de datos a integrar en sus sistemas de información, pero carecen de los conceptos básicos de la biología molecular como para hacerlo con éxito. A su vez, los bioinformáticos amplían sus horizontes tratando de demostrar que todos los resultados logrados hasta la fecha pueden desembocar en aplicaciones médicas, pero resulta muy distinto aplicar la informática en la investigación biológica que aplicarla en la práctica clínica y, en muchos casos, desconocen las peculiaridades de este entorno.
Y sucede que, con el incremento en complejidad y capacidad, tanto de las computadoras como de las técnicas de investigación, se necesitan "puentes" humanos que puedan entrelazar ambas disciplinas y que sean capaces de comunicarse con los expertos de los dos campos. Históricamente, el uso de las computadoras para resolver cuestiones biológicas comenzó con el desarrollo de algoritmos y su aplicación al estudio de las interacciones de los procesos biológicos y las relaciones filogenéticas entre diversos organismos. El incremento exponencial en la cantidad de secuencias disponibles, así como la complejidad de las técnicas que emplean dichas computadoras para la adquisición y el análisis de los datos, han servido para la expansión de la bioinformática.
Ha llegado, por tanto, el momento de que ambas disciplinas se acerquen, colaboren e incluso desarrollen un nuevo tipo de aproximación, que hay quien denomina informática biomédica. En ella, se integrarían todos los niveles de información -desde la molécula hasta la población, pasando por la célula, el tejido, el órgano, el paciente y la propia enfermedad- y se aplicarían las técnicas y métodos más adecuados en cada caso, unas procedentes de la bioinformática, otras, de la informática clínica e incluso de la informática en salud pública y epidemiología. ]]>
El objetivo no es otro que el de procesar, de la manera más eficiente posible, toda la información procedente de la investigación biológica, clínica y medioambiental para avanzar en el desarrollo de la medicina molecular y de la medicina individual. Incluso, añadiría el concepto de medicina preventiva, en el sentido de practicar intervenciones sanitarias antes incluso de que aparezcan los síntomas de las enfermedades, debido a la posibilidad de predecir interacciones genotipo-medioambiente que podrían desembocar en fenotipos asociados a patologías.
Durante los últimos años, la bioinformática ha trabajado con muchas bases de datos que almacenaban información biológica en la medida que aparecía. Esto no sólo ha tenido efectos positivos: muchos científicos se quejan de la creciente complejidad que representa encontrar información útil en este "laberinto de datos". Para mejorar esta situación, se desarrollan técnicas que integran la información dispersa, gestionan bases de datos distribuidas, las seleccionan automáticamente, evalúan su calidad y facilitan su accesibilidad a los investigadores.
Integración es la palabra clave para entender la importancia de la bioinformática, porque con el auxilio de las herramientas y el uso de la información depositada en las bases de datos alrededor del mundo, se han iniciado el proceso de descubrir relaciones no triviales escondidas en el código de la vida.
Y la bioinformática, entonces, ha comenzado a ocupar un lugar central como "puente" que une a diversas áreas de la ciencia como son: la enzimología, la genética, la biología estructural, la medicina, la morfología y la ecología entre muchos otros. La pregunta crítica es ¿cómo conseguir las relaciones importantes entre tanta información? Esta pregunta y muchos otros problemas biológicos pueden responderse por medio de la bioinformática, que une o relaciona toda la información que esta depositada en las bases de datos por medio de asociaciones con los genes.
El repertorio de genes expresados y su patrón de actividad temporal gobiernan los procesos celulares. Se necesitan herramientas para gestionar información genética en paralelo. Para ello, se emplean nuevas tecnologías para extracción de conocimiento, minería de datos y visualización. Se aplican técnicas de descubrimiento de conocimiento a problemas biológicos como el análisis de los datos del genoma y el proteoma. La bioinformática, en este sentido, ofrece la capacidad de comparar y relacionar la información genética con una finalidad deductiva, y es capaz de ofrecer respuestas que no parecen obvias a la vista de los resultados de los experimentos. Todas estas tecnologías están justificadas por la necesidad de tratar información masiva, no individual, sino desde enfoques celulares integrados -genómica funcional, proteómica, expresión multigénica, etcétera.
Antecedentes históricos 7,29 ]]>
No se puede tratar la historia de la bioinformática sin tocar inicialmente la historia de la biología. En realidad son los biólogos y los bioquímicos quienes hacen su primer acercamiento a la tecnología computacional en busca de nuevas herramientas para su trabajo diario.
Desde los siglos XVIII y XIX, los biólogos se enfrentaron a problemas relacionados con el procesamiento masivo de la información. Darwin, por ejemplo en su viaje en el Beagle, recolectó y procesó manualmente multitud de datos sobre las especies. En aquellos tiempos, los taxonomistas catalogaron más de 50.000 plantas.
El desarrollo de la genética con la formulación de las Leyes de Mendel hace más de 100 años y el descubrimiento de la estructura del ADN en 1953, abrieron las puertas de la investigación que desembocó en el proyecto "Genoma humano" en el año 1990. Desde los años 60, el crecimiento en el número de secuencias conocidas de aminoácidos de las proteínas impulsó la aplicación pionera de las computadoras en biología molecular.
El desarrollo de la genética como una disciplina científica, basada en claros principios como las Leyes de Mendel y el descubrimiento de la estructura del ADN condujo a nuevas investigaciones que crearon un volumen enorme de información que era necesario guardar y analizar. Así, al principio de los años 60, el número creciente de secuencias de aminoácidos era uno de los factores principales que contribuyó al desarrollo de la biología computacional.
La cantidad de datos que debían analizarse y la mejora del rendimiento, y los precios más asequibles de las computadoras, hicieron posible su introducción en los ambientes biológicos y académicos. ]]>
La tecnología proporciona las herramientas prácticas para que los científicos puedan explorar las proteínas y el ADN. Estas son moléculas grandes que consisten de un encadenamiento de residuos más pequeños llamados aminoácidos y nucleótidos respectivamente. Son bloques del edificio de la naturaleza, pero estos bloques no se utilizan exactamente como los ladrillos, la función de la molécula final depende fuertemente del orden de estos bloques. La estructura (tridimensional) 3D de una proteína depende de la secuencia individual de estos residuos numerados. El orden de aminoácidos de una proteína específica se deriva del ADN correspondiente. Este pedazo de ADN consiste en una secuencia ordenada de nucleótidos.
Paralelamente, una perspectiva científica surge en los años sesenta, con la idea de que la genética podría estudiarse considerando la codificación, almacenamiento y el flujo de información entre las moléculas. Esta perspectiva queda en el origen de la disciplina conocida como biología computacional. Según este punto de vista, las proteínas llevarían información codificada en las sucesiones lineales de aminoácidos. Algunos acercamientos pioneros trataban de unir la teoría de información, teorías matemáticas y genéticas durante los años cuarenta en torno a los enfoques de la cibernética. Por ejemplo, Claude Shannon, el padre de la teoría de información desarrolló una metáfora algebraica para modelar el código genético.
Durante los últimos 20 años, se ha determinado que muchas proteínas de diverso origen pero con una función similar, también tienen secuencias similares de aminoácidos. Así, existen las secuencias correspondientes del DNA que son similares aunque la proteína bajo análisis aparezca en diversas especies como ratones y seres humanos.
La idea de considerar a las proteínas como moléculas portadoras de información se basa en tres aspectos. Primero, el código genético muestra cómo una sucesión de nucleótidos puede transformarse en una sucesión de aminoácidos. Segundo, la información molecular en una sucesión de aminoácidos determina la estructura espacial tridimensional de las proteínas. Tercero, la información en el ADN también determina la función de las proteínas. En 1965, Zuckerland y Pauling sugirieron que las proteínas y los ácidos nucleicos también portan información evolutiva que puede ayudar a responder algunas cuestiones científicas clásicas en biología.
En esta década también, aparecieron los primeros signos de una convergencia entre la biología, bioquímica, ingeniería e informática que conduciría después al nacimiento de la Bioinformática. No obstante, el uso de las computadoras para la investigación biológica durante estos años no se reconocía como un elemento importante para la investigación en el laboratorio. El campo de la bioinformática se necesitaba un liderazgo y una financiación, similar al que comenzaba a gestarse al mismo tiempo por los profesionales de la informática médica. Después, algunos investigadores mostraron que las computadoras podían acelerar dramáticamente la secuenciación y la determinación de estructuras de la proteína. Los métodos informatizados para la secuenciación del ADN empezaron a aparecer y los primeros bancos de datos de secuencias de proteína se hicieron presentes. También, se emplearon técnicas computacionales para predecir la estructura secundaria del ARN. ]]>
Con un acercamiento diferente, basado en inteligencia artificial, el Premio Nóbel Lederberg y otros pioneros de esta área como Feigenbaum y Buchanan, desarrollaron los primeros sistemas expertos.
Hacia finales de los años 80, comenzó a emplearse el término bioinformática, aunque algunos pioneros habían aplicado las computadoras con éxito a los problemas de la biología molecular, incluso una década antes de que fuera posible la secuenciación del ADN. Entre estas aplicaciones, Margaret Dayhoff desarrolló los primeros programas para determinar la secuencia de aminoácidos de una proteína en 1965 y preparó el primer banco de datos de secuencias de proteínas que luego evolucionó para convertirse en PIR (Protein Information Resource) en 1983. Los programas de comparación de secuencias y de análisis filogenético fueron algunos de los primeros avances en este campo alrededor de los años 60.
Incluso, el análisis estructural de las macromoléculas se inició por esos años, aunque limitado por las capacidades de la informática disponible en ese momento. A comienzos de los años 70, esos métodos se aplicaron al procesamiento de información sobre ácidos nucleicos. Entonces, se diseñaron programas para comparar secuencias. FASTA se desarrolló en 1985 aunque Genbank, el banco de datos de secuencias de ADN central se crea en 1980 y SwissProt, su homólogo para las proteínas empezó su actividad en 1987.
Hacia finales de los años 80, se desarrollaron programas bioinformáticos en los centros académicos que rápidamente se convirtieron en productos comerciales, y se comenzaron a distribuir como paquetes integrados de herramientas para la administración de datos en el campo de la biología molecular. Las mejoras en los sistemas computacionales permitieron el avance de las técnicas de aprendizaje automático con clara aplicabilidad en bioinformática. Se aplicaron redes de neuronas artificiales, modelos de Markov ocultos o métodos de clustering para analizar los conjuntos de datos no caracterizados.
Otro hito importante fue el desarrollo del WWW, como un medio universal para acceder a bases de datos biológicas y programas bioinformáticos. Esto permitió el desarrollo de muchas bases en las que los investigadores pueden encontrar la información que requiere su trabajo experimental. El WWW también es la infraestructura que soporta al intercambio activo de información entre investigadores. ]]>
A finales de los años 90, la demanda de especialistas en bioinformática era notable; sin embargo, sólo un pequeño grupo de universidades ofrecía programas educativos en este tema.
Hoy, algunos de los problemas más importantes de la biología moderna y la genómica son imposibles de resolver sin el poder del cálculo de las computadoras. Los programas de búsqueda y anotación de genes fueron muy importantes para el completamiento del proyecto "Genoma humano". El número de estructuras de proteína resueltas se dobla cada dos años. Las técnicas como la comparación de pares de secuencias biológicas, alineación múltiple, análisis filogenético o búsquedas por similitud en bases de datos por medio del web, facilitan el trabajo de los biólogos ocupados en tareas de identificación de genes o en la predicción de su estructura y función. La bioinformática suscita una atención creciente durante los últimos años, directamente unida al avance del mencionado proyecto.
Definición, estructura disciplinaria y búsqueda de la información
El término bioinformática comenzó a emplearse durante los finales de la década de los años 80's y los inicios de los 90s, aunque las aplicaciones de las tecnologías de la información en las ciencias biomédicas se iniciaron muchos años antes.7
La Bioinformática es una disciplina emergente que utiliza las tecnologías de la información para captar, organizar, analizar y distribuir información biológica con el propósito de responder preguntas complejas en biología. Es un área de investigación multidisciplinaria, que puede definirse como la interfase entre dos ciencias: la biología y la computación, impulsada por la incógnita del genoma humano y la promesa de una nueva era en la que la investigación genómica puede ayudar dramáticamente a mejorar la condición y la calidad de la vida humana.29
La bioinformática se ocupa del tratamiento de los datos en el campo de las biociencias moleculares -biología molecular, bioquímica, medicina y biotecnología. Es el resultado de la convergencia de la informática con la bioquímica, la genética, la biotecnología, la biología molecular, etcétera. En este sentido, la bioinformática posibilita una valoración cada vez más integrada de estos datos a partir de las diferentes esferas y con ello, acelera los procesos de investigación en los campos de la biología, la biotecnología y la medicina.14 ]]>
Según la definición del Centro Nacional para la Información Biotecnológica "National Center for Biotechnology Information" -NCBI por sus siglas en inglés: la Bioinformática es un campo de la ciencia en el que confluyen varias disciplinas como son: la biología, la computación y las tecnologías de la información. Su fin último es facilitar el descubrimiento de nuevos conocimientos y el desarrollo de perspectivas globales a partir de las cuales puedan discernirse principios unificadores en el campo de la biología.29
La bioinformática, por tanto, se ocupa de "…la adquisición, almacenamiento, procesamiento, distribución, análisis e interpretación de información biológica, mediante la aplicación de técnicas y herramientas procedentes de las matemáticas, la biología y la informática, con el propósito de comprender el significado biológico de una gran variedad de datos".31
Al comienzo de la "revolución genómica", el concepto de bioinformática se refería sólo a la creación y mantenimiento de base de datos donde se almacenaba información biológica, como son las secuencias de nucleótidos y aminoácidos. El desarrollo de este tipo de base de datos no sólo significaba su diseño sino también el desarrollo de interfaces complejas donde los investigadores pudieran acceder los datos existentes y suministrar o revisar datos.29
Luego toda esa información debía combinarse para formar una idea lógica de las actividades celulares normales, de tal manera que los investigadores pudieran estudiar cómo estas actividades se veían alteradas durante los estados de una enfermedad. De ahí surgió el campo de la bioinformática y ahora el área más popular es el análisis e interpretación de varios tipos de datos, incluidas las secuencias de nucleótidos y aminoácidos, los dominios de proteínas y su estructura.29
La bioinformática es una disciplina científica independiente que proporciona las herramientas y recursos necesarios para favorecer la investigación biomédica. Es la ciencia en la que la biología y la informática convergen y emergen como una única disciplina.31 ]]>
La bioinformática comprende tres subespecialidades: 31
- Bioinformática propiamente dicha, que abarca la investigación y desarrollo de la infraestructura y de los sistemas de información y comunicación que requiere la biología moderna -redes y bases de datos para el genoma, estaciones de trabajo para procesamiento de imágenes, etcétera.
Entre sus áreas de interés, se encuentran: (1) la administración de datos en el laboratorio; (2) la adquisición de datos y descifrado; (3) la alineación y ensamblaje de secuencias, (4) la predicción de dominios funcionales en las secuencias del genoma, (5) la búsqueda en bases de datos de estructuras, (6) la determinación y predicción de estructuras macromoleculares, (7) la construcción de árboles filogenéticos, (8) las bases de datos compartidas y (9) la robótica aplicada a tareas relacionadas con el mapeo y secuenciación de ADN.7
- Biología Computacional, que comprende la computación aplicada a la comprensión de las cuestiones biológicas básicas, a partir de la modelación y simulación -sistemas de vida artificial, algoritmos genéticos, redes de neuronas artificiales.7
]]>
- Biocomputación, que incluye el desarrollo y utilización de sistemas computacionales basados en modelos y materiales biológicos -biochips, biosensores, computación basada en ADN, entre otros. Las computadoras basadas en DNA se están empleando para la secuenciación masiva y el pesquisaje de diversas enfermedades, a partir de la explotación del procesamiento paralelo implícito.11
- El desarrollo e implementación de herramientas que permitan el acceso, uso y manejo de varios tipos de información.
]]>
La creación de nuevos algoritmos -fórmulas matemáticas- y estadísticos con los que se pueden relacionar partes de un conjunto enorme de datos como, por ejemplo, métodos para localizar un gen dentro de una secuencia, predecir la estructura o función de distintas proteínas y agrupar secuencias de proteínas en familias relacionadas.29 - Ser capaz de descubrir información oculta.
]]>
La información debe ser de gran utilidad para tomar decisiones importantes - La información se obtiene de grandes volúmenes de datos, donde existe mucha información.
- Ese conocimiento debe presentarse de una forma que se pueda entender sin un esfuerzo excesivo.
- Descubrir distintos comportamientos de una misma patología.
- Realizar pronósticos ajustados a cada paciente.
- Predecir las patologías que pueden aparecer como complicación de una enfermedad determinada.
- Encontrar la predisposición a padecer determinadas enfermedades.
- Descubrir asociaciones entre patologías. ]]>
- Determinar el mejor tratamiento individual para cada paciente.
- Sistema de apoyo al diagnóstico.
- Descubrir nuevas características de una patología.
- Comparación entre parámetros clínicos.
- la bioinformática, que es un campo interdisciplinario que se encuentra en la intersección entre las ciencias de la vida y de la información, y que proporciona herramientas y recursos necesarios para facilitar la investigación biomédica. ]]>
- la informática médica, que es el campo de la ciencia de la información que se ocupa del análisis y la diseminación de datos médicos mediante diferentes aplicaciones informáticas sobre aspectos del cuidado de la salud y medicina (figura 1).
Si bien la bioinformática puede definirse como la disciplina científica que se ocupa de la adquisición, procesamiento, almacenamiento, distribución, análisis e interpretación de datos e información biológica por medio de métodos y herramientas informáticas, la Biología Computacional, por su parte, atiende las simulaciones y la modelación matemática de los procesos biológicos, aunque en los últimos años la frontera entre estas disciplinas se ha hecho borrosa, como resultado de la disponibilidad de técnicas de alto rendimiento.7
En la bioinformática y la biocomputación, existen otras áreas importantes:
Finalmente, los adelantos en las tecnologías genómicas han atraído la atención hacia el procesamiento de cantidades masivas de datos procedentes de los estudios realizados en materia de genómica funcional, proteómica o variación genética humana, que aportan nuevas materias primas para analizar -perfiles de expresión génica, datos de la espectrometría de masas, polimorfismos, etcétera- y que abren grandes desafíos relacionados con la distribución e integración de todos estos datos.7
La minería de datos (DataMining) 4
La minería de datos es el proceso automatizado de descubrir información desconocida (oculta), y de presentarla en una forma que se pueda comprender, a partir de grandes volúmenes de datos, útil para toma de decisiones críticas. Así, los puntos críticos que definen un sistema de minería de datos son:
Estas nuevas técnicas se apoyan principalmente en algoritmos matemáticos, y en consecuencia genéticos, así como en redes neuronales. La minería de datos, al contrario del análisis de datos estadístico tradicional, trabaja sobre la totalidad de los datos y no con una muestra por lo que los resultados tienen una fiabilidad muy superior, ello que permite tomar decisiones con mucho menos riesgo de cometer errores.
Una vez construido el almacén de datos (data warehouse) se trata de descubrir el conocimiento oculto en los datos y que aporta información muy valiosa sobre las enfermedades y su tratamiento. Es muy importante señalar que estos sistemas no utilizan la información reseñada en la documentación científica, sino que aprenden de los datos que registra la comunidad hospitalaria en su almacén de datos. De esta forma, no se está sujeto a estudios estadísticos incompletos o realizados sobre poblaciones muy diferentes a las existentes en el entorno propio. Así, los resultados obtenidos se pueden aplicar con una fiabilidad absoluta. Algunas aplicaciones de las soluciones de minería de datos pueden ser: ]]>
La informática, la medicina y la genómica
Cuando se interrelacionan la informática, la medicina y la genómica dan lugar a:31
- la medicina molecular, que es el producto de la convergencia entre la medicina y la genómica, y que es el resultado de múltiples avances en la genética, la genómica y la posgenómica, aplicadas a la medicina. Esta nueva área promete el desarrollo de nuevas soluciones diagnósticas y terapéuticas basadas en un conocimiento mejorado de las causas moleculares de las enfermedades y adaptadas a los rasgos genéticos de los pacientes.7
La medicina molecular y la biotecnología constituyen dos áreas fuertes de desarrollo e innovación tecnológica. El progreso de una se encuentra estrechamente relacionado con el crecimiento de la otra. En ambas áreas, se pretende potenciar la investigación genómica y posgenómica, así como la Bioinformática, como herramienta imprescindible para el avance de estas. Debido al extraordinario avance de la genética molecular y la genómica, la Medicina Molecular se configura como un arma estratégica del bienestar social en el futuro inmediato. Se pretende potenciar la aplicación de las nuevas tecnologías y de los avances genéticos para el beneficio de la salud.29
La identificación de las causas moleculares de las enfermedades junto con el desarrollo de la industria biotecnológica en general y de la farmacéutica en particular permitirán el desarrollo de mejores métodos de diagnóstico, la identificación de dianas terapéuticas y el desarrollo de fármacos personalizados, así como una mejor medicina preventiva.29
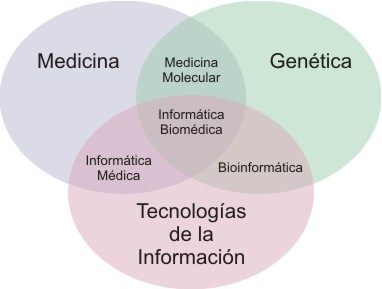
Fig. 1. La informática, la medicina y la genómica.29
Las tres disciplinas han comenzado a acercarse y, en el futuro, su interacción deberá ser más estrecha, si se desea responder a las demandas que surgirán de la medicina molecular y la asistencia sanitaria individualizada. Convergencia que originará una nueva disciplina, denominada "informática biomédica", que comprende enfoques integrados para el procesamiento de la información relacionada con las enfermedades. Parece apropiado pensar que, para comprender las causas de las enfermedades y avanzar en la puesta a punto de sistemas diagnósticos y terapéuticos más eficientes, seguros y adaptados a las peculiaridades de los pacientes, será necesario gestionar y analizar información compleja, multinivel, que va desde el genotipo (bioinformática) hasta el fenotipo (informática médica) y que incorpora también, factores ambientales -informática en salud pública, informática en farmacia.31
Bioinformática e informática médica 32 ]]>
La Informática Médica puede definirse como la disciplina que trata los aspectos teóricos y prácticos relacionados con el procesamiento y la comunicación eficiente de información sobre salud. Su evolución responderá, entre otros factores, a las necesidades de una medicina individualizada, a la carta o centrada en el paciente y a un avance tecnológico sin precedentes.
La computación móvil y la comunicación sin hilos, la integración de la telefonía e Internet, el desarrollo de ordenadores embebidos en dispositivos médicos, la aparición de nuevas interfaz con voz en lenguaje natural, el establecimiento de una nueva generación de Internet con una alta calidad de servicio, la generalización de aplicaciones multimedia interactivas sobre redes de banda ancha, o el diagnóstico por imagen avanzado, aplicado en sistemas virtuales para la realización de intervenciones asistidas mediante neuronavegación y de sistemas de planificación, simulación de cirugía y radiación asistida por imágenes, el progreso de la robótica en la cirugía, así como el crecimiento de los sistemas diagnósticos basados en nanotecnología, la ingeniería microelectrónica, la creación de tarjetas personales inteligentes, dispensadores automáticos de medicamentos y de nuevos sensores y biochips para obtener información bioquímica o genética de forma rápida y costo-efectiva, entre otros muchos avances propondrán un panorama realmente revolucionario en el entorno clínico del futuro.
Pero el futuro no sólo deparará nuevas tecnologías; también afectará a la propia definición de la informática médica como especialidad. En la medida que el conocimiento se profundice y aumente su complejidad, se asistirá al nacimiento de nuevas subespecialidades, como informática del cáncer o informática en salud pública.
En la medida que se engrana la información sobre los genes con la información sobre las enfermedades, se asiste a una convergencia de la informática clínica con la bioinformática, que se reflejará, en el futuro cercano, en la introducción de datos genéticos en la historia clínica de los pacientes o en nuevos sistemas de apoyo a la toma de decisiones para el diagnóstico y la terapia, entre otras áreas.
La informática deberá responder a la necesidad de gestionar distintos niveles de información sobre salud: repositorios de información molecular sobre causas genéticas de las enfermedades, registros sobre las características y diferencias genéticas entre los pacientes, datos personales de salud y la historia clínica virtual, fuentes de información médica de interés, así como bases de datos sobre enfermedades con información para la práctica, ensayos clínicos y bases de conocimiento sanitario globales desagregables por niveles -regional, nacional o internacional- con información poblacional, epidemiológica y relacionada con factores medioambientales, indicadores de salud, etcétera.
Todos los ciudadanos dispondrán de su registro de salud multimedia con información clínica, genética y sobre su estilo de vida.
El registro individual de salud se encontrará distribuido, el lugar físico de almacenamiento de sus datos de salud será transparente para el paciente. Su historia clínica se enriquecerá constantemente con los nuevos resultados procedentes de las investigaciones realizadas en los marcos de la medicina basada en la evidencia.
En el futuro, se asistirá a una revolución basada en las tecnologías que posibilitará la medicina a la carta o individualizada, en la que el paciente participe en la toma de decisiones y tenga acceso a un tratamiento de alta calidad, adaptado a sus características individuales, peculiaridades de su desarrollo y condiciones del entorno.
En busca de la madurez: obstáculos y progresos 7
Tanto la informática médica como la bioinformática se enfrentan a grandes problemas para conseguir el reconocimiento académico y profesional. Los científicos de la computación consideran que la informática aplicada es sólo una rama de un tronco común que soporta todas las teorías y los logros científicos. Según esta visión, ambas son simplemente aplicaciones de la informática a la medicina y la biología, respectivamente. Para muchos médicos, los informáticos médicos son profesionales de la tecnología que construyen software y bases de datos para ayudarlos en su práctica habitual. Un argumento similar puede explicar la relación entre biólogos y bioinformáticos.
Durante las dos últimas décadas, ha existido un continuo debate sobre el carácter de ciencia independiente de la informática médica. Este es un tema recurrente en las revistas especializadas y cada cierto tiempo vuelven a aparecer artículos que exponen que ella no es sólo una disciplina de apoyo y que posee una entidad científica propia. Algo parecido sucede con la bioinformática en los últimos años. La razón de esta insistencia es clara. Los profesionales de ambas disciplinas sienten que necesitan demostrar que sus especialidades son disciplinas científicas establecidas, que merecen reconocimiento académico y profesional. Sólo así, pueden lograrse programas universitarios, laboratorios independientes, mecanismos propios de financiación y el desarrollo de verdaderas carreras profesionales dentro de los departamentos tradicionales de biología, medicina o informática.
La obtención del genoma humano y la aparición de la medicina molecular han generado cambios en las comunidades de ambas disciplinas. Por un lado, los bioinformáticos tienen un enorme campo de aplicación. Por otro, los informáticos médicos diseñan una nueva agenda de investigación. Algunas actividades recientes enfatizan la necesidad de una colaboración entre ambas disciplinas para potenciar los enfoques de la medicina personalizada. Se podría crear una nueva área interdisciplinaria entre estas especialidades. La última podría aportar su foco y resultados en la gestión y la modelación de la información a nivel molecular, mientras que la primera puede proporcionar su experiencia en el desarrollo de aplicaciones clínicas.
Además, se podrían evitar episodios de "reinvención de la rueda" y de fracasos a la hora del uso rutinario en la práctica clínica, debidos a la resistencia de los médicos a la hora de incorporar ciertos sistemas informáticos y a la complejidad intrínseca al uso de la información clínica. Se necesita una nueva batería de desarrollos de software para transferir al entorno clínico, la enorme cantidad de datos que los investigadores de la genética obtienen en sus laboratorios. Los médicos tendrán que acostumbrarse a manejar un nuevo tipo de información, con características especiales.
Así, no sólo necesitarán métodos para buscar, acceder y recuperar información genética, sino también, métodos para reunir, clasificar e interpretar este tipo de datos.
Por ello, podrían aparecer sinergias entre ambas disciplinas, que complementen las carencias y problemas que individualmente presentan. Esta interacción podría tener un enorme impacto en la práctica de la medicina del futuro.
Producción científica sobre bioinformática en el Web of Science: una aproximación informétrica ]]>
Entre el 1ro de enero del 2000 y el 15 de marzo del 2004, se registraron 2 090 artículos de investigación en el Web of Science. Ellos se publicaron en 748 revistas de 38 países.
Entre los artículos recuperados, 1 972 presentaron el campo "Author Adress" con sus datos completos. El análisis de este campo permitió identificar un total de 55 países que publicaron al menos un artículo sobre el tema estudiado en el Web of Science.
Un total de 229 de los 1 972 artículos analizados fueron el producto de la colaboración entre varios países: 188 entre dos países y 41 entre tres o más países.
Un pequeño grupo de países, integrado por Estados Unidos, el Reino Unido, Alemania y Japón, generaron el 64,7 % de los artículos. China fue el quinto y último país con un aporte de 100 o más de artículos (tabla 1).
Tabla 1. Productividad según países en Web of Science, 2000-2004.
| País | No de artículos | ]]> Sin colaboración extranjera | Con colaboración extranjera | Con primer autor nacional |
| Estados Unidos | 880 | 740 | 140 | 806 |
| Reino Unido | 263 | 206 | 57 | ]]> 235 |
| Alemania | 136 | 102 | 34 | 115 |
| Japón | 132 | 113 | 19 | 120 |
| China | 100 | ]]> 83 | 17 | 91 |
| Francia | 87 | 67 | 20 | 77 |
| Canadá | 65 | 38 | 27 | ]]> 52 |
| Suecia | 53 | 38 | 15 | 45 |
| Australia | 51 | 32 | 19 | 39 |
| Italia | 43 | ]]> 25 | 18 | 33 |
| Suiza | 42 | 25 | 17 | 31 |
| India | 37 | 28 | 9 | ]]> 28 |
| España | 33 | 18 | 15 | 22 |
| Holanda | 33 | 25 | 8 | 27 |
| Brasil | 25 | ]]> 17 | 8 | 24 |
| Israel | 25 | 21 | 4 | 22 |
| Singapur | 25 | 13 | 12 | ]]> 21 |
| Dinamarca | 24 | 16 | 8 | 19 |
| Bélgica | 23 | 15 | 8 | 17 |
| Rusia | 21 | ]]> 11 | 10 | 13 |
| Taiwan | 21 | 16 | 5 | 19 |
| Corea del Sur | 20 | 19 | 1 | ]]> 20 |
Total de artículos analizados: 1972
Colaboraciones internacionales: 229
Un análisis por continentes permitió comprobar, como es habitual, la supremacía de América del Norte y Europa sobre el resto del mundo. En conjunto, ellos generaron el 80 % de los artículos.33 Estados Unidos fue el país con mayor productividad científica, mientras que por el bloque europeo, el Reino Unido, Alemania, Francia, Suecia, Italia, Suiza, España y Holanda lideraron en la región. El continente asiático estuvo representado por 13 países que produjeron el 17 % de las contribuciones. Países como Japón, la República Popular China, la India, Israel, Singapur, Taiwan y Corea del Sur se ubicaron entre los más productividad. Australia, América Latina y Africa produjeron el 3 % restante (figura 2).
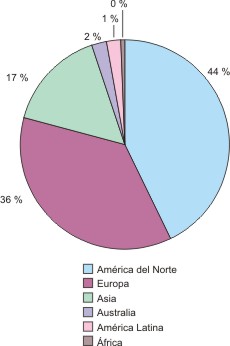
Fig. 2. Producción científica de artículos sobre bioinformática en el Web of Science, según continentes, 2000-2004.
La región latinoamericana estuvo representada por siete países, aunque sólo Brasil aportó 25 trabajos, para situarse entre los 15 primeros países productores de artículos sobre bioinformática. México con tres artículos, Cuba y Uruguay con dos cada uno y Argentina, Chile y Puerto Rico con uno, también aparecen en este bloque, el cual produjo de forma individual, es decir, con la participación sólo de autores de la región, 19 de los 28 artículos generados por el continente, 17 de ellos proceden de Brasil y los dos restantes de Chile y Cuba.
El análisis del volumen de la producción científica sobre bioinformática por años en el período estudiado, muestra un crecimiento lineal, que denota el momento de avance y expansión que experimenta esta nueva disciplina (figura 3).
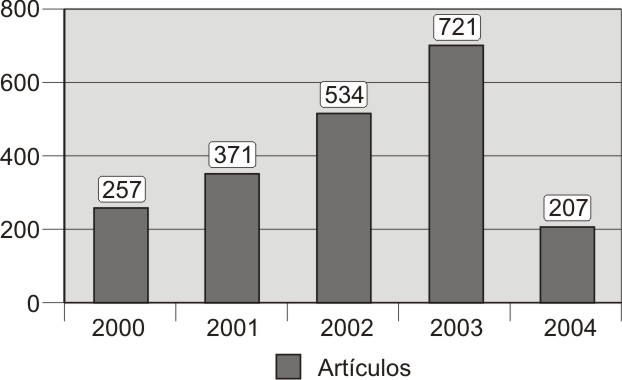
Fig. 3. Comportamiento anual de la producción científica sobre bioinformática en el Web of Science, 2000-2004.
El núcleo de publicaciones seriadas con una mayor producción de artículos sobre bioinformática, según el modelo de Bradford, quedó conformado por 14 títulos, que publicaron el 25 % del total de los artículos considerados; las más destacadas fueron las revistas británicas "Bioinformatics" y "Nucleic Acids Research" y la "International Journal of Molecular Medicine", publicada en los Estados Unidos (Tabla 2).
Tabla 2. Publicaciones seriadas con mayor cantidad de artículos publicados sobre bioinformática, 2000-2004.
| Título | ]]> No artículos | País |
| Bioinformatics | 105 | UK |
| Nucleic Acids Research | 73 | UK |
| International Journal of Molecular Medicine | 40 | USA |
| International Journal of Oncology | 39 | GRE |
| Journal of Molecular Biology | ]]> 38 | USA |
| Comparative and Functional Genomics | 37 | UK |
| Proteomics | 28 | ALE |
| Abstracts of Papers of the American Chemical Society | 26 | USA |
| Genetic Engineering News | 25 | USA |
| Proceedings of the National Academy of Sciences of the United States of America | ]]> 24 | USA |
| Progress in Biochemistry and Biophysics | 23 | CHIN |
| Protein Science | 23 | USA |
| Drug Discovery Today | 21 | UK |
| Proteins-Structure Function and Genetics | 21 | USA |
La presente contribución se inscribe en el esfuerzo que realiza el Centro Nacional de Investigaciones Científicas (CNIC) por generalizar el uso del ProCite en el desarrollo de servicios de alto valor agregado.34
Referencias bibliográficas
1. Wikipedia [en línea]. Disponible en: http://es.wikipedia.org/wiki/Biolog%C3%ADa [Consultado: 1 de octubre del 2004].
2. Wikipedia [en línea]. Disponible en: http://es.wikipedia.org/wiki/Bioqu%C3%ADmica [Consultado: 1 de octubre del 2004].
3. Mathews CK, Holde KE, Ahern KG. Biochemestry. 3 era. ed. San Francisco: Addison Wesley Longman Inc., 1999. p. 84-357.
4. Joyanes Aguilar DL. La bioinformática como convergencia de la biotecnología y la informática. Disponible en: http://leonxiii.upsam.net/sem-pensamiento/01_biotec/web_ljoyanes.pdf [Consultado: 24 de septiembre del 2004].
5. Wikipedia [en línea]. Disponible en: http://es.wikipedia.org/wiki/Biotecnolog%C3%ADa [Consultado: 18 de septiembre del 2004].
6. Wikipedia [en línea]. Disponible en: http://es.wikipedia.org/wiki/ADN [Consultado: 1 de octubre del 2004].
7. Martín Sánchez F, Maojo García V. La convergencia entre la Bioinformática y la Informática Médica. I+S 2002;(38):25-31. Disponible en: http://www.seis.es/i_s/is38/is38_2.htm [Consultado: 5 de septiembre del 2004].
8. Wikipedia [en línea]. Disponible en: http://es.wikipedia.org/wiki/Genoma [Consultado: 3 de octubre del 2004].
9. Coltell O, Corella D. Aproximaciones desde la Bioinformática al tratamiento de información genética en investigaciones epidemiológicas. I+S 2002;(37):15-26. Disponible en: http://www.seis.es/i_s/is37/is37_3.htm [Consultado: 15 de septiembre del 2004].
http://www.ornl.gov/sci/techresources/Human_Genome/medicine/medicine.shtml [Consultado: 5 de septiembre del 2004].
11. Amgen. Bioinformática. Disponible en: http://biotec.amgen.es/cgi-bin/wdbcgi.exe/amgen/pak_biotec.muestradoc?p_item=6 [Consultado: 6 de septiembre del 2004].
12. Rivas M. Bioinformática. Disponible en: http://www.informaticamedica.org.ar/numero10/monografia2.htm [Consultado: 20 de septiembre del 2004].
13. Pelayo I, Carretero Vaquer T, Yarte del Toro A, Martín-Sánchez F. Genoma humano y bibliotecas en ciencias de la salud. Disponible en: http://216.239.59.104/search?q=cache:-28TljEDbeUJ:www.jornadasbibliosalud.net/comunicaciones/cc1.doc+La+convergencia+de+la+Bioinform%C3%A1tica+y+la+Inform%C3%A1tica&hl=es [Consultado: 10 de septiembre del 2004].
14. Schomburg A. Bioinformatik - auch ein Thema für Informationsfachleute? Information Wissenschaft und Praxis 2003;54(2):81-6.
15. Jiménez Sánchez G. Introducción a la medicina genómica. Disponible en:
http://www.inmegen.org.mx/Contenidos/curso_genomica/lineamientos.htm
[Consultado: 15 de septiembre del 2004].
16. Wikipedia [en línea]. Disponible en: http://es.wikipedia.org/wiki/Genoma [Consultado: 8 de septiembre del 2004].
17. Piédrola Gil G, Domínguez Carmona M, Cortina Greus P, Gálvez Vargas R, Sierra López A, Sáenz González RC, et.al. Medicina Preventiva y Salud Pública. 8va ed. Barcelona: Salvat, 1988.
18. Risser J, Risser W. Introduction to Clinical Epidemiology. Disponible en: http://ped1.med.uth.tmc.edu/neo/clinepi1.ppt [Consultado: 5 de octubre del 2004].
19. Wikipedia [en línea]. Disponible en: http://es.wikipedia.org/wiki/Epidemiolog%C3%Ada [Consultado: 6 de octubre del 2004].
20. Espinosa Brito A. ¿Epidemiología clínica o epidemiología para clínicos? Ateneo 2000;1(1):64-71. Disponible en: http://www.bvs.sld.cu/revistas/ate/vol1_1_00/ate11100.pdf [Consultado: 10 de septiembre del 2004].
21. López Sánchez J. Finlay, el hombre y la verdad científica. La Habana: Editorial Científico-Técnica, 1989.
22. Lorenzano C. La estructura teórica de la medicina y las ciencias sociales. En: Rodríguez MI. Lo biológico y lo social, su articulación en la formación del personal de salud. Washington: Organización Panamericana de la Salud, 1994. Serie Desarrollo de Recursos Humanos No. 101:35-62.
23. White KL. La epidemiología contemporánea: perspectivas y usos. En: Usos y perspectivas de la epidemiología. Documentos del Seminario sobre usos y perspectivas de la epidemiología. Buenos Aires (Argentina) 7-10 Noviembre, 1983. Washington: Organización Panamericana de la Salud, 1988. Publicación Científica No. PNSP 84-47: 211-20.
24. Rojas F. Estado de salud de la población: objeto y contenido de su estudio. Rev Cub Adm Salud 1982;8(1):39-50.
25. Espinosa D. La unicidad en la diversidad. En: La clínica a las puertas del siglo XXI. Primer encuentro: La conceptualización general. La Habana, Diciembre de 1995.
26. Spitzer WO. Clinical epidemiology (editorial). J Chron Dis 1986;39(6):411-5. en def epid clin determinantes.
27. Soriguer Escofet PJ. ¿Es la clínica una ciencia? Madrid: Díaz de Santos, 1993.
28. Smith LH. Medicine as an art. En: Cecil-Loeb. Textbook o f Medicine. 17 th ed. Philadelphia: WB Saunders, 1982. p xxxiii-xxxvii.
29. Zepeda García O. Bioinformática. Disponible en:
http://www.monografias.com/trabajos14/bioinforma/bioinforma.shtml [Consultado: 4 de septiembre del 2004].
30. Wikipedia [en línea]. Disponible en: http://es.wikipedia.org/wiki/Prote%C3%B3mica [Consultado: 15 de septiembre del 2004].
31. Bibgen. Introducción a la Bioinfomática. Disponible en:
http://bvs.isciii.es/bib-gen/Actividades/curso_virtual/Introduccion/bioinformatica.htm [Consultado: 12 de septiembre del 2004].
http://www.diariomedico.com/grandeshist/numero2000/telemedicina.html [Consultado: 8 de septiembre del 2004].
33. Perezleo Solorzano L, Arencibia Jorge R, Conill González C, Achón Veloz G, Araujo Ruíz JA. Impacto de la bioinformática en las ciencias biomédicas. ACIMED 2003;11(4) URL: http://bvs.sld.cu/revistas/aci/vol11_4_03/aci07403.htm
34. Arencibia Jorge R, Perezleo Solorzano L, Araujo Ruíz JA. Experiencias
preliminares del Centro Nacional de Investigaciones Científicas en el uso
del ProCite para la implementación de servicios de alto valor agregado.
ACIMED 2003;11(6) URL: http://bvs.sld.cu/revistas/aci/vol11_6_03/aci14603.htm
Recibido: 22 de noviembre del 2004. ]]>
Aprobado: 10 de diciembre del 2004.Lic. Rubén Cañedo Andalia
Red Telemática de Salud en Cuba (Infomed). Centro Nacional de Información de Ciencias Médicas. Calle 27 No. 110 entre N y M, El Vedado. C P 10 400, Ciudad de La Habana, Cuba. Correo electrónico: ruben@infomed.sld.cu
1Licenciado en Información Científico-Técnica y Bibliotecología. Red Telemática de Salud en Cuba (Infomed) Centro Nacional de Información de Ciencias Médicas.
2 Técnico Medio en Información Científico-Técnica y Bibliotecología. Centro Nacional de Investigaciones Científicas (CNIC).
Ficha de procesamiento
Clasificación: Artículo original.
¿Cómo citar esta contribución según el estilo Vancouver? ]]>
Cañedo Andalia R, Arencibia Jorge R. Bioinformática: en busca de los secretos moleculares de la vida. Acimed 2004;12(6). Disponible en: http://bvs.sld.cu/revistas/aci/vol12_6_04/aci02604.htm Consultado: día/mes/año.Términos sugeridos para la indización
Según DeCS 1
BIOLOGIA COMPUTACIONAL;INFORMATICA MEDICA;BIBLIOTECAS MEDICAS;BIBLIOTECA GENOMICA
COMPUTATIONAL BIOLOGY;MEDICAL INFORMATICS;LIBRARIES, MEDICAL;GENOMIC LIBRARY
Según DeCI 2
BIOMEDICINA/desarrollo;BIOMEDICINA/tecnologías;INFORMATICA MEDICA; IBLIOTECAS MEDICAS/tecnologías;BIBLIOTECARiOS/desarrollo;BIBLIOTECARIOS/habilidades;INFORMATICOS/desarrollo; INFORMETRIA
BIOMEDICINA/development;BIOMEDICINE/technologies;MEDICAL INFORMATICS;LIBRARIES, MEDICAL/technologies;LIBRARIANS/development;LIBRARIANS/skilfulness;COMPUTER SPECIALISTS/development; INFORMETRICS
1 BIREME. Descriptores en Ciencias de la Salud (DeCS). Sao Paulo: BIREME, 2004.
Disponible en: http://decs.bvs.br/E/homepagee.htm ]]>