Una combinación de KICA y filtrado EWMA-ED para la detección de fallos de pequeña magnitud en procesos químicos
A combination of KICA and filtering EWMA-ED proposed for detection of small magnitude fault in chemical processes.
José M. Bernal de Lázaro I, Alberto Prieto Moreno I, Diego Campos Knupp II, Antônio J. Silva Neto II
I Departamento de Automática y Computación de la Facultad de Ingeniería Eléctrica de la CUJAE, La Habana, Cuba. ]]> II Universidade do Estado do Rio de Janeiro UERJ, Brazil.
RESUMEN
La industria actual requiere de sistemas de diagnóstico de fallos, que en su etapa de detección garanticen pocas falsas alarmas y logren detectar por demás, los fallos con la mayor rapidez posible independientemente de su naturaleza y magnitud. Sin embargo, un problema de los enfoques de monitoreo de procesos mediante estadística multivariada (MSPM) que son utilizados con este propósito es la incapacidad de detectar fallos de pequeña magnitud sin incurrir en un elevado número de falsas alarmas, u omitir gran cantidad de fallos que deben ser detectados. Como solución a este problema, en el presente trabajo se propone un esquema de trabajo que combina las ventajas de los métodos kernel y un novedoso enfoque EWMA con dinámica reforzada para filtrar el estadístico T2 de Hotelling utilizado como mecanismo de detección en un proceso químico de gran escala.
Palabras claves: Detección de fallos, EWMA-ED, Filtrado de señales, Tennessee Eastman, T2 de Hotelling.
ABSTRACT
The current industry requires of the fault diagnostic systems with a detection stage that can ensure a small number of false alarms and a quick detection of faults, regardless of their nature and magnitude. However, a common problem of the approaches based on the Multivariate Statistical Process Monitoring (MSPM) which are currently used for this purpose is the difficulty of them to detect small magnitude faults without incurring a high number of false alarms, and faults not detected. To overcome this drawback, in this paper is proposed a novel approach that combines the advantages of kernel methods, and a novel EWMA with enhanced dynamic to filter the T2 Hotelling statistic used as the fault detection mechanism in a complex chemical process.
Key words: Fault detection, EWMA-ED, Signal filtering, Tennessee Eastman , Hotelling T2.
]]>
1.- INTRODUCCIÓN
Actualmente, en las industrias biofarmacéuticas, petroquímicas, y de producción de energía existe una marcada intención de mejorar el desempeño en los procesos, de producir con más calidad y de satisfacer las crecientes regulaciones medioambientales [1-3]. Sin embargo, en sistemas tecnológicos como éstos, que se caracterizan por una naturaleza compleja y multivariable, la presencia de fallos en equipos críticos puede tener un impacto desfavorable respecto a la disponibilidad de los procesos, la seguridad de los operadores y el medio ambiente. Según [4], un fallo puede definirse como una desviación no permitida de al menos una propiedad característica o variable de un sistema; de manera que éste ya no puede satisfacer la función para la cual fue diseñado. La aparición de estos fallos puede estar originada por diferentes causas, por ejemplo, debido al efecto de la temperatura, como resultado de desgastes por fricción mecánica, o por el bloqueo en las tuberías. Aunque también resulta común la aparición de fallos debido a desviaciones en los sensores, por la degradación de los catalizadores, y el envejecimiento de los componentes del sistema, entre otras muchas causas. Considerando su efecto, tales deterioros pueden ser reflejados de manera gradual o inmediata en el proceso, en sensores, actuadores, y controladores [4]. Es por ello que para garantizar que la operación de un sistema satisfaga las especificaciones de desempeño, los fallos necesitan ser detectados, aislados, y eliminados; tareas todas asociadas con los métodos de diagnóstico de fallos.
En este sentido, la tendencia de las investigaciones actuales va dirigida a integrar diferentes herramientas para brindar soluciones complementarias y mejorar el desempeño de los sistemas de diagnóstico de fallos. Cada día es más común que, dentro de la gran variedad de métodos dirigidos al diagnóstico de fallos, se potencien principalmente las técnicas y enfoques que permiten obtener sistemas de diagnóstico sensibles a fallos de pequeña magnitud, pero robustos ante ruidos e incertidumbres [5, 6]. La revisión realizada, sugiere que los sistemas de diagnóstico deben tener, al menos, tres componentes fundamentales. En primer lugar, un método basado en datos históricos y análisis de tendencias para detectar de manera rápida cualquier posible cambio en el proceso [7]. Esta característica resulta crucial en sistemas industriales complejos donde fallos de pequeña magnitud y/o lento desarrollo suelen ser enmascarados por la ocurrencia de otros fenómenos en el proceso. Como segundo aspecto, debe considerarse un método que permita la selección de atributos relevantes para reconocer las características discriminantes que identifican a cada uno de los estados de operación [4]. Entre los algoritmos que pueden aplicarse para lograr este objetivo, los métodos kernel resultan herramientas muy potentes dado que permiten manejar relaciones no lineales entre variables, y aplicar técnicas convencionales de clasificación, agrupamiento, y estimación de datos en una etapa posterior [8-11]. Como tercer aspecto es recomendable que los sistemas de diagnóstico de fallos tengan en cuenta el uso de herramientas discriminantes que, mediante un proceso de clasificación, permitan el aislamiento de los fallos [12-13]. Con ellos, de ser posible, pueden incorporarse simultáneamente algún método basado en conocimiento para proporcionar explicaciones y razonamientos causa-efecto a los operadores a fin de asistirlos con la toma de las decisiones asociadas a las tareas de diagnóstico y mantenimiento en el proceso.
En este contexto, la detección de los fallos es sin dudas, el primer y más importante paso dentro de las tareas de diagnóstico de fallos. La etapa de detección permite determinar cuándo ha ocurrido un comportamiento anormal en el proceso, y proporciona avisos sobre problemas emergentes, que permiten realizar acciones encaminadas a su solución [4,14]. La detección de comportamientos anómalos adquiere mayor importancia en sistemas críticos, y fundamentalmente en procesos donde la presencia de fallos de pequeña magnitud y/o lento desarrollo puede ser enmascarada por otros fenómenos. Sin embargo, un problema común de los enfoques de monitoreo de procesos mediante estadística multivariada (MSPM) utilizados actualmente con este propósito es su incapacidad de detectar fallos de pequeña magnitud sin incurrir en un elevado número de falsas alarmas, que en ocasiones, viene acompañado de gran cantidad de fallos no detectados [13,14].
Como solución a este problema, en el presente trabajo se propone un nuevo esquema de detección que es capaz de identificar correctamente la ocurrencia de comportamientos no permitidos en el proceso, fundamentalmente aquellos de pequeña magnitud. El mecanismo de detección propuesto combina las ventajas de los métodos kernel y de un enfoque EWMA con dinámica reforzada para filtrar el estadístico T2 de Hotelling que es utilizado como mecanismo de detección. Para evaluar la propuesta realizada se utilizan los datos obtenidos del proceso de prueba Tennessee Eastman (TEP). Además, todas las técnicas empleadas se ejecutan sobre MATLAB R2015a.
La estructura del trabajo es la siguiente, en la Sección 2 se describe el problema de prueba TEP. En la Sección 3 se presenta la propuesta de enfoque EWMA con dinámica mejorada. Posteriormente, en la Sección 4, se discuten las ventajas de combinar EWMA-ED con KICA, y se presenta un análisis del desempeño del enfoque propuesto para la detección de fallos en el caso de estudio TEP. Por último, se realizan las conclusiones.
2.- DESCRIPCIÓN DEL PROBLEMA DE PRUEBA
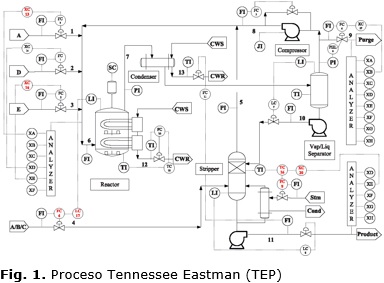
]]>El caso de estudio Tennessee Eastman (TEP) representa una planta química que la compañía Eastman Chemical desarrolló con el objetivo de evaluar nuevas técnicas de control de procesos y métodos de supervisión y diagnóstico [11,14,15]. Desde el punto de vista de la estructura del proceso, el TEP presenta cinco unidades de operación: un reactor, un condensador, un separador líquido-vapor, un compresor de reciclaje y una columna de destilación, que se interconectan como muestra la Figura 1.
Desde el punto de vista del diagnóstico de procesos, el TEP considera 21 posibles fallos pre-programados distribuidos en las zonas de alimentación y en torno al reactor y el condensador. Además, se cuenta con un conjunto de datos que caracterizan la operación normal (NOC, Normal Operating Condition) del mismo. En este proceso de prueba, los datos históricos son generados durante 48h y los fallos se introducen a partir de las 8h de funcionamiento continuo. Cada conjunto de datos contiene un total de 52 variables con tiempo de muestreo de 3 min y ruido Gausiano de bajo nivel incorporado en todas las mediciones [11].
Esto implica que los análisis que se realizan en este trabajo llevan incorporado un análisis de la robustez ante la presencia de ruido en las mediciones. Las simulaciones realizadas para generar los posibles fallos, utilizan el esquema de control para la planta completa descrito en [15], y todos los datos históricos correspondientes a dichos fallos pueden ser descargados de la web: web.mit.edu/braatzgroup/TE_process.zip.
Es importante señalar que a fin de evaluar la propuesta del presente trabajo, se seleccionaron del TEP los siete fallos más importantes que tienen lugar en los bloques de condensador-reactor, los mismos se muestran en la Tabla 1. Además, para garantizar la rapidez en la detección de los fallos, de los datos históricos sólo fueron consideradas aquellas variables cuya medición está disponibles en línea [14].
3.- EWMA CON DINÁMICA REFORZADA.
El enfoque EWMA convencional es un procedimiento que considera la dinámica del proceso como:
]]>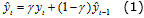
donde  es el valor estimado teniendo en cuenta el comportamiento dinámico anterior. El parámetro γ es una constante 0<γ≤1, que determina la profundidad de memoria o capacidad de olvido para la estrategia. Respecto al diagnóstico de procesos, EWMA ha sido ampliamente aplicada para mejorar la detección de fallos de pequeña magnitud [16]. En este sentido, y tal como plantea [4], los mejores resultados dentro de la detección con enfoques MSPM se encuentran en el uso de estrategias integradas donde se involucra la filosofía EWMA y los métodos kernel para filtrar los estadísticos SPE y T2 de Hotelling con el objetivo de detectar fallos pequeños y/o de lento desarrollo. Sin embargo, es importante señalar que en la práctica, lograr un ajuste adecuado del factor de memoria (γ), tal que se alcance una alta Tasa de Detección de Fallos (FDR, Fault Detection Rates) sin incrementar significativamente la Tasa de Falsas Alarmas (FAR, False Alarm Rates), es una tarea compleja. El enfoque EWMA con dinámica reforzada (EWMA-ED) propuesto en este trabajo mejora no sólo la detección de fallos de pequeña magnitud, sino que además, facilita el ajuste del parámetro de memoria apoyándose en una dinámica que tiene más información válida del estadísticos T2 de Hotelling. Como resultado es posible detectar de manera rápida tanto fallos incipientes como abruptos. La filosofía EWMA-ED queda formalizada entonces como:
es el valor estimado teniendo en cuenta el comportamiento dinámico anterior. El parámetro γ es una constante 0<γ≤1, que determina la profundidad de memoria o capacidad de olvido para la estrategia. Respecto al diagnóstico de procesos, EWMA ha sido ampliamente aplicada para mejorar la detección de fallos de pequeña magnitud [16]. En este sentido, y tal como plantea [4], los mejores resultados dentro de la detección con enfoques MSPM se encuentran en el uso de estrategias integradas donde se involucra la filosofía EWMA y los métodos kernel para filtrar los estadísticos SPE y T2 de Hotelling con el objetivo de detectar fallos pequeños y/o de lento desarrollo. Sin embargo, es importante señalar que en la práctica, lograr un ajuste adecuado del factor de memoria (γ), tal que se alcance una alta Tasa de Detección de Fallos (FDR, Fault Detection Rates) sin incrementar significativamente la Tasa de Falsas Alarmas (FAR, False Alarm Rates), es una tarea compleja. El enfoque EWMA con dinámica reforzada (EWMA-ED) propuesto en este trabajo mejora no sólo la detección de fallos de pequeña magnitud, sino que además, facilita el ajuste del parámetro de memoria apoyándose en una dinámica que tiene más información válida del estadísticos T2 de Hotelling. Como resultado es posible detectar de manera rápida tanto fallos incipientes como abruptos. La filosofía EWMA-ED queda formalizada entonces como:
donde Y representa el valor del estadístico T2 de Hotelling. Nótese que Yt es el nuevo valor estimado, considerando el comportamiento dinámico observado a partir de la estimación Y0. El enfoque EWMA-ED permite adaptar rápidamente el valor de la predicción a fluctuaciones en los datos recientes, resultando en una detección temprana de cambios abruptos en la serie de tiempo. Por otra parte, al aumentar simultáneamente el aporte dinámico de cada una de las estimativas anteriores, utilizando el factor de reforzamiento (δ), el EWMA-ED también logra expandir la profundidad de memoria haciendo que la influencia del valor actual Yt sea notable sin que esto implique perder la sensibilidad a cambios de pequeña magnitud, lo cual es una ventaja respecto a la variante convencional de este algoritmo.
3.1.- COMBINACIÓN DE EWMA-ED CON KICA
El trabajo con métodos kernel puede ser visto como la unión de dos operaciones concatenadas. La primera de ellas consiste en pre-procesar los datos de entrada mediante un mapeo no lineal xi ∈ Rp → Φ(xi) ∈ H, que los proyecta hacia un espacio de dimensión superior H. La segunda etapa se centra en aplicar un algoritmo de aprendizaje diseñado para descubrir patrones lineales en el espacio mapeado.
En este contexto, KICA es una técnica de reducción de dimensión basada en ICA que tiene como objetivo encontrar una representación no lineal del conjunto de variables originales, en la cual la dependencia estadística de las componentes es minimizada [17]. La idea básica de kernel ICA consiste en realizar un mapeo no lineal de los datos hacia el espacio de KPCA, y a continuación, extraer la información útil de los mismos utilizando ICA [18]. De acuerdo con [19], kernel ICA puede ser implementado a partir de un procedimiento general formado por dos pasos: (i) pre-procesar los datos con KPCA, (ii) aplicar ICA en el espacio kernel transformado para obtener las componentes independientes. El objetivo de ICA, durante la segunda etapa del procedimiento, es determinar una matriz de separación o blanqueado (de-mixing matrix) W∈Pdxd en el espacio kernel transformado para recuperar las componentes independientes, a partir de maximizar la no-gausianidad de los datos, minimizar la información mutua o utilizar la estimación de máxima verosimilitud como medida de independencia estadística tal cual plantea [20]
El algoritmo KICA que se emplea en este trabajo se basa, específicamente, en el criterio de no-gausianidad y el algoritmo FastICA desarrollado por [20] Además, como se ha mencionado anteriormente, en el presente trabajo el estadístico T2 de Hotelling se utiliza para determinar si el proceso se encuentra fuera del estado de operación normal utilizando como base la información del proceso en el espacio de variables latentes obtenido con KICA. Por último, la propuesta de EWMA-ED se integra como filtro para mejorar detección de fallos de pequeña magnitud. La Figura 2 describe cualitativamente el efecto que tienen cada una de estas etapas en el procedimiento propuesto. La primera etapa, Figura 2(a), intenta aprovechar fundamentalmente la capacidad que tienen los métodos kernel para incrementar la separabilidad entre las observaciones. Esto significa maximizar las diferencias entre el estado de operación normal y los patrones que describen los estados de operación con fallo. Esta primera etapa incluye aplicar KICA y utilizar el T2 de Hotelling convencional para evaluar la similitud del comportamiento actual respecto a las características típicas del proceso, y de esta manera, decidir si se cumplen o no con los requerimiento de la operación normal. Por otra parte, en la Figura 2(b) se representa la segunda etapa del procedimiento, y se realiza una comparación entre el filtrado con EWMA-ED y el filtrado con el EWMA convención.
La Figura 2(b) muestra que el EWMA-ED propuesto mantiene el filtrado suave de su contraparte convencional, pero además disminuye el tiempo en que se detecta el fallo. Nótese que en este sentido, el suavizado del estadístico es otra característica que contribuye a diferenciar mejor las observaciones que pertenecen a un estado de operación normal de aquellas que corresponden a un fallo.
3.2.- ESTIMACIÓN DE LOS PARÁMETROS CON PSO.
]]> La optimización por enjambre de partículas (PSO) es un algoritmo inspirado en el comportamiento social de diferentes especies que forman grupos para, de manera colaborativa y con el menor gasto de energía posible, lograr trasladarse y encontrar alimento en la naturaleza. PSO ha mostrado un ser una alternativa viable para dar solución a aquellos problemas de optimización relacionados con la selección de los parámetros kernel. De manera general, la aplicación del algoritmo de optimización por enjambre de partículas requiere lograr un balance entre su capacidad de exploración, y su capacidad de explotación . Sin embargo, en este caso la estimación de los parámetros kernel se realiza fuera de línea, por lo cual no es de interés analizar el costo computacional de dichas etapas. Además, debe señalarse que aunque existen muchas variantes de este algoritmo, en el presente trabajo se optó por utilizar la versión convencional de PSO, dada su simplicidad y fácil implementación para problemas de estimación con métodos kernel. Una descripción general de este algoritmo se muestra en el seudo-código de la Figura 3.A partir de esto, la configuración del algoritmo se estableció con tamaño de población igual a 50, wmax=0.9, wmin=0.4, c1=2, c2=2, y MaxIter = 600. Para cada parámetro estimado, se proporcionó además, un intervalo de búsqueda tal que: σ ∈ [300, 1500] (parámetro kernel), γ ∈ [0.001, 100], y δ ∈ [0.001, 100]. En tanto, como criterio de parada se consideró el número de iteraciones y el error en la estimación. Por otra parte, para realizar kernel ICA se implementó un kernel RBF. Como función objetivo se empleó la relación que existe entre el desempeño del proceso de detección de fallos y el área debajo de la curva ROC (AUC, Area Under the Curve ROC) cuando se tienen en cuenta c estados de operación diferentes del funcionamiento normal del proceso.
Respecto al número de componentes retenidas, se optó por utilizar 19 componentes principales para KPCA, lo cual equivale a trabajar en el primer paso de kernel ICA con el 95.07% de la información total retenida en las 33 componentes originales del proceso. Así mismo, para kernel ICA se seleccionaron 19 componentes independientes manteniendo esta misma cantidad de información. Consecuentemente, la dimensión del espacio de características se redujo de R33 a R19.
4.- DETECCIÓN DE FALLOS EN EL TEP.
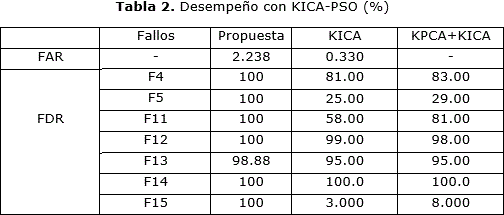
El procedimiento propuesto unifica las ventajas de KICA y EWMA-ED, su aplicación al proceso de prueba TEP tiene como objetivo validar la efectividad del mismo para detectar fallos de pequeña magnitud. La Tabla 2 muestra una comparación entre los resultados del esquema de detección propuesto y otros enfoques kernel que previamente han sido reportados en la literatura para la detección de tales fallos en el TEP. La comparación de estos enfoques se realiza sobre la base de los indicadores FAR y FDR obtenidos con el enfoque propuesto, y utiliza los resultados de detección alcanzados por [19] al aplicar kernel ICA y por [21] que combina KPCA y KICA. Todos los trabajos seleccionados para esta comparación utilizan sólo las variables del TEP que están disponibles en línea, y un límite de control T2 de Hotelling de 99% de confianza.
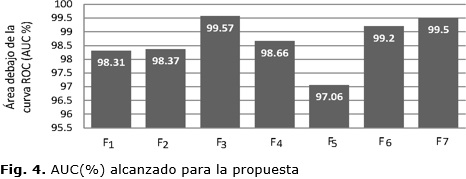
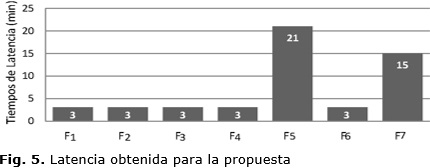
La Tabla 2 muestra que el enfoque propuesto tiene una elevada capacidad para detectar los fallos (valor de FDR) independientemente de la naturaleza de los mismos. En este sentido, el desempeño obtenido mediante la combinación de KICA y EWMA-ED resulta superior al resto de los métodos analizados. En comparación con estos métodos, el enfoque propuesto también resulta más sensible a los cambios en el proceso y esto es evidente al analizar el valor de FAR. Esto significa, por ejemplo, que comparado a los resultados obtenidos por [21], el enfoque propuesto va a presentar un mayor número de falsas alarmas. Sin embargo, es importante resaltar que el objetivo fundamental en estos enfoques es obtener sistemas de detección que logren pocas falsas alarmas, y que garanticen altas tasas de detección de manera simultánea.En este contexto, no es recomendable emplear sistemas de detección que solo logren cumplir con uno de estos requerimientos. Por ejemplo, los sistemas de detección con bajos valores de FAR y FDR tendrán pocas falsas alarmas pero no serán capaces de detectar correctamente los fallos. Por otra parte, alcanzar altos valores de FAR y FDR simultáneamente puede tener como desventaja que los operadores desconecten aquellas alarmas que están constantemente activándose sin causa aparente. En cualquier caso, la mejor opción será llegar a un compromiso que represente un sistema de detección de fallos con bajos valores de FAR y altos valores de FDR, pero que además realice un rápida detección (baja latencia) de los fallos en el proceso. En este sentido, las Figuras 4 y 5 se muestran los valores del área bajo la curva ROC (AUC representada en valores porcentuales), y tiempos de latencia (tiempo de demora en minutos) alcanzados durante la detección de los fallos con el enfque propuesto.
El análisis de estos resultados refleja que, teniendo en cuenta al valor de AUC, el enfoque propuesto presenta una alta probabilidad de diferenciar correctamente las observaciones de fallo respecto al estado de operación normal del proceso. Nótese que, de manera general, se obtienen valores de AUC superiores al 97%. En tanto, la detección con el enfoque propuesto resulta casi inmediata para la mayoría de los fallos, excepto los fallos F13 y F15. En estos casos, la combinación de KICA y EWMA-ED logra detectar los fallos de manera continúa sólo luego de 5 y 7 muestreos del sistema respectivamente.
5.- CONCLUSIONES
En el presente trabajo se propueso unificar el pre-procesamiento de kernel ICA y un enfoque EWMA con dinámica reforzada, para filtrar la dinámica del estadístico T2 de Hotelling a fin de obtener altos indicadores de desempeño en la detección, independientmente de la magnitud del fallo. El uso combinado de estas herramientas en el problema de prueba TEP, mostró una alta capacidad para detectar, con pocas falsas alarmas y bajos tiempos de latencia, cualquier posible estado de operación anormal en la planta. Además, respecto a otros enfoques kernel previamente reportados en la literatura de diagnóstico de fallos, la propuesta realizada demostró que es posible mejorar el desempeño del sistema de detección al considerar la dinámica anterior del proceso y realizar un ajuste adecuado de los métodos kernel involucrados.
]]> REFERENCIAS
1. Aström KJ, Kumar PR. Control: A perspective. Automatica. 2014; 50(1): 3-43.
2. Wang J, Yang F, Chen T, Shah SL. An Overview of Industrial Alarm Systems: Main Causes for Alarm Overloading, Research Status, and Open Problems. IEEE Transactions on Automation Science and Engineering. 2016; 13(2): 1045-1061.
3. Mannan MS, Reyes-Valdes O, Jain P, Tamim N, Ahammad M. The evolution of process safety: current status and future direction. Annual Review of Chemical and Biomolecular Engineering. 2016; 7: 135-162.
4. Isermann R. Fault-diagnosis applications, Model-based condition monitoring: actuators, drives, machinery, plants, sensors, and fault-tolerant systems. Springer; 2011.
]]>5. Van Impe J, Gins G. An extensive reference dataset for fault detection and identification in batch processes. Chemometrics and Intelligent Laboratory Systems. 2015; 148: 20-31.
6. Tidriri K, Chatti N, Verron S, Tiplica T. Bridging data-driven and model-based approaches for process fault diagnosis and health monitoring: A review of researches and future challenges. Annual Reviews in Control. 2016; http://dx.doi.org/10.1016/j.arcontrol.2016.09.008. 2016.
8. Gao Q, Chang Y, Xiao Z, Yu X. Monitoring of Distillation Column Based on Indiscernibility Dynamic Kernel PCA. Mathematical Problems in Engineering. 2016; vol 2016: 1-11. http://dx.doi.org/10.1155/2016/9567967.
9. Bernal-de Lázaro JM, Moreno-Prieto A, Llanes-Santiago O, Silva-Neto AJ. Optimizing kernel methods to reduce dimensionality in fault diagnosis of industrial systems. Computers & Industrial Engineering. 2015; 87: 140-149.
10. Xiao YW, Zhang XH. Novel Nonlinear Process Monitoring and Fault Diagnosis Method Based on KPCA–ICA and MSVMs. Journal of Control, Automation and Electrical Systems. 2016; 27(3): 289-299.
11. Shi H, Liu J, Wu Y, Zhang K, Zhang L, Xue P. Fault diagnosis of nonlinear and large-scale processes using novel modified kernel Fisher discriminant analysis approach. International Journal of Systems Science. 2016; 47(5): 1095-1109.
12. D'Angelo MF, Palhares RM, Camargos Filho MC, Maia RD, Mendes JB, Ekel PY. A new fault classification approach applied to Tennessee Eastman benchmark process. Applied Soft Computing. 2016; http://dx.doi.org/10.1016/j.asoc.2016.08.040.
13. Yin Z, Hou J. Recent advances on SVM based fault diagnosis and process monitoring in complicated industrial processes. Neurocomputing. 2016; 174: 643-650.
14. Bernal-de-Lázaro JM, Llanes-Santiago O, Prieto-Moreno A, Knupp DC, Silva-Neto AJ. Enhanced dynamic approach to improve the detection of small-magnitude faults. Chemical Engineering Science. 2016; 146: 166-179.
15. Lyman PR, Georgak C. Plant-wide control of the Tennessee Eastman problem. Computers and Chemical Engineering. 1995; 19(3): 321-331.
16. Cheng C, Hsu C, Chen M. Adaptive kernel principal component analysis (KPCA) for monitoring small disturbances of nonlinear processes. Industrial and Eng. Chemistry Research. 2010; 49(5): 2254-2262.
17. Fan J, Qin SJ, Wang Y. Online monitoring of nonlinear multivariate industrial processes using fltering KICA-PCA. Control Eng. Practice. 2014; 22: 205-216.
18. Zhang Y, Qin SJ. Improved nonlinear fault detection technique and statistical analysis. AIChE Journal. 2008; 54(12): 3207-3220.
19. Lee J, Qin SJ, In-Beum L. Fault detection of non-linear processes using kernel independent component analysis. The Canadian Journal of Chemical Engineering. 2007; 85(4): 526-536.
20. Hyvärinen A. Fast and robust fixed-point algorithms for independent component analysis. IEEE Transactions on Neural Networks. 1999; 10(3): 626-634.
21. Zhang Y. Enhanced statistical analysis of nonlinear processes using KPCA, KICA and SVM. Chemical Eng. Science. 2009; 64(5): 801-811.
Recibido: 5 de marzo de 2016
Aprobado: 19 de septiembre de 2016
José M. Bernal-de Lázaro. Departamento de Automática y Computación de la Facultad de Ingeniería Eléctrica de la CUJAE, La Habana, Cuba. Correo electrónico: jbernal@crea.cujae.edu.cu
]]>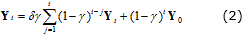
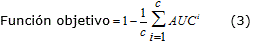

{kind=link}
{kind=link}