
Lic. Anissa Gramatges Ortiz
Se realizó una actualización sobre el análisis de supervivencia en las investigaciones clínicas. Se expusieron algunos de los conceptos más generales sobre este tipo de análisis y las características de los tiempos de supervivencia.Se abordan temas relacionados con los diferentes métodos que facilitan la estimación de las probabilidades de supervivencia para uno o más grupos de individuos, con la ejemplificación del cálculo de las probabilidades para el método de Kaplan-Meier. Se destaca la comparación de la supervivencia de varios grupos atendiendo a distintos factores que los diferencian, así como también se enuncian algunas de las pruebas estadísticas que nos posibilitan la comparación, como son la prueba log rank y la Breslow, como alternativa de esta cuando se evidencia una divergencia del azar proporcional, es decir, cuando las curvas de supervivencia se cruzan.
DeCS: ANALISIS DE SUPERVIVENCIA; ANALISIS ACTUARIAL; METODOS Y PROCEDIMIENTOS ESTADISTICOS; INVESTIGACION
Una característica muy propia de los tiempos de supervivencia es que hay presencia de tiempos censurados, es decir, hay individuos a los que no se les conoce su tiempo real de supervivencia.3-6
Para un conjunto de tiempos de supervivencia (incluyendo los censurados) de una muestra de individuos, se puede estimar la proporción de la población que sobrevivirá un intervalo de tiempo en las mismas circunstancias.7,8 Entre los métodos que se usan para hacer esta estimación se encuentra el Kaplan-Meier. Este método también nos permite a través de diferentes pruebas estadísticas (log rank, Breslow, Tarone- Ware, etc) la comparación de la supervivencia de 2 o más grupos de individuos que difieren con especto a ciertos factores.
El análisis de supervivencia centra el interés en un grupo o varios grupos de individuos para los cuales se define un evento, a menudo llamado fracaso, que ocurre después de un intervalo de tiempo, llamado tiempo de fracaso. Para determinar el tiempo de fracaso hay 3 requerimientos: un tiempo inicial, que debe estar inequívocamente definido; una escala para medir el transcurso del tiempo y tener bien claro qué se entiende por evento.9 El tratamiento estadístico de estos tiempos es conocido como análisis de supervivencia.7
Usualmente hay una definición clara del final del período de observación, el comienzo es menos evidente. Por ejemplo, rara vez conocemos el momento exacto en el cual se enfermó un individuo, por lo tanto, la fecha de diagnóstico es, a menudo, una alternativa para resolver este dilema. Téngase en cuenta que para algunas enfermedades estas 2 fechas son muy diferentes.7,8,10,11
En estudios clínicos, los tiempos de supervivencia a menudo se refieren al tiempo de muerte, al desarrollo de un síntoma particular, o a la recaída después de remisión completa de una enfermedad. Como fracaso se entiende la muerte, la recaída o la incidencia de una nueva enfermedad. En las investigaciones médicas, el evento de interés es usualmente algo no deseado, como por ejemplo, la muerte, por lo que el interés científico no se corresponde con el clínico.1,8,10-12
En muchos análisis de supervivencia, cuando se llega al final del período de observación fijado por el investigador previamente, hay individuos a los cuales no les ha ocurrido el evento y no conocemos cuándo le ocurrirá. Por lo tanto, no se conoce el tiempo real de supervivencia para ellos, solo se conoce el tiempo de supervivencia hasta el final del estudio. A tales tiempos de supervivencia se les llama tiempos censurados.2,5,6,9,12,13 También ocurre, en algunos casos, que los pacientes abandonan el estudio antes de concluir el período de análisis por motivos ajenos a la investigación, por ejemplo, los cambios de domicilio, las muertes por otras causas como son los accidentes, etc.; estos tiempos también son censurados. Los tiempos censurados indican que el período de obsevación es más corto que el tiempo de supervivencia real. Los datos censurados contribuyen con información valiosa y ellos no pueden ser omitidos en el análisis.13
A causa de la censurabilidad, en las investigaciones clínicas, los datos relevantes para un análisis de supervivencia son el estado del sujeto en la última observación, que indica si el sujeto respondió o fue censurado cuando finalizó la observación, y el intervalo de tiempo en que el sujeto fue seguido.8
Los períodos de seguimiento en este tipo de análisis son casi siempre diferentes, ya que los pacientes se van incorporando al estudio durante todo el período de observación, por lo que los últimos en hacerlo, serán observados durante un período de tiempo menor que los que entraron al principio.2,7 El tiempo de fracaso de cada individuo es medido a partir de su fecha de entrada al estudio. Para cada paciente se dispone de un tiempo real, que es el que se corresponde con la fecha en la que este se incorpora al estudio hasta su última observación, y de un tiempo "t" que es el que representa el tiempo (en años, meses, días, etc.) que estuvo el paciente en seguimiento.7,9 En la figura 1 se ofrece una ilustración de estos tiempos.
Fig. 1. Experiencia de 10 pacientes con entrada en el transcurso del tiempo y seguimiento hasta 1980.
Un requerimiento universal de los tiempos de fracaso es que son no negativos (toman valores positivos y el cero). Una razón para la opción de una escala de tiempo es que esta tiene que estar relacionada directamente con el individuo en estudio.
No solo se pueden conocer las distribuciones de los tiempos de fracaso en un solo grupo, sino que también se puede comparar el tiempo de fracaso en 2 o más grupos. Por ejemplo, si quisiéramos comprobar en 2 grupos dados que los tiempos de fracaso de los individuos del grupo 2 son sistemáticamente más largos que los de los del grupo 1.
Fecha inicial: fecha de diagnóstico, de inicio del tratamiento o de remisión completa.
Fecha de última noticia: fecha correspondiente a la última información que se tiene del caso. ]]>
Seguimiento: es la observación de los individuos de un grupo a partir de la fecha inicial, para conocer su estado vital (vivo, fallecido o desconocido).
Período de seguimiento: el tiempo transcurrido entre la fecha de inicio y la fecha de corte del estudio.
Fecha de corte del estudio: fecha fijada por el investigador para el término del seguimiento de los pacientes.
Tiempo de supervivencia: es el intervalo de tiempo transcurrido entre el inicio y la fecha de última noticia.
La muerte o recaída después de remisión completa (RC): ocurrió el evento o fracaso. ]]>
Pérdida del seguimiento: observación censurada.
Muerte por otras causas: observación censurada.
Es excluido del estudio sin haber ocurrido el evento: observación censurada.
No ocurre el evento en el período de observación: observación censurada.
De un conjunto de tiempos de supervivencia (incluyendo los censurados) de una muestra de individuos, podemos estimar la proporción de la población que sobrevivirá un intervalo de tiempo bajo las mismas condiciones. Por ejemplo, podemos usar datos de un estudio de pacientes a los que se les realizó un tratamiento quirúrgico para estimar la probabilidad que tienen nuevos pacientes de sobrevivir a esta técnica en un intervalo de tiempo (con la condición de la representatividad de la muestra original). El método produce una tabla o un gráfico, los cuales se nombran: tabla de vida y curva de supervivencia o de Kaplan-Meier, respectivamente.13
En este método, los intervalos se determinan por la ocurrencia del evento, es decir, la probabilidad de supervivencia es calculada cada vez que ocurre un evento. La probabilidad condicional de supervivencia, que es la probabilidad de ser un sobreviviente en el final del intervalo condicionado a que es un sobreviviente en el comienzo del mismo4,14 para cada paciente, se calcula a partir del número exacto de casos en riesgo al producirse el evento. Asume que la tasa instantánea es cero durante el intervalo entre 2 eventos. Es más preciso que las tablas de vida y no está restringido a pequeños grupos de sujetos, porque su procesamiento se puede hacer con la ayuda de diferentes paquetes estadísticos.
La metodología de Kaplan-Meier puede ser usada para estimar la probabilidad de supervivencia por encima de un período de tiempo dado. Este método poporciona un estimador de estar libre del evento en el tiempo t.4
La probabilidad de sobrevivir en un período de tiempo puede ser calculada considerando pequeñas particiones de este tiempo. Por ejemplo, la probabilidad condicional de un paciente de sobrevivir 2 días después de una cirugía es calculada como la probabilidad de supervivencia del primer día multiplicado por la probabilidad de supervivencia del segundo, dado que el paciente sobrevivió el primer día.2,12 Si escribimos p10 como la probabilidad condicional de supervivencia en el décimo día habiendo sobrevivido los 9 días anteriores, entonces la probabilidad de sobrevivir 10 días después de un proceder quirúrgico es: p1.p2.... · p9. p10
La probabilidad de sobrevivir el décimo día es estimada simplemente como la proporción de la muestra que se conoce que está viva en el noveno día. A la probabilidad la llamaremos a partir de ahora p. La probabilidad p es 1 en el caso de no haber ocurrido ningún evento.
Si pk es la probabilidad de sobrevivir el k-ésimo día, rk es el número de sujetos aún en riesgo (es decir, aún están en seguimiento) inmediatamente antes del k-ésimo día y fk es el número de observaciones fracasadas en el día de k, entonces tenemos:
]]> pk = pk-1. (rk-fk) / rkLas observaciones censuradas en un tiempo dado afectan el número de pacientes en riesgo al comienzo del del próximo mes.3, 7,14
Los cálculos de la curva de supervivencia serán ilustrados en un pequeño conjunto de datos hipotéticos sobre la supervivencia de un grupo de pacientes a los que se les realizó un proceder quirúrgico. Se analizó un período de tiempo de un año desde enero de 1995 a diciembre del mismo año. En este tiempo se operaron a 10 pacientes; 4 sobrevivieron al transcurrir el año. Los tiempos de supervivencia (en meses) de los otros 6 sujetos fueron 1,3; 5*; 5,3; 6; 7*; 8,3, donde las 2 observaciones marcadas con * fueron censuradas, ya que los pacientes salieron de la investigación por causas ajenas a ésta (uno murió de un infarto, el otro se trasladó de provincia y se perdió su seguimiento), las otras 4 corresponden a pacientes que fallecieron. Las observaciones de los 4 pacientes que sobrevivieron fueron censuradas y sus tiempos son 3*; 5*; 8*; 12*.
La tabla 1 muestra la tabla de vida para esos datos, dando la proporción de supervivencia en los tiempos de supervivencia no censurados. Como solamente ocurrieron 4 muertes, hay 4 probabilidades de supervivencia estimadas. La probabilidad de supervivencia permanece en 1 hasta el tiempo del primer evento (1,3 meses). Esto usualmente se muestra en un gráfico (fig. 2).
Tabla 1. Tabla de vida para pacientes operados
| Número de sujeto | Tiempo de supervivencia (meses) | Probabilidad de supervivencia | Error estándar |
| 1 | ]]> 1,3 | 0,9 | 0,0949 |
| 2 | 3,0* | ||
| 3 | 5,0* | ||
| 4 | 5,0* | ]]> | |
| 5 | 5,3 | 0,75 | 0,1581 |
| 6 | 6,0 | 0,6 | 0,1844 |
| 7 | 7,0* | ]]> | |
| 8 | 8,0* | ||
| 9 | 8,3 | 0,3 | 0,2313 |
| 10 | 12,0* |
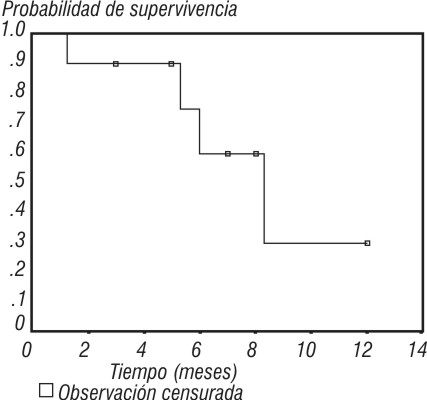
Fig. 2. Curva de supervivencia correspondiente a los pacientes operados.
Para la tabla 1 la unidad es meses y el fracaso es la muerte. La proporción de supervivencia es 1 hasta 1,3 meses. Por lo tanto, tenemos p1,2 = 1 y r1,3 = 10 porque todos los sujetos están en riesgo en 1,3 meses. A los 1,3 meses hubo un fracaso, por tanto f1,3 = 1 y podemos calcular la proporción de supervivencia a los 1, 3 meses como:
p1,3 = p1,2. (r1,3 - f1,3) / r1,3 = 1. (10-1) / 10 = 0,9
]]> Como muestra la tabla 1, la proporción estimada de supervivencia es la misma hasta que ocurra el próximo evento, el cual es a los 5,3 meses, entonces tenemos:P5,3 = p1,3. (r5,3 - f5,3) / r5,3 = 0,9. (6-1) / 6 = 0,75
En este caso r5,3 es 6, ya que las observaciones que se registraron desde el tiempo 1,3 hasta 5,3 son censuradas y en estas no ocurrió el evento. Así sucesivamente, se pueden realizar todos los cálculos.
La probabilidad de supervivencia entre un evento y otro permanece constante.2 Por ejemplo, en la tabla 1 se puede decir que a los 3 y 5 meses la probabilidad de supervivencia es 0,9, que es la calculada en el tiempo 1,3, ya a los 7 meses la probabilidad es de 0,6 y después de los 8, 3 meses la probabilidad permanece en 0,3.
La mediana de supervivencia se puede obtener a partir de la curva de Kaplan-Meier como el tiempo en el cual la curva cambia de una probabilidad de supervivencia mayor de 0,5 a una menor de 0,5.7 Por ejemplo en la figura 2, la mediana del tiempo de supervivencia es 8,3. En caso de que la curva estimada sea horizontal en el nivel 0,5, como no se puede tomar un único número como estimador de la mediana, el punto medio del intervalo de tiempo sobre el cual la curva es 0,5 es un valor razonable. El uso de la estimación de Kaplan-Meier para estimar la mediana de supervivencia asegura que se hace un uso correcto de las observaciones censuradas en los cálculos, y esto es muy importante. Los datos censurados pueden complicar los cálculos de la mediana del tiempo de supervivencia y, como resultado, se pueden definir una serie de estimaciones. Si la estimación de la probabilidad de supervivencia siempre excede de 0,5, entonces no puede estimarse la mediana. Podemos establecer que la mediana excede el valor del tiempo de supervivencia de la observación mayor.
La curva de supervivencia es dibujada como una "función escalonada": la proporción de supervivencia permanece constante entre eventos. Es incorrecto juntar los puntos calculados por líneas inclinadas. Los tiempos censurados son algunas veces indicados por marcas sobre la curva de supervivencia, los cuales nos facilitan la búsqueda de los tiempos de supervivencia de los sujetos a los cuales no les ha ocurrido el evento (fig. 1).7
Podemos calcular intervalos de confianza para la proporción de supervivencia. Si no hay valores censurados se pueden usar métodos estándares para deducir un intervalo de confianza para la proporción, pero generalmente se necesita una modificación para admitir a los censurados.7,15 El error estándar de la proporción de supervivencia puede calcularse de varias formas, y llegar a resultados similares. Una fórmula muy simple es: SE (pk) = pk. [(1- pk) / rk] donde pk es la proporción de supervivencia en el tiempo k. Hay muchas fórmulas alternativas para el error estándar de una probabilidad de supervivencia estimada, la más conocida se debe a Greenwood:

Los errores estándares de la tabla 2 fueron caculados mediante esta fórmula.
Tabla 2. Tabla de vida para pacientes operados en el grupo 2
| Número de sujeto | Tiempo de supervivencia (meses) | Proporción de supervivencia | Error estándar |
| 1 | 1,3 | ]]> 0,8750 | 0,1169 |
| 2 | 2,0* | ||
| 3 | 4,3 | 0,7292 | 0,1650 |
| 4 | 5,0* | ]]> | |
| 5 | 6,0* | ||
| 6 | 7,0* | ||
| 7 | 8,0 | 0,3646 | 0,2707 |
| 8 | ]]> 9,0* |
*Observación censurada
Con el supuesto de que pk tenía una distribución muestral aproximadamente normal, podemos calcular un intervalo de confianza al 95 % para pk como:
[ pk - 1,96 ´ SE (pk) ; pk + 1,96 ´ SE (pk) ]
Esta no es una buena aproximación para tamaños de muestra pequeños, para muy grandes o para probabilidades pequeñas. Por ejemplo, la poporción de supervivencia a los 8 meses es 0,6 con un error estándar de 0,1844; el intervalo de confianza al 95 % es de [0,6 - 1,96* 0, 1844; 0,6 + 1,96* 0,1844] ó [0, 24; 0, 96].
Como es usual, con una muestra pequeña el intervalo de confianza es ancho. Cuando la proporción de supervivencia está cerca de 1 ó 0 el cálculo del intervalo de confianza puede incluir valores imposibles por encima de 1 o menor que 0. Si esto sucede, podemos tomar 1 como límite superior o 0 como límite inferior. Sin embargo, esta ocurrencia indica que la aproximación normal no es realmente apropiada y es preferible usar algún otro método.
El método más común de comparar tiempos de supervivencia de grupos independientes es la prueba log rank. Esta es una prueba de hipótesis donde la hipótesis nula asumida es que los grupos proceden de la misma población.
Sin perder generalidad, en el caso de 2 grupos por ejemplo, esta prueba está hecha para detectar una diferencia que se produce entre las curvas de supervivencia cuando la tasa de mortalidad en un grupo es considerablemente mayor que la correspondiente tasa en un segundo grupo, y la razón entre las 2 tasas es constante a lo largo del tiempo.
Cabe hacerse la pregunta de si es necesario hacer una prueba para un riesgo relativo constante antes de hacer la prueba log-rank. La prueba log-rank es bastante robusta contra desviaciones de azar proporcional (o lo que es lo mismo, desviaciones de los logaritmos de las curvas de supervivencia), pero debe tenerse cuidado. Si las curvas de supervivencia de Kaplan-Meier se cruzan, entonces esto evidencia una divergencia del azar proporcional, por lo que la prueba log-rank no puede utilizarse; 6,12 (en este caso se utilizan otras pruebas tales como la Breslow, también llamada prueba de Gehan o de Wilcoxon generalizado). Una prueba intermedia entre la log-rank y la Breslow es la Tarone-Ware.
La tabla 2 muestra los datos de un segundo seguimiento, hipotético, a pacientes a los que se les aplicó una cirugía. Igualmente fueron observados durante 1 año los 8 pacientes que entraron en el estudio. La prueba log-rank puede emplearse para comparar los datos de los 2 experimentos.
La prueba log-rank para comparar k grupos pruduce para cada grupo un valor observado (o) y uno esperado (e) del evento. Estos se comparan mediante el cálculo de la suma de (O-E)2 / E, llamado X2, y se compara el resultado con una distribución X2 con k-1 grados de libertad.7
(o) es el número de eventos observados en todo el período de observación. Para el cálculo de E se utiliza el siguiente procedimiento: supongamos que en el instante de tiempo tk ocurre un evento. Sean n1 y n2 las cantidades de individuos en riesgo de los grupos 1 y 2, respectivamente. De estos individuos, S1 y S2 sobrevivieron en los grupos 1 y 2, respectivamente.
| N° de riesgo | N° de sobrevivientes | |||
| Grupos | G1 | G2 | G1 | ]]> G2 |
| Instante de tiempo tk | n1 | n2 | S1 | S2 |
El riesgo de ocurrencia del evento en el instante tk para ambos grupos se estima como:
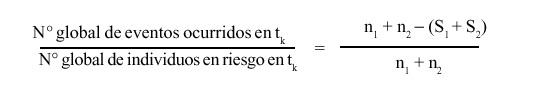
El número de eventos esperados en el grupo 1 bajo la hipótesis nula en el tiempo tk es:

Similarmente por el grupo 2 se tiene:

Por ejemplo: si tenemos 2 grupos en los cuales, a los 4 meses:
n1 = 10 S1 =10
n2 = 10 S2 = 7
El riesgo de ocurrencia de un evento a los 4 meses = (18-17) / 18 = 0,0556 ]]>
El valor esperado de eventos en el grupo 1 = 10. 0,0556 = 0,556| Grupo 1 | Grupo 2 | |||
| O | E | O | E | |
| 4 meses | 0 | ]]> 0,556 | 1 | 0,444 |
De esta forma, se tienen los valores observados y esperados en cada instante de tiempo en el que ocurre un evento, para cada grupo. Sumando todos los valores observados y los esperados en cada grupo se obtienen O1, E1 y O2, E2, respectivamente.6
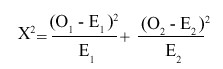
En el ejemplo de la cirugía se tiene:
O1 = 4 E1 = 4,1048; O2 = 3 E2 = 2,8952
Por tanto, la prueba log-rank es X2 = 0,0065. La suma de los valores observados y la de los valores esperados de los 2 grupos da 7, es decir, es la misma. Es importante comprobar esto cuando se está ejecutando el cálculo a mano.

Fig.3. Curvas de supervivencia correspondientes a los pacientes operados de los 2 grupos.
La prueba log-rank puede utilizarse cuando se quieren analizar más de 2 grupos. El estadígrafo X2 se calcula usando una extensión de la primera ecuación, por lo que si tenemos k grupos se calcula como:
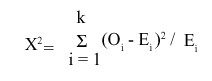
El valor de X2 entonces se compara con una distribución X2 con k-1 grados de libertad.
Es posible restringir la comparación de la experiencia de supervivencia entre 2 grupos a un intervalo del período de observación; la prueba de log-rank es válida cuando se restringe de esta manera. Sin embargo, es importante que la elección del intervalo no esté basada en el examen de los datos observados y en la selección de un intervalo donde la mortalidad parece diferente; este método de elección del intervalo invalida el cálculo del valor p, debido a que se deriva de un muestreo selectivo de la experiencia de supervivencia observada.
Debe ponerse especial atención a la confección y manejo de la base de datos para estos análisis dada la complejidad de los mismos, así como toda la codificación que llevan las variables para su tratamiento. Se recomienda a los investigadores solicitar asesoría a personal especializado en el tema.
El análisis de supervivencia es muy útil en las investigaciones clínicas. Este tiene numerosas aplicaciones en el campo de la medicina, sobre todo en el estudio de enfermedades crónicas fatales, ya que nos ayuda a hacer evaluaciones de la efectividad de modalidades terapéuticas, entre otros usos.
An updating of the use of survival analysis in clinical research was made. Some of the most general concepts of this type of analyses and the characteristics of survival times were presented. Aspects related with the different methods facilitating the estimation of survival probabilities for one or more groups of subjects, including the example of calculation of Kaplan Meier method´s probabilities were dealt with . The survival rates of several groups were compared, taking into consideration various factors that differentiate them. Some of the statistical tests making the comparison possible such as log rank test, and the Breslow test as an alternative of the former when there is a proportional random divergence, that is, when survival curves cross were stated.
Subject headings: SURVIVAL ANALYSIS; ACTUAARIAL ANALYSIS; STATISTICAL METHODS AND PROCEDURES; RESEARCH.
Recibido: 14 de marzo del 2002. Aprobado: 25 de junio del 2002.
Lic. Anissa Gramatges Ortiz. Instituto de Hematología e Inmunología. Apartado 8070, CP 10800, Ciudad de la Habana, Cuba. Tel (537) 578268, 544214. Fax (537) 442334. e-mail: inhidir@hemato.sld.cu