Lic. Oscar Saavedra Fernández,1 Lic. Gilberto Sotolongo Aguilar2 y M.Sc María V. Guzmán Sánchez3
A partir del uso de las redes neuronales artificiales (RNA), y más concretamente de la técnica de mapas autoorganizados (SOM), conocidos también como algoritmo de Kohonen, se intenta identificar algunos elementos que influyen la posición que ocupan las revistas de América Latina y el Caribe (AL y C), y el efecto que determinadas acciones pudieran tener sobre ella. En su calidad de técnicas exploratorias, aquí sólo se revelan patrones de comportamiento (signos) de la realidad que necesariamente deben valorar los expertos. Al abordar este tema,se han considerado los resultados de esfuerzos regionales recientes (resultados parciales de proyectos en curso como LATINDEX y RICYT) que permitirán en el futuro enfrentar tareas de evaluación más completas.
DeCS: PUBLICACIONES SERIADAS; AMERICA LATINA; REDES NEURALES(COMPUTACIÓN); REGION DEL CARIBE
Las publicaciones científicas y técnicas constituyen una de las formas de existencia de la ciencia y la tecnología, resultado del devenir histórico de esas dos actividades; en tanto los artículos aparecidos en revistas y las patentes se erigen como las publicaciones más paradigmáticas.
Las publicaciones científicas son depositarias de los conocimientos documentados que la humanidad acumula en cualquier campo del saber; son la vía fundamental para trasmitir dichos conocimientos, debido a que la transmisión directa de sus propietarios a quienes los necesitan es prácticamente imposible. Al propio tiempo, el cúmulo de materiales publicados crece en forma de avalancha y no es posible acceder directa-mente a ellos, mucho menos asimilar de forma directa su contenido. La propia ciencia ha permitido el desarrollo de técnicas que pueden contribuir a solucionar en parte este problema, como es el caso de los estudios cuantitativos de la información que, para diferentes fines, se han desarrollado en el transcurso de los últimos 80 años.1
]]>
Se utilizaron los datos de la ultima actualización del directorio titulado LATINDEX http://www.LATINDEX.unam.mx . Su consulta, en agosto de 2000, se realizó mediante el acceso a dicho sitio como a partir del trabajo de Alonso Gamboa mencionado anteriormente.5
Con ello, de forma muy general, se caracterizó cualitativa y cuantitativamente la situación actual de las revistas, en ella se hace referencia fundamentalmente a su distribución por rangos6 en la región. Así aparecen las revistas editadas en América Latina y el Caribe. También, se utilizaron algunos datos procedentes del directorio y se complementaron con indicadores tomados de la Red Iberoamericana de Indicadores de la Ciencia y la Tecnología (RICYT) http://www.ricyt.edu.ar/ accedida en igual fecha,6 se construyeron mapas autoorganiza-dos (SOM) de América Latina y el Caribe. Ellos posibilitan la realización de diferentes análisis para determinar las variables con la influencia necesaria de manera que se mejorar la visibilidad de las publicaciones del área.
A partir de los datos del directorio LATINDEX se estableció la distribución por rangos de las revistas que se publican en 22 países (tabla 1, variable: r-revistas (2000)). En esta tabla, se muestra la posición que cada país ocupa en relación con la cantidad de revistas editadas. Se hizo lo mismo con las revistas procesadas por GSIR (tabla 1,variables: rev-scisearch, rev-ca, rev-biosis, rev-medline, rev-cab). Con ello, es posible determinar la posición que ocupa cada país, según su aporte a estos servicios de información.
]]>
Con el propósito de explorar el comportamiento de los datos y de obtener una representación gráfica integrada de estos indicadores, los datos obtenidos se utilizaron para entrenar una red neuronal artificial (RNA) mediante el algoritmo de mapeo autoorganizado (algoritmo de Kohonen). Con ello fue posible modelar parcialmente la problemática bajo estudio y conocer la influencia de algunas de las variables (e.g. cantidad de revistas en el directorio LATINDEX, cantidad de revistas procesadas en GSIR, etc.).
Se empleó el software Viscovery SOMine® 3.0 Enterprise para obtener los SOM****; por la novedad del uso de estas técnicas, se hace necesario una pausa para ofrecer algunas explicaciones.
La corteza cerebral es posiblemente la estructura más fascinante que existe en la fisiología humana. A pesar de su enorme complejidad desde el punto de vista microscópico, la corteza revela una estructura uniforme a escala macroscópica, incluso al pasar de un cerebro a otro. Los centros correspondientes a actividades tan diversas como el pensamiento, la visión, oído, y las funciones motoras, están situados en zonas concretas de la corteza, las cuales se hallan ubicadas, de cierta forma, unas con respecto a las otras. Además, las zonas individuales muestran una ordenación lógica de su funcionalidad. Un ejemplo (es el denominado mapa tonotópico) de las frecuencias auditivas, en el cual las neuronas próximas entre sí responden a frecuencias de sonido similares según una sucesión ordenada, desde los tonos más altos a los más bajos. Otro ejemplo (es el mapa somatotópico) de nervios motores, que se representa artísticamente mediante el homúnculo. Las regiones tales como el mapa tonotópico y el mapa somatotópico suelen recibir el nombre de correspondencias ordenadas de características. El interés por descubrir esta organización es el que llevó a Teuvo Kohonen (Finlandia) a desarrollar el algoritmo al que se refiere este apartado.6
**** Tomado de: Red Iberoamericana de Indicadores de Ciencia y Tecnología (RICYT). Indicadores de ciencia y tecnología. Iberoamericanos/Interamericanos (1990-1997). Buenos Aires: REDES A.C; 1999.
La corteza es, en esencia, una capa extensa (aproximadamente de 1m2 , en humanos adultos) y fina (entre 2 y 4 mm de grosor) que consta de seis capas de neuronas (con un gran nivel de interconexión entre ellas) de distintos tipos y densidades (unos diez mil millones de neuronas) que interaccionan mediante los procesos físico-químicos. La corteza está plegada de forma tal que maximiza la densidad de empaquetado en el cráneo. Una hoja bidimensional de elementos de procesamiento es un buen modelo de la corteza cerebral.
Las redes neuronales artificiales, o simplemente redes neuronales, intentan emular lo antes descrito mediante procesos computacionales. Se puede pensar que las redes neuronales son técnicas de regresión, no lineal, en múltiples capas y de forma paralela. Existen dos tipos de redes neuronales: las supervisadas y las no supervisadas.
Las redes neuronales supervisadas son técnicas para extraer datos a partir de las relaciones de entrada-salida y para almacenar tales relaciones en ecuaciones matemáticas que pueden utilizarse en actividades de pronóstico o en la toma de decisiones. Requieren de que el usuario especifique la salida deseada. La red aprende a detectar la relación entre las entradas y las salidas suministradas, mediante un proceso iterativo y adaptativo. Una vez que la red se ha entrenado, se puede utilizar con datos que nunca haya visto o puede ser embebida en un programa para el apoyo a las decisiones.
Las redes neuronales no supervisadas son técnicas para clasificar, organizar y visualizar grandes conjuntos de datos. Los mapas autoorganizados (SOM) son un ejemplo del enfoque de las redes neuronales no supervisadas. Este enfoque, con origen a comienzos de los años 80, se ha utilizado ampliamente en ingeniería y en muchos otros campos. Muchas aplicaciones de redes neuronales no supervisadas y de SOM pueden encontrarse en la obra de Teuvo Kohonen. 7
Los mapas autoorganizados son un enfoque de red neuronal con alimentación directa que utiliza un algoritmo de entrenamiento no supervisado, que mediante un proceso conocido como autoorganización, configura las unidades de salida en una representación topológica de los datos originales. Los SOM, son una técnica de red neuronal que aprende sin supervisión. En contraste con las técnicas de las redes neuronales supervisadas que requieren que se especifique una o más salidas, conjuntamente con una o más entradas a fin de encontrar patrones o relaciones entre los datos, los SOM reducen datos multidimensio-nales a un mapa de menores dimensiones o una rejilla de neuronas.
El algoritmo de los SOM se basa en el aprendizaje competitivo. Proporciona un mapeo de preservación topológica a partir de un espacio multidimensional para mapear las unidades. Las unidades de mapeo o neuronas, usualmente forman una rejilla de dos dimensiones, el mapeo es de un espacio multidimensional en un plano o cubo. La propiedad de preservación topológica significa que en los SOM se agrupan vectores de datos de entradas similares en neuronas: los puntos que se encuentran cercanos unos de otros en el espacio de entrada son mapeados en el SOM, en unidades del mapa que son cercanas; por ello el SOM puede servir como una herramienta de agrupamiento (clustering) así como para visualizar datos multidimensionales. ]]>
Cuando se presenta un patrón de entrada a una red SOM, las unidades en la capa de salida compiten entre sí por el derecho de ser declarada la ganadora. La unidad de salida ganadora será la unidad cuya ponderación de la conexión de entrada está más cerca del patrón de entrada en términos de distancia euclidiana. Entonces, la entrada se presenta y cada unidad de salida compite para cotejar con el patrón de entrada. La salida que está más cerca al patrón de entrada es declarada la ganadora. Entonces, se ajusta la ponderación de la conexión de la unidad ganadora (i.e), se mueve en la dirección del patrón de entrada por un factor determinado por la tasa de aprendizaje; lo anterior constituye la naturaleza básica de las redes neuronales competitivas.
Los SOM realizan el mapeo topológico no sólo al ajustar las ponderaciones de la unidad ganadora, también ajustan las ponderaciones de las unidades de salida que son adyacentes en la vecindad más próxima de la unidad ganadora. Por lo tanto, no sólo la unidad ganadora es ajustada, sino también que toda la vecindad de unidades de salida se mueve más cerca del patrón de entrada. Con frecuencia, comenzando con valores aleatorios de las ponderaciones, las unidades de salida se alinean solas, de forma tal, que cuando se presenta un patrón de entrada, entonces una vecindad de unidades responde a los patrones de entrada. Según el entrenamiento progresa, decrece el tamaño de la vecindad alrededor de la unidad ganadora. Inicialmente, se actualiza una gran cantidad de unidades de salida, pero en la medida en que avanza el entrenamiento sólo se ajusta la unidad ganadora. De forma similar, las tasas de aprendizaje disminuirán según avanza el entrenamiento, y en algunas aplicaciones, la tasa de aprendizaje se reducirá con la distancia de las unidades de salida ganadoras.
El resultado es un grupo de conexiones ponderadas que representa un patrón de entrada prototipo para el subconjunto de entrada que corresponde a un grupo (cluster) en particular. El proceso de reducir datos multidimensionales a un conjunto de grupos (clusters) se llama segmentación. El espacio multidimensional de entrada se reduce a un mapa de dos dimensiones. Si se utiliza el índice de la unidad de salida ganadora, en esencia lo que produce es la partición de los patrones de entrada en un conjunto de categorías o grupos (clusters). Los SOM también tienen la capacidad de generalizar. Esto significa que la red puede reconocer o caracterizar entradas que nunca antes haya recibido. Una nueva entrada se asimila por la unidad del mapa con la cual se mapea. Aún más, los vectores de entrada con falta de datos pueden utilizarse para buscar o pronosticar los valores de los datos que faltan, basados en el mapa entrenado. ]]>
La actualización del directorio LATINDEX, correspondiente al año 2000,5 recoge unas 7 000 revistas de cerca de 30 países de Iberoamérica (se ha incluido a España, Portugal y organizaciones internacionales radicadas en la región), así como otras islas del Caribe no incluidas anteriormente en el Directorio LATINDEX. El 61 % de las revistas corresponde a países de ALyC y también del total, se ha identificado como activas el 60 %. Más de la mitad de la colección corresponde a revistas en ciencias sociales (39,8 %) y humanidades (13 %). El resto se distribuye entre 6 agrupaciones temáticas: ciencias de la salud (15,1 %), ingenierías (9,7 %), ciencias de la tierra (3,7 %), ciencias naturales (11,4 %), ciencias exactas (4,7 %) y revistas multidis-ciplinarias (2,6 %). La mayoría de las revistas surgieron en el transcurso de las últimas tres décadas. Más de la mitad de las revistas tiene una frecuencia anual-trimestral-irregular-semestral; y sólo el 2 % aparece en alguna modalidad electrónica (i.e. en línea, CD ROM o disco flexible). Finalmente, el 62 % se edita en español, mientras que el 22 % en portugués, el 15 % son multidisciplinarias y el 1 % aparece en inglés.
En la tabla 1 (variable: r-revistas (2000)), se puede observar la posición de cada uno de los países, según el rango que ocupan en el directorio LATINDEX. Argentina ocupa la primera posición, seguida de México, Brasil, Cuba, Chile y Colombia. Colombia a su vez supera entre otros a Venezuela, Uruguay, Costa Rica y Perú.
Mediante al acceso al directorio LATINDEX, se pudo identificar la presencia de revistas de ALyC procesadas en algunos de los GSIR. De esta forma, se pudo saber que en SciSearch, que incluye los tres índices de citas editados por el ISI (Institute for Scientific Information, Filadelfia), está representada de la siguiente forma SCI (Science Citation Index) = 14 (Colombia=1), SSCI (Social Science Citation Index)=8 (Colombia=1), AHCI (Arts & Humanities Citation Index) = 6. En otros GSIR, la presencia es la siguiente: PASCAL = 1; INSPEC = 1; Chemical Abstract (CA) = 10 (Colombia = 1); Medline = 9; Biological Abstracts (BIOSIS) = 46 (Colombia = 1), Commonwealth Agricultural Bureau (CAB) = 20. Resulta curioso que COMPENDEX no aparece en la lista de servicios de resúmenes reportados por LATINDEX (ni tampoco Engineering Index). La temática de las revistas de ALyC procesadas en GSI denota el peso específico de las ciencias sociales y humanidades, así como de las biociencias en la región.
En la tabla 1 (variables: rev-scisearch, rev-ca, rev-biosis, rev-medline, rev-cab) aparece la distribución por rangos de la presencia de revistas de ALyC en 5 de los GSIR. Así por ejemplo, si se compara Cuba y Colombia se observa que ambos países ocupan la misma posición (6) por la presencia de sus revistas en SciSearch y Medline; al tiempo que Cuba supera a Colombia respecto a los restantes GSIR, esto es, en Chemical Abstract, Cuba 1, Colombia 4, en BIOSIS, Cuba 3, Colombia 6 y en CAB, Cuba 5 y Colombia 7. ]]>
Tabla 2. Producción científica de ALyC según su aporte a las bases de datos internacionales (datos de 1997) rango Bases de datos %
| Rango | Bases de datos | % |
| 1 | ICYT | ]]> 5,3 |
| 2 | CAB | 5 |
| 3 | IME | 3,8 |
| 4 | BIOSIS | 2,3 |
| 5 | SciSearch ]]>
| 2,1 |
| 6 | PASCAL | 1,8 |
| 7 | INSPEC | 1,6 |
| 8 | COMPENDEX | 1,4 |
| 8 | ]]> CA | 1,4 |
| 8 | MEDLINE | 1,4 |
Estos datos permiten alimentar una red neuronal no supervisada de forma que se obtiene el mapeo autoorganizado (SOM) de los datos conforme al algoritmo de Kohonen. De esta manera, se puede disponer de mapas de ALyC en dos dimensiones a partir de los datos referidos anteriormente y examinarse la influencia que ejercen las distintas variables en la conformación del mapa de ALyC (22 países), conformado a partir de los indicadores bajo estudio (20 variables).
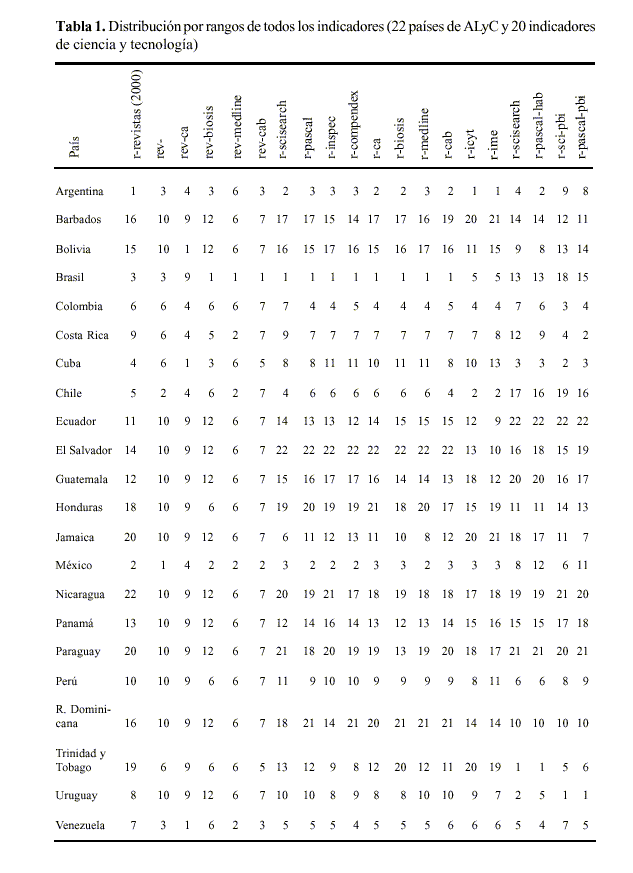
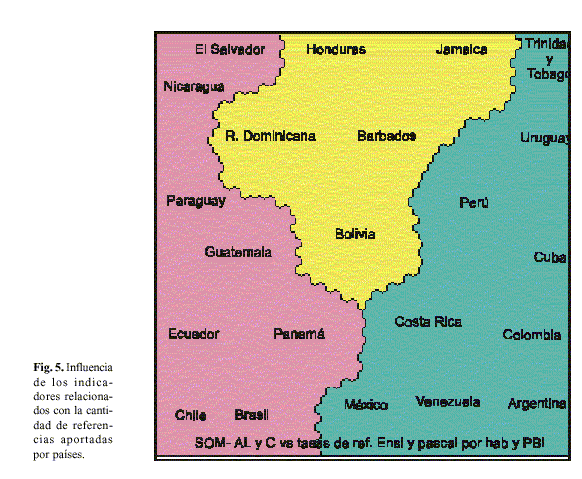
La figura 1 muestra el mapa autoorganizado de ALyC considerando las 20 variables simultáneamente. Como se puede observar, se forman 21 clusters o agrupa-mientos coincidiendo en todo los casos con cada uno de los países con la sola excepción de Nicaragua y Paraguay los que se agrupan en un solo cluster. Este resultado sugiere la idea de que todas las variables permiten un mapeo de ALyC donde cada uno de los países, con las excepciones antes señaladas, muestran su plena identidad. La situación de Nicaragua y Paraguay se debe a los bajos rangos que tienen en todas las variables, que se pueden constatar en la tabla 1.
De nuevo, el agrupamiento se debe a la semejanza de las posiciones (rangos de los países debido a su aporte de revistas registradas en el Directorio LATINDEX). Como se puede corroborar, la mera presencia del directorio ejerce muy poca influencia en la conformación del mapa de ALyC, presentado en la figura 1.
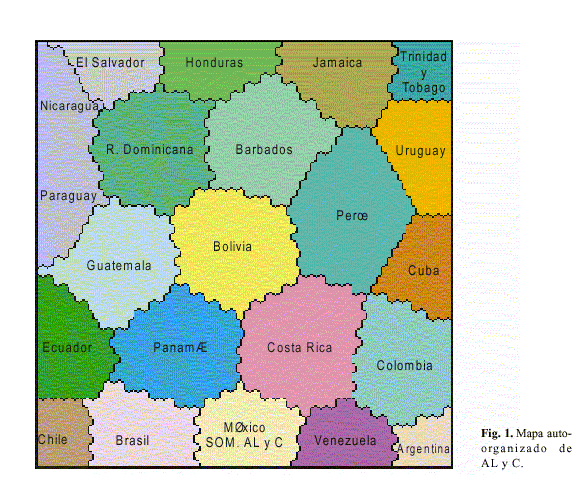
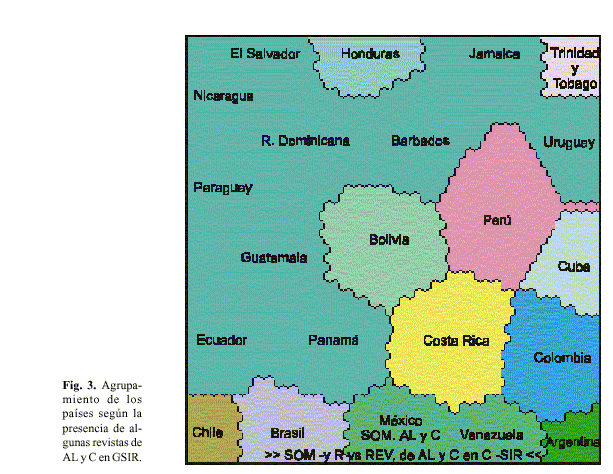
La figura 3 muestra el agrupamiento de los países atendiendo a la presencia de algunas revistas de ALyC en GSIR. Como se puede apreciar, esta variable muestra signos de influencia en el mapa completo de ALyC, donde se incluyen todas las variables (figura 1). Asimismo, aparecen claras definiciones de las fronteras de los países: Honduras, Trinidad y Tobago, Bolivia, Perú, Costa Rica, Cuba, Colombia, Chile, Brasil y Argentina. Venezuela y México forman un cluster; también, se forma otro cluster con los restantes países. Estos resultados sugieren la idea de que en general, aunque la presencia en los GSIR de las revistas de ALyC es baja, los dos cluster formados por múltiples países presentan la misma situación; por este concepto no se logra ni una visibilidad mínima.
]]>

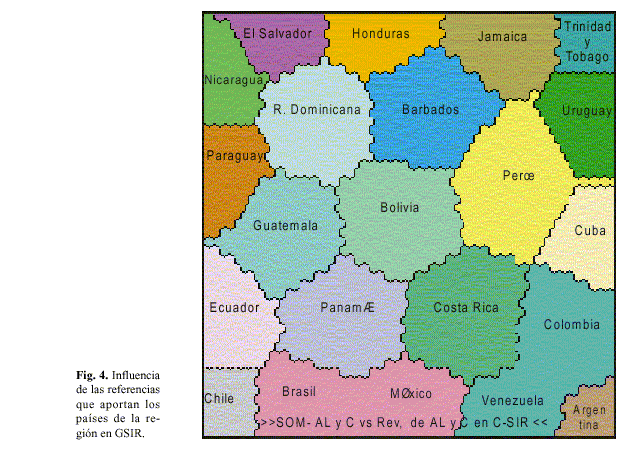
La figura 4 muestra la influencia de las referencias que aportan los países de la región en GSIR con independencia de las revistas que en ellos se procesan. Su influencia en la conformación del mapa de ALyC es indudable (figura 1). Todos los países se agrupan en sí mismo, incluso, Paraguay y Nicaragua; sin embargo, los dos clusters formados por Brasil y México de una parte, y Venezuela y Colombia de la otra, sugieren la idea de la insuficiencia de esos países por sí mismos de lograr la visibilidad adecuada mediante este indicador. En particular es necesario destacar la situación de México y de Venezuela, que aunque agrupados de forma diferente, si se observan las figuras 3 y 4, no es posible realizar su plena identificación.
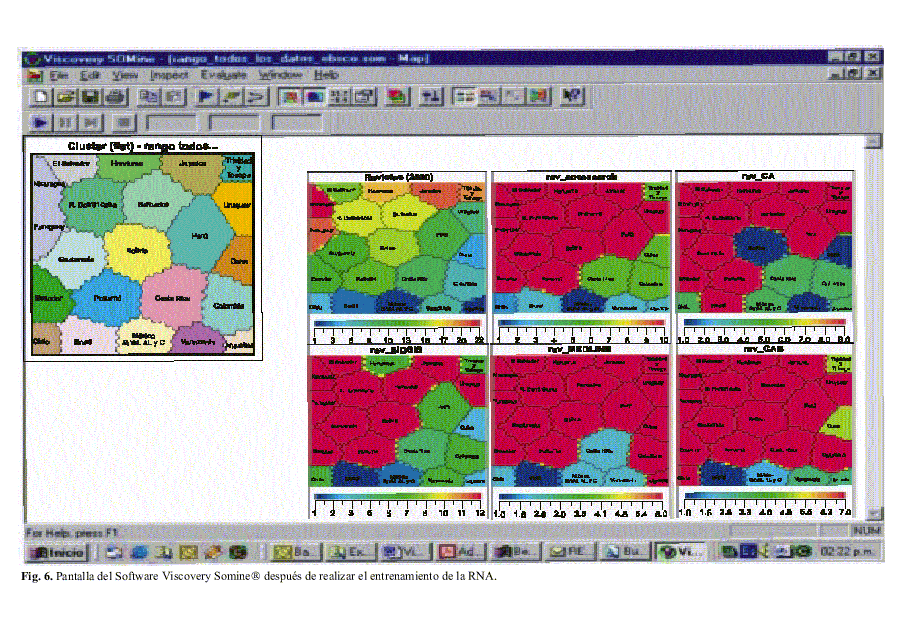
Por las características del método empleado en este tipo de análisis, es posible realizar una mayor cantidad de análisis y con más profundidad. Considére-se que de cada uno de los mapas mos-trados, es posible obtener hasta otros 25 mapas en los que puede examinarse el comportamiento de cada variable. Al propio tiempo es posible revelar la influencia de cada variable, una por una, como sucede en el caso de la figura 2, que muestra la influencia de la variable correspondiente al directorio LATINDEX, o de una combinación de estas, como es en el caso de las restantes figuras en las cuales se muestra la influencia de diversas variables de forma simultánea. La figura 6 es un ejemplo de lo antes planteado.
La figura 6 presenta una pantalla del software Viscovery SOMine® después de realizar el entrenamiento de la RNA (con los datos de los 20 indicadores de los 22 países de ALyC) conforme al algoritmo de Kohonen. El gráfico que aparece en la parte superior izquierda, muestra el mapa completo de ALyC según se presentó en la figura 1. A continuación se presentan otros siete gráficos. Los primeros tres, situados en la parte superior derecha así como los primeros tres en la parte inferior izquierda, corresponden a la tabla 1 (variables: r-revistas (2000), rev-scisearch, rev-ca, rev-biosis, rev-medline, rev-cab). Los colores que presenta cada país se corresponden con la escala de colores que aparece debajo de cada gráfico, así los tonos de azul corresponden a valores de cada variable denotando un alto rango, en tanto hacia la derecha los tonos de rojos denotan un nivel más bajo en la escala. Los colores intermedios denotan rangos intermedios. El último gráfico en el extremo inferior derecho representa la curvatura del mapa. Las zonas con azul más intenso muestran la delimitación de los clusters, esta es la zona donde el plano flexible se cambia formando una suerte de accidente geográfico montañoso (ver la escala en el borde inferior del gráfico). Las zonas de una azul menos intenso, pueden llegar a ser completamente blancas, ahí están los llanos o sabanas donde se ubican los países según los datos utilizados.
Al colega Octavio Alonso Gamboa que propició el acceso a su reciente artículo sobre Latindex del cual se utilizaron parte de sus datos para realizar el presente trabajo. Al Dr. Gerhard Kranner, presidente de la firma Eudaptics Software GmbH de Viena, Austria, por su licencia para emplear el software Viscovery SOMine® 3.0 Entersprise y que se usó en este trabajo para obtener los SOM.
Contribution to the study of the journals from Latin America and the Caribbean by self-organized mapping
Starting from the use of neural artificial networks (NAN), and more concretely from the technique of self-organized maps (SOM), also known as Kohonen’s algorithm, the authors try to identify some elements influencing on the position occupied by journals from Latin America and the Caribbean and the effect that certain actions may have on it. As exploratory techniques, they only reveal patterns of behavior (signs) of reality that have to be assessed by experts. On dealing with this topic, there have been considered the results of recent regional efforts (partial results of ongoing projects as LATINDEX and RICYT) that will allow to face in the future more complete tasks.
Subject headings: SERIALS; LATIN AMERICA; NEURAL NETWORKS(COMPUTERS); CARIBBEAN REGION
Recibido: 14 de mayo de 2002
Aprobado: 20 de junio de 2002
Lic. Oscar Saavedra Fernández. Gerente General de EBSCO México, INC. S.A. DE C.V. Ensenada 91. Col. Hipódromo Condesa, Del. Chauhtemoc 06170 México, D.F. México. E.mail: osaavedra@exchange.ebsco.com
]]>