Dr.C. José E. Medina Pagola1 y Lic. Laritza Hernández Rojas2
Detectar automáticamente los límites físicos adecuados de los subtópicos en un documento es una tarea difícil y muy útil en el procesamiento de texto. Existen algunos métodos que intentan resolver este problema, varios de ellos con resultados favorables, aunque presentan algunas deficiencias; además, muchas de estas soluciones dependen del dominio de la aplicación. Se realiza un análisis de dos algoritmos para la segmentación de documentos y se comparan los resultados obtenidos con cada uno de ellos.
Palabras clave: Cohesión léxica, segmentación por tópicos.
To automatically detect the adequate physical limits of subtopics in a document is a difficult but highly useful task in text processing. There is a few methods attempting to solve this problem, several of which have favorable results, although presenting some difficulties; also, many of these solutions depend on application skills. An analysis was made of two document segmentation algorithms and the results from each of them were compared.
Key words: Lexical cohesion, topic segmentation.
Copyright: © ECIMED. Contribución de acceso abierto, distribuida bajo los términos de la Licencia Creative Commons Reconocimiento-No Comercial-Compartir Igual 2.0, que permite consultar, reproducir, distribuir, comunicar públicamente y utilizar los resultados del trabajo en la práctica, así como todos sus derivados, sin propósitos comerciales y con licencia idéntica, siempre que se cite adecuadamente el autor o los autores y su fuente original.
Cita (Vancouver): Medina Pagola JE, Hernández Rojas L. Segmentación por tópicos en documentos de múltiples párrafos Acimed 2007;15(6). Disponible en: http://bvs.sld.cu/revistas/aci/vol15_6_07/aci06607.htm [Consultado: día/mes/año].
Con frecuencia, un documento contiene varios subtópicos. Estos se definen como piezas de texto que tratan sobre algo; ellas están formadas por unidades de texto: palabras, oraciones o párrafos. Sin embargo, no siempre los autores de los documentos utilizan marcas, subtítulos o comentarios para identificar los subtópicos.
]]> El proceso automático para identificar en un texto, los subtópicos que lo forman, se conoce como Segmentación de textos por tópicos. En lo adelante se denominará segmentos a los subtópicos.La segmentación por tópicos es útil en varias tareas del procesamiento de texto, como: la realización de resúmenes de los documentos, la segmentación de una transmisión continua de noticias, la recuperación de información, entre otras.
En la recuperación de información, más específicamente en la recuperación de pasajes, se utilizan los métodos de segmentación por tópicos para devolver, como resultados, los segmentos o pasajes más relacionados con la consulta —que realizaría un usuario— en lugar del documento completo.
El resumen de documentos sería más robusto si se conocieran todos los subtópicos que lo forman, porque estos subtópicos se emplean como guía para la selección de las ideas principales que conformarán el resumen del documento.
Aunque se han encontrado algunas aproximaciones para resolver el problema de la segmentación, los resultados demuestran que estas no siempre tienen una alta calidad. Esto motivó la presente investigación en el que se describe el comportamiento de dos métodos de segmentación de documentos de múltiples párrafos y particularmente la segmentación de documentos que explícitamente explican o enseñan sobre un tópico, en los cuales es más probable que se repitan las palabras.
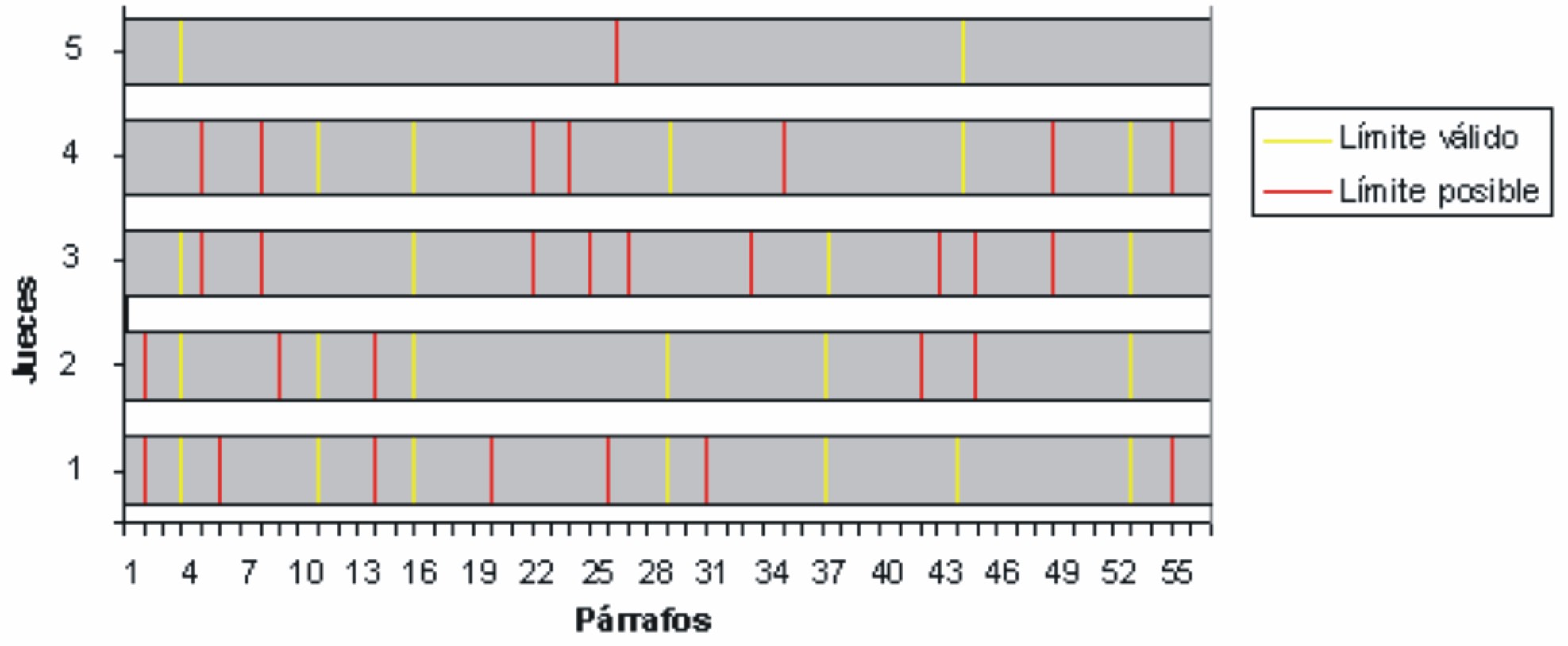
Para realizar el experimento, se escogió el primer acápite del capítulo 2 del libro titulado Mars, de Percival Lowell: Evidence of it.1 Este epígrafe tiene aproximadamente 55 párrafos y se segmentó manualmente por cinco personas. Se escogieron como válidos los siete límites de segmento (3, 10, 15, 28, 36, 43, 52), donde al menos existieron tres coincidencias (fig. 1).
FIG. 1. Resultados de la segmentación manual basada en el juicio humano.
A continuación, se aplicaron ambos algoritmos a los textos seleccionados. Se construyó, además, para continuar con el experimento, un texto con ocho subtópicos de siete artículos diferentes tomados de la enciclopedia libre Wikipedia: Solar System, Sun, Geography, Hydrography, Earth, Atmosphere, Animal y Soil; 2-8 seguidamente se realizó su segmentación con los algoritmos estudiados; se tomaron en este caso, como límites válidos, los límites exactos entre los ocho subtópicos escogidos.
Se calcularon entonces los valores de precisión, recobrado y de la métrica WindowDif para las segmentaciones de los dos algoritmos en ambos textos: Evidence of it, de Mars, y los artículos de Wikipedia.
Los resultados de estas investigaciones muestran que la cohesión léxica es un elemento muy útil para detectar los cambios de subtópicos en un texto, porque las unidades textuales que se relacionan fuertemente por una cohesión léxica comúnmente constituyen un segmento que abarca un subtópico simple.
A continuación se describirán dos métodos utilizados para la segmentación de textos en subtópicos y que se apoyan de alguna forma en la cohesión léxica para el proceso de segmentación. Pero antes, y aunque no es el objetivo de esta contribución, es oportuno precisar que existen algunos trabajos en el área de la segmentación, enfocados al descubrimiento de unidades de tópico y al descubrimiento de la estructura de subtópicos en los documentos.
Un ejemplo es el sistema elaborado por Stokes, Carthy y Smeaton, y que se denomina SeLeCT, orientado a distinguir noticias individuales en un programa de transmisión de noticias.10 SeLeCT se basa en el análisis de la fuerza de cohesión léxica entre las unidades textuales y utiliza una técnica lingüística llamada encadenamiento léxico.11
En esta misma línea se encuentra un método prepuesto por Ponte y Croft que comprende como objetivo de aplicación el rastreo de tópicos en trasmisiones de noticias y la identificación de tópicos en una base de datos documental. Su trabajo está dirigido hacia textos con tamaños de segmentos relativamente pequeños y para los cuales las oraciones dentro de los segmentos tengan relativamente pocas palabras en común; esto hace de la segmentación un problema más complicado. Este método emplea una técnica de expansión de consulta para encontrar rasgos comunes en los segmentos de tópicos.12
Segmentación en subtópicos propuesta por Hearst
Entre los métodos de segmentación que se dirigen a la identificación de estructuras de subtópicos en los documentos se encuentran el desarrollado por Hearst, quien propuso un algoritmo al que denominó TextTiling. Este algoritmo divide textos explicativos en unidades de discurso de múltiples párrafos. Contrario a muchos modelos de discurso, que asumen una segmentación jerárquica de este, el autor determinó representar el texto en una secuencia lineal de segmentos.13
El algoritmo tiene tres partes principales: preprocesamiento, cálculo de puntuaciones léxicas e identificación de los límites. En la primera se eliminan los stopwords o palabras negativas (proposiciones, artículos, etc.), se realiza un análisis morfológico del texto y los documentos se dividen en secuencias de palabras significativas, sin considerar signos de puntuación; a estas secuencias se les llama oraciones.
Luego se pasa a determinar una puntuación léxica para los espacios entre grupos de oraciones según sea el método que se escoja entre los dos propuestos en TextTiling . El primer método compara bloques adyacentes de texto, formados por un grupo de oraciones, y asigna una puntuación de similitud entre estos bloques de acuerdo con la cantidad de palabras que tengan en común. El segundo método, nombrado introducción de vocabulario, forma intervalos de texto con oraciones y asigna una puntuación léxica al punto medio del intervalo, basada en la cantidad de palabras nuevas (palabras no vistas antes en el texto) que aparecen alrededor de este punto medio.
Finalmente, la identificación del límite se realiza en forma idéntica para los dos métodos de puntuación léxica. Sobre esta base, se asigna una puntuación de profundidad a cada espacio entre oraciones donde ocurra un valle (baja puntuación léxica). La puntuación de profundidad del valle corresponde a cuán fuertemente cambiaron las señales para un subtópico en ambos lados del valle, basada en la distancia desde el valle a los dos picos que lo forman. En otras palabras, si una baja puntuación léxica es precedida y sucedida por una alta puntuación léxica, esto se asume como indicador de un cambio en el vocabulario que corresponderá, según lo asumido, con un cambio de subtópico. Seguidamente, las puntuaciones de profundidad se ordenan y se utilizan para determinar los límites de los segmentos; son las posiciones con puntuaciones más altas las de mayor probabilidad para que ocurran los límites.13
]]> Este algoritmo tiene un buen desempeño, pero presenta la dificultad que provoca la interrupción de un segmento que contenga un subtópico simple. Esto ocurre cuando existe un párrafo corto u otro que pueda hacer que se interrumpa la continuidad del sentido entre dos párrafos. El algoritmo no detecta este comportamiento porque, al bajar la puntuación léxica, notablemente en esta zona del texto el algoritmo asigna un límite de segmento.Segmentación en subtópicos propuesta por Heinone
Heinone, a diferencia de Hearst, propuso un método que emplea una ventana que recorre todo el texto y determina para cada párrafo el párrafo más similar dentro de la ventana. Esta se formará por una cantidad de párrafos superiores e inferiores al que se analiza.
Este método es muy útil cuando es necesario controlar la longitud (en cantidad de palabras) de los segmentos. El método de segmentación utiliza un método de programación dinámica para garantizar que se encuentren los límites de segmento de mínimo costo con respecto a una curva de cohesión léxica entre los párrafos, una longitud de preferencia para los segmentos especificada por el usuario y una función paramétrica definida de costo de longitud.14
Primeramente se construye un vector de cohesión ![]() con todos los párrafos del documento, donde a cada uno se le asocia el valor de similitud más alto en su ventana.
con todos los párrafos del documento, donde a cada uno se le asocia el valor de similitud más alto en su ventana.
Como en el algoritmo se considera la longitud de los segmentos, se utiliza una función de costo de longitud que determina la correspondencia entre la longitud de un segmento y la longitud deseada para este, ![]() , donde x es la longitud del segmento, plalongitud deseada, y h un parámetro de escala para ajustar las longitudes.
, donde x es la longitud del segmento, plalongitud deseada, y h un parámetro de escala para ajustar las longitudes.
La lógica que sigue el algoritmo es determinar los costos de segmentación para cada párrafo de forma secuencial del primero al último, según la siguiente expresión:

Además, por cada párrafo se determina su límite, que será el último párrafo del segmento anterior al que lo contiene. Este límite queda determinado por la expresión:
![]()
Comparación y evaluación de los resultados obtenidos con las propuestas de Hearst y Heinone
Evaluar los resultados de los algoritmos de segmentación tiene dos dificultades fundamentales. La primera está determinada por la naturaleza subjetiva de la detección de los límites físicos de los subtópicos, en la que pueden, incluso, estar en desacuerdo varios lectores humanos que decidan realizar esta tarea; esto hace difícil seleccionar un corpus de prueba para realizar las comparaciones.11,15 Frecuentemente, esta dificultad se resuelve al comparar el resultado de los algoritmos contra las marcas, encabezados o subtítulos, para identificar los subtópicos que especifica el autor del documento; pero estas marcas no siempre se precisan. Algunos comparan sus resultados contra un conjunto de documentos concatenados, donde se distingan diferentes tópicos. Mientras tanto, otros comparan contra el resultado de una segmentación manual basada en el juicio de varios lectores humanos.
La segunda dificultad es que la importancia de los tipos de errores depende de las aplicaciones donde se precisan las técnicas de segmentación; por ejemplo, en la recuperación de información pueden aceptarse límites de segmento que difieran en unas pocas oraciones del límite real del segmento. En cambio, para la segmentación de una transmisión continua de noticias es muy importante la exactitud de la ubicación de los límites.
Encontrar una métrica de evaluación adecuada para determinar la exactitud de un algoritmo de segmentación es un tema que ha generado mucha polémica. Una medida de evaluación que se ha utilizado por muchos autores es la de precisión y recobrado, que es una medida estándar en las experimentaciones con sistemas de recuperación de información. En la evaluación de la segmentación, la precisión y el recobrado se definen de la siguiente forma.
Precisión: El porcentaje que representan los límites de segmento correctamente detectados por el algoritmo del total de límites detectados por el algoritmo.
Recobrado : El porcentaje que representan los límites de segmento correctamente detectados por el algoritmo del total de límites reales detectados en la segmentación de referencia.
Esta medida de evaluación suele ser muy conveniente en aplicaciones donde es imprescindible la exactitud de la localización de los límites de segmento. Pero no es así en aquellas aplicaciones que no lo requieren, porque penaliza muy fuerte al algoritmo cuando encuentra límites que no coinciden exactamente con los límites reales, y no considera si existe proximidad entre ellos.
En el año 2000, Pevzner y Hearst propusieron una métrica denominada WindowDiff para mejorar el proceso de evaluación de la segmentación.15 WindowDif utiliza una ventana corrediza de longitud k para recorrer todo el texto y encontrar las discrepancias entre la segmentación de referencia y la que se obtiene como resultado del algoritmo.
En la literatura, se encuentran muchos autores que experimentan con varios tamaños de la ventana; es decir, con varios valores de k. En este trabajo, k se toma como la mitad del promedio del tamaño que tienen los segmentos en la segmentación de referencia como sugieren los autores de la métrica.
]]> En cada posición de la ventana, se determina para ambas segmentaciones el número de límites existentes en la ventana, y si el número de límites no es el mismo se penaliza el algoritmo. Posteriormente, se suman todas las penalizaciones que se encontraron en el texto completo y se normaliza este valor de forma que la métrica toma un valor entre 0 y 1. WindowDiff toma el valor de 0 si el algoritmo asigna todos los límites correctamente y toma el valor de 1 si difiere con la segmentación de referencia en todas las posiciones de la ventana. Más formalmente: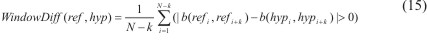
Donde b(i,j) representa el número de límites entre la posición i y j en el texto, N representa el número total de unidades textuales en el texto completo según sea el interés de la segmentación, como por ejemplo, oraciones o párrafos, ref es la segmentación de referencia y hyp la segmentación del algoritmo.
A continuación se compararán los resultados obtenidos con una segmentación manual y otra realizada con los algoritmos estudiados - TextTiling y Heinone.
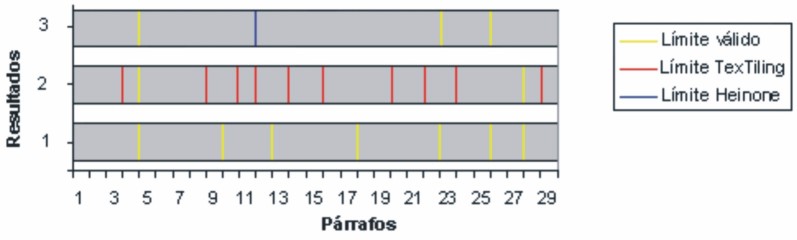
La segmentación manual (fig 1) produjo siete límites válidos, donde coincidieron al menos tres de los individuos que participaron en esta segmentación. Los resultados de los algoritmos coinciden en ocasiones con los límites que se especifican como válidos para los dos textos de referencia. Cuando esto no ocurre, los límites establecidos por ellos son próximos a los válidos (figs. 2 y 3).

FIG. 2. Resultados de la segmentación manual, TextTiling y Heinone.
Las medidas precisión y recobrado son poco ilustrativas para medir el desempeño de los algoritmos utilizados, porque ellas no consideran la proximidad de los límites encontrados sino la exactitud de estos.
Los resultados muestran un mejor desempeño del algoritmo de Heinone, con el que se obtiene una menor cantidad de límites falsos (tablas 1 y 2). Sin embargo, este algoritmo requiere de la especificación de la longitud aproximada de los subtópicos, un valor impredecible realmente y que no suele ser similar para todos los subtópicos de un documento.
Tabla 1. Valores de precisión, recobrado y WindowDif de la segmentación manual, TextTiling y Heinone, para el texto Evidence of it
| Algoritmos | Precisión | Recobrado | WindowDif |
| ]]> TextTiling | 7,14 | 28,57 | 0,75 |
| Heinone | 10 | 14,2 | 0,55 |
Tabla 2. Valores de precisión, recobrado y WindowDif de la segmentación manual, TextTiling y Heinone, para el texto de Wikipedia
| Algoritmos | ]]> Precisión | Recobrado | WindowDif |
| TextTiling | 16,67 | 28,57 | 0,5 |
| Heinone | 75 | 42,86 | ]]> 0,18 |
Se aprecia un comportamiento aceptable para ambos algoritmos, porque cuando no coinciden los límites de segmentos que estos presentan con los de segmentos considerados como válidos, se observa una cercanía entre ellos. Sin embargo, sus resultados distan mucho de ser los necesarios como para introducirse en la práctica real de un procesamiento automatizado de textos. Su perfeccionamiento depende precisamente de la eliminación de las deficiencias expuestas en esta contribución.
1. Lowell P. Mars S.n: s.e. 1895. Disponible en: http://www.wanderer.org/refere n ces/lowell/Mars/ [Consultado: 7 de marzo de 2007].
2. Solar System. Disponible en: http://en.wikipedia.org/wiki/Solar_System [Consultado: 8 de marzo de 2007].
3. Geography. Disponible en: http://en.wikipedia.org/wiki/Geography [Consultado: 8 de marzoabril de 2007].
4. Hydrography. Disponible en: http://en.wikipedia.org/wiki/Hydrography [Consultado: 8 de abril de 2007].
5. Herat. Disponible en: http://en.wikipedia.org/wiki/Soil [Consultado: 8 de abril de 2007].
6. Atmosphere. Disponible en: http://en.wikipedia.org/wiki/Atmosphere [Consultado: 8 de abril de 2007].
7. Animal. Disponible en: http://en.wikipedia.org/wiki/Animal [Consultado: 8 de abril del 2007].
8. Soil. Disponible en: http://en.wikipedia.org/wiki/Soil [Consultado: 8 de abril de 2007].
9. Halliday MAK, Hasan R. Cohesion in English. New York C: Longman Group. 1976.
10. Stokes N, Carthy J, Smeaton AF. SeLeCT: A Lexical Cohesion Based News Story Segmentation System. Dublin: IOS Press; 2004.
11. Stokes N. Applications of Lexical Cohesion Analysis in the Topic Detection and Tracking Domain. Dublin: Department of Computer Science Faculty of Science, National University Of Ireland. 2004.
12. Ponte JM, Croft WB. Text segmentation by topic. Massachusetts: Computer Science Department, University of Massachusetts. 1997.
13. Hearst MA. TextTiling: Segmenting Text into Multi-paragraph Subtopic Passages. Computational Linguistics. 1997;23(1):33-64. Disponible en: http://ucrel.lancs.ac.uk/acl/J/J97/J97-1003.pdf [Consultado: 9 de abril de 2007].
14. Heinonen O. Optimal Multi-Paragraph Text Segmentation by Dynamic Programming. Helsinki: University of Helsinki.1998.
15. Pevzner L, Hearst M. A Critique and Improvement of an Evaluation Metric for Text Segmentation. Computational Linguistics. 2002;28(1):19-36.
Recibido: 13 de abril de 2007 Aprobado: 17 de abril de 2007.
Dr.C. José E. Medina Pagola. Departamento Minería de Datos. Centro de Aplicaciones de Tecnologías de Avanzada (CENATAV). Calle 7ma. No. 21 812 e/ 218 y 222. Reparto Siboney, Playa. CP 12 200. La Habana, Cuba. Correo electrónico:jmedina@cenatav.co.cu
Términos sugeridos para la indización
Según DeCS1
PROCESAMIENTO AUTOMATIZADO DE DATOS/métodos; RESUMEN E INDIZACIÓN/ métodos.
AUTOMÁTICA DATA PROCESSING/methods; ABSTRACTING AND INDEXING/ methods.
Según DeCI2
PROCESAMIENTO DE LA INFORMACIÓN; PROCESAMIENTO DEL LENGUAJE NATURAL; PROCESAMIENTO DE TEXTOS/métodos; RESÚMENES.
INFORMATION PROCESSING; NATURAL LANGUAJE PROCESSING; WORD PROCESSING/methods; ABSTRACTS.
1BIREME. Descriptores en Ciencias de la Salud (DeCS). Sao Paulo: BIREME, 2004.
Disponible en: http://decs.bvs.br/E/homepagee.htm
]]> 2Díaz del Campo S. Propuesta de términos para la indización en Ciencias de la Información. Descriptores en Ciencias de la Información (DeCI). Disponible en: http://cis.sld.cu/E/tesauro.pdf1Doctor en Ciencias Técnicas. Departamento Minería de Datos. Centro de Aplicaciones de Tecnologías de Avanzada (CENATAV). Cuba.
2Licenciada en Ciencias de la Computación. Departamento Minería de Datos. Centro de Aplicaciones de Tecnologías de Avanzada (CENATAV). Cuba.