Procedimiento perfeccionado para la búsqueda bibliográfica en PubMed-Medline a través de Hinari
]]>
Improved procedure for the literature search from PubMed-Medline through Hinari
]]>
Rubén Cañedo AndaliaI; Karen Peña RodríguezII; Roberto Rodríguez LabradaIII; Omara Mercedes Cardona SánchezIV; Elizabeth Concepción ReyesV
ILicenciado en Información Científico-Técnica y Bibliotecología. Departamento Fuentes y Servicios de Información. Centro Nacional de Información de Ciencias Médicas-Infomed.
IILicenciada en Educación en idioma Inglés. Centro Provincial de Información de Ciencias Médicas. Holguín. Cuba.
IIILicenciado en Microbiología. Centro para la Investigación y la Rehabilitación de las Ataxias Hereditarias. Holguín, Cuba.
IVLicenciada en Gestión de Información en Salud. Policlínico universitario "Camilo Torres Restrepo". Santiago de Cuba, Cuba.
VTécnico Medio en Información Científico-Técnica y Bibliotecología. Centro Provincial de Información de Ciencias Médicas. Holguín. Cuba.
]]>
La búsqueda bibliográfica es una etapa condicionante de la investigación como proceso central de la actividad científica. Sin embargo, con frecuencia recibe poca atención entre los investigadores y este es un factor determinante de sus pobres resultados en esta actividad. Se expone una forma lo más sencilla posible para la búsqueda de información efectiva en la base de datos PubMed-Medline desde Hinari, con vista a facilitar su exploración y a continuación la manera en que es posible realizar un análisis métrico simple de los resultados hallados en la búsqueda realizada en la base de datos objeto de estudio.
]]> Palabras clave: Bases de datos, bibliografía, ciencias de la salud.
The literature search is a time constraint of research as the central process of scientific activity. However, often receives little attention among researchers and this is a factor in their poor research in this activity. It sets out a form as simple as possible for effective information search database from PubMed-Medline through Hinari in order to facilitate their exploration and then the way it is possible to make a simple metric analysis of the results found in the search held in the database under study.
Key words: Databases, bibliography, health sciences.
]]>
La búsqueda bibliográfica es una etapa condicionante de la investigación como proceso central de la actividad científica. Puede dividirse en tres etapas principales: planificación, ejecución y evaluación. Entre ellas, la primera es la más importante. En esta fase deben identificarse los conceptos, aspectos y límites que comprenden cada necesidad de información, así como expresar estos de manera que el sistema de recuperación los entienda. Para poder realizar esta conversión es esencial el conocimiento, tanto de los requisitos semánticos y formales de la necesidad como de las características y facilidades que presenta la base de datos que nos proponemos consultar.
Un problema de investigación puede generar una o varias necesidades de información en dependencia de su complejidad. La formulación de dichas necesidades en los términos y formas que comprende el sistema de recuperación de la información y que normalmente es el intermediario entre el usuario y una o varias bases de datos se denomina, indistintamente, prescripción, condición o estrategia de búsqueda. La estrategia propiamente dicha abarca el contenido o temática de la necesidad, así como algunos de sus aspectos formales como son: el idioma, las fechas de publicación, los tipos de documentos, etcétera.
Durante la fase de ejecución, el usuario introduce su estrategia de búsqueda, observa los resultados y realiza los ajustes necesarios a su estrategia inicial con el fin de obtener una mejor correspondencia entre los resultados que entrega el sistema y sus necesidades de información.
]]>Para la evaluación de los resultados de la utilización de una estrategia de búsqueda, generalmente se emplean diversos puntos de vista y conceptos como son: relevancia, pertinencia, recobrado y precisión. La primera se mide por el número de documentos recuperados cuyo contenido responde a la estrategia formulada; la pertinencia depende más de la capacidad de quien interactúa con el sistema para desarrollar una prescripción de búsqueda eficaz y se evalúa según el grado de correspondencia que existe entre los documentos recuperados y la necesidad de información del usuario. El recobrado (también llamado sensibilidad), por su parte, se refiere a la capacidad de la estrategia de búsqueda para recuperar la mayor parte posible de los documentos existentes en la base de datos, relacionados con el tema objeto de búsqueda. Finalmente, la precisión (también denominada especificidad) se refiere a la capacidad de la estrategia para discernir entre los documentos existentes en la base de datos objeto de exploración, aquellos que mejor responden a la prescripción de búsqueda. La evaluación de los resultados de la búsqueda depende en gran medida de la intención de quien la realiza. Si el interés es recuperar el mayor número de referencias posible entonces un alto recobrado será un indicador apropiado para medir la calidad de la exploración; si lo que se requiere es que los resultados presenten la mayor correspondencia semántica posible con la prescripción de búsqueda, entonces será el nivel de precisión de los resultados el que medirá su calidad como proceso de búsqueda y así sucesivamente. En general estas nociones son difíciles de determinar debido a los volúmenes de información que es necesario manejar, pero sobre todo a causa del grado de subjetividad que encierran.
Sin embargo, con frecuencia la necesidad de información como tal no se satisface solo como resultado de la utilización de una estrategia de búsqueda eficaz en la recuperación de la información en uno o varios recursos, y requiere a menudo del diseño de un servicio personalizado que considere, además de los aspectos relativos a la semántica de la necesidad, los relacionados con la estructura y requerimientos de la actividad o actividades profesionales que desempeña el usuario y en el seno de las cuales se originan las necesidades de información que el servicio pretende satisfacer, las condiciones en que se realizan estas, así como las características sociopsicológicas y culturales de quienes se propone servir.1
No es nuestro propósito tratar la evaluación de las estrategias de búsqueda o de los servicios de información propiamente dichos, sino exponer una forma lo más sencilla posible para planificar y ejecutar la búsqueda de información de manera efectiva en la base de datos PubMed-Medline a través de Hinaria.
PubMed (http://preview.ncbi.nlm.nih.gov/pubmed) es el recurso bibliográfico más utilizado en el área de la salud en Internet. Cubre los campos de la medicina, la enfermería, la estomatología, la veterinaria, la gestión de salud, las ciencias preclínicas y algunas áreas de las ciencias de la vida. Sus archivos contienen más de 20 millones de registros desde el año 1865 hasta la fecha y procesa casi 5 200 revistas de unos 80 países, seleccionadas mediante un riguroso proceso de evaluación. Contiene referencias en su colección de más de 140 000 revisiones sistemáticas (más de 6 000 realizadas por los grupos de revisión de la Colaboración Cochrane); de unas 15 000 guías para la práctica clínicab, más de 600 000 informes de ensayos clínicos y más de millón y medio de artículos de revisión. Procesa los contenidos de fuentes de referencia clínica tan importantes como Cochrane Database of Systematic Review y Clinical Evidence. PubMed contiene alrededor de 1,9 millones de registros más que los procesados para Medline (PubMed: 20,3 millones; Medline: 18,4 millones), su subconjunto fundamental y más conocido. Incorpora además en un plazo de 72 horas la mayor parte de los artículos publicados por Biomed Central y más de 1 millón 650 mil (alrededor del 80 %) del total de 2 millones de los registrosc que procesa PubMed Centrald (Valjavec-Gratian M. About PubMed Central. 24 de octubre de 2010. Comunicación vía correo). Una búsqueda en PubMed comprende: referencias bibliográficas "en proceso" de inclusión en Medline; referencias a fuentes (revistas esencialmente) que preceden a su fecha de ingreso a la base de datos; referencias a trabajos no cubiertos en Medline; referencias a manuscritos de autores pertenecientes a los Institutos Nacionales de Salud de los Estados Unidos publicados en revistas no procesadas por Medline, así como de algunas revistas en ciencias de la vida; etcétera.
Para cumplir con el objetivo referido trataremos primero algunos elementos que es imprescindible dominar antes de enfrentarse directamente al trabajo con la base de datos y a continuación, mediante un ejemplo, se mostrará el uso de la estrategia construida para la exploración de dicha base desde Hinari.
PLANIFICACIÓN DE LA BÚSQUEDA
La planificación de la búsqueda es una fase esencial, previa a su ejecución y de la que depende, en gran parte, la evaluación de sus resultados. Sin embargo, con frecuencia recibe una escasa atención entre los investigadores como consecuencia de la existencia de una inadecuada concepción sobre la búsqueda bibliográfica, que le niega su carácter de investigación documental con exigencias nada inferiores a los de la investigación histórica, social u otras. Esta insuficiencia se convierte entonces en una de las causas principales de sus pobres resultados de investigación.
El conocimiento de las características de las bases de datos, como son su cobertura temática, documental, geográfica e idiomática; la retrospectividad de la colección y su período de actualizacióne, entre otros, así como de las facilidades que ofrece su sistema de recuperación: vocabularios controlados (tesauros, encabezamientos de materias), operadores (lógicos, de proximidad), opciones para restringir la recuperación de resultados (límites), posibilidades para el agrupamiento de los términos (paréntesis o corchetes) y para el truncado, estructura de los campos y otras, son imprescindibles para formular una estrategia de búsqueda moderadamente adecuada. En dependencia de las posibilidades que ofrece el sistema, la estrategia tomará una forma u otra y será necesario trabajar más o menos para conseguir los resultados deseados.
Pensemos que la investigación que nos ocupa pretende desarrollar nuevas técnicas para diagnosticar la ataxia espinocerebelosa tipo 2, una enfermedad de base genética con una alta tasa de prevalencia en Cuba.2 El primer paso antes de involucrarse en una investigación cualquiera es revisar la literatura existente con el fin de determinar la disponibilidad de bibliografía útil desde diferentes puntos de vista para nuestros propósitos. El tema de la búsqueda pudiera formularse entonces como sigue: diagnóstico de la ataxia espinocerebelosa tipo 2.
]]>
El primer paso es la identificación de los conceptos, aspectos y límites apropiados para el tema objeto de exploración. En este caso, el único concepto que se trata es la ataxia espinocerebelosa tipo 2. El aspecto que interesa específicamente es su diagnóstico —obsérvese cómo se produce una relación similar a la que ocurre entre el sustantivo y el adjetivo en la gramática española donde el adjetivo califica al sustantivo—. Es precisamente por esta razón que a estos aspectos se les denomina calificadores en el argot de la recuperación de la información. La presencia explícita de un aspecto de interés (diagnóstico) facilita elevar considerablemente la precisión de los resultados de la búsqueda.
A priori, sabemos que PubMed-Medline posee un vocabulario controlado y jerárquico de encabezamientos de materia (Headings), compuesto por más de 25 000 términos (y otros 170 000 términos de entrada que facilitan el acceso a los autorizados por el vocabulario),3 rigurosamente desarrollado: el MeSH (http://preview.ncbi.nlm.nih.gov/mesh). Este, a su vez, presenta una versión en español: el DeCS (http://decs.bvs.br/E/homepagee.htm), útil para aquellos usuarios que no dominan la terminología médica en inglés. De hecho, el usuario que utilice el DeCS también requerirá utilizar el MeSH. Más adelante volveremos sobre este aspecto.
Conocemos también que PubMed-Medline dispone de Limits (http://preview.ncbi.nlm.nih.gov/pubmed/limits), una opción muy bien desarrollada, que posibilita restringir los resultados de las búsquedas por diversos criterios de valor general y clínico:
Finalmente, esta página permite limitar los términos de búsqueda por campos específicos (Search field tags). Los límites además pueden utilizarse para descubrir información importante sobre nuestros temas de investigación.5
Supongamos que, en nuestro caso hipotético, se requiere que la literatura se encuentre en inglés o español; que los estudios fueran realizados en humanos; publicados durante los últimos cinco años; y que solo interesan aquellos que poseen acceso libre al texto completo del material.
Este es el momento de acceder primero a los vocabularios y después a la base de datos seleccionada. Accedamos al DeCS. Copiemos y peguemos la dirección del DeCS en una ventana de nuestro navegador. Al oprimir Enter, este nos llevará al DeCS (figura 1).
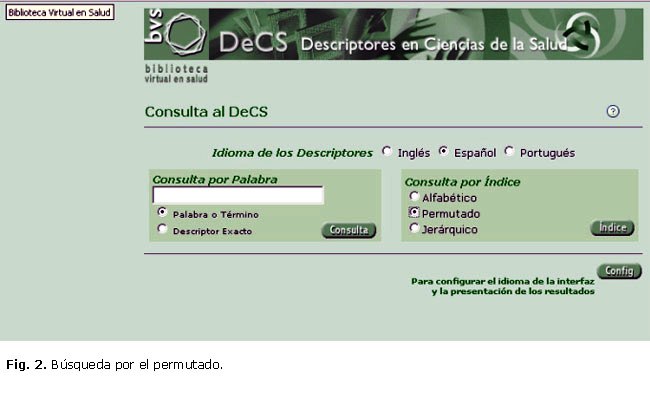
]]>Escojamos la opción Consulta al DeCS. Seleccionemos entonces la opción Permutado del Índice (figura 2).
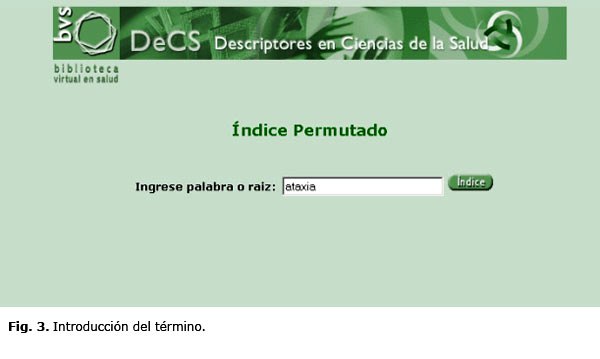
Esta opción nos facilita introducir uno o varios términos que conozcamos previamente y que se utilizan con cierta frecuencia para representar la entidad buscada. Este índice nos llevará de los términos no autorizados a los autorizados. Tecleemos, por ejemplo, la palabra ataxia y hagamos clic sobre el botón Índice (figura 3).
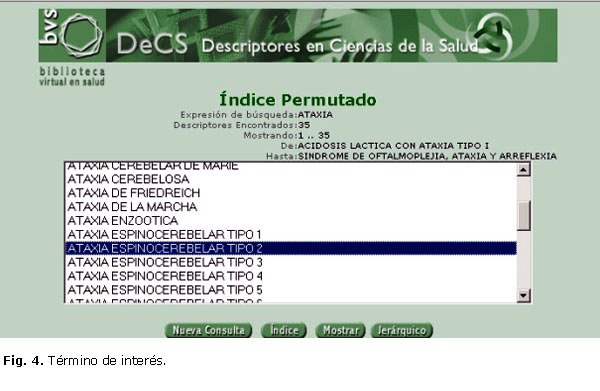
Demos clic sobre el término ATAXIA ESPINOCEREBELAR TIPO 2 (figura 4) y oprimamos el botón Mostrar.
]]> El sistema nos devuelve inmediatamente el término autorizado: Ataxias espinocerebelosas, en inglés Spinocerebellar ataxias. También nos informa los términos que contiene como sinónimos (Sinónimos Español); la definición de la entidad (Definición Español), así como los calificadores permitidos Español (figura 5).
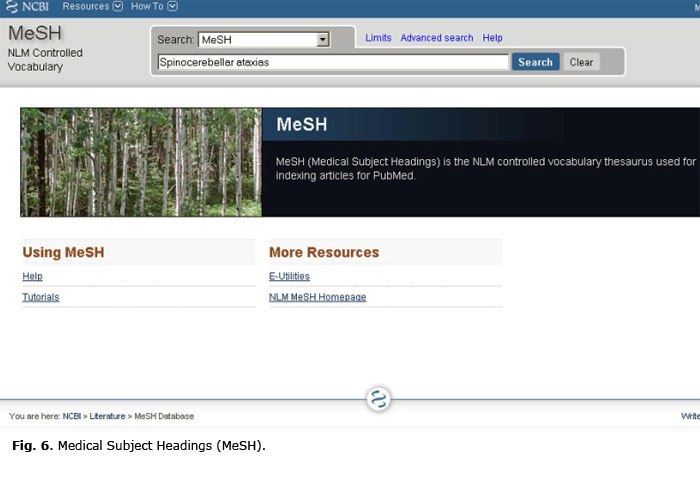
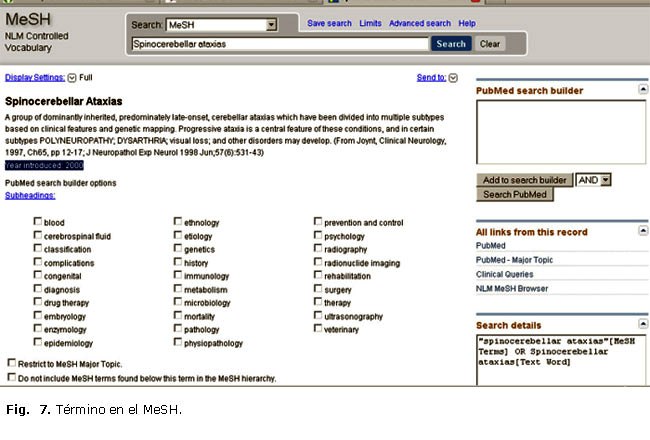
Una vez conocido el término controlado autorizado en inglés, accedamos al MeSH, tecleemos el término y hagamos clic en el botón Go (figura 6).
El vocabulario nos entrega un registro muy parecido al que nos presentó el DeCS. Sin embargo, este posee, además de la información antes referida, el año de introducción del término en el MeSH. Este dato es singularmente importante porque nos indica a partir de qué momento se introdujo este para la indización de los documentos con esa temática que ingresan a la base de datos (figura 7). Pueden apreciarse también otros elementos antes mencionados, como los calificadores (Subheadings o subencabezamientos de materia) y la definición de la enfermedad en inglés. En caso de que no exista el término controlado para representar el concepto que buscamos, puede, eventualmente, utilizarse la opción Preview/Index, que permite consultar el índice de palabras y frases significativas desarrollado por la base de datos a partir del total de vocablos, nombres de autores y sustancias, siglas y otros existentes en la totalidad de sus registros.
]]> Puede apreciarse una larga lista de entidades que entran bajo este término al vocabulario, lo que nos da una idea de su generalidad con respecto al tema sobre el cual deseamos recuperar información. A este hecho se suma que existen unos 30 tipos de ataxias y solo nos interesa el diagnóstico de una de ellas (figura 8).
También pueden observarse, si existen, los vocablos controlados que se utilizaron antes de la introducción del término actual para la indización de la condición o trastorno objeto de interés (Previous indexing) (figura 9). Esto reviste especial importancia porque nos especifica con cual término debe realizarse la búsqueda en cada período. Además, nos indica el lugar que ocupa en el término en la estructura jerárquicafdel vocabulario, un dato también relevante debido a su influencia en la precisión de la búsqueda, porque el sistema recupera por omisión (a menos que se especifique lo contrario) los términos que se encuentran subordinados en la jerarquía al término objeto de búsqueda (anexo 1, código de campo: MH).
Los datos recuperados pueden sintetizarse de la siguiente manera: para buscar información sobre las ataxias en PubMed-Medline es posible utilizar el encabezamiento de materia Spinocerebellar ataxias, aunque es muy general con respecto a nuestros intereses (la ataxia espinocerebelosa tipo 2). Aun con esa limitación, la existencia de un término controlado para restringir o precisar los resultados de la búsqueda es una magnífica ventaja. Este encabezamiento de materia se introdujo en el año 2000; entonces nos es útil para el período que deseamos establecer como límite temporal (últimos cinco años).
Según las posibilidades que ofrece el sistema para la búsqueda temática, existen tres opciones fundamentales: emplear solo los términos de indización: principales y secundarios [MH] o solo los principales [MAJR]; utilizar palabras o frases claves en campos como Título del artículo [TI] y Título del artículo y Resumen [TIAB] que ofrece la base de datos; o usar una combinación de ambas.
La decisión sobre cual opción utilizar, obviamente, dependerá de los requerimientos de las necesidades de los usuarios y de su pericia para la búsqueda. La primera opción incrementa significativamente la precisión de los resultados recuperados siempre que existan los términos exactos que necesitamos. El total de los materiales procesados para la base de datos referida, se indizan por profesionales dedicados a esta tarea.
]]> La segunda opción, de palabras y frases claves, de forma general aumenta el recobrado pero disminuye la precisión de los resultados de la exploración bibliográfica, y requiere como prerrequisito importante el conocimiento de las formas más comunes con las que se describe la entidad buscada para elevar la cantidad de registros recuperados y evitar la pérdida de información de utilidad como resultado de los efectos indeseables de la sinonimia que caracteriza a los lenguajes naturales. Veamos un ejemplo que hemos estado utilizando en los últimos tiempos, el caso de la ataxia espinocerebelosa tipo 2.2 En el estudio realizado se encontraron las formas principales en que se trata esta entidad en la literatura:
La última alternativa la combinación de términos del vocabulario controlado y de palabras y frases claves del lenguaje natural en el caso de términos de indización que comprenden "algo" mucho más amplio que lo que se busca en realidad (como ocurre en el caso que nos ocupa), sirve para aumentar la precisión de los resultados.
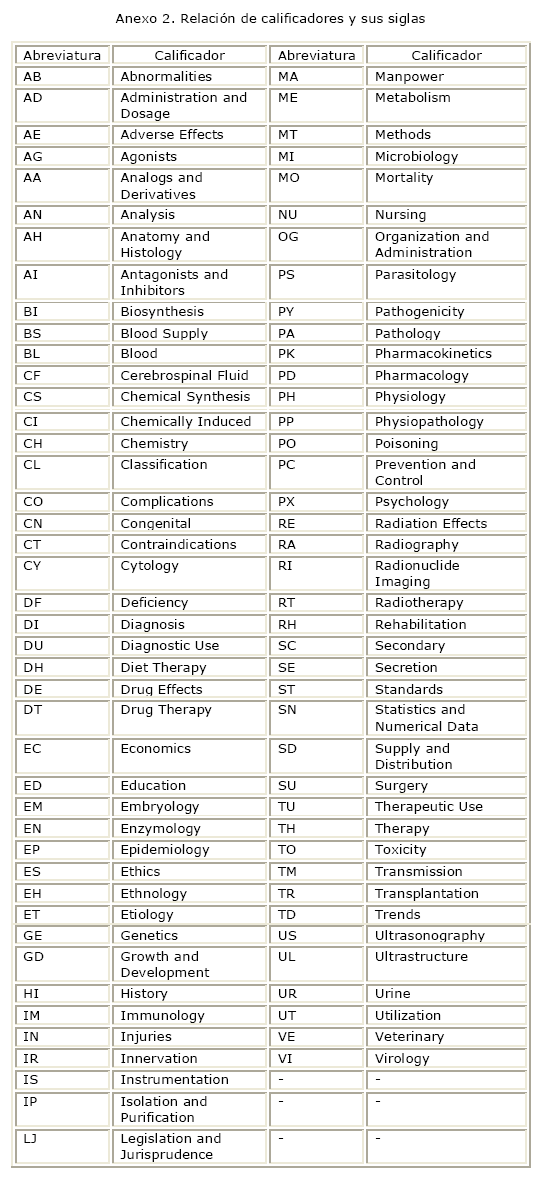
]]> Por su parte, el encabezamiento de materia acepta el calificador Diagnosis (DI), que es el aspecto que nos interesa de la entidad objeto de estudio téngase en cuenta que cada clase de encabezamiento de materia presenta sus propios calificadores, y los límites de que disponemos ya los conocemos y sabemos cuáles utilizaremos. Construyamos entonces nuestra estrategia de búsquedag a partir de la información recopilada y la que ofrecen los anexos de la presente contribución (anexos 1, 2 y 3).
Spinocerebellar Ataxias/DI[MH] AND (SCA2[TIAB] OR SCA 2[TIAB] OR Spinocerebellar ataxia 2[TIAB] OR Spinocerebellar ataxia type 2[TIAB] OR Type 2 spinocerebellar ataxia[TIAB]) AND (loattrfree full text[SB] OR loprovhinari[SB])
Donde:
- Spinocerebellar Ataxias: es el encabezamiento de materia.
- /DI: es el calificador. Puede utilizarse la sigla o el calificador en forma literal: diagnosis (anexo 2).
- AND: es el operador lógico "Y". Además de AND, el sistema permite el OR u "O" lógico y el NOT o "NO" lógico.
]]> - (SCA2[TIAB] OR SCA 2[TIAB] OR Spinocerebellar ataxia 2[TIAB] OR Spinocerebellar ataxia type 2[TIAB] OR Type 2 spinocerebellar ataxia[TIAB]): son las cinco formas principales con que se representa el concepto de interés en el lenguaje natural en el inglés escrito, según PubMed-Medline.2 Es importante señalar que hallar estas variantes es un proceso que solo puede realizarse manualmente y mediante la inspección visual de las formas de expresión que se utilizan, tanto en los títulos como en los resúmenes de los trabajos recuperados durante el proceso de exploración inicial.- (loattrfree full text[SB] OR loprovhinari[SB]): es una condición que le especifica al sistema que recupere solo aquellos documentos que posean acceso libre al texto completo, sea por medio de PubMed-Medline o de Hinari. Se emplea esta forma porque la opción Text options de la página de límites no permite especificar "Texto completo en Hinari", como es obvio, ya que no procedería colocar una alternativa como esta (limitada para los países en desarrollo) en un sistema que está a disposición del mundo.
PROCEDIMIENTO PARA LA REALIZACIÓN DE LA BÚSQUEDA
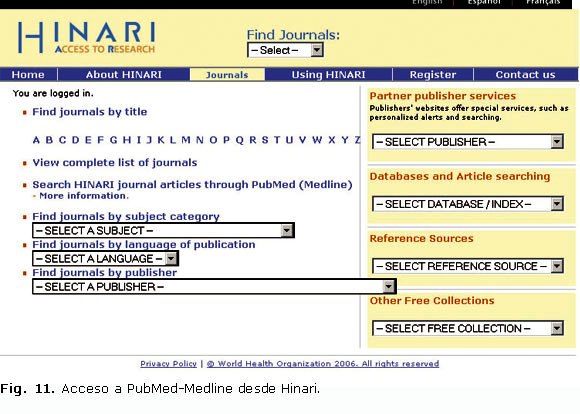
Accedamos entonces a PubMed-Medline desde Hinari. A Hinari se accede en Cuba, desde la página de Infomed (http://www.sld.cu)h. Su enlace se encuentra en el cuadro de Esenciales, que aparece al principio de la columna izquierda de la referida página (figura 10). Una vez cargada la página de Hinari, debe seleccionarse la opción Search HINARI journal articles through Pubmed (Medline) (figura 11). En este momento es posible introducir nuestra estrategia en la caja de búsqueda que nos ofrece el sistema en su página inicial (figura 12).
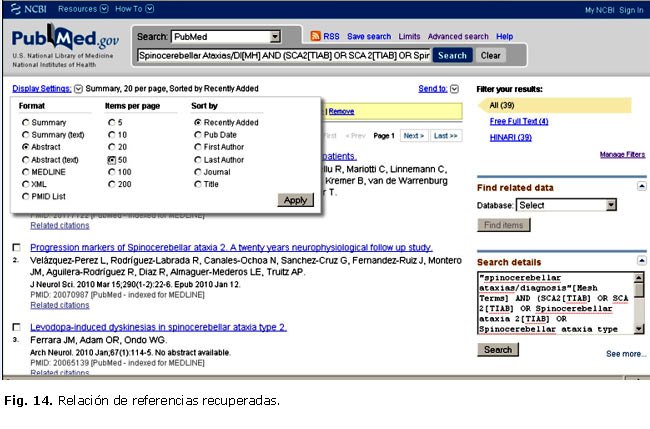
]]> A continuación podemos establecer lo límites predefinidos como de interés a los efectos de la búsqueda mediante la opción Limits. Es algo simple, solo se requiere desplegar cada uno de los menús que nos ofrece el sistema para cada tipo de límite y marcar los de interés. Finalmente, se oprime el botón Search (figura 13). Ahora el sistema nos devolverá los resultados que responden a los intereses temáticos y restricciones establecidas para la realización de la búsqueda.En total son 39 documentos (29 de junio de 2010; 12:45 PM). Para ver los registros con su resumen, despleguemos Display settings y marquemos en la opción Format: Abstract y en la opción Items per page: 50, para que el sistema nos muestre en una sola página el total de los registros (39)i. Oprimamos entonces el botón Apply (figura 14).
El sistema nos muestra las 39 referencias con sus resúmenes (siempre que estas los posean). Debajo de cada resumen aparecen íconos que nos indican el acceso libre al texto completo (figura 15). Al oprimir el primero: Full Text Neurology, el sistema nos indica que no podemos acceder a él porque no estamos suscritos (figura 16), aun cuando le especificamos que recuperara solo los documentos que dispusieran de acceso libre al texto completo.
Sin embargo, al oprimir el botón Hinari, el sistema nos permite acceder al documento (figura 17).
]]> Pudiera incluso ocurrir que al oprimir los dos botones no pudiéramos acceder libremente al texto completo del documento que nos interesa. Sin embargo, puede que aún en este caso "todo no esté perdido". Con los datos de la publicación: autor, título, fuente, etc., podemos probar a:
Si una vez examinados los resultados de la búsqueda, estos resultan insuficientes o si durante dicho examen hallamos una referencia de especial importancia para nuestros intereses, puede utilizarse el recuadro que aparece en la columna de la derecha titulado Related citations, que nos presenta una lista de referencias existentes en la base de datos que guardan una relación muy estrecha con la que observamos en ese momento en nuestra pantalla. Incluso, esta es una práctica que no debe solo utilizarse cuando recuperamos poco material, sino que debe convertirse en una especie de hábito inconsciente para la revisión de los resultados de cualquier búsqueda.
Una vez descargados los documentos de interés, podemos volver a interrogar el sistema, esta vez con una condición que permita recuperar las referencias y resúmenes de los materiales que no disponen de acceso libre al texto completo. Para esto debemos proceder a sustituir el último AND por un NOT, que indica al sistema que recupere aquellos documentos que no poseen cumplen con la condición requerida en la primera exploración. Introducimos entonces la nueva búsqueda en la caja destinada para estos fines:
Spinocerebellar Ataxias/DI[MH] AND (SCA2[TIAB] OR SCA 2[TIAB] OR Spinocerebellar ataxia 2[TIAB] OR Spinocerebellar ataxia type 2[TIAB] OR Type 2 spinocerebellar ataxia[TIAB]) NOT (loattrfree full text[SB] OR loprovhinari[SB])
El sistema nos devuelve cuatro nuevos materiales (29 de junio de 2010; 13:50 PM). Si son de nuestro interés, para obtener su texto completo podemos probar las alternativas antes referidas para este caso.
Antes de terminar la sesión de trabajo, debemos guardar en nuestra máquina, tanto las estrategias de búsqueda utilizadas, como las listas de referencias (con sus resúmenes) recuperadas. Para guardar debidamente la estrategia de búsqueda que hemos concebido (incluye sus límites) debemos utilizar la opción Search detail, ubicada en la columna derecha de la página de resultados (figura 14). Para esto es suficiente con copiar el contenido que aparece en su caja y pegarlo, por ejemplo, en un documento Word. Conservar las estrategias utilizadas nos será muy útil después, tanto para la elaboración de la sección de Métodos del informe de la investigación que pretendemos desarrollar, como para la realización de un análisis métrico con algunos de los sistemas disponibles para esto.6
Para guardar los resultados de la búsqueda, es decir, la lista de referencias y resúmenes recuperados, a pesar de existir varias opciones en Send to —y en servicios como el RSS y los que prestan los gestores bibliográficos—, entre las que se encuentran el almacenamiento de un fichero con formato texto en nuestra máquina o el envío de los resultados por correo electrónico, la forma que puede facilitar más su posterior empleo en nuestras condiciones de navegabilidad es copiar y pegar la página de los resultados en un documento Word. Esta alternativa, tal vez "anticuada" a la luz de las condiciones de navegabilidad que disfrutan muchas instituciones no solo a escala internacional, sino también a nivel nacional, si nos atenemos a la media de accesibilidad existente en el país nos permite continuar trabajando aún con un mínimo de condiciones tecnológicas. Claro, que desde el fichero con los resultados de la búsqueda en nuestra máquina no se podrá acceder directamente a los documentos en Hinari, porque el uso de este sistema requiere de un proceso de autenticación que se produce al pasar un usuario del dominio .sld.cu por Infomed, como se dijo antes. Para conseguir esto, se debe acceder nuevamente al sistema desde Infomed y repetir la búsqueda, algo muy fácil si guardamos la estrategia utilizada en un documento en nuestra máquina, y que consiste simplemente en copiar y pegar la estrategia de búsqueda en la caja de Pubmed-Medline, destinada a estos fines, y oprimir el botón Search. En general, para guardar las estrategias de búsquedas y otros datos relativos a la exploración bibliográfica pueden utilizarse los mismos procedimientos que para los resultados de las búsquedas.
Una vez que disponemos de una estrategia de búsqueda que satisfaga al menos semánticamente nuestras necesidades de información, podemos crear un perfil de diseminación selectiva de la información sobre la base del servicio de RSS (Really Simple Syndication) que ofrece PubMed-Medline. Para esto, antes debe:
Esto nos permitirá recibir en nuestra computadora hasta 100 de las referencias recuperadas en la búsqueda, así como las que se añadan en el futuro a dicha base y que respondan exactamente a la estrategia formulada.
Las referencias recibidas por este medio, sin embargo, no contienen —aun cuando los tenga— los íconos para el acceso al texto completo de los materiales recuperados que presentan acceso libre en Hinari. Esta es una limitación importante para el empleo de esta facilidad de PubMed-Medline, no importa desde dónde se realice la búsqueda, si en la base de datos directamente o desde Hinari. En caso de que por esta razón se decida no utilizarla, el usuario puede —cada vez que lo desee y disponga de la conectividad adecuada— repetir la búsqueda en la base de datos; incluso para esta última opción, un límite como el de fecha, con opciones como 30, 60, 90 y 180 días, puede ser una alternativa útil. Claro, implica llevar cuidadosamente un registro de la última fecha en que se realizó cada una de las exploraciones.
Finalmente, es posible guardar los resultados de la búsqueda en alguno de los gestores de referencias bibliográficas disponibles actualmente como EndNote (propietario) y Zotero (libre).
ANÁLISIS MÉTRICO DE LOS RESULTADOS DE UNA BÚSQUEDA REALIZADA EN PUBMED-MEDLINE
Tal vez este es el momento más propicio para esbozar cómo obtener los datos necesarios para realizar un sencillo análisis métrico del comportamiento de los componentes que forman la cadena de la comunicación científica en nuestro tema de interés. Para esto debemos utilizar la estrategia sin la condición que especifica al sistema "que debe" o "que no debe" recuperar documentos que posean acceso libre al texto completo, es decir: (loattrfree full text[SB] OR loprovhinari[SB]), así como su correspondiente operador lógico (AND o NOT). Con esto se evita añadir nuevos sesgos a los resultados de la búsqueda. La estrategia quedaría como sigue:
"spinocerebellar ataxias/diagnosis"[Mesh Terms] AND (SCA2[TIAB] OR SCA 2[TIAB] OR Spinocerebellar ataxia 2[TIAB] OR Spinocerebellar ataxia type 2[TIAB] OR Type 2 spinocerebellar ataxia[TIAB]) AND ("humans"[MeSH Terms] AND (English[lang] OR Spanish[lang]) AND "2005/07/01"[PDat]: "2010/06/29"[PDat])
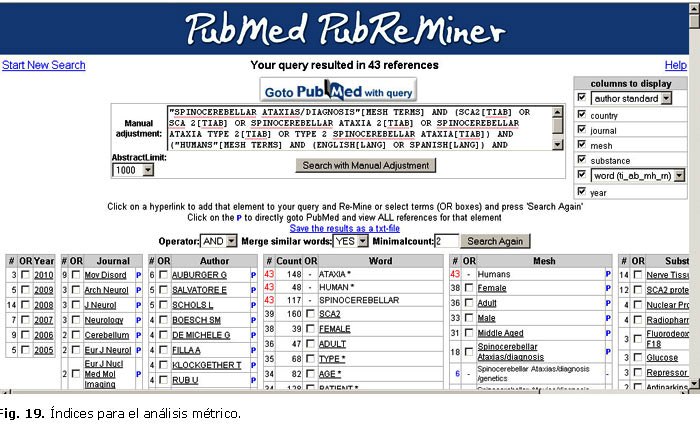
]]>Utilizaremos para el análisis PubReMiner (http://bioinfo.amc.uva.nl/human-genetics/pubreminer/). Peguemos entonces la estrategia copiada de la ventana Search detail de PubMed-Medline a la ventana denominada Start remining PubMed for: de PubReMiner y oprimamos el botón Start PubReMiner (figura 18). Preferimos en general utilizar PubReMiner a GoPubMed (http://www.gopubmed.org/web/gopubmed/1?WEB111Ogomeshpubmed_2FSearch_2FWEB16OWEB10O000h001000900001), a pesar de las prestaciones semánticas y gráficas de este último, ya que PubReMiner presenta una alta estabilidad para su uso (prácticamente siempre está disponible y es muy fácil acceder a él desde Infomed por su rapidez para cargarse); una mayor capacidad para procesar estrategias de búsqueda complejas elaboradas para PubMed-Medline, una mayor ventana "real" para el procesamiento de registros (Abstract limit: hasta 10 000), un entorno textual que lo hace de más fácil acceso en nuestras condiciones de bajo ancho de banda para el acceso a la red y la posibilidad de llevar la mayoría de los índices hasta la frecuencia 1. Esta última facilidad posee un gran valor, por ejemplo, para el análisis y normalización de los índices de autores, donde muchas veces es necesario unificar la producción de un mismo autor que aparece como si fueran varios, por la cantidad de formas de escritura que se emplean para llamarlo.
Como puede observarse, el sistema nos presenta índices de año, fuente (publicación seriada o revista), autor, palabras, términos MeSH, sustancias y países. Entre otras facilidades, el sistema posibilita incorporar nuevos datos para modificar el análisis realizado; recuperar todas las referencias que presentan un valor específico en PubMed-Medline; así como guardar en un fichero .txt los resultados del análisis realizado (figura 19).
La primera columna nos presenta la distribución por años de la bibliografía recuperada. Ella nos indica con claridad algo tan elemental como es el hecho de si se trata de un área del conocimiento en crecimiento, estancada o en retroceso.
La segunda columna ofrece una información muy útil, se trata de un índice de frecuencia de los títulos de revistas organizados en forma descendente según su productividad para el tema objeto de exploración. Esto sirve tanto a autores y lectores como a los profesionales de la información. Conocer cuáles títulos de revistas publican con mayor frecuencia en un área de interés sirve a los autores para determinar cuáles revistas son las más apropiadas para difundir sus trabajos; a los lectores, para enfrentarse a un sistema como Hinari, donde esta es una información imprescindible para explorar con eficacia su extensa colección de revistas (más de 7 000), ya que el sistema carece de una interfaz única de búsqueda que posibilite la exploración completa de la referida colección de una sola vez; y a los gestores, consultores, referencistas o consejeros en temas de información y publicación, para orientar a sus usuarios sobre cuáles son las fuentes que mejor pueden servirle en ciertos campos del conocimiento a partir de una base de datos con una cobertura tan amplia como PubMed-Medline.
En relación con el índice de autor, aun cuando presenta ciertas deficiencias sobre todo con respecto a la identificación correcta de los autores hispanos, y que como consecuencia reduce sus posibilidades de aparecer mejor ubicados en la clasificación que realiza el sistema de ellos, sirve de base para: a) guiarse en la búsqueda de los autores más productivos en un tema de interés y b) reelaborar una clasificación mejor a partir de la realización de una cuidadosa labor de normalización de los nombres de los autores, posibilidad que nos brinda el sistema al relacionarnos hasta los autores con frecuencia 1 (se explicó antes su significado) en el índice. Los índices de palabras, términos MeSH y sustancias posibilitan conocer los aspectos en nuestro tema de interés que se tratan con mayor frecuencia.
]]> Por último, el sistema nos presenta un índice de países que nos permite hallar los de mayores niveles de producción en el área del conocimiento de nuestro interés. Es necesario advertir que los resultados obtenidos como producto de los análisis hechos con cualquier herramienta para el análisis métrico a partir de la búsquedas realizadas en PubMed-Medline u otra base de datos deben interpretarse con mucho cuidado y no deben extrapolarse más allá de los límites de la muestra (si se puede denominar muestra, estadísticamente hablando, al conjunto de referencias recuperadas) utilizada para su ejecución, es decir, los resultados de la búsqueda.
CONSIDERACIONES FINALES
Aun cuando el procedimiento explicado presenta ciertas insuficiencias, constituye el resultado de un análisis muy cuidadoso del total de las opciones que ofrece PubMed-Medline, así como de su funcionabilidad en nuestro contexto.
]]> Aunque se considere la amplia cobertura que presenta la base de datos en el área de las ciencias de la salud y la vida, no debe dejarse de explorar directamente las colecciones de Hinari, porque existen muchas revistas registradas por este sistema que PubMed-Medline no procesa. Una búsqueda como la realizada en este sistema puede complementarse con otra en Scopus, la mayor base de datos de citas y resúmenes de literatura arbitrada y de fuentes de alta calidad en el Web, disponible también para los países subdesarrollados por la vía de Hinari.
Finalmente, es oportuno señalar que aun cuando se realizan esfuerzos sistemáticos, tanto por parte de Hinari como de Infomed, en ocasiones se producen fallas en el acceso al sistema. Entonces, es necesario esperar e insistir nuevamente, así como ponerse en contacto con la Biblioteca Nacional de Medicina de Cuba, nuestros proveedores para este servicio. Tal vez por esta razón sea recomendable utilizar directamente PubMed-Medline, es decir, sin utilizar la vía a través de Hinari, cuando lo que se pretende es estudiar, observar o simplemente construir una estrategia de búsqueda; una vez probada, podemos introducirla en el sistema desde la interfaz que nos ofrece Hinari. Según nuestra experiencia, el acceso a PubMed-Medline es más rápido que a través de Hinari, pero esta última nos permite precondicionar en la prescripción de búsqueda la recuperación de referencias con acceso libre al texto completo en Hinari.
REFERENCIAS BIBLIOGRÁFICAS
]]>
1. Fernández Valdés MM, Núñez Paula IA. Metodología para el estudio de las necesidades de información, conocimiento y aprendizaje en las bibliotecas y centros de documentación de salud. Acimed. 2007;15(4). Disponible en: http://scielo.sld.cu/scielo.php?script=sci_arttext&pid=S1024-94352007000400004&lng=es&nrm=iso [Consultado: 28 de junio de 2010].
2. Cañedo Andalia R. Búsqueda bibliográfica, investigación métrica e inteligencia: el caso de la ataxia espinocerebelosa tipo 2 en Cuba. Acimed. 2009;19(2). Disponible en: http://bvs.sld.cu/revistas/aci/vol19_2_09/aci01209.htm [Consultado: 11 de junio de 2010].
3. National Library of Medicine. United States. Medical Subject Headings (MeSH®). Disponible en: http://www.nlm.nih.gov/pubs/factsheets/mesh.html [Consultado: 11 de junio de 2010].
Recibido: 6 de julio de 2010.
Aprobado: 9 de septiembre de 2010. ]]>
Lic. Rubén Cañedo Andalia. Departamento Fuentes y Servicios de Información. Centro Nacional de Información de Ciencias Médicas-Infomed. Calle 27 No. 110 e/ N y M, El Vedado. Plaza de la Revolución. Ciudad de La Habana. Cuba. Correo electrónico: ruben@infomed.sld.cu
b A pesar de que PubMed registra una cantidad de guías para la práctica clínica muy superior a la que presentan sitios como National Guidelines Clearinghouse (NGC -http://www.guideline.gov/) y otros especializados en el procesamiento de esta clase documentos, ante una búsqueda específica limitada a ciertos tipos de materiales como son las referidas guías y las antes mencionadas revisiones sistemáticas no se debe dejar de consultar recursos dedicados a ellos como es el caso de NGC y biblioteca de la Cochrane Collaboration (CC -accesible desde Cuba en http://cochrane.bvsalud.org/portal/php/index.php?lang=es). La NGC por ejemplo, ofrece además de un riguroso control de calidad del contenido de sus recursos, una formidable interfaz de búsqueda que incluye la posibilidad de restringir ésta según la edad de la población objetivo, la especialidad de quien pretende aplicarla, la categoría (diagnóstico, tratamiento, valoración de riesgo…), las herramientas para su implementación (algoritmo clínico, guía abreviada, …), los usuarios potenciales (dentistas, enfermeras, pacientes, …), el método utilizado para analizar la evidencia (metanálisis, revisiones sistemáticas, …), el método empleado para evaluar la calidad y la fortaleza de la evidencia (consenso de expertos, ponderación según esquema de clasificación, …), el método usado para formular las recomendaciones (consenso de expertos, hoja de balance, …), el enfoque de los resultados (seguridad, eficacia, …), el tipo de organización que la generó, la fecha y el sexo de los pacientes, entre otros, dirigidos a lograr una recuperación con un máximo de especificad. Las bases de datos de la CC presentan igualmente un control estricto de la calidad de los documentos que procesan, sean estos propios o externos. Así, por ejemplo, el NHS Centre for Reviews and Dissemination de la University of York, en Inglaterra, revisa la calidad metodológica de revisiones sistemáticas publicadas en la literatura médica antes de su incorporación a Database of Abstract of Review of Effects (DARE), una de las bases que conforman la colección que posee la biblioteca de la CC y que contiene los resúmenes estructurados (y los enlaces al texto completo en caso de que estén disponibles) de las revisiones realizadas por individuos y entidades ajenas a los grupos de revisión de esta organización.
c Para conocer el número de registros atesorados en PubMed o PubMed Central basta con introducir en sus cajas de búsqueda el comando: all[filter]. Para conocer el número de registros de PubMed Central que procesa PubMed basta con escribir en las referidas cajas: all[filter] AND "pmc pubmed"[Filter]. Tras un Enter el sistema nos devolverá el número de registros que aparecen duplicados en ambos recursos. El grado de solapamiento entre ambos debe expresarse en forma de porcentaje.
dMás de los 350 000 de los poco más de 400 000 registros de PubMed Central que no procesa PubMed proceden del proyecto que acomete la Biblioteca Nacional de Medicina de los Estados Unidos para escanear las colecciones de interés de revistas procesadas por sus bases de datos que preceden a la fecha de ingreso de la revista a sus fondos. Estos registros tienden a incorporarse progresivamente a la colección de PubMed.
eEs el período que transcurre desde el momento de la publicación de la contribución hasta la aparición de su referencia en la base de datos.
fEl hecho de que el MeSH y su versión e español, el DeCS, posean una organización además de alfabética, jerárquica, convierte a estos en una suerte de sistema de clasificación, que soporta extensamente las labores de recuperación de la información en PubMed-Medline, al facilitar la realización, tanto de búsquedas amplias como específicas. Por ejemplo, en la búsqueda que nos ocupa, el uso del término Nervous System Diseases posibilitaría recuperar el amplio conjunto de documentos que tratan las enfermedades del sistema nervioso central, el cerebro, el cerebelo, las ataxias y otros. Esta facilidad, sola o combinada, con las que prestan los Límites, posibilitan la obtención de información nueva, no contenida en la base de datos. El empleo de ésta como fuente de conocimientos nuevos, a partir de la utilización de sus herramientas de recuperación como herramientas para el descubrimiento del conocimiento puede sernos de gran utilidad. Supongamos, por ejemplo, que nos interesa saber si el tratamiento de cierto grupo de enfermedades o condiciones, como las enfermedades del cerebelo, ha experimentado en los últimos años un crecimiento geométrico. Para ello basta con utilizar la categoría Cerebellar Diseases y repetir sucesivamente la búsqueda con límites de tiempo que representen períodos iguales: 2005-2009; 2000-2004, etcétera. Esta búsqueda tan simple nos permitirá conocer si el tratamiento del tema en la literatura crece, se encuentra estancado o decrece. En esta clase de análisis deberá precisarse con cuidado cualquier cambio en la forma de indizar el tema que nos interesa o en el interés de la base de datos por el tema. Por ello, debe ejecutarse con la asistencia de un profesional de la información conocedor de ella.
gEn caso de que la estrategia de búsqueda consista esencialmente de términos del MeSH (y no palabras y frases claves), puede construirse esta desde la opción MeSH Databases. Esta alternativa facilita la labor de usuarios inexpertos en el uso de la base de datos.
hEsto debe hacerse así y no tecleando directamente su dirección electrónica, porque el paso por medio de la opción Hinari de los Esenciales de la página de Infomed es la vía establecida para la autenticación de los usuarios del dominio sld.cu en el país. Sin esa autenticación no es posible acceder a este recurso que, como se ha dicho antes, es el producto de un programa fundamentalmente dirigido a facilitar el acceso libre a los textos completos de miles de revistas científicas de las instituciones de salud en los países desarrollados.
]]> iTambién el sistema nos permite ordenar las referencias recuperadas por fecha de publicación, primer y último autor, nombre de la fuente y título del trabajo (opción Sort by). Por omisión, el sistema organiza las referencias según fecha de procesamiento desde la más reciente hacia la más antigua. ]]>{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}