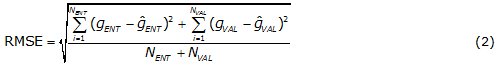Modelación energética y operacional del sistema de agua de alimentar caldera de una central termoeléctrica
Modeling energetic and operational of the boiler feed water system of a power plant
Ing. Ernesto Miguel Solís Alemán; Dr. C. Juan Luis Rodríguez Olivera; Dr. C. Mercedes Alemán García
Departamento de Ingeniería Mecánica. Facultad de Ingenierías. Universidad de Matanzas, Matanzas, Cuba.
]]>
RESUMEN
Se propone un modelo combinado basado en la implementación paralela de dos aproximadores funcionales, utilizando una red neuronal del tipo (MLP) y una regresión estadística, para la obtención de las características energéticas y de operación actual del Sistema de Agua de Alimentar Caldera (SAAC) en una Central Termoeléctrica (CTE), en la cual se regula el flujo de agua a la caldera por variación de velocidad. La respuesta del modelo combinado se obtiene a partir de la suma ponderada de cada aproximador funcional. Dicho modelo es utilizado para relacionar el consumo de corriente y la posición del variador de velocidad, en función de la presión de descarga y el flujo entregado por cada bomba del SAAC. Para el ajuste de los modelos se utilizan mediciones almacenadas en el archivo histórico del sistema SCADA, donde se aplica un método de procesamiento de datos para eliminar ruidos que pueden afectar el ajuste de los modelos propuestos.
Palabras clave: características operacionales del sistema de bombeo, inteligencia artificial, sistema de agua de alimentar caldera.
ABSTRACT
Is proposed a combined model based on the parallel implementation of two functional approximators, using a neural network of the type (MLP) and a statistical regression to obtain the actual energetic and operation characteristics of the Boiler Feed Water System (BFWS) in a Power Plant, in which the water flow to the boiler is controlled by variation speed. The response of the combined model is obtained from the weighted sum of each functional approximator. This model is used to relate the current consumption and the position of the speed variator, in function of the discharge pressure and flow delivered by each pump of the BFWS. For the fit of the models is used save measurements of the historical file of the SCADA system, where is applied a data processing method to eliminating noise that can affect the fit of the models proposed.
Key words: operational characteristics of the system of pumping, artificial intelligence, boiler feed water system, .
INTRODUCCIÓN
]]> El suministro de agua necesaria al generador de vapor en la central termoeléctrica analizada se realiza a través del SAAC, este está constituido por: un motor eléctrico de doble acoplamiento al eje, donde se encuentra acoplado, a un extremo, el variador de velocidades y seguidamente a este la bomba principal del tipo centrífuga multietapa y en el otro extremo, una bomba booster monoetapa utilizada para aumentar la presión en la succión de la bomba principal (figura 1). Estos conjuntos de motobombas se encuentran en número de tres unidades instaladas en paralelo, garantizando la operación para cargas variables de la CTE, con dos en operación normal y uno de reserva. Este es un sistema complejo para la operación ya que hay que tener una estricta vigilancia sobre el nivel del domo.Analizando las condiciones actuales de dichos equipos, existe la problemática de que las características energéticas han variado en comparación con los datos ofrecidos por el fabricante, lo que es debido a dos factores: el envejecimiento de los sistemas que en muchos casos llevan más de 25 años de explotación y los cambios provocados por las intervenciones de mantenimientos. El alto consumo de estos equipos, accionados por motores de 4,5 MWh, representa el 50 % del insumo total de la CTE, siendo necesario su caracterización para introducir métodos de optimización de su funcionamiento acorde a las posibilidades que brinda el sistema SCADA (Supervisory Control and Data Acquisition) de operación y control, que originalmente cubría la carga variable con la regulación simultanea de las dos bombas en servicio, es decir, la variación de flujo se asumía con idénticas variaciones de velocidad en cada conjunto de motobomba.
La diferenciación de las características energéticas y operacionales de las bombas obliga a su caracterización actual para distribuir de forma óptima el flujo de agua entre las bombas minimizando el consumo de energía del SAAC. Según la bibliografía especializada existen diferentes métodos para la obtención de las características energéticas y operacionales, que van desde la modelación matemática [1-3], análisis de las condiciones actuales [4-6] y evaluaciones de los sistemas de bombeo [1, 2, 7]; el gran inconveniente de estos métodos radica en la necesidad de realizar mediciones directas en dichos sistemas para conocer su estado. El objetivo de la presente investigación es proponer un método que permita determinar dichas condiciones a partir de las mediciones almacenadas en los históricos del sistema SCADA, eliminando la necesidad de realizar mediciones directas en el SAAC aumentando la disponibilidad del mismo.
MATERIALES Y MÉTODOS
Modelo Combinado y Procesamiento de los Datos
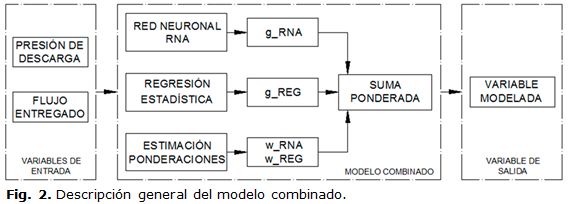
Para obtener la actualización de las características energéticas y de operación es necesario relacionar las variables de explotación del SAAC almacenadas en los ficheros históricos del sistema SCADA. En la presente investigación las variables modeladas son: el consumo de corriente y la posición del variador de velocidad en función de la presión de descarga y el flujo entregado por cada conjunto de motobomba del SAAC de la CTE. La variable de consumo de corriente es utilizada, pues la predicción de dicha variable permite determinar el consumo energético de cada conjunto de motobomba porque se carece de mediciones de consumo energético en el SAAC. Para la modelación se propone un modelo basado en técnicas de inteligencia artificial y estadística, tal como se muestra en la figura 2.
Este modelo propone una combinación de dos métodos de aproximación funcionales, el primero basado en una Red Neuronal Artificial (RNA), de tipo Perceptrón Multicapas (MLP) y el segundo una Regresión Estadística Lineal Múltiple (REG). Cada modelo propuesto es entrenado y ajustado según corresponde en cada caso con los mismos conjuntos de observaciones [8]. El modelo combinado utiliza la predicción de cada modelo de red neuronal artificial y regresión estadística (RNA y REG) y establece ponderaciones para los mismos (WRNA y WREG). La novedad de utilizar este modelo combinado es que utiliza la suma ponderada de las predicciones de los modelos de RNA y REG. Es decir, el modelo combinado permite calcular cuál de los dos modelos (RNA y REG) tiene una mejor precisión según la predicción de la variable modelada y asigna los pesos correspondientes para cada modelo, por lo que el modelo de mejor precisión de la predicción posee un mayor peso, permitiendo utilizar las mejores predicción de cada modelo de RNA y REG. Para el ajuste de los modelo de RNA y REG, es necesario disponer de datos experimentales. Inicialmente se dispone de un conjunto de datos obtenidos a partir de mediciones realizadas y almacenadas en el fichero histórico del sistema SCADA de la CTE; este conjunto se corresponde con mediciones de aproximadamente dos meses de trabajo continuo del SAAC, donde se registra el valor promedio de las mediciones cada cinco minutos.
]]> El conjunto de datos inicialmente es filtrado, estableciendo el rango de trabajo de cada motobomba, donde se seleccionan primeramente los valores que se encuentran comprendidos entre el rango de trabajo normal de flujo mínimo y flujo máximo. Posteriormente se realiza un muestreo estratificado, donde se divide la población total (conjunto de datos filtrado inicialmente) en estratos o clases disjuntos entre sí, como proponen [9-11], cada estrato se divide analizando la variable flujo, proponiéndose un incremento del mismo de 2 m3/h; se elige en cada clase una muestra, a partir de una prueba de medias, donde la muestra tomada se corresponde con una medición real próxima a la media calculada para cada clase. Este método de procesamiento de datos de análisis estadístico permite obtener un nuevo conjunto de datos con una disminución de su dispersión físicamente significativa y por consiguiente logra disminuir el nivel de ruido que pudiera influir sobre el ajuste de los modelos de RNA y REG, garantizando una adecuada capacidad de generalización (CG) con un error cuadrático medio de los residuales (RMSE) mínimo frente a nuevas instancias.Para cada conjunto de motobomba se obtiene un conjunto de datos con diferentes números de observaciones, estos datos, se agrupan en tres conjuntos (ajuste, validación y prueba) para el ajuste, validación y prueba de los modelos de red neuronal y regresión estadística respectivamente, según proponen [12,13 y 8].
Modelo de regresión estadística
El análisis de regresión es la técnica de dependencia más utilizada y aplicada a cualquier problema de ingeniería para obtener un modelo que permita relacionar ciertas variables independientes con una dependiente de una forma sumamente sencilla. Existen disímiles formas de relacionar estas variables, para este caso se emplea la regresión lineal múltiple, la cual relaciona el consumo de corriente y la posición del variador de velocidades con el flujo entregado y la presión de descarga. La ecuación (1), representa el modelo general de la regresión estadística obtenida.
donde: y, q, p, C, i, j, representan respectivamente la variable modelada, el flujo entregado por cada bomba, la presión de descarga y sucesivamente los coeficientes de ajuste de la regresión.
Modelo de redes neuronales
El aproximador funcional basado en técnicas Inteligencia Artificial, utiliza una red neuronal de tipo Perceptrón Multicapas (MLP) para relacionar las variables de entrada (presión y flujo) con la variable de salida (consumo de corriente o posición del variador), dada las características no muy complejas que relacionan dichas variables se emplea una sola capa oculta, [8,13,14], donde para cada caso obtenido, las cantidad de neuronas varían, en la capa de entrada se tiene la misma cantidad de neuronas que variables de entrada y en la capa de salida una sola neurona correspondiente al valor esperado de la RNA. Este tipo de RNA es utilizada, por los excelentes resultados ya probados [15,16,17,18,19], permitiendo predecir la variable modelada con un error relativamente bajo y una capacidad de generalización aceptable, probada frente a nuevas instancias.
En la capa oculta se ubicará el mínimo de neuronas necesario para lograr que el RMSE sea mínimo y la CG sea máxima. Si existen muy pocas neuronas en esta capa, los errores en la predicción serán demasiado altos. Si, por el contrario, la cantidad de neuronas en la capa oculta es excesiva, se produce el fenómeno conocido como sobreajuste (overfitting) que trae consigo una pobre CG. La salida está constituida por una sola neurona que se corresponde con la variable modelada (consumo de corriente o posición del variador).
Optimización de los parámetros estructurales y de entrenamiento de la red neuronal
]]> Para el ajuste de los pesos y los umbrales de la RNA se utiliza el método de retropropagación del error, basado en el gradiente descendente con momento; este método tiene ciertos parámetros fundamentales que deben ser ajustados adecuadamente para lograr que la RNA, una vez entrenada, genere respuestas con una CG alta y un RMSE bajo [8,15,16,20]. Dentro de estos parámetros se encuentra el número de neuronas en la capa oculta (NN), la velocidad de aprendizaje (LR), la constante de momento (CM), el número de iteraciones máximas (Imax) y el error cuadrático a alcanzar en el proceso de entrenamiento, este último parámetro mientras más cercano a cero sea, la red tendrá una mejor precisión y una CG alta. Para determinar los valores óptimos de los parámetros mencionados anteriormente se propone un diseño de experimento empleando el método de Tagushi, el cual es un arreglo ortogonal L9 (34) para la RNA durante el proceso de entrenamiento, donde se seleccionan cuarto factores: NN, LR, CM y Imax, con tres niveles convencionalmente denominado como bajo, medio, alto que se corresponde con los valores que pueden tomar los factores y como objetivos del diseño se tienen la precisión de la RNA y la capacidad de generalización (CG), [8].La precisión de la red neuronal se evalúa mediante el error medio cuadrático de los residuales (RMSE) de los conjuntos principal y de validación según la ecuación (2).
donde: gENT y ĝENT son el valor real y el valor predicho para el i-ésimo punto del conjunto de entrenamiento; gVAL y ĝVAL son el valor real y el valor predicho para el i-ésimo punto del conjunto de validación; NENT y NVAL son la cantidad de puntos del conjunto de entrenamiento y de validación respectivamente, [8].
La CG de la RNA se determina mediante el valor de probabilidad asociado al estadígrafo t-Student, en una prueba de igualdad de medias para los residuales del conjunto principal y de validación. Cuanto más cercano sea el valor de la probabilidad asociado a uno, mayor será la CG de la red, [8]
El valor más conveniente para cada factor de diseño, se determina a partir de un gráfico donde los objetivos de diseño (RMSE y C.G.) se representan para cada factor considerado. Donde se selecciona el valor del factor a partir de la condición de que el RMSE de la RNA sea mínimo y la capacidad de generalización sea máxima, [8]. Una vez seleccionado los factores óptimos de la RNA, se procede al proceso de entrenamiento para obtener los valores ajustados de los pesos y los umbrales para simular la RNA una vez entrenada.
Determinación de la precisión de los modelos y suma ponderada
Para la determinación de las precisiones de los modelos que se proponen (RNA y REG), en un punto cualesquiera del rango establecido por el conjunto de entrenamiento, es necesario normalizar los valores de entrada presión (p) y flujo(q), estableciendo así un vector normalizado correspondiente al punto en cuestión denotado por µ,como se muestra en la ecuación (3).
]]> donde las variables p y q de la ecuación anterior son escaladas tiendo en cuenta el rango de [0,1], pudiéndose obtener los WENT y WVAL puntos para el conjunto de entrenamiento y de validación respectivamente. Entonces cada punto del conjunto de entrenamiento y validación puede ser escrito según las ecuaciones (4) y (5).Teniendo en cuenta esto se puede evaluar la posición relativa del punto considerado, µ, a los conjuntos de entrenamiento y de validación, para lo cual se definen las distancias SENT y SVAL, que se determinan según las ecuaciones (6) y (7):
donde: μ, representa el vector posicional normalizado del punto considerado, y donde µWent y µWval son los vectores posicionales de los i-ésimos puntos de los conjuntos principal y de validación respectivamente.
Con las distancias establecidas se puede determinar la precisión Zi de cada modelo (RNA y REG), para el punto μ (ecuación 8), donde dicha precisión se establece proporcionalmente a los valores cuadráticos medios de las precisiones del modelo para el conjunto de entrenamiento, ZENT y validación, ZVAL; donde estos se calculan como la raíz del valor cuadrático medio del error relativo para los i‑esimos puntos de cada conjunto.
Determinada las precisiones, se puede calcular las ponderaciones wi, para cada uno de los modelos según la ecuación (9), para esto se establece que dichas ponderaciones son proporcionales a la función exponencial inversa de su precisión, y de forma que la suma de las dos ponderaciones sea igual a uno.
]]>Donde Zi, es la precisión para el modelo que se analiza, ZRNA y ZREG, son las precisiones para los modelos de RNA y REG respectivamente; por último se puede obtener el valor esperado del modelo combinado a partir de la suma ponderada dado por la ecuación (10).
El valor esperado del modelo combinado, será próximo al valor predicho del modelo de RNA o REG, donde su precisión sea los más cercano a cero; esto se debe a que existe una dependencia ajustada a la función exponencial inversa entre la precisión y la ponderación.
RESULTADOS Y DISCUSIÓN
Resultados del modelo de regresión estadística
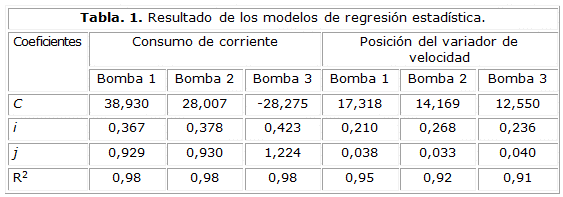
En la tabla 1, se muestra los resultados de los modelos obtenidos, así como, el coeficiente de correlación para cada variable modelada.
Resultado de la optimización del modelo de red neuronal
]]> Para el diseño y proceso de entrenamiento de la RNA se utilizó el software MatLab V 8.0, donde dicho modelo se obtuvo posterior a un diseño de experimento aplicando el método de Tagushi (L9) tal como se explicó en epígrafe anteriores, correspondiéndose los factores con los principales parámetros estructurales y de entrenamiento de la RNA y como objetivos del diseño la Capacidad de Generalización (C.G.) y el Error medio Cuadrático de los Residuales (RMSE). Los parámetros estructurales y de entrenamiento son seleccionados a partir de graficar los resultados obtenidos en el diseño experimental. A continuación se expone un ejemplo de cómo se seleccionan los valores óptimos de la red neuronal para el modelo de consumo de corriente de la bomba 2 (figura 3). Cada gráfico mostrado representa un parámetro estructural o de entrenamiento de la RNA en función de los objetivos de diseño. El parámetro se considera óptimo cuando el valor de la C.G. es máximo y el RMSE es mínimo. Como cada función es continua en todo el intervalo analizado se pueden obtener los valores máximos y mínimos. Los valores óptimos de los parámetros para todos los modelos obtenidos se muestran en la tabla 2.Una vez obtenidos los parámetros estructurales y de entrenamiento óptimos para la red neuronal se entrena la misma con dichos parámetros obtenidos y posteriormente se obtienen los valores de los pesos y los umbrales para su simulación.
Comparación de los modelos y precisión del modelo combinado
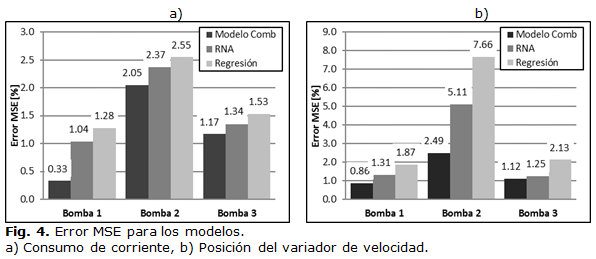
El modelo combinado se propone para disminuir el error de predicción de las variables modeladas como se mencionaba anteriormente, la figura 4, muestra una comparación del error cuadrático medio (MSE) según la estimación de los modelos de RNA, REG y el combinado, para el conjunto de prueba, donde se demuestra que el uso del modelo combinado reduce significativamente el error de predicción para las variables modeladas, demostrando que existe una excelente respuesta del modelo combinado frente a nueva instancias.
Para validar el uso del modelo combinado se utilizan tres combinaciones de trabajo del conjunto de motobomba del SAAC (motobombas 1-2, 2-3 y 1-3) para una hora de explotación y se determina el error relativo máximo y MSE entre los valores predichos por este modelo y la medición real obtenida del sistema SCADA para cada variable modelada (consumo de corriente y posición del variador de velocidad). En la tabla 3 se muestran los resultados obtenidos del error relativo máximo y MSE para cada variable modelada en cada motobomba, los cuales fueron determinados según las combinaciones de motobombas mencionadas anteriormente, ya que el SAAC trabaja con dos motobombas en operación normal. Según los resultados expuestos se demuestra que los errores de predicción de dichos modelos son menores de un 3 %, justificándose su validez para la predicción de las variables modeladas.
Superficies de respuesta de las variables modeladas
]]> La figura 5, muestra las superficies de respuesta obtenidas para cada modelo de consumo de corriente y posición del variador de velocidad correspondiente a cada conjunto de motobombas del SAAC, en función de la presión de descarga y el flujo entregado, pudiéndose apreciar que existen diferencias significativas entre las superficies de respuesta, lo cual demuestra las variaciones entre las características energéticas y operacionales. Estas variaciones son causadas principalmente por dos factores que son: el envejecimiento del SAAC y el cambio de los elementos estructurales fundamentales provocado por intervenciones de mantenimientos. La obtención de las curvas características es el primer paso para determinar las condiciones óptimas de operación del SAAC; ya que los modelos matemáticos que la describen pueden ser utilizados posteriormente por un algoritmo de optimización como funciones objetivos para establecer las condiciones óptimas de operación, pudiendo ser implementado en un software y aplicarse en tiempo real desde la sala de control de la CTE. Las superficies de respuestas también pudieran ser empleadas como una herramienta para el mantenimiento predictivo, al poder realizarse comparaciones en el tiempo de las mismas; siendo posible detectar variaciones de las condiciones técnicas de cada conjunto de motobomba, dadas por un incremento exponencial de la diferencia obtenida entre las dos superficies comparadas en los diferentes instantes de tiempo; esto se explica ya que los datos utilizados para el ajuste de los modelos poseen de forma implícita las condiciones técnicas de cada conjunto de motobomba del SAAC.
CONCLUSIONES
El diseño de experimento aplicado a los datos iniciales permite obtener un nuevo conjunto de datos con una disminución de su dispersión físicamente significativa y por consiguiente logra disminuir el nivel de ruido que pudiera influir sobre el ajuste de los modelos.
El uso del modelo combinado de implementación paralela de la red neuronal artificial y la regresión estadística permite obtener una respuesta de las variables modeladas con un error de predicción menor que el obtenido por los modelos independientes para todos los puntos del conjunto de prueba. Se demuestra un adecuado nivel de precisión de las predicciones del modelo combinado frente a un nuevo conjunto de valores reales de operación del SAAC, donde el error relativo máximo es inferior al 3 % en todos los casos. Esto demuestra que el método propuesto es factible para determinar las características energéticas y operacionales del SAAC utilizando mediciones almacenada en el fichero histórico del sistema SCADA de la CTE.
Es importante señalar que las superficies de respuestas obtenidas como resultado de la modelación matemática demuestran la existencia de variaciones significativas de las características energéticas y operacionales del SAAC. Dichas superficies son de gran utilidad para determinar las condiciones óptimas de operación del SAAC, al emplear un algoritmo de optimización para dicho fin, pudiendo ser implementado en un software que permita realizar la optimización del SAAC en tiempo real desde la sala de control de la CTE; además, pudieran ser empleadas como un indicador para el mantenimiento predictivo del sistema.
REFERENCIAS
1. HU, S.; GAO, H.; JIA, X. "Regulating Characteristics Analysis of Boiler Feed-water Pump when 600MW Unit Sliding-pressure Operating". Energy Procedia. 2012. vol. 17, no. Part B, p. 1153-1160. ISSN: 1876-6102 (doi: 10.1016/j.egypro.2012.02.221)
2. VOGELESANG, H. "Energy consumption in pumps-friction losses". World Pumps. 2008. vol. 2008, no. 499, p. 20-24. ISSN: 0262 1762 EAT 02113 (doi: 10.1016/S0262-1762(08)70140-8)
3. HMS GROUP. "Cost cutting with pump performance prediction". World pumps. 2013. vol. 2013, no. 7-8, p. 16, 18-19. ISSN: 0262 1762 EAT 02113(doi: 10.1016/S0262-1762(13)70208-6)
4. BEEBE R. "Pump monitoring: unusual incidents". World pumps. 2010. vol. 2010 , no. 523, p. 24‑26, 28. ISSN: 0262 1762 EAT 02113(doi: 10.1016/S0262-1762(10)70125-5)
5. SCHICKETANZ W. "Reducing avoidable pressure losses". World pumps. 2011. vol. 2011, no. 1, p. 18-21. ISSN: 0262 1762 EAT 02113(doi: 10.1016/S0262-1762(11)70031-1)
6. SALISBURY J. "Optimizing process speed and efficiency". World pumps . 2011. vol. 2011 , no. 11, p. 39-41. ISSN: 0262 1762 EAT 02113(doi: 10.1016/S0262-1762(11)70306-6)
7. BEEBE R. "Optimize time for overhaul of your pumps using condition monitoring". World pumps. 2004. vol. 2004, no. 452, p. 24‑28. ISSN: 0262 1762 EAT 02113. (doi: 10.1016/S0262-1762(04)00203-2)
8. QUIZA, R. "Optimización multiobjetivos del proceso de torneado". Director: Marcelino Rivas Santanas. Tesis Doctoral, Universidad de Matanzas, Matanzas, 2004. Consultado el 15 enero 2012. Disponible en: www.lania.mx/~ccoello/EMOO/tesis_quiza.pdf.gz
9. HAIR, J. F., et al. Análisis Multivalente. 5ta ed. Madrid: Prentice Hall Iberia, 2009. p. 512-695. ISBN: 84-8322-035-0
10. MONTSERRAT I.B., et al. Análisis Exploratorio de Datos: Nuevas Técnicas Estadísticas. 1era ed. Barcelona, España: PPU S.A., 1992. p. 125-172. ISBN 84-7665-179-1
11. JOHNSON, D. E. "Métodos multivariados aplicados al análisis de datos". México: International Thomson, 2008. p. 343-437. ISBN 968-7529-90-3
12. KHASHEI, M., BIJARI, M. “An artificial neural network (p, d, q) model for time series forecasting”, Expert Systems with Applications. 2010. vol. 37, n. 1, p.479–489. ISSN: 0957-4174 (doi: 10.1016/j.eswa.2009.05.044)
]]>13. MUÑOZ, A. "Aplicación de técnicas redes neuronales artificiales al diagnóstico de procesos industriales". Director: Miguel Ángel Sanz Bobi. Tesis Doctoral. Universidad Pontificia Comillas, Madrid, 1996. Consultado el: 8 febrero 2012. Disponible en: http://www.iit.upcomillas.es/publicaciones/mostrar_tesis_doctorado.php.es?id=24
14. MARTÍN B., SANZ A. "Redes Neuronales y Sistemas Difusos". 2da. ed. Zaragoza, España: Alfaomega. 2001. p. 17-98, 150-214. ISBN 13:978-9701507339
16. FAST, M., ASSADI M., DE S. "Development and multi-utility of an ANN model for an industrial gas turbine". Applied Energy. 2009. vol. 86, no. 1, p. 9-17. ISSN 0306-2619 (doi: 10.1016/j.apenergy.2008.03.018)
17. CHE J., WANG J., WANG G. "An adaptive fuzzy combination model based on selforganizing map and support vector regression for electric load forecasting". Energy. 2012. vol. 37, no. 1, p. 657-664. ISSN 0360-5442 (doi: 10.1016/j.energy.2011.10.034
18. GUO Z., et al. "Multi-step forecasting for wind speed using a modified EMD-based artificial neural network model". Renewable Energy. 2012. vol.37, n. 1, p. 241-249. ISSN 0960-1481 (doi: 10.1016/j.renene.2011.06.023
19. NING A., et al. "Using multi-output feedforward neural network with empirical mode decomposition based signal filtering for electricity demand forecasting". Energy. 2013. vol. 49, p. 279-288. ISSN 0360-5442 (doi: 10.1016/j.energy.2012.10.035)
Recibido: julio de 2014 ]]> Aprobado: enero de 2015
Ernesto Miguel Solís Alemán. Ingeniero Mecánico, Profesor Instructor, Departamento de Ingeniería Mecánica. Facultad de Ingenierías. Universidad de Matanzas, Matanzas, Cuba. e-mail: ernesto.solis@umcc.cu
]]>