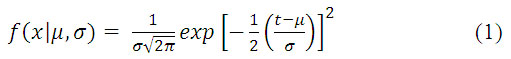
ARTICULO ORIGINAL
Clasificación del clutter marino utilizando redes neuronales artificiales
Classification of sea clutter using artificial neural networks
MSc. Argel González Padilla1, MSc. Berta Bravo Quintana2, Ing. José R.Machado Fernández3 , Ing. Adrián Bueno4, Ing.Ernesto Sainz de la Torre Ruiz1, Ing. Mónica Jiménez Alvarez1, Ing. Roselí Pérez Pino4
1 Instituto Superior Politécnico ¨ José Antonio Echeverría¨, Cujae,Ciudad Habana, Cuba. argel@electrica.cujae.edu.cu ]]>
2 Instituto Técnico Militar ¨José Martí¨, Ciudad Habana, Cuba.
3 Dirección de tecnología y sistema MININT,Ciudad Habana, Cuba.
4 ETECSA, Ciudad Habana, Cuba.
RESUMEN
La detección de radar bajo la acción del clutter marino es un problema actual. La efectividad de esta detección puede ser mejorada o aún optimizada si el comportamiento estadístico de los parámetros de las señales dispersadas por la superficie del mar (clutter marino) es conocida. En el presente trabajo, la mayoría de los modelos estadísticos del clutter marino bajo diferentes condiciones es dada y se logra en un solo documento de manera sintética agrupar un gran volumen de información, difícil de encontrar, y en muchos casos, de interpretar. La mayor contribución investigativa de este trabajo es la presentación de los fundamentos de un sistema auto adaptativo para la detección de blancos de radar, basado en el reconocimiento de diferentes distribuciones que modelan las mediciones de amplituddelclutter marino, obtenida en un intervalo de tiempo dado. Realizando una clasificación más fina al especificar el rango de valores que toman los parámetros de la distribución, para el intervalo de tiempo que se analiza. Este sistema fue simulado satisfactoriamente utilizando redes neuronales.Los resultados revelaron que se puede realizar de forma efectiva el reconocimiento de distribuciones de mediciones de amplitud del clutter marino y de los parámetros de la distribución.
Palabras claves: clutter marino, sistema auto adaptativo, redes neuronales artificiales.
ABSTRACT
]]> The radar detection under the action of sea clutter is an ongoing problem. The effectiveness of this detection can be improved or even optimized if the statistical behavior of the parameters of the signals scattered by the sea surface (sea clutter) is known. In this study, most of the statistical models of ocean clutter under different conditions is given and is accomplished in a single document synthetically group a large volume of information, hard to find, and in many cases, to interpret. The major contribution of this research work is the presentation of the foundations of anauto-adaptive system for detecting radar targets, based on the recognition of different distributions that model the sea clutter collected in a given time interval. Performing a finer classification to specify the range of values taken by the parameters of the distribution, for the time interval being analyzed. This system was successfully simulated using neural networks. The results revealed that can effectively perform recognition distributions of the marine clutter amplitude measurements and parameters distribution.Key words: sea clutter, auto adaptive system, neural networks.
INTRODUCCIÓN
El término clutter hace referencia a los ecos indeseables que aparecen en las mediciones de radar producto del entorno que rodea al blanco. Pueden estar causados por objetos del entorno como el mar, las precipitaciones (lluvia, nieve o granizo), las tormentas de arena, los animales (especialmente las aves), las turbulencias y otros efectos atmosféricos como reflexiones ionosféricas y estelas de meteoritos. También puede haber clutter debido a objetos fabricados por el hombre.
El cluttermarinoson los ecos provenientes de la superficie del mar. El principal problema que enfrentan los radares marinos es la eliminación de esta interferencia ya que es una señal indeseable que entra al receptor proveniente del eco reflejado en el océano. Es considerado como un proceso estocástico y uno de los tipos de cluttermás difíciles de modelar, debido a la compleja naturaleza de la superficie del mar. Para la atenuación del efecto de esta interferencia, en la actualidad se emplean algoritmos matemáticos soportados en software que interactúan con el detector del radar, corrigiendo el umbral de decisión y logrando de esta manera la adaptación al clutter. Estos sistemas son complejos y caros.
El objetivo de la investigación fue clasificar un grupo de distribuciones estadísticas que modelan el clutter marino a partir del parámetro de amplitud de la señal de eco de radar recibida, utilizando redes neuronales artificiales como clasificador. Presentando de esta manera los fundamentos de un sistema de auto adaptación para mejorar la efectividad de la detección de blancos en presencia de clutter marino.
]]>DISTRIBUCIONES MÁS UTILIZADAS PARA REPRESENTAR LA AMPLITUD DEL CLUTTER
El clutter marino es un blanco difícil de representar debido a dos factores fundamentales. En primer lugar, el mar es un blanco distribuido que no está compuesto por una sola masa o bloque puntual, sino que se distribuye en una región extensa. En segundo lugar, el mar se mueve sin seguir ninguna ley predeterminada o calculable. Los ecos de clutter son aleatorios y tienen características semejantes a las del ruido, porque sus componentes individuales tienen fases y amplitudes regidas por el azar[1].
Distribuciones clásicas
Existen un conjunto de distribuciones que se han utilizado tradicionalmente en el modelado del clutter marino, dentro de las que se destacan las distribuciones: Normal, Log- Normal, Weibull, Rayleigh y K.
La distribución Normal según Moya [2] puede ser utilizada para la modelación de clutter en radares de baja resolución, donde este se comporta como un proceso gaussiano incorrelado. Su función de densidad de probabilida (fdp) se muestra en la ecuación 1.
Los dos parámetros de la función son ![]() (media)y
(media)y ![]() (varianza), su variación modifica la posición y la escala respectivamente. Sin embargo la distribución normal no modela correctamente las mediciones de amplitud del clutter marino, debido a ser simetrica la distribución con respecto al centro. Para que una curva se adapte a las cartacteristicas del clutter debe ser ligeramente asimétrica.
(varianza), su variación modifica la posición y la escala respectivamente. Sin embargo la distribución normal no modela correctamente las mediciones de amplitud del clutter marino, debido a ser simetrica la distribución con respecto al centro. Para que una curva se adapte a las cartacteristicas del clutter debe ser ligeramente asimétrica.
La distribución Log Normal de acuerdo con Mahafza [3]se emplea para el clutter de tierra en ángulos de rasancia bajos; y en el de mar, para ángulos de rasancia en la región de estancamiento siguiendo una fdp caracterizada por la ecuación 2.
]]> AquíSi el clutter de mar o la tierrasegún Mahafza [3], está compuesto por muchos dispersores pequeños, cuando la probabilidad de recibir el eco de un solo reflector es estadísticamente independiente del eco recibido de otro dispersor, entonces el clutter puede ser modelado usando la distribución Rayleigh, cuya fdp es la que se muestra en la ecuación 3.
La desviación típica ![]() es elúnico parámetro de la función y constituye un parámetro de escala, el cual modifica la altura de la curva al variarar la concentración de los valores con respecto al punto máximo .
es elúnico parámetro de la función y constituye un parámetro de escala, el cual modifica la altura de la curva al variarar la concentración de los valores con respecto al punto máximo .
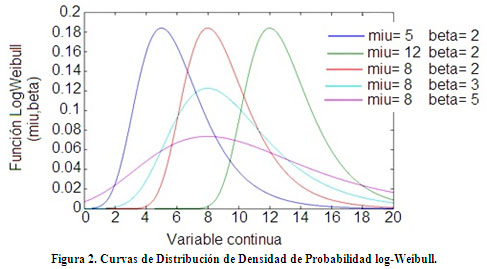
La distribución Weibull de acuerdo con Mahafza [3] es utilizada para modelar clutter en ángulos bajos de rasancia (menores que 50) para frecuencias entre 1 y 10 GHz, ver fdp ecuación 4.
Por último, según Dong[4] muchos estudios han mostrado que el clutter de mar obedece una distribución K. Es muy útil cuando se interpreta el eco del clutter como un fenómeno en que componentes rápidas son moduladas por componentes lentas. La justificación física de la distribución recae en que la K está formada por dos componentes que están asociados a observaciones experimentales. El componente rápido está asociado a las olas de fluctuación rápida u olas capilares. Este componente es a veces llamado componente mancha (speckle) y su estadística es representada por una función de distribución Rayleigh. El otro componente es un componente de variación lenta y no es afectado por la fluctuación rápida. Es representado mediante una función de distribución raíz-Gamma oChi. De esta manera, el modelo asume una distribución rápida fluctuante Rayleigh modulada porun componente distribuido gamma de fluctuación lenta[5], ver fdp ecuación 5. Esta es la razón por la que la distribución K es llamada muchas veces K compuesta. Se propone utilizar para los parámetros de la distribución K(c,v) un rango desde (0.5,0.1) hasta (5,19.6) Figura 1.
Distribuciones Compuestas
]]> Recientemente se han publicado nuevas propuestas de distribuciones que se logran a partir de otras más simples, por lo que se les puede denominar distribuciones compuestas. Estas son las distribuciones KA, KK y Weibull-Weibull.Las distribuciones compuestas se utilizan fundamentalmente para modelar el clutter de mar muy heterogéneo. El estado muy heterogéneo se alcanza fundamentalmente para ángulos de rasancia muy bajos o para alta resolución, o lo que es más frecuente, una combinación de ambas condiciones[6].
La distribución KA ha sido propuesta para mejorar la correspondencia del clutter de mar con las distribuciones específicamente en la región de la cola [6]. En la distribución KA se asume que las olas siguen un modelo compuesto por una distribución K y una Poisson.
La distribución KK representa la distribución del clutter marino al aparecer un componente de espiga en las componentes superiores de amplitud. Esta distribución asume que las olas capilares y las gravitatorias siguen una distribución K, al igual que la componente nueva de espiga, la cual aparece comúnmente a alta frecuencia y con polarización horizontal ver ecuación 6.
La distribución Weibull-Weibull utiliza como la KK una distribución para representar el componente de fluctuación rápida y lenta (olas gravitatorias y capilares) y otro para representar el componente de pico o espiga que comienza a aparecer en la alta resolución, su fdp es la que se muestra en la ecuación 7.
Distribuciones Novedosas
Las distribuciones novedosas son algunas que no son tan populares en la modelación del clutter, pero que han mostrado ser de gran utilidad. Una de ellas es la log-Weibull que de acuerdo con Ishii, Sayama, Mizutani[7] existe evidencia científica reciente de que la distribución modela el comportamiento de las mediciones de amplitud de los ecos de mar y sigue la fdpque se muestra en la ecuación 8.
Donde ![]() está compuesta por
está compuesta por ![]() que son los parámetros de la distribución. El primero
que son los parámetros de la distribución. El primero ![]() es el parámetro de localización y el segundo
es el parámetro de localización y el segundo ![]() es el de escala. Para el caso especial donde
es el de escala. Para el caso especial donde ![]() se está en presencia de la distribución estándar de Gumbel ver ecuación 9.
se está en presencia de la distribución estándar de Gumbel ver ecuación 9.
Otra distribución laTsallis, que es una distribución de probabilidad derivada de la maximización de la entropía Tsallis. La q-Gaussiana y la q-Exponencial son las distribuciones más conocidas de la familia Tsallis. Para el modelado del clutter marino, en años recientes se ha propuesto utilizar una distribución de la familia Tsallis cercana a la q-Gaussiana[8].
Su función de densidad de probabilidad se presenta a continuación (ecuación 10):
Donde ![]() es una constante de normalización. El parámetro está relacionado con la varianza de
es una constante de normalización. El parámetro está relacionado con la varianza de ![]() , y el parámetro
, y el parámetro ![]() cuantifica la igualdad de la distribución Tsallis con la Gaussiana. Cuando
cuantifica la igualdad de la distribución Tsallis con la Gaussiana. Cuando ![]() , la Tsallis se reduce a la Gaussiana, cuando
, la Tsallis se reduce a la Gaussiana, cuando ![]() se convierte en la distribución Cauchy, y cuando
se convierte en la distribución Cauchy, y cuando ![]() la distribución es de cola pesada[8].
la distribución es de cola pesada[8].
Los que apoyan el uso de la distribución Tsallis argumentan que el resto de los modelos son inexactos por el hecho de que el clutter marino es altamente no estacionario. Claman además que una buena forma de convertir un proceso no estacionario a uno estacionario es mediante la diferenciación[8]. Esto implica que los datos con los que se trabaja para modelar el clutter en una distribución Tsallis serán diferenciados previamente, según la siguiente fórmula (ecuación 11):
En la fórmula anterior se considera ![]() a las mediciones de amplitud, n a la cantidad de mediciones y
a las mediciones de amplitud, n a la cantidad de mediciones y ![]() los datos que se utilizan en la distribución Tsallis.
los datos que se utilizan en la distribución Tsallis.
El efecto contrario puede lograrse si se aumenta el valor de ![]() . En la figura 3 b) se puede apreciar que la curva Tsallis se contrae a media que dicho parámetro aumenta.
. En la figura 3 b) se puede apreciar que la curva Tsallis se contrae a media que dicho parámetro aumenta.
El comportamiento de las mediciones de amplitud de la superficie del mar puede ser descrito por todas las distribuciones previamente mostradas. La elección de una u otra es una decisión relacionada principalmente con el estado del mar y con las características del radar utilizado.
CONFECCIÓN Y ENTRENAMIENTO DE LA RED NEURONAL
Para la tarea de clasificar qué distribución sigue el parámetro de amplitud dado por el detector del radar, a partir de la señal de eco recibida, podría solucionarse empleando una clasifiación estadística, pero se seleccionaron las redes neuronales pues tienen la ventaja de ser máquinas independientes de los modelos, comportándose como aproximadores universales y son capaces de ajustarse a cualquier salida deseada o a cualquier topología de clases en el espacio de los rasgos.Además es un método de menos costo computacional, aunque el entrenamiento de la red si conlleva un tiempo significativo y requiere una buena unidad de procesamiento, la velocidad de respuesta en tiempo real es mayor que empleando una clasificación estadística; característica muy importante para aplicaciones de radar. Como desventaja presenta que si se desea agregar otra distribución habría que entrenar nuevamente la red de neuronas.Dada la naturaleza no lineal de la dinámica del mar, las redes neuronales son indudablemente buenas candidatas para decidir que distribución sigue la medición de amplitud del clutter marino y en que rango de valores se encuentran los parámetros de la distribuciónparade esta manera ajustar el umbral de decisión del detector y la señal de referencia en el receptor.
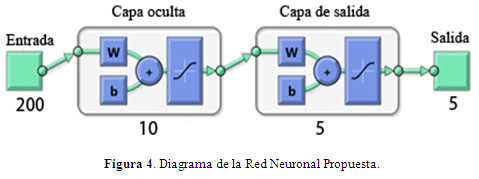
Para realizar la clasificación de las funciones probabilísticas K, log-Weibull, Tsallis, K-K y Weibull-Weibull, que sirven para modelar el mar en diferentes estados se utilizó una red neuronal artificial (perceptrón multicapas) cuyo clasificador se fundamenta en los principios de reconocimiento de patrones. La Tabla 1 muestra la selección de las variables de diseño de la red, estas son el resultado de la síntesis de las recomendaciones de varios autores [9,10, 11, 12]:
La estructura de la red propuesta puede apreciarse en la Figura 4:
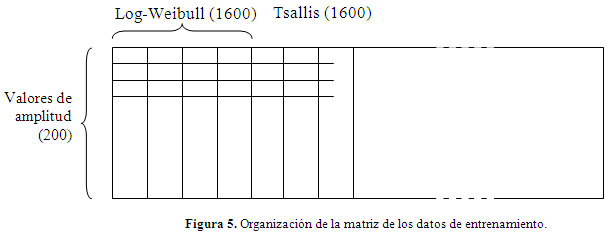
]]>Para el entrenamiento de la red se conformaron 1600 curvas (de 200 puntos cada una) para cada distribución. Lo anterior se logra variando los parámetros en un intervalo finito. El resultado final son 8000 curvas entre las 5 distribuciones. Estos valores se colocan en una matriz y se le presentan a la red neuronal columna a columna en la etapa de entrenamiento. La Figura 5 ilustra la matriz.
Se le adicionó ruido blanco gaussiano al conjunto de entrenamiento para que la red modele el comportamiento imperfecto de las mediciones reales. Este ruido simula la ocurrencia natural de imperfecciones en la construcción de las curvas de cada distribución. El nivel de ruido utilizado toma valores de 30, 20, 10, 5 y 3dB.
RESULTADOSY DISCUSIÓN
Con las condiciones previamente señaladas se lleva a cabo el entrenamiento de la red neuronal. Los resultados de este son satisfactorios. Se logra cumplir el objetivo de sobrepasar el 90% de reconocimiento lo que es considerado aceptable.
Analizando los resultados se puede decir primeramente que las redes entrenadas con mayores niveles de ruido necesitaron más cantidad de neuronas para obtener resultados óptimos. Esto se muestra en la Tabla 2:
Se entrenaron en total 5 redes neuronales. Cada una de ellas tiene un buen desempeño cuando trabajan con niveles de ruido iguales a los niveles de ruido con que fueron entrenadas. De igual forma cada una de las redes tiende a estabilizar los resultados a medida que se prueba con conjuntos de menos ruido. Estas conclusiones y algunas otras pueden obtenerse analizando la Tabla 3 que se muestra a continuación, en ella se ilustra el comportamiento de cada red para los distintos niveles de ruido.
En la tabla 3 las filas son los conjuntos con los que se prueba la eficiencia del desempeño de la red. En cuanto a las columnas, cada una representa una red diferente. Los datos se muestran de tres colores distintos. El color naranja representa el desempeño de la red para el conjunto que fue entrenada. El color verde ilustra los valores para los cuales se estabiliza el reconocimiento. Por último, el color azul abarca el resto de los datos.
]]> La Tabla 3 ilustra el hecho de que cada red empeora su funcionamiento para los conjuntos que tienen mayor nivel de ruido. Por otra parte, las redes que fueron entrenadas con niveles de ruido muy altos no logran tan buenos resultados para los conjuntos con poco ruido. Dado estos dos hechos, se recomienda el uso de la red que se adapte mejor a las condiciones del ambiente en el cual se desee utilizar. De cualquier forma, si se desconocen de antemano las condiciones de trabajo entonces lo más seguro es utilizar la red de 30 neuronas que funciona bien para todos los niveles de ruido, por lo tanto esta sería la candidata óptima para el clasificador. Esta red tiene como particularidad el hecho de que funciona mejor para los conjuntos de poco ruido que para el propio conjunto de entrenamiento. Esto indica que la red es un magnífico generalizador.Es importante señalar que el aumento del número de neuronas de la red no significa siempre una mejora en el desempeño. Para todas las redes se probaron diferentes tamaños de red hasta encontrar el óptimo. Este procedimiento se describe en la tabla 4. En ella se ilustran las pruebas que fueron realizadas para encontrar la cantidad de neuronas óptimas en el caso de la red entrenada con 30 dB, que finalmente fue concebida para 8 neuronas.
Como puede apreciarse los mejores porcientos de reconocimiento se obtuvieron para 4, 8 y 15 neuronas. La red entrenada con 8 neuronas es definitivamente la mejor, porque logra los mejores resultados manteniendo un tamaño modesto.
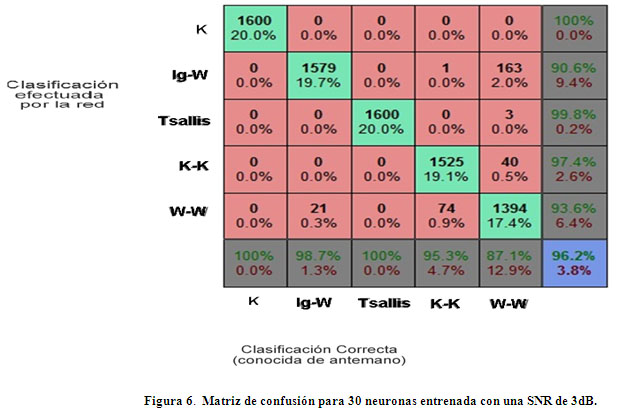
Está claro que el peor funcionamiento de la red de 30 neuronas es para los datos de 5 dB de relación señal a ruido. Para analizar la distribución del error que comete la red para dicho caso se utiliza la matriz de confusión (ver Figura 6 ), en la cual por la izquierda se coloca el resultado que devuelve la red neuronal y por debajo el resultado correcto que se conoce de antemano. La primera celda de la primera fila representa el número de distribuciones que se reconocen por la red como K y que en realidad son K. En este caso aparece el número 1600, lo que quiere decir que las 1600 distribuciones que se reconocieron como K son efectivamente K. A la derecha de esta celda aparecen varias celdas con el valor de 0. Estas dan la información de que la red no identificó como K a ninguna distribución log-Weibull, Tsallis, K-K o Weibull-Weibull. Si se sigue este análisis para el resto de las filas puede comprenderse que la diagonal central, resaltada en verde, proporciona los reconocimientos correctos y el resto de las celdas coloreadas de rojos los incorrectos.
Como puede observarse en la Figura 6, el punto crítico en el desempeño de la red aparece en la segunda fila y quinta columna. Allí se muestra que 163 distribuciones que son reconocidas como log-Weibull en realidad son Weibull-Weibull. Este error hace caer en un 2% la efectividad de la red. Otra confusión de relevancia ocurre cuando la red identifica la distribución Weibull-Weibull y en realidad la curva pertenece a una K-K (5ta fila y 4ta columna). Esta última confusión es responsable de una caída del 0.9% en el por ciento de aceptación. En la figura 6 se muestra detalladamente el tipo de error que se comete, responsable de que el reconocimiento caiga a un 96.2%. La conclusión que se puede sacar de lo anterior es que los errores que comete la red se encuentran localizados en puntos aislados. Estos puntos pueden ser mejorados repitiendo el proceso de entrenamiento varias veces o modificando ligeramente la estructura de la red. Otra variante, quizás más factible, es la de diseñar una pequeña red que se acople a la que aquí se presenta y que corrija sus defectos.
Para aumentar la precisión de la clasificación y contribuir realmente al aumento de la capacidad de detección, se entrenaron redes neuronales con el fin de determinar el rango en el que varían los parámetros de la distribución que modela la superficie del mar. Para ello se eligió la distribución K por ser entre las distribuciones clásicas la que mayores ventajas presenta para modelar el comportamiento del mar.
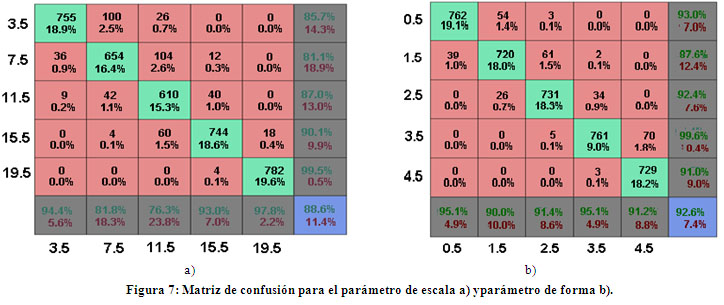
Empleando la ecuación 5, dondeÃ(.) es la función gamma, K es una función modificada de Bessel de segunda especie de orden v, c es el parámetro de escala y v es el parámetro de forma, se obtuvo como resultado un rango para los parámetros de escala y forma de (3.5; 0.5) a (19.6; 4.5) respectivamente.
Para analizar la distribución del error que comete la red en la determinación del rango de los valores que toman los parámetros en la distribución se recurre nuevamente a la matriz de confusión (ver Figura 7 ). Realizando un análisis similar al anterior se puede apreciar que el parámetro de escala toma valores entre 3.5 y 19.6 el 88.6% de las veces y el parámetro de forma entre 0.5 y 4.5 el 92 .6%.
Los errores que comente una red neuronal no se distribuyen de manera uniforme. Al contrario, suelen concentrarse en ciertos puntos que son visibles a través de la matriz de confusión.
]]> CONCLUSIONES
En este artículo se presenta uno de los primeros pasos para el mejoramiento de la detección de blancos de radar en entorno marino, mediante la atenuación del eco indeseado proveniente del mar (clutter marino). Los resultados revelaron que las mediciones de amplitud del clutter marino pueden representarse mediante distribuciones de probabilidad. Existen varias recomendaciones para el uso de una distribuciónu otra, pero no puede asegurarse la convergencia de las mediciones a una sola distribución. Se puede realizar de forma efectiva el reconocimiento de distribuciones de mediciones de amplitud del clutter marino si seutilizan redes neuronales artificiales. Se recomienda el uso de una red neuronal entrenada para una SNR de 3dB en la identificación de las distribuciones del clutter marino debido a que esta red muestra buenos niveles de reconocimiento para distintos conjuntos de prueba. Es posible determinar el rango de los valores que toman los parámetros de la distribución K que modela el clutter marino con una aceptación por encima del 86%. Contando con la información que proveen las redes neuronales (clasificación del clutter y determinación del rango de valores de los parámetros de la distribución) se puede mejorar la efectividad de la detección del radar bajo la influencia del clutter marino.
REFERENCIAS
1. Skolnik, M.I., Radar HandBook, 1990, McGraw-Hill. p. 846.
2. Carretero Moya, J., Detección Adaptativa en Eadares de Alta Resolución. Análisis con datos experimentales de clutter 2011, Universidad de Madrid. p. 301.
]]>3. Chapman, H.C., Radar Systems Analysis and Design Using MATLAB. 2000.
4. Dong, Y., Distribution of X-Band High Resolution and High Grazing Angle Sea Clutter. 2006: Defence Science and Technology OrganisationAziz, N.H.b.A., Radar Performance Analysis in thepresence of Sea Clutter, 2005, Universidad Tecnológica de Malasia. pág. 76.
5. Dong, Y. Distribution of X-Band High Resolution and High Grazing Angle Sea Clutter. 2006. 80.
6. Ishii, S., S. Sayama, and K. Mizutani, Effect of Changes in Sea-Surface State on Statistical Characteristics of Sea Clutter with X-band Radar. Wireless Engineering and Technology, 2011. Volumen 2: pág. 175 -183.
7. Hu, J., W.-w. Tung, Wen-wen , and J. Gao, A New Way to Model Nonstationary Sea Clutter. IEEE Signal Processing Letters, 2009. Volumen 16.
]]>8. Olabe, X.B., Redes Neuronales Artificiales y sus Aplicaciones, 2005, Escuela Superior de Ingeniería de Bilbao. pág. 79.
9. Kriesel, D.,A Brief Introduction to Neural Networks, 2005. pág. 244.
10. Fodslette Moller, M., A Scaled Conjugate Gradient Algorithm for Fast Supervised Learning. Neural Networks, 1993. Volumen 6: p. 525 - 533.
11. Hudson Beale, M., M.T. Hagan, and H.B. Demuth, Neural Network Toolbox™ 7, 2010. pág. 951.
]]> Recibido: Diciembre 2012
]]>


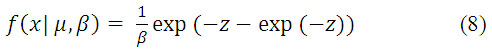

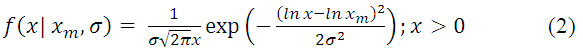{kind=link}
{kind=link}
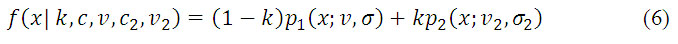{kind=link}
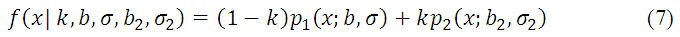{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}