ARTÍCULO ORIGINAL
Diagnóstico de proceso basado en el descubrimiento de subprocesos
Diagnosis of process based on the discovery of sub-processes
Raykenler Yzquierdo-Herrera, Rogelio Silverio-Castro, Manuel Lazo-Cortés, Adrian Torres-Graña
Universidad de las Ciencias Informáticas (UCI). La Habana, Cuba.
]]>
RESUMEN
Resulta muy útil realizar un diagnóstico en etapas tempranas del análisis del proceso de negocio. El diagnóstico de proceso es parte de la minería de proceso e incluye análisis de rendimiento, detección de anomalías e inspección de patrones comunes. Las técnicas desarrolladas en esta área presentan problemas para detectar los subprocesos que conforman al proceso analizado y enmarcar en estos subprocesos las anomalías y patrones significativos. Esta propuesta resuelve las deficiencias mencionadas, haciendo uso de la alineación de trazas; además, facilita el entendimiento del proceso desde la etapa inicial y permite detectar anomalías y los patrones más comunes. Finalmente, se presenta una aplicación del algoritmo propuesto en un entorno real y se analizan los resultados obtenidos.
Palabras clave: diagnóstico del proceso, minería de proceso, proceso de negocio, traza alineada.
ABSTRACT
It is useful to diagnose in early stages of business process analysis. The diagnosis of process is part of the process mining and it encompasses performance analysis, anomaly detection and inspection of common patterns. The techniques developed in this area have problems to detect sub-processes associated with the analyzed process and to frame anomalies and significant patterns in the detected sub-processes. The proposal resolves these shortcomings making use of the trace alignment. It also facilitates the understanding of the process at an early stage, detects anomalies as well as most common patterns. Finally, an application of the proposed algorithm in a real environment is presented, and the obtained results are discussed.
Key words: diagnosis of process, process mining, business process, aligned trace.
]]> INTRODUCCIÓN
La mayoría de las empresas utilizan sistemas de información para gestionar la ejecución de sus procesos de negocio (en lo adelante, "proceso") [1]. Estos sistemas registran en forma de trazas las acciones que se van realizando cuando se ejecutan instancias o casos del proceso [2; 3]. Al descubrimiento del proceso a partir de la información contenida en las trazas, se le denomina minería de proceso. La minería de proceso permite también el monitoreo y la mejora de los procesos reales extraídos de las trazas almacenadas por los sistemas. En el contexto de la minería de proceso, una traza está formada por una secuencia de eventos que se corresponde con la ejecución de una instancia del proceso. Un grupo de trazas asociadas a la ejecución de un proceso forman un registro de eventos [4].
Es común encontrar procesos poco estructurados, es decir, sus instancias no son estrictamente gobernadas por los sistemas de información utilizados. Los participantes en este tipo de proceso pueden tener una noción del mismo, sin que ésta llegue a ser clara y completa. Cuando se aplican técnicas de minería a este tipo de proceso, aparece un amplio espectro de posibles comportamientos que dificultan su entendimiento. Los modelos descubiertos en estos casos son poco estructurados o estereotipados como "espaguetis" [5; 6; 7].
Resulta útil realizar un diagnóstico en etapas tempranas del análisis del proceso, debido a que el diagnóstico incluye: análisis de rendimiento, detección de anomalías e identificación de patrones comunes [8]. El diagnóstico ayuda a tener una visión general del proceso, de los aspectos más significativos del mismo y de las técnicas que pueden ser más útiles en su análisis posterior.
En el área del diagnóstico de proceso se han desarrollado un conjunto de técnicas, entre las que se puede mencionar la desarrollada por Song y Van der Aalst (2007) [9]. Esta técnica permite tener una visión general del registro de eventos, lo que facilita la identificación de patrones existentes. Sin embargo, para registros de eventos de mediano a gran tamaño, se dificulta la comprensión y detección de aspectos relevantes.
Otros trabajos permiten identificar patrones recurrentes pero no permiten correlacionarlos, ni tener una vista general del proceso para enmarcarlos claramente en un contexto [10]. Este mismo problema lo presenta el trabajo presentado por Günther (2009), dado que solo considera la visualización de cada traza por separado [11].
El Chequeo de conformidad permite identificar las desviaciones y anomalías en el proceso ejecutado, pero se requiere de un modelo con el cual comparar el proceso descubierto y este modelo no siempre existe [12; 13]. En otro sentido, se pueden mencionar otros trabajos que permiten agrupar las actividades del proceso analizado, lo cual puede ser útil para entender el contexto en que se manifiestan determinadas anomalías. Sin embargo, estos trabajos resultan poco recomendados para entornos reales o no es posible conocer la relación que se establece entre las actividades que conforman un grupo, así como es difícil tener una visión integral del proceso [6; 14]. La técnica de descubrimiento Fuzzy Miner permite agrupar las actividades, pero considera que cada actividad pertenece a un único nodo [15].
El trabajo desarrollado por Bose y Van der Aalst (2012), permite identificar los patrones recurrentes y brinda una vista integral del proceso; sin embargo, presenta algunas limitantes [8], ya que no permite detectar los subprocesos que conforman al proceso analizado y enmarcar en estos las anomalías y patrones detectados. Esta limitación hace complicado contextualizar en muchas ocasiones el aspecto detectado, así como llegar a un entendimiento de las causas que lo originaron.
En este trabajo se presenta un nuevo algoritmo para el diagnóstico que permite construir el árbol de matrices representativas de los subprocesos que componen el proceso analizado. El algoritmo propuesto permite agrupar las tareas automáticamente y resalta los aspectos más significativos del proceso en cada momento. El descubrimiento de los subprocesos que componen el proceso analizado, sus dependencias y correlaciones, permiten una mayor precisión en el diagnóstico realizado.
]]>
MÉTODOSInicialmente se exponen un conjunto de definiciones que son necesarias para el entendimiento de la propuesta.
Definición 1 (Proceso de negocio): Un proceso de negocio es una colección de actividades que son realizadas coordinadamente en un ambiente técnico y organizacional. La conjunción de estas actividades logra un objetivo del negocio. Cada proceso de negocio es ejecutado por una organización, pero con él pueden interactuar procesos de negocios de otras organizaciones [16].
Definición 2 (Subproceso): Un subproceso es una agrupación de actividades del negocio que representa una unidad de trabajo. Los subprocesos tienen sus propios atributos y metas, y contribuyen a la meta del proceso que los contiene. Un subproceso es también un proceso y su mínima expresión es una actividad.
Un proceso puede descomponerse en varios subprocesos mediante los patrones de flujo de trabajo siguientes:
Definición 3 (Traza y registro de eventos): Se denota por la sumatoria (Σ) del conjunto de todas las actividades. Σ+ es el conjunto de todas las secuencias finitas de actividades no vacías sobre Σ. Cada T ∈Σ+ es una posible traza. Un registro de eventos L es un grupo de trazas [8].
Definición 4 (Bloque de construcción y descomposición en bloques de construcción): Sea S: el conjunto de todos los subprocesos que componen a un proceso P, L: el registro de eventos que representa a las instancias del proceso P ejecutadas, A: la matriz obtenida a partir de la alineación de las trazas contenidas en L y QA el conjunto de todas las sub-matrices de A. La alineación de las trazas se realiza según Bose y Van der Aalst (2012) [8].
Se denota por Q'A el conjunto de sub-matrices que representan a los subprocesos de S, tal que Q'A ⊆QA. Sean CiA y CjA: sub-matrices de Q'A. La relación de secuencia entre 2 subprocesos representados por CiA y CjA se denota por CjA>'LCj+1A. De forma análoga se denota la relación de selección (XOR específicamente) por CjA#'LCj+1A y la relación de paralelismo por ![]() . En el caso de manifestarse un lazo, la descomposición de CiA se realiza en un único sub-proceso que se repite múltiples veces y se denota por (CjA)*.
. En el caso de manifestarse un lazo, la descomposición de CiA se realiza en un único sub-proceso que se repite múltiples veces y se denota por (CjA)*.
Sea si ∈ S un subproceso representado por la matriz CiA ∈ Q'A y que está compuesto por una secuencia de subprocesos representados por CjA,...,Cj+kA, entonces tanto la matriz CiA como el conjunto {CjA,...,Cj+kA} se le denominan bloques de construcción y los sub-procesos representados por {CjA,...,Cj+kA} se relacionan de una única forma (secuencia, paralelismo, XOR o lazo).
Esta propuesta tiene como objetivo construir el árbol de bloques de construcción que representa la descomposición del proceso analizado.
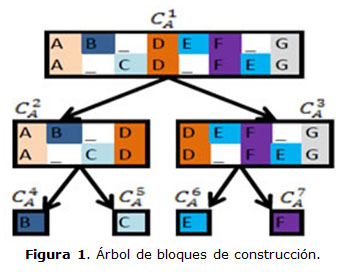
La figura 1 muestra un ejemplo de un árbol de bloques de construcción. Los bloques de construcción C2A y C3A representan subprocesos ordenados secuencialmente, C4A y C5A representan subprocesos ordenados como opciones de una selección, y C6A y C7A representan subprocesos en paralelo. La figura 1 no permite distinguir visualmente las relaciones que se establecen entre los subprocesos, pero posteriormente se mostrará la forma de identificación de este aspecto.
Pasos generales del algoritmo propuesto
1. Alineación de las trazas ]]>
El primer paso es el agrupamiento de las trazas y su alineación según Bose y Van der Aalst (2012) [8]. Las trazas alineadas constituyen una representación de las actividades de acuerdo a un orden relativo y su estructuración en casos. El orden establecido entre las actividades permite identificar los patrones de flujo de control que se manifiestan entre los subprocesos. Como resultado de la alineación de un grupo de trazas se obtiene una matriz A.2. Pre-procesamiento de las trazas alineadas
A partir de las trazas alineadas se pueden determinar los casos incompletos (casos que no terminan con las actividades finales identificadas para el proceso). Estos casos pueden ser tratados o eliminados según se considere, así se puede volver a alinear las trazas. El resultado de la alineación permite detectar visualmente estos casos, dado que los que están incompletos, presentan vacíos (símbolo de "-") en las columnas correspondientes a las actividades finales del proceso.
3. Determinación del árbol de bloques de construcción
En este paso se construye, a partir de la matriz A, un árbol de bloques de construcción que representan los subprocesos que componen al proceso analizado. El Algoritmo 1 detalla la forma en la que se realiza la determinación del árbol de bloques de construcción.
Entrada: Matriz A'
Salida: Árbol de bloques de construcción
1: Se crea un árbol vacío.
2: Se crea un bloque de construcción C1A y se asocia al nodo raíz del árbol la matriz A', tal que C1A= A'. ]]>
3: Si CiA no es una matriz con una sola fila Entonces4: LH = Buscar secuencia(C1A). LH es la lista que almacena los bloques de construcción obtenidos producto de la descomposición realizada.
5: Si |LH| < 1Entonces
6: LH = Buscar lazo(C1A)
7: Si |LH| < 1Entonces
8: LH = Buscar XOR-OR(C1A)
9: Si |LH| < 1Entonces
10: LH = Buscar paralelismo(C1A)
11: Si |LH| < 1Entonces
12: LH = Buscar secuencia oculta(C1A) ]]>
FinSiFinSi
FinSi
FinSi
13: Para cada bloque de construcción i contenido en la lista LH Hacer
14: El bloque de construcción se modifica, eliminándose de ser necesario, las filas repetidas y las columnas que solo contienen símbolos vacíos ("-")
15: El bloque de construcción i es adicionado como hijo del nodo que contiene a C1A
16: Al bloque de construcción modificado se le aplica el Algoritmo para determinación del árbol de bloques de construcción comenzando por el paso 3
17: Si el árbol obtenido en el paso anterior ≠ Ø Entonces
18: Los nodos hijos del árbol obtenido se adicionan como hijos de nodo que contiene el bloque de construcción i ]]>
FinSiFinPara
Sino
19: Devolver un árbol vacío
FinSi
20: Devolver el árbol de bloques de construcción construido
Los métodos que permiten determinar la descomposición mediante secuencia, lazo, XOR, OR, paralelismo y secuencia oculta se describen a continuación.
Buscar secuencia: El objetivo de este procedimiento es definir si el bloque de construcción que tiene como entrada, representa un proceso que puede ser descompuesto mediante una secuencia de subprocesos. En caso de ser posible la descomposición, se devuelve una lista con los bloques de construcción detectados; en caso contrario, se devuelve una lista vacía. Los subprocesos ordenados secuencialmente pueden ser claramente identificados debido a que éstos están separados por una o varias actividades (que aparecen de forma consecutiva) que se presentan ocupando una columna completa. Un ejemplo es la actividad D de la figura 1, la cual permite distinguir la secuencia entre 2 subprocesos representados por C2A y C3A. En ocasiones este tipo de actividades no se puede identificar, debido a que pudieron no mapearse en el registro de eventos.
Buscar Lazo: El objetivo de este procedimiento es definir si el bloque de construcción que tiene como entrada, representa un subproceso que se repite en varias ocasiones. En caso de ser posible, la descomposición devuelve una lista con un solo bloque de construcción, el cual representa al subproceso que se repite; en el caso contrario, se devuelve una lista vacía. Para determinar un bloque de construcción que representa un subproceso que se repite en múltiples ocasiones, es necesario identificar la actividad inicial de ese subproceso. Esta actividad inicial permitirá separar secuencias de actividades que posteriormente conformarán las filas del nuevo bloque de construcción. Las secuencias repetidas se desechan. ]]>
Buscar XOR-OR: El objetivo de este procedimiento es definir si el bloque de construcción que tiene como entrada, representa un proceso que puede ser descompuesto mediante una selección de subprocesos (ya sea XOR u OR). En caso de ser posible, la descomposición devuelve una lista con los bloques de construcción detectados; en caso contrario, se devuelve una lista vacía. Inicialmente se busca identificar una descomposición según XOR. Para determinar los bloques de construcción que representan opciones de una selección (XOR), se construyen conjuntos disjuntos con las actividades que componen el bloque de construcción analizado. Inicialmente existe un conjunto que contiene las actividades que comparten una fila del bloque de construcción analizado, posteriormente se unen los conjuntos que se intersectan mediante alguna actividad. Si al finalizar este proceso queda más de un conjunto, entonces se construyen los bloques de construcción que representan cada una de las opciones.Si solo queda un conjunto, entonces se busca identificar una descomposición según OR. Para ello se determinan las secuencias bases. Una secuencia base es una fila del bloque de construcción que no está compuesta completamente por la unión de otras filas. Las secuencias que contienen actividades comunes se unen en un mismo conjunto. Si al finalizar este proceso queda más de un conjunto, entonces se construyen los bloques de construcción que representan cada una de las opciones.
Buscar paralelismo: El objetivo de este procedimiento es definir si el bloque de construcción que tiene como entrada, representa un proceso que puede ser descompuesto mediante paralelismo entre subprocesos. En caso de ser posible, la descomposición devuelve una lista con los bloques de construcción detectados; en caso contrario, se devuelve una lista vacía. Para determinar los bloques de construcción que representan subprocesos en paralelo, se construyen conjuntos disjuntos con las actividades que componen el bloque de construcción analizado. Las actividades que pertenecen a conjuntos diferentes se encuentran en paralelo, mientras que las actividades que forman un mismo conjunto se relacionan mediante otro tipo de patrón de flujo de control. Si como resultado se obtiene más de un conjunto, entonces los bloques de construcción que se forman a partir de éstos representan subprocesos en paralelo.
Buscar secuencia oculta: El objetivo de este procedimiento es definir si el bloque de construcción que tiene como entrada, representa un proceso que puede ser descompuesto mediante una secuencia de subprocesos. En caso de ser posible, la descomposición devuelve una lista con los bloques de construcción detectados; en caso contrario, se devuelve una lista vacía. En este caso se supone que la actividad o actividades que delimitan los subprocesos ordenados secuencialmente no han sido registradas en las trazas. En consecuencia, se determinan las posibles soluciones (variantes de descomposición) considerando los aspectos que se enuncian a continuación.
RESULTADOS
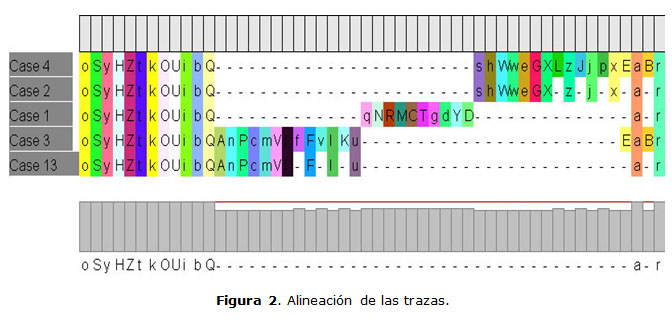
Se desarrolló un sistema a partir del algoritmo propuesto y se analizaron las trazas del Sistema Único de Identificación Nacional (SUIN), específicamente del módulo Gestionar Roles. El SUIN es un sistema desarrollado por el Ministerio del Interior de Cuba en conjunto con la Universidad de las Ciencias Informáticas. El registro de eventos correspondiente al proceso seleccionado (31 casos, 804 eventos, 52 clases de eventos y 3 tipos de eventos) permitió determinar anomalías en el proceso analizado. El primer paso consistió en aplicar el algoritmo de alineación de trazas desarrollado por Bose y Van der Aalst (2012) [8]. La figura 2 muestra la alineación obtenida a partir del registro de eventos. ]]>
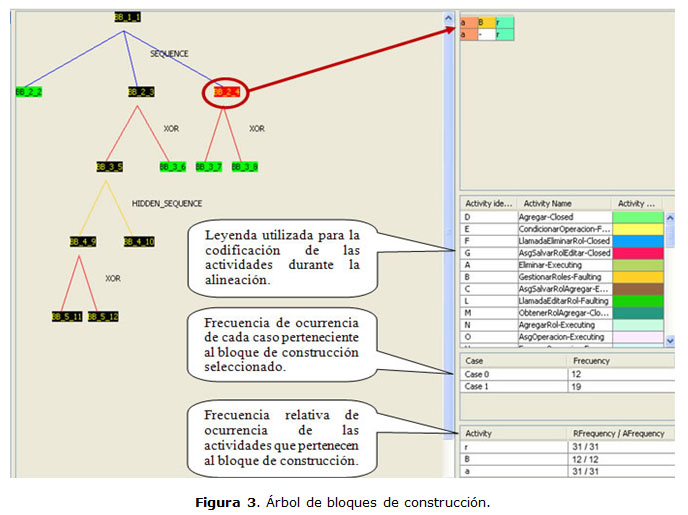
A la matriz obtenida de la alineación (figura 2) se le aplicó el algoritmo propuesto y se obtuvo el árbol de bloques de construcción que se muestra en la figura 3 (panel izquierdo).Es necesario señalar que el árbol de bloques de construcción obtenido puede seguirse expandiendo hasta que todos los nodos sean de color verde (nodo hoja correspondiente a un bloque de construcción con una sola fila) o hasta que aparezcan nodos azules (nodos que no tienen descomposición según los patrones de flujo de trabajo analizados). Las aristas presentan diferentes colores para diferenciar el patrón de flujo de trabajo por el cual se produjo la descomposición; además, se indica con un mensaje de texto en cada caso (SEQUENCE, XOR, HIDDEN_SEQUENCE).
En la figura 3 aparece seleccionado el bloque de construcción BB_2_4 (encerrado en el círculo) el cual corresponde al último subproceso resultado de la descomposición mediante una secuencia del bloque de construcción BB_1_1. Se escoge este bloque de construcción porque posibilita saber cómo termina el proceso. BB_2_4 contiene solo 2 casos, el primero con frecuencia de 12 y el segundo de 19. Esta información se puede apreciar en la tabla que se muestra en la figura 3, correspondiente a la frecuencia de ocurrencia de cada caso. La frecuencia de ocurrencia, tanto de los casos como de las actividades, no se emplean en el Algoritmo 1, pero sí se incorpora en la herramienta desarrollada para facilitar el diagnóstico del proceso.
El primero de los casos de BB_2_4 está asociado a la actividad B, la cual representa al evento "fallo de la actividad Gestionar Roles". Es notorio que este proceso falló 12 de las 31 veces que se ejecutó, lo que representa el 38,7 %. En consecuencia, se buscaron las causas de los fallos del proceso analizado.
Se busca el origen de las causas en el bloque de construcción BB_2_3, que representa el subproceso Condicionar Operación (incluye las posibles acciones relacionadas con agregar, editar o eliminar un rol). De la descomposición de BB_2_3 se obtienen 2 bloques de construcción, el BB_3_5 y BB_3_6, los cuales representan opciones de una selección. BB_3_6 representa el subproceso Crear Rol y el mismo no contiene ningún caso que contenga la actividad B, lo cual denota que este bloque de construcción no ejercía ninguna influencia sobre el fallo del proceso. De la descomposición de BB_3_5, se obtienen 2 bloques de construcción en la que el BB_4_10 representa el final de los subprocesos Editar Rol y Eliminar Rol. En el BB_4_10 aparece el evento de fallo correspondiente al subproceso Condicionar Operación, lo que denota que el fallo se originó en los subprocesos Editar Rol y Eliminar Rol. Se analiza en detalle el bloque de construcción BB_4_9 y su descomposición, con el objetivo de determinar la secuencia de actividades que condujeron a los fallos de Editar Rol (representado por BB_5_11) y Eliminar Rol (representado por BB_5_12). Esta secuencia de actividades detectada es útil para poder, en el futuro, alertar con anterioridad la posibilidad de un fallo en el proceso. Se determinó también identificar los casos en los que se produjeron concretamente las fallas y en consecuencia, poderlo revisar en detalle. Conociendo los casos y eventos en los que se produjo la anomalía, se pudo identificar, usando la herramienta ProM6.1, el usuario que ejecutó cada acción en el proceso.
DISCUSIÓN
La técnica desarrollada, al igual que la expuesta por Bose y Van der Aalst (2012) [8], permite detectar patrones interesantes y brinda una vista integral del proceso. Además, la propuesta permite detectar los subprocesos que conforman el proceso analizado y enmarcar en éstos las anomalías y patrones detectados, aspecto que no se satisface en el resto de las técnicas analizadas.
Otra de las ventajas de este trabajo es que permite combinar el análisis de las frecuencias de ocurrencia, tanto de los casos como de las actividades, con el análisis de manera escalonada de la secuencia de acontecimientos, correctamente estructurada en subprocesos. Esto contribuye a la comprensión de las causas de las fallas y por tanto, a la posible mejora del proceso.
Otro de los aspectos que constituyen un aporte del trabajo y que es poco tratado por las demás técnicas es que las anomalías detectadas se pueden enmarcar en un contexto. Por ejemplo, en el proceso analizado se identifica que las anomalías detectadas tienen su origen en los subprocesos Editar Rol y Eliminar Rol. ]]>
CONCLUSIONES
1. El diagnóstico del proceso puede ser útil para detectar los patrones y anomalías presentes en el registro de eventos analizado.
2. Las técnicas desarrolladas hasta el momento no permiten identificar anomalías y patrones considerando una descomposición en subprocesos ordenados jerárquicamente.
3. El algoritmo propuesto para el diagnóstico permite construir un árbol de bloques de construcción representativos de los subprocesos que componen el proceso analizado. Además, permite agrupar las tareas automáticamente y resalta los aspectos más significativos del proceso.
4. El descubrimiento de los subprocesos que componen el proceso analizado, sus dependencias y correlaciones, proporcionan una mayor precisión en el diagnóstico realizado. Todo esto es posible gracias a la combinación del análisis de las frecuencias de ocurrencia, tanto de los casos como de las actividades, con el análisis de manera escalonada de la secuencia de acontecimientos correctamente estructurada en subprocesos.
REFERENCIAS
1. HENDRICKS, K. B.; SINGHAL, V. R.; STRATMAN, J. K., "The impact of enterprise systems on corporate performance: A study of ERP, SCM, and CRM system implementations", Journal of Operations Management [en línea], 2007, vol. 25, no. 1, pp. 65-82 [consulta: 2011-11-16], ISSN 0272-6963. Disponible en: <doi: 10.1016/j.jom.2006.02.002>; <http://www.sciencedirect.com/science/article/pii/S0272696306000052> ]]>
2. AGRAWAL, R.; GUNOPULOS, D.; LEYMANN, F., "Mining Process Models from Workflow Logs", en EDBT '98 Proceedings of the 6th International Conference on Extending Database Technology: Advances in Database Technology London, UK, Springer-Verlag, 1998, pp. 1-15. ISBN 3-540-64264-1.
3. COOK, J.E.; WOLF, A.L., "Discovering Models of Software Processes from Event-Based Data", ACM Transactions on Software Engineering and Methodology [en línea], 1998, vol. 7, no. 3, pp. 215-249 [consulta: 2011-12-06], ISSN 1049-331X. Disponible en: <doi: 10.1145/287000.287001>; <http://doi.acm.org/10.1145/287000.287001>
4. VAN DER AALST, W.M.P., Process Mining. Discovery, Conformance and Enhancement of Business Processes, London New York, Springer Heidelberg Dordrecht, 2011, ISBN 978-3-642-19344-6.
5. BOSE, R.P.; VAN DER AALST, W.M.P., "Trace Alignment in Process Mining: Opportunities for Process Diagnostics", en International Conference on Business Process Management (BPM'2010) Berlin, Springer-Verlag Berlin, Heidelberg, 2010, pp. 227-242. ISBN 3-642-15617-7 978-3-642-15617-5.
6. DONGEN, B. F.; ADRIANSYAH, A., "Process Mining: Fuzzy Clustering and Performance Visualization. Business Process Management Workshops", S.; SADIQ RINDERLE-MA, S.; LEYMANN, F. (ed.), Lecture Notes in Business Information Processing, vol. 43 Berlin, Springer Berlin Heidelberg, 2010, pp. 158-169, ISBN 978-3-642-12186-9.
7. SONG, M; GÜNTHER, C. W.; VAN DER AALST, W.M.P., "Trace Clustering in Process Mining", en Business Process Management Workshops (2009) Milano, Italy, Lecture Notes, 2009, vol. 17, pp. 109-120. ISBN 978-3-642-00327-1.
8. BOSE, R. P.; VAN DER AALST, W.M.P., "Process diagnostics using trace alignment: Opportunities, issues, and challenges" Inf. Syst., 2012, vol. 37, no. 2, pp. 117-141, ISSN 0306-4379.
9. SONG, M.; VAN DER AALST, W.M.P., "Supporting process mining by showing events at a glance", en 17th Annual Workshop on Information Technologies and Systems (WITS) Montreal (Canada), 2007, pp. 139 -145. [consulta: 2011-12-06]. Disponible en: <http://www.processmining.org/blogs/pub2007/supporting_process_mining_by_showing_events_at_a_glance>
10. BOSE, R.P.; VAN DER AALST, W.M.P., "Abstractions in Process Mining: A Taxonomy of Patterns", U.; EDER DAYAL, J.; KOEHLER, J.; REIJERS, H. (ed.), Lecture Notes in Computer Science, vol. 5701 Berlin, Springer Berlin / Heidelberg, 2009, pp. 159-175, ISBN 978-3-642-03847-1.
11. GÜNTHER, C.W., "Process Mining in Flexible Environments", [Ph.D. thesis], Eindhoven (Germany), Eindhoven University of Technology, 2009.
12. ADRIANSYAH, A.; VAN DONGEN, B. F.; VAN DER AALST, W.M.P., "Towards Robust Conformance Checking", en BPM 2010 Workshops, Proceedings of the 6th Workshop on Business Process Intelligence (BPI2010) Springer, Berlin, Lecture Notes in Business Information Processing, 2011, [consulta: 2011-11-15]. Disponible en: <http://is.ieis.tue.nl/staff/wvdaalst/publications/p610.pdf>
13. ROZINAT, A.; VAN DER AALST, W.M.P., "Conformance checking of processes based on monitoring real behavior", Inf. Syst. [en línea], 2008, vol. 33, no. 1, pp. 64-95 [consulta: 2011-12-06], ISSN 0306-4379. Disponible en: <doi: 10.1016/j.is.2007.07.001>
14. VAN DER AALST, W.M.P.; RUBIN, V.; VERBEEK, H.M.W.; VAN DONGEN, B.F.; KINDLER, E.; GÜNTHER, C.W., "Process Mining: A Two-Step Approach to Balance Between Underfitting and Overfitting", Software and Systems Modeling [en línea], 2009, vol. 9, no. 1, pp. 87-111 [consulta: 2011-12-06], ISSN 1619-1366. Disponible en: <doi: 10.1007/s10270-008-0106-z>
15. GÜNTHER, C.W.; VAN DER AALST, W.M.P., "Fuzzy Mining: Adaptive Process Simplification Based on Multi-Perspective Metrics", en G.; DADAM ALONSO, P.; ROSEMANN, M. (ed.), International Conference on Business Process Management (BPM 2007) Springer, Berlin, Lecture Notes in Computer Science, 2007, vol. 4714, pp. 328-343. [consulta: 2011-11-16]. ISBN 3-540-75182-3, 978-3-540-75182-3. Disponible en: <http://dl.acm.org/citation.cfm?id=1793114.1793145>
16. WESKE, M., Business Process Management. Concepts, Languages, Architectures (Springer-Verlag Berlin Heidelberg), 2007, ISBN 978-3-540-73521-2.
]]>
Recibido: 16 de enero de 2012
Aprobado: 22 de abril de 2012
Raykenler Yzquierdo-Herrera. Universidad de las Ciencias Informáticas (UCI). La Habana, Cuba. Correo electrónico: ryzquierdo@uci.cu
{kind=link}
{kind=link}