Obtención de un modelo neuronal para la estimación de la concentración de etanol en la destilería Héctor Molina
Obtaining a neural model for ethanol´s concentration estimation at Héctor Molina distillery
Ing. Luis Eduardo López de la Maza 1 , Dra. Lourdes Zumalacárregui de Cárdenas 1 , Dr. Osney Pérez Ones 1 , Dr. Orestes Llanes Santiago 2
]]> 1 Grupo de Análisis de Procesos, Facultad de Ingeniería Química, Universidad Tecnológica de La Habana José Antonio Echeverría (CUJAE), La Habana, Cuba. lourdes@quimica.cujae.edu.cu
Resumen
La producción de etanol para el consumo humano mediante fermentación alcohólica en la destilería Héctor Molina se realiza en un biorreactor tipo tanque, con modo de operación discontinuo incrementado. Actualmente la modelación de procesos biológicos utilizando técnicas de inteligencia artificial se ha convertido en tendencia. En este trabajo se crearon modelos con las redes neuronales artificiales (RNA), perceptrón multicapa específicamente, que lograron estimar la concentración de etanol en los fermentadores de la destilería Héctor Molina, utilizando el software MATLAB 2013 . La mejor topología neuronal, obtenida en Matlab presenta cuatro variables de entrada y seis neuronas en la capa oculta con una media del error cuadrático medio de 4,34·10 -4 y un factor de correlación con los datos experimentales de 0,916.
Palabras clave: fermentación alcohólica, redes neuronales, modelos.
Abstract
The ethanol production for alcoholic beverages manufacturing based on fermentation at Héctor Molina distillery is performed in a bioreactor tank operating at discontinuous mode. Currently the biological processes' modeling using artificial intelligence techniques has become a trend. In this paper, models with artificial neural networks (RNA), multilayer perceptron specifically, were created. These models were able to estimate the concentration of ethanol in the fermenters of the Héctor Molina distillery using MATLAB 2013. The best neural topology presents four input variables and six neurons in the hidden layer with a mean of the mean square error of 4,34 10 -4 and a correlation factor with the experimental data of 0,916.
Keywords: neural networks, models, fermentation
]]>
INTRODUCCION
Los conocimientos acerca de la fermentación alcohólica se remontan a las primeras civilizaciones que llegaron a alcanzar un grado de desarrollo considerable. La fermentación alcohólica es un proceso llevado a cabo por microorganismos en condiciones anaerobias, en el cual se degradan carbohidratos para obtener etanol y dióxido de carbono como productos principales [1].
Para la fabricación de bebidas alcohólicas a escala industrial se han desarrollado dos tecnologías fundamentales de fermentación: la fermentación continua y la fermentación discontinua. En las destilerías cubanas se utiliza la fermentación discontinua y las mieles finales del proceso de fabricación de azúcar como materia prima, pues esta constituye un medio de cultivo idóneo para la obtención de etanol [2]. Particularmente en la destilería Héctor Molina la etapa de fermentación ocurre en fermentadores abiertos en modo de operación discontinuo incrementado.
Actualmente existe marcada tendencia a la simulación y optimización de procesos, para contribuir a la disminución de los tiempos de operación y al incremento de los rendimientos en el caso de la fermentación alcohólica. Los modelos matemáticos constituyen valiosas herramientas para lograr este objetivo pues permiten simular diversas condiciones operacionales y diseñar equipamiento para lograr volúmenes de producción deseados [2], [3].
El proceso de fermentación alcohólica tiene parámetros tanto no lineales como dinámicos dada su naturaleza biológica, por tanto, su modelación resulta difícil y desafiante por la gran cantidad de variables y condiciones de operación que influyen en la misma.
Se han desarrollado modelos de crecimiento de microorganismos que toman en cuenta varios efectos inhibitorios de manera simultánea. Sin embargo, no existe un modelo en el que se tengan en cuenta todos los factores inhibitorios, medioambientales y de nutrientes.
Atendiendo al variado número de factores que se pueden considerar, pudiera resultar un modelo tan complejo que no sería viable. Los modelos a escala de reactor, que difieren entre sí por el modo de operación, deben tener en cuenta necesariamente un modelo de crecimiento microbiano, que por demás no describe totalmente las condiciones particulares de una operación que no es netamente de reproducción [4].
El propósito de este estudio es obtener un modelo, que teniendo en cuenta los valores iniciales de las variables que mayor información encierren, permita estimar la concentración de etanol una vez terminada la etapa de fermentación, utilizando redes neuronales artificiales. En los últimos tiempos la aplicación de redes neuronales para la modelación de la fermentación alcohólica ha ido en ascenso [5], [6], [7] debido a las ventajas que presentan [8]:
• Las redes neuronales artificiales tienen la capacidad de aproximar funciones no lineales.
]]> • Pueden ser entrenadas fácilmente utilizando datos almacenados del sistema objeto de estudio.• Son aplicables a sistemas multivariables.
• No requieren especificación estructural de la interrelación entre los datos de entrada y salida.
Las redes neuronales artificiales se consideran como modelos de caja negra, es decir no se puede hacer una interpretación de la estructura del modelo [9] .
MATERIALES Y MÉTODOS
Recopilación de datos para la obtención del modelo
Los valores de las variables temperatura (T), concentración de células vivas en el inóculo (Xv), pH, 0 Brix y concentración de etanol (cEt) utilizados para la obtención del modelo neuronal se extrajeron de las hojas de control en la etapa de fermentación que se registraron en la destilería Héctor Molina durante el período comprendido entre el 1 de diciembre de 2016 y el 15 de marzo de 2017. Se pudieron recopilar datos de 298 procesos de fermentación ocurridos en este intervalo de tiempo.
Las mediciones de las variables T, pH y 0 Brix en la destilería se realizan directamente en el fermentador. La temperatura se mide con un termómetro, pH con un pH-metro y 0 Brix con un aerómetro. Las variables Xv y cEt son el resultado de análisis realizados en el laboratorio de la destilería. La Xv se obtiene a partir del conteo celular en un estereomicroscopio Novel y la cEt se obtiene mediante destilación de una muestra de vino de fermentación al final de dicha etapa.
Creación y entrenamiento de la red neuronal
La red neuronal utilizada para la modelación de la operación de los fermentadores de la destilería Héctor Molina fue perceptrón multicapa con una capa oculta. Esta elección está sustentada sobre la base de que este tipo de redes neuronales es fácil de utilizar y permite la modelación de funciones complejas [5] ; además varios autores la han utilizado para un fin muy similar al de este trabajo [6], [7], [10] .
]]> La función de activación empleada para la capa oculta fue la tangente sigmoidea (tansig), mientras que para la capa de salida fue seleccionada la función lineal (purelin).El número de neuronas de la capa oculta se varió desde 4 hasta 10. Para el entrenamiento de la red se empleó una técnica de propagación hacia atrás, el algoritmo Levenberg-Marquardt. Las variables de entrada a la red fueron: T, Xv, pH y 0 Brix, mientras que la variable de salida fue cEt.
Se procesaron 298 pares de datos de entrada/salida. Los datos se dividieron en 5 subgrupos (pliegues) de entrada/salida de forma tal que se pudiera realizar la validación cruzada del modelo de modo que, en cada caso, la red se entrenó con el 80% de los datos y se validó con el 20%. El error de validación se chequeó durante el entrenamiento. Inicialmente este error va decreciendo, pero cuando la red comienza a sobreentrenarse este comienza a aumentar. El incremento en 5 iteraciones consecutivas del error de validación y 1 000 como número máximo de ciclo de entrenamiento fueron los criterios utilizados para detener el entrenamiento.
Antes de realizar el entrenamiento los datos se normalizaron en el intervalo de 0 a 1. Tanto la creación de la red neuronal como su entrenamiento se realizaron en Matlab 2013.
Para la selección de la cantidad de neuronas óptima en la capa oculta se tuvieron en cuenta dos criterios: el error cuadrático medio en la validación del modelo y el coeficiente de correlación entre los valores de concentración de etanol estimados por el modelo neuronal y los valores reales.
El error cuadrático se muestra a continuación [7] :
Donde ye y yc son el valor real y el valor estimado de la concentración de etanol para i=1 ..... n, siendo N el número de muestras con que se trabajó.
Métodos estadísticos
Coeficiente de correlación
]]> El coeficiente de correlación es muy utilizado para evaluar el comportamiento de modelos neuronales. Se obtiene por regresión lineal entre los valores estimados por la red y los valores reales. A continuación, se muestra cómo calcularlo [5] .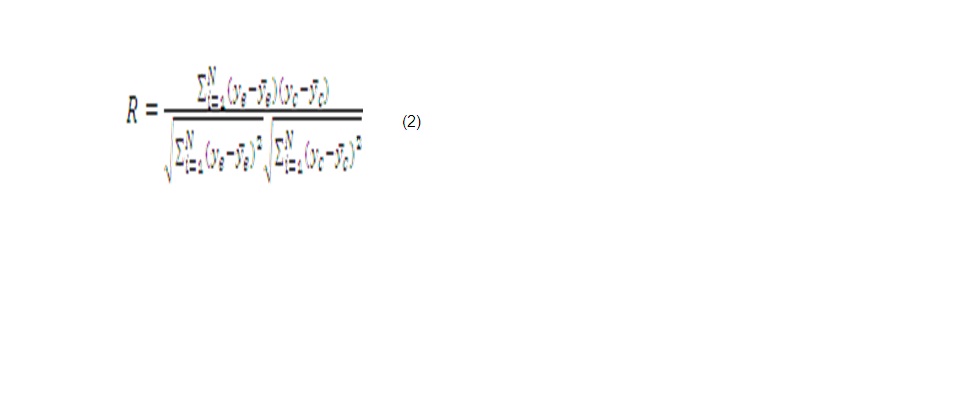
Prueba de Friedman
La prueba de Friedman, que permite la comparación de varias muestras, se utilizó para la selección de la arquitectura neuronal de mejor comportamiento de acuerdo al criterio del error cuadrático medio, ya que los resultados parecían muy similares y la decisión se dificultaba. Esta prueba tiene dos hipótesis: h 0 (hipótesis nula), que plantea la igualdad entre todas las medianas de un grupo, y h 1 (hipótesis alternativa), que plantea la no igualdad entre todas las medianas del grupo. Es una prueba no paramétrica. La selección de la arquitectura neuronal está basada en el valor P; si este es menor que 0,05 se rechaza la hipótesis nula.
Con esta prueba además se ordenan las muestras de acuerdo al rango promedio calculado en Statgraphics Centurión XVI.II.
Prueba de Wilcoxon
Cuando la prueba de Friedman revela que existen diferencias estadísticamente significativas entre las medianas del grupo es necesario realizar la prueba de Wilcoxon para seleccionar la arquitectura neuronal de mejor comportamiento. La prueba de Wilcoxon (no paramétrica) permite la comparación de pares de muestras. Tiene dos hipótesis: h 0 (hipótesis nula), que plantea la igualdad entre dos medianas, y h 1 (hipótesis alternativa), que plantea la no igualdad entre dos medianas. La selección de la arquitectura neuronal está basada en el valor P; si este es menor que 0,05 entonces se rechaza la hipótesis nula.
RESULTADOS Y DISCUSIÓN
Topología de la red neuronal
El número de neuronas en la capa oculta se varió de 4 a 10 y se comparó el comportamiento de todas las topologías. El coeficiente de correlación de la concentración de etanol para cada una de las topologías se muestra en la tabla 1.
]]>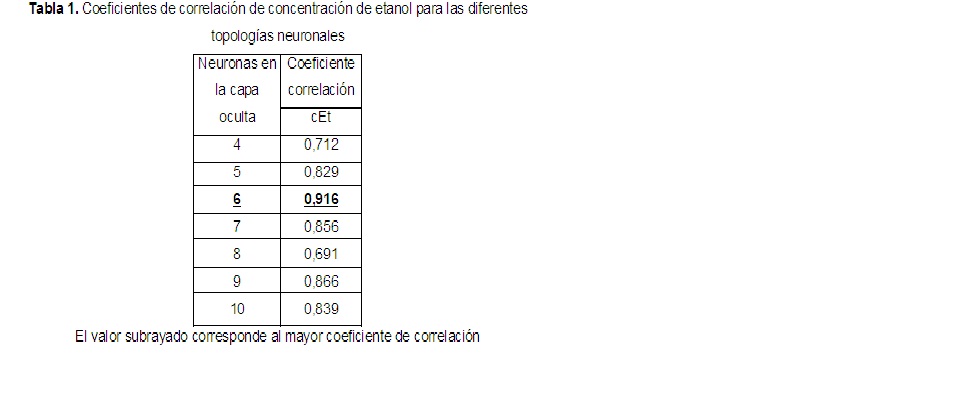
A partir del análisis de la tabla 1 se muestra que los valores de coeficiente de correlación están en el intervalo de 0,691 a 0,916. También se observa que el mayor coeficiente de correlación se alcanzó para la topología con 6 neuronas en la capa oculta (en la figura 1 se muestra esta topología). Atendiendo al criterio del coeficiente de correlación la red neuronal con mejor comportamiento tiene la estructura 4-6-1.
El error cuadrático medio para cada pliegue de validación cruzada en la cada topología se muestra en la tabla 2.
Tabla 2 . Comportamiento del error cuadrático medio en las topologías estudiadas
| Neuronas en la capa oculta | Error cuadrático medio | ||||
| Pliegue ]]> 1 | Pliegue 2 | Pliegue 3 | Pliegue 4 | Pliegue 5 | |
| 4 | 9,92·10 -4 | ]]> 8,96·10 -4 | 1,38·10 -3 | 7,84·10 -4 | 7,13·10 -4 |
| 5 | 4,39·10 -4 | 6,02·10 -4 | 5,64·10 -4 | 6,03·10 -4 | 3,95·10 -4 |
| ]]> 6 | 5,94·10 -4 | 4,64·10 -4 | 4,65·10 -4 | 3,40·10 -4 | 2,96·10 -4 |
| 7 | 3,07·10 -4 | 5,11·10 -4 | 5,28·10 -4 | ]]> 7,94·10 -4 | 6,45·10 -4 |
| 8 | 5,03·10 -4 | 5,32·10 -4 | 5,67·10 -4 | 5,74·10 -4 | 6,79·10 -4 |
| 9 | 6,37·10 -4 | ]]> 5,37·10 -4 | 9,83·10 -4 | 5,82·10 -4 | 4,05·10 -4 |
| 10 | 4,90·10 -4 | 4,66·10 -4 | 4,20·10 -4 | 4,76·10 -4 | 4,59·10 -4 |
En la tabla 2 se observa la similitud en el orden de error cuadrático medio para cada topología por lo que fue necesario realizar la prueba de Friedman para determinar si existían diferencias estadísticamente significativas.
El resultado del valor-P para la prueba de Friedman fue de 0,00979 (< 0,05). Por tanto, existían diferencias significativas entre los comportamientos de las diferentes topologías y debía realizarse la prueba de Wilcoxon para definir la mejor topología neuronal atendiendo al criterio del error cuadrático medio. La tabla 3 muestra el ordenamiento según el rango promedio resultado de la prueba de Friedman.
Tabla 3 . Rango promedio de las topologías
| Neuronas en la capa oculta | Rango promedio |
| 6 | 2,0 |
| ]]> 10 | 2,4 |
| 5 | 3,8 |
| 7 | 3,8 |
| 8 | 4,4 |
| 9 | 4,8 |
| ]]> 4 | 6,8 |
Como se observa en la tabla 3 la topología que menor rango promedio tiene es la de 6 neuronas en la capa oculta (4-6-1). La comparación desarrollada mediante la prueba de Friedman fue entre muestras de errores, por tanto, la comparación entre pares de muestras para la determinación de la mejor topología debe hacerse entre la topología con 6 neuronas en la capa oculta y las demás.
Los resultados de la prueba de Wilcoxon se muestran en la tabla 4.
Tabla 4 . Comparación de pares de topologías mediante prueba de Wilcoxon
| Topologías comparadas | Valor-P | Diferencias significativas |
| 4-6-1 y 4-4-1 | ]]> 0,012 | * |
| 4-6-1 y 4-5-1 | 0,296 |
|
| 4-6-1 y 4-7-1 | 0,210 |
|
| 4-6-1 y 4-8-1 | 0,0946 | ]]> |
| 4-6-1 y 4-9-1 | 0,143 |
|
| 4-6-1 y 4-10-1 | 0,164 |
|
Solo existen diferencias estadísticamente significativas respecto al error cuadrático medio entre la topología de 6 neuronas en la capa oculta y la de 4 neuronas en la capa oculta. Por tanto, pudiera considerarse como buena cualquier topología excepto la de 4 neuronas en la capa oculta teniendo en cuenta el criterio del error cuadrático medio.
Tomando como bases los resultados del mejor modelo de acuerdo con la topología de la red neuronal, según los criterios del error cuadrático medio y el coeficiente de correlación por separado, se decidió que el modelo neuronal que mejor describe la etapa de fermentación de la destilería Héctor Molina es el 4-6-1. El mejor coeficiente de correlación entre todas las topologías, una moderada complejidad estructural que permite un ahorro en cálculos al software Matlab y bajos valores de error cuadrático medio, son razones que justifican la decisión anterior.
Simulación
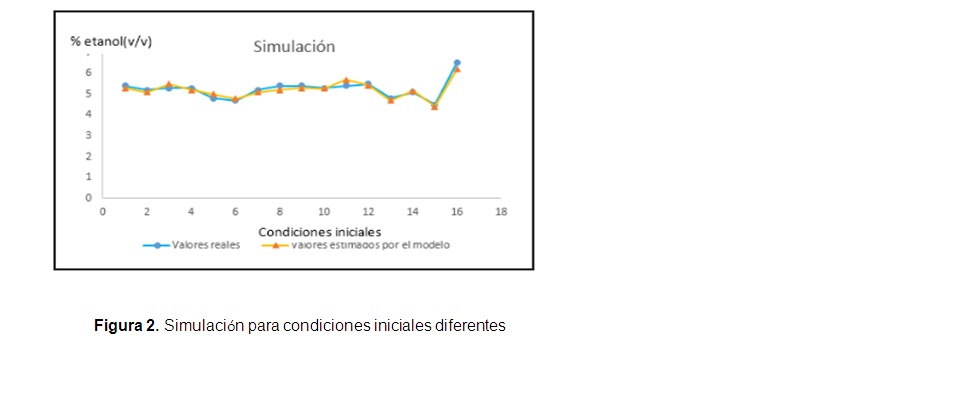
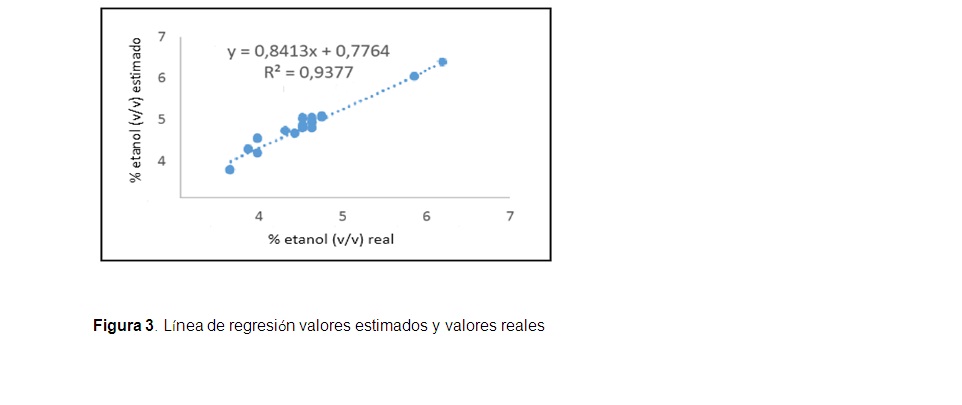
]]> La topología 4-6-1 se utilizó para simular 16 condiciones iniciales de fermentaciones que no fueron empleadas para el entrenamiento y la validación. La calidad del modelo se puede observar en la figura 2, donde se muestran los valores reales y los estimados por el modelo neuronal para las diferentes condiciones iniciales. Se puede observar que los valores estimados están muy cerca de los valores reales.La línea de regresión entre los valores estimados por el modelo neuronal y los valores de concentración de etanol reales, así como el coeficiente de determinación se muestran en la figura 3.
CONCLUSIONES
La red neuronal del tipo perceptrón multicapa con topología 4-6-1 se utilizó para la modelación de fermentadores en la destilería Héctor Molina y demostró su capacidad de estimar satisfactoriamente la concentración de etanol al final de la etapa de fermentación. El alto valor del coeficiente de determinación (0,9377) entre los valores simulados y los valores reales, y los bajos valores de error cuadrático medio en la validación del modelo indican la conveniencia de la utilización de redes neuronales en la modelación de la fermentación alcohólica.
BIBLIOGRAFÍA
1. EPIFANIO, S. Influencia de la tecnología de vinificación en la microbiología y el desarrollo de la fermentación alcohólica. Tesis Doctoral. Universidad de la Rioja, España, 2005.
]]>2. MENÉNDEZ, Z. Desarrollo de módulos de cálculo para los procesos de fermentación alcohólica. (Tesis de maestría en Análisis y Control de Procesos), Universidad Tecnológica de La Habana José Antonio Echeverría CUJAE, Cuba, 2010.
3. LIN, Y., & TANAKA, S. Ethanol fermentation from biomass resources: current state and prospects. Applied microbiology and biotechnology, 2006, vol.69, Nº 6, p. 627-642.
4. PSICHOGIOS, D. C., & UNGAR, L. H. A hybrid neural network - first principles approach to process modeling. AICHE JOURNAL, 1992, vol.38, Nº10, p.1499-1511.
5. ASSIDJO, E. Batch fermentation process of sorghum wart modeling by artificial neural network. European Scientific Journal , ESJ, 2015, vol.11, Nº3.
6. ASSIDJO, E. A hybrid neural network approach for batch fermentation simulation. Australian Journal of basic and applied sciences, 2009, vol.3, Nº 4, p. 3930-3936.
]]>7. ESFAHANIAN, M., NIKZAD, M., NAJAFPOUR, G., & GHOREYSHI, A. A. Modeling and optimization of ethanol fermentation using Saccharomyces cerevisiae : Response surface methodology and artificial neural network. Chemical Industry and Chemical Engineering Quarterly/CICEQ , 2013, vol. 19, Nº 2, p. 241-252.
8. ASSIDJO, E., & YAO, B. Industrial Brewery Modeling by Using Artificial Neural Network. Journal of Applied Sciences , 2006, vol.6, Nº 8, p.1858-2006.
9. UNGAR, L., HARTMAN, J., KEELER, J., & MARTIN, G. Process modeling and control using neural networks. Paper presented at the International Conference on Intelligent Systems in Process Engineering, 1996.
10. AHMADIAN-MOGHADAM, H., ELEGADO, F., & NAYVE, R. Prediction of ethanol concentration in biofuel production using artificial neural networks. American Journal of Modeling and Op
Recibido: Noviembre 2017 ]]> Aprobado: Marzo 2018
Ing. Luis Eduardo López de la Maza.Grupo de Análisis de Procesos, Facultad de Ingeniería Química, Universidad Tecnológica de La Habana José Antonio Echeverría (CUJAE), La Habana, Cuba
]]>