- Evaluar un conjunto de habilidades derivadas de la habilidad genérica. Por ejemplo, para la habilidad genérica “habilidades para la comunicación”, evaluar las habilidades derivadas: habilidades para la expresión escrita, habilidades para la expresión oral, habilidades para la escucha y habilidades para la observación.
- Evaluar elementos de carácter metacognitivo. Estos propician un constante perfeccionamiento del desempeño del individuo y se refieren a los siguientes indicadores o conductas no observables.
- Conoce sus límites y potencialidades.
- Reflexiona acerca de estos aspectos. ]]> Pone en práctica estrategias de superación de dificultades.
- Existe congruencia entre la imagen que tiene de sí y la que proyecta.
Después de definir o seleccionar los formularios de evaluación para las habilidades técnicas, y los tests de evaluación y autoevaluación para las habilidades genéricas, los evaluadores deben registrar los resultados y procesarlos, mediante la herramienta EvalSoft, para poder realizar los análisis necesarios. Sin embargo, debido al volumen de dicha información, no es viable procesarla por los métodos tradicionales. El análisis e interpretación manual de esta información resulta sumamente lento y podría ser muy superficial. Es por ello que se propone utilizar técnicas de minería de datos, ya que estas enriquecen el proceso de análisis, descubriendo relaciones ocultas entre los datos e información desconocida, favoreciendo la gestión y toma de decisiones en los procesos del negocio.
RESULTADOS Y DISCUCIÓN
Como resultado de la Evaluación del Desempeño de roles, actividad que se deberá realizar de forma sistemática, es posible obtener numerosos y valiosos indicadores, entre estos se encuentran: las variables que miden la calidad de los artefactos elaborados (como resultado de la evaluación de las habilidades técnicas) y las variables que miden las habilidades genéricas desarrollas por los estudiantes durante su formación. Estos indicadores deberán ser analizados en profundidad con el propósito de:
- Identificar fortalezas y debilidades del proceso de formación de ingenieros informáticos.
- Obtener información útil y nuevo conocimiento, que apoye la toma de decisiones vinculadas al proceso de enseñanza de la carrera. (Identificar relaciones ocultas entre los datos.)
- Validar el proceso de evaluación que siguen las diferentes asignaturas de la carrera que tributan a la formación de roles. (Ajustar pesos, puntajes, entre otros (WILFORD, 2006)).
- Realizar propuestas de mejoras continuas, vinculadas al proceso de formación de roles en la carrera. ]]>
- Relacionar las variables que miden la calidad general de los artefactos elaborados por los estudiantes, con las variables que miden la calidad del desempeño del rol que se evalúa. (Los valores de las variables que miden la calidad general de los artefactos y la calidad del desempeño del rol que se evalúa, se obtienen a partir de procesar los formularios de evaluación de las habilidades técnicas correspondientes (WILFORD, 2006)).
- Relacionar las variables que constituyen indicadores de la calidad de un determinado artefacto, con las variables que miden la calidad general de dicho artefacto y las variables que miden la calidad del desempeño del rol que se evalúa.
- Relacionar las variables que miden las habilidades genéricas desarrolladas por los estudiantes, con las variables que miden la calidad del desempeño del rol que se evalúa. (Los valores de las variables que miden las habilidades genéricas desarrolladas por los estudiantes, se obtienen a partir de procesar los tests de evaluación y autoevaluación de las habilidades genéricas correspondientes (WILFORD, 2006)).
- Relacionar las variables que miden las habilidades derivadas desarrolladas por los estudiantes, con las variables que miden las habilidades genéricas y las variables que miden la calidad del desempeño del rol que se evalúa. (Los valores de las variables que miden las habilidades derivadas desarrolladas por los estudiantes, se obtienen a partir de procesar los tests de evaluación y autoevaluación de las habilidades derivadas correspondientes (WILFORD, 2006)).
- Relacionar las variables que miden las conductas que describen una determinada habilidad derivada, con las variables que miden las habilidades derivadas correspondientes, y las variables que miden la calidad del desempeño del rol que se evalúa. ]]> Relacionar las variables que miden la calidad del desempeño de los roles evaluados en un “corte evaluativo” determinado, con las variables que miden el resultado final de la evaluación de las habilidades técnicas requeridas en dicho “corte evaluativo”.
- Datos generales de los evaluados, por ejemplo: “identificador”, “grupo docente”, “vía de ingreso”, “índice académico de ingreso”, entre otros que resulten de interés.
- Variables que miden el resultado final de la evaluación de las habilidades técnicas requeridas en un “corte evaluativo” dado. En este grupo se incluyen las variables que almacenan la Valoración Final sobre la calidad general del desempeño de todos los roles evaluados en dicho “corte evaluativo”, cuyos valores se obtienen a partir del procesamiento de los formularios de evaluación de las habilidades técnicas correspondientes. Además, se incluye en este grupo, la variable que almacena la Calificación Final correspondiente al “corte evaluativo”, determinada por los evaluadores de las habilidades técnicas.
- Variables que miden la calidad del desempeño de un determinado rol. En este grupo se incluyen las variables que almacenan la Valoración Final sobre la calidad del desempeño de un rol dado, cuyos valores se obtienen a partir del procesamiento del formulario de evaluación de las habilidades técnicas correspondientes. Por ejemplo, una variable puede ser “DESEMPEÑO_Analista_Negocio_Valoración Final” (Valoración Final de la calidad del desempeño del rol Analista del Negocio), donde los valores posibles que dicha variable puede tomar podrían ser: “Óptimo”, “Bueno”, “Regular” o “Malo”).
- Variables que miden la calidad general de los artefactos elaborados. En este grupo se incluyen las variables que almacenan la Valoración Final sobre la calidad de los artefactos evaluados, cuyos valores se obtienen a partir del procesamiento del formulario de evaluación de las habilidades técnicas correspondientes.
- Variables que constituyen indicadores de la calidad de un determinado artefacto. Estas variables se corresponden con cada una de las frases que conforman la lista de chequeo relativa al artefacto evaluado y que se incluyen en los formularios de evaluación.
- Variables de coincidencia de habilidades genéricas. Las variables incluidas en este grupo indican si “hay coincidencia” o no entre los resultados de los test de autoevaluación y evaluación para una habilidad genérica determinada.
- Variables de coincidencia de habilidades derivadas. Las variables incluidas en este grupo indican si “hay coincidencia” o no entre los resultados de los test de autoevaluación y evaluación para una habilidad derivada de una habilidad genérica determinada. ]]> Variables que miden las habilidades genéricas desarrolladas por los estudiantes. Estas variables se corresponden con las Valoraciones Finales sobre las habilidades genéricas desarrolladas por los estudiantes, obtenidas a partir del procesamiento de los test de evaluación y autoevaluación correspondientes. Por ejemplo, una variable podría referirse a la Valoración Final sobre las habilidades para la comunicación desarrolladas, según resultados de los test de evaluación que han sido procesados, donde los valores posibles que dicha variable puede tomar podrían ser:“Malas“, “Regulares”, “Buenas” o “Muy Buenas”.
- Variables que miden las habilidades derivadas desarrolladas por los estudiantes. Estas variables se corresponden con las Valoraciones Finales sobre las habilidades derivadas desarrolladas por los estudiantes, obtenidas al procesar los test de evaluación y autoevaluación relativos a la habilidad genérica correspondiente.
- Variables que miden las conductas que describen las diferentes habilidades derivadas. Estas variables se corresponden con las valoraciones referentes a las conductas que describen las diferentes habilidades derivadas, evaluadas en los test de evaluación y autoevaluación relativos a la habilidad genérica correspondiente. Un ejemplo de variable que se puede incluir en este grupo podría ser la que se refiere a la conducta: “Utiliza un lenguaje directo, sin rodeos”, donde los valores posibles que dicha variable puede tomar podrían ser: “Casi Siempre”, “A Veces” o “Casi Nunca”.
- Valoración Final resultante del procesamiento de los formularios de evaluación. (Se refiere a la calidad del desempeño de un rol dado, en un “corte evaluativo” de una asignatura determinada, o a la calidad general del desempeño de todos los roles implicados en dicho “corte evaluativo”, según el objetivo.)
- Calificación Final determinada por los evaluadores de las habilidades técnicas. (Se refiere a la calidad del desempeño de un rol dado, en un “corte evaluativo” de una asignatura determinada, o a la calidad general del desempeño de todos los roles implicados en dicho “corte evaluativo”, según el objetivo.)
- Clasificación. Identificación de características de un objeto o registro con el propósito de asignarle una clase o categoría predefinida. Para ello, se requiere construir un modelo de clasificación. La salida obtenida son valores discretos, que se distribuyen en grupos o clases. Para la clasificación existen varios tipos de técnicas: métodos de inducción de reglas, árboles de decisión, redes neuronales, algoritmos tipo k-nn (k-nearest neighbours), métodos bayesianos, entre otros.
- Determinación de grupos afines o reglas de asociación. Se encarga de descubrir fenómenos que ocurren de conjunto, aunque se desconoce el tipo de relación causal que existe entre estos. A partir de los grupos afines identificados es posible, generar reglas de asociación entre los datos. Una regla de asociación constituye una implicación X à Y, en la que X (antecedente) y Y (consecuente) representan conjuntos de pares atributo-valor. Si un atributo determinado aparece en el antecedente de una regla, entonces no aparecerá en el consecuente de la misma, y viceversa. Uno de los algoritmos más populares para generar reglas de asociación, y en el que se basan otros muchos algoritmos, es el Apriori.
- Agrupamiento o Clustering. Tiene el propósito de formar subgrupos homogéneos (clusters), a partir de un grupo diverso, según el grado de semejanza entre las instancias; los elementos de un cluster tienen una “similitud” alta entre ellos y baja con respecto a los elementos de otros clusters. La formalización del concepto de “similitud” es a través de métricas o medidas de distancia. Para implementar esta tarea se han desarrollado diferentes técnicas: métodos aglomerativos jerárquicos, divisivos jerárquicos, particionales, probabilísticos, entre otros.
- Es preciso modificar la forma en que tiene lugar, en la actualidad, el proceso de Evaluación del desempeño de roles en la carrera de Ingeniería Informática, para ello resulta conveniente poner en práctica la propuesta de evaluación enunciada en este trabajo.
- La propuesta se basa en la evaluación de las habilidades técnicas y genéricas desarrolladas por los estudiantes durante su formación, y en la aplicación de técnicas de minería de datos para el análisis de dichos resultados.
- Para la implementación, se propone un sistema que integra las herramientas: EvalSoft y KNIME. EvalSoft para proporcionarle a la plataforma KNIME las fuentes de datos necesarias para la aplicación de las técnicas de minería de datos seleccionadas.
- La propuesta permitirá identificar las fortalezas y debilidades de la carrera en relación al proceso de formación de los roles que precisa la Industria Nacional de Software y brindará elementos para proponer mejoras con el objetivo de perfeccionar la enseñanza de la Ingeniería Informática en Cuba.
La minería de datos, enriquece el proceso de análisis, descubriendo relaciones ocultas entre los datos e información desconocida; por lo que se propone la aplicación de técnicas de minería de datos para el análisis de dichos indicadores. Para ello, es necesario realizarlas siguientes tareas: definir las variables a utilizar en la minería de datos, definir la variable objetivo y seleccionar las técnicas de minería de datos a ser empleadas.
Aplicación de la Minería de Datos: definición de las variables para la minería de datos
Previo a la definición de las variables de entrada para la aplicación de las técnicas de minería de datos, es conveniente detallar los objetivos que se persiguen con el análisis de los datos disponibles. Estos objetivos son los siguientes:
A partir de los objetivos planteados, es posible definir los siguientes grupos de variables a utilizar en la minería de datos:
En correspondencia con los objetivos planteados anteriormente, se define “DESEMPEÑO” como variable objetivo, a partir de la Valoración Final y la Calificación Final:
La variable objetivo DESEMPEÑO Valoración Final, según la propuesta, toma valores nominales (Óptimo, Bueno, Regular, Malo); mientras que, la variable objetivo DESEMPEÑO Calificación Final, toma valores numéricos (5, 4, 3, 2), por lo que, en este caso, se decidió categorizar dicha variable como se muestra en la tabla 1:
]]> Una vez definidos los objetivos y las variables necesarias, es preciso seleccionar las técnicas y algoritmos de minería de datos a emplear.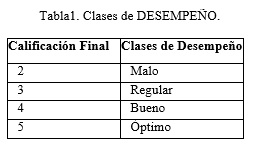
Selección de técnicas de Minería de Datos y herramientas
Para cumplir los objetivos antes enunciados se propone la aplicación conjunta de las siguientes técnicas de minería de datos: Clustering o agrupamiento, Determinar grupos afines o reglas de asociación y Clasificación (HAN, 2006) (HERNANDEZ, 2004) (WITTEN, 2005) (SUGANTHI, 2014) (LIAO, 2012) SREEVIDYA, 2014) (WESLEY, 2013) (FOSTER, 2013) (ZAKI, 2014).
Para la implementación de la propuesta de análisis de la calidad del proceso de formación de roles en la carrera de ingeniería informática, se propone un sistema que integra las herramientas: EvalSoft y KNIME (Konstanz Information Miner).
EvalSoft se encarga de automatizar las fases de recopilación, preparación y pre-procesamiento de los datos, con el objetivo de proporcionarle a una herramienta de minería de datos, las fuentes de datos necesarias para la aplicación de las técnicas de minería de datos seleccionadas (WILFORD, 2006).
]]>
KNIME es una plataforma de exploración de datos modular que guía el proceso de descubrimiento de conocimiento en bases de datos. Fue desarrollada originalmente en el departamento de bioinformática y minería de datos de la Universidad de Constanza, Alemania. Es una herramienta de código abierto, multiplataforma, y compuesta por módulos ensamblables que permiten extenderla. Se basa en el diseño de flujos de trabajo (workflows) de forma visual, y permite además ejecutar selectivamente algunos o todos los pasos de análisis, para luego investigar los resultados a través de vistas interactivas de los datos y modelos (BERTHOLD, 2007).
El sistema propuesto permitirá identificar las fortalezas y debilidades de la carrera en relación al proceso de formación de los roles que precisa la Industria Nacional de Software, así como descubrir posibles relaciones entre las variables definidas, ayudando a proponer mejoras con el objetivo de perfeccionar la enseñanza de la ingeniería informática en Cuba.
CONCLUSIONES
REFERENCIAS BIBLIOGRÁFICAS
AGRAWAL, R., IMIELINSKI, T., SWAMI, A. Mining association rules between sets of items in large databases. In: Proceedings of the ACM SIGMOD International Conference on Management of Data. 1993. Washington D.C., p. 207-216.
BROWN, Meta S. Data mining for dummies. John Wiley & Sons, 2014.
BRIN, S., MOTWANI, R., ULLMAN, J. D., TSUR, S. Dynamic itemset counting and implication rules for market basket data. Proceedings ACM SIGMOD International Conference on Management of Data. 1997. Tucson, Arizona, USA. p. 255-264
CHEN, M., HAN, J. AND YU P. Data Mining: An Overview from a Database Perspective. IEEE Transactions on Knowledge and Data Engineering, 1996. V.8 N.6, p.866-883.
CONEAU- http://www.coneau.gov.ar/
HAHSLER, Michael; HORNIK, Kurt; REUTTERER, Thomas. Implications of probabilistic data modeling for mining association rules. En From Data and Information Analysis to Knowledge Engineering. Springer Berlin Heidelberg, 2006. p. 598-605.
HERRERA VARELA, Ricardo. Bibliomining: minería de datos y descubrimiento de conocimiento en bases de datos aplicados al ámbito bibliotecario [en linea]. "Forinf@", vol. 33, 2006. [Consulta: 01/09/2014]. <http://lemi.uc3m.es/est/forinf@/index.php/Forinfa/rt/printerFriendly/122/127>
HIPP, Jochen; GÜNTZER, Ulrich; NAKHAEIZADEH, Gholamreza. Algorithms for association rule mining—a general survey and comparison. ACM sigkdd explorations newsletter, 2000, vol. 2, no 1, p. 58-64.
KANTARDZIC, M. Data Mining: Concepts, Models, Methods, and Algorithm . John Wiley & Sons .2003.343 pages.
LENCA, P., MEYER, P., VAILLANT, B., LALLICH, S. On selecting interestingness measures for association rules: user oriented description and multiple criteria decision aid. [en linea].
European Journal of Operational Research.Volume 184, Issue 2, 16 January 2008, Pages 610–626. [Consulta: 01/03/2008]. http://www.sciencedirect.com/science/article/pii/S0377221706011465
NICHOLSON, S. The basis for bibliomining: Frameworks for bringing together usage-based data mining and bibliometrics through data warehousing in digital library services. [en linea]. Information Processing & Management.Volume 42, Issue 3, May 2006, Pages 785–804 [Consulta: 01/02/2008]. http://www.sciencedirect.com/science/article/pii/S0306457305000658
LÓPEZ, Ana Pérez. La evaluación de colecciones: métodos y modelos.Documentación de las Ciencias de la Información, 2002, vol. 25, p. 321-360.
LUCAS, Joel Pinho. Métodos de clasificación basados en asociación aplicados a sistemas de recomendación. 2010. Tesis Doctoral. Universidad de Salamanca.
]]>
ROMERO, C. Aplicación de técnicas de adquisición de conocimiento para la mejora de cursos hipermedia adaptativos basados en Web. Tesis Doctoral.. Universidad de Granada. E.T.S. Ingeniería Informática. 2003.
SAHU, Hemlata; SHRMA, Shalini; GONDHALAKAR, Seema. A Brief Overview on Data Mining Survey. International Journal of Computer Technology and Electronics Engineering (IJCTEE) Volume, 2011, vol.1.
SILVERSTEIN, Craig; BRIN, Sergey; MOTWANI, Rajeev. Beyond market baskets: Generalizing association rules to dependence rules. Data mining and knowledge discovery, 1998, vol. 2, no 1, p. 39-68.
UNIVERSIDAD DE BUENOS AIRES. SISTEMA DE BIBLIOTECAS Y DE INFORMACIÓN. COMISIÓN TÉCNICA DE ESTÁNDARES. Estándares del Sistema de Bibliotecas de la Universidad de Buenos Aires. SISBI, Universidad de Buenos Aires, Secretaría de Ciencia y Técnica, Sistema de Bibliotecas y de Información, 2013.
VAILLANT, Benoît; LENCA, Philippe; LALLICH, Stéphane. A clustering of interestingness measures. En Discovery Science. Springer Berlin Heidelberg, 2004. p. 290-297.
]]>
ZHAO, Yanchang; ZHANG, Chengqi; ZHANG, Shichao. Discovering interesting association rules by clustering. En AI 2004: Advances in Artificial Intelligence. Springer Berlin Heidelberg, 2005. p. 1055-1061.
Recibido: 05/01/2015
Aceptado: 20/02/2015