Un algoritmo eficiente para problemas single machine con tiempos de procesamiento difusos
An efficient algorithm for single machine problems with fuzzy processing times
Edwin Lazo Eche1, Flabio Gutiérrez Segura1*, Edmundo Vergara Moreno3
1,2Universidad Nacional de Piura. Urb. Miraflores s/n, Castilla, Piura, Perú. lazoedwin88@gmail.com, flabio@unp.edu.pe
3Universidad Nacional de Trujillo. Calle Diego de Almagro 344, Trujillo, Perú. evergara@unitru.edu.pe ]]>
*Autor para la correspondencia: flabio@unp.edu.pe
RESUMEN
Los modelos clásicos de scheduling en single machine han sido estudiados con diversas características de procesamiento y funciones objetivo. La mayoría de técnicas propuestas para resolver este tipo de problemas no consideraron la naturaleza imprecisa de algunas variables que intervienen en su formulación. En este trabajo se propone un algoritmo para el cálculo del máximo tiempo de culminación ponderada en problemas de single machine con tiempos de procesamiento difusos y asignación de prioridades (pesos) a los trabajos. La metodología planteada representó la imprecisión de los tiempos de procesamiento mediante números difusos triangulares y utilizó una medida de comparación robusta y flexible basada en el concepto del intervalo esperado de un número difuso. Se obtuvo un schedule óptimo y robusto que soporta variaciones en los tiempos de procesamiento. El schedule óptimo se representó en forma gráfica mediante el diagrama de Gantt difuso. El algoritmo propuesto resulta ser eficiente en pruebas para un determinado conjunto de trabajos en la búsqueda de un schedule óptimo para el cálculo del máximo tiempo de culminación ponderada.
Palabras clave: scheduling difuso, single machine, números difusos, intervalo esperado.
ABSTRACT
The classic models of scheduling on single machine have been studied with different processing characteristics and objective functions. Most proposed techniques for solving such problems did not consider the imprecise nature of some variables involved in its formulation. This paper proposes a heuristic for calculating the maximum weighted completion tine in single machine problems with fuzzy processing times and priority assignments (weights) to the jobs. The proposed methodology represented imprecise processing times by triangular fuzzy numbers and used a measure robust and flexible comparison based on the concept of the expected inerval of a fuzzy number. Optimal and robust schedule that support variations in processing times was obtained. The optimal schedule is represented graphically by fuzzy Gantt chart. The proposed algorithm proves to be efficient based on tests made for a given set of jobs with the aim of find feasible schedule to calculate the maximum weighted completion time.
Key words: fuzzy scheduling, single machine, fuzzy numbers, expected interval.
INTRODUCCIÓN
El Scheduling en máquinas y sistemas es la fuente de trabajos de investigación desde aproximadamente 1950. Las diferentes áreas donde se aplica tienen como común denominador la asignación de tareas, la planificación de horizontes de trabajos y la optimización de las operaciones entre recursos y tareas, entre otros. Un scheduling puede definirse como la tarea de determinar el inicio y finalización de cada operación (Alharkan, 2010) a ser procesada en un taller (fábrica, planta). Al resultado de esta planificación se le denomina schedule (secuencia de trabajos) que puede ser, por ejemplo, un horario, planes de aterrizaje o de despegue de aviones, atraques de barcos, etc. Desde el punto de vista matemático, puede entenderse como un arreglo de trabajos y operaciones que deben satisfacer ciertas condiciones de asignación y restricciones, además de satisfacer una condición de la optimalidad en los resultados.
En el scheduling hay una gran brecha entre la teoría y la práctica, esto se debe, principalmente al hecho que en la modelación de los problemas no se considera la incertidumbre. Las causas de la incertidumbre se deben a: la falta de información, abundancia de información, conflicto en las evidencias, ambigüedad, medidas, creencias (Zimmermann, 2000). El desarrollo de la lógica difusa, permite considerar la incertidumbre como un elemento muy importante en la formulación de los problemas de asignación. La imprecisión es una incertidumbre de tipo difuso, en el cual se posee información subjetiva del estado de ocurrencia de un determinado suceso, o quizás que el comportamiento de una determinada variable está relacionado con un conjunto de valores numéricos.
En los entornos de scheduling, la imprecisión puede aparecer de manera natural, sobre todo en el estado del procesamiento de los trabajos (específicamente su duración), los adelantos, retrasos, los tiempos de culminación, el cumplimiento de una restricción de precedencia entre otras. Resulta natural, por ejemplo, considerar la imprecisión en el tiempo de aterrizaje de un avión en la pista de un aeropuerto, el descargue del contenido de un barco en un muelle, el atraque del mismo. Ambas tareas coinciden en el supuesto que, tanto la pista de aterrizaje y el muelle pueden ser considerados como una máquina simple.
El desarrollo de la lógica difusa, se dio casi en paralelo a los primeros algoritmos o modelos de scheduling, pero la espera por considerar la imprecisión en los entornos de scheduling tuvo que prolongarse hasta los inicios de la década de los 90’s.
Sobre fuzzy scheduling, las investigaciones se fundamentan en modelos de optimización, búsqueda de heurísticas e implementación de metaheurísticas eficientes considerando los datos de entrada como variables difusas (Wang y otros, 2002; Ahmadizar y Hosseini, 2011; Ishi y Tada, 1995).
El problema de fuzzy single machine, con imprecisión en los tiempos de procesamiento, ha sido abordado mediante un algoritmo que utiliza los grados de posibilidad y la necesidad de un schedule (Chanas y Kasperski, 2004). Este algoritmo requiere de todas las combinaciones posibles entre los trabajos y de optimizar sus medidas de posibilidad y necesidad, cuando el número de trabajos crece, se requiere demasiadas operaciones de cálculo.
En este trabajo, se consideran los problemas de scheduling en entornos single machine, con imprecisión en el tiempo de procesamiento de los trabajos, sin restricciones en el procesamiento de los trabajos, la función objetivo consiste en minimizar el máximo tiempo de culminación ponderada de los trabajos. Para resolver este problema, se propone un algoritmo, en el cual, la imprecisión en los tiempos de procesamiento de los trabajos se representa mediante números difusos triangulares, y se utiliza una medida de comparación robusta que permite ordenar números difusos para así obtener la secuencia óptima. A diferencia del algoritmo de Chanas y Kaspersky, no se requiere de todas las combinaciones posibles de los trabajos para determinar el schedule óptimo.
]]> El algoritmo obtenido, se justifica por la misma naturaleza de los problemas de single machine, los cuales pueden extenderse a problemas de máquinas paralelas u otros entornos de máquinas, donde cada pequeño problema puede ser considerado como uno de single machine.
METODOLOGÍA
Scheduling Clásico.
En su formulación, un problema de scheduling puede verse sujeto a ciertas restricciones que afecten su operatividad, por esta razón, se han desarrollado diversos métodos y algoritmos para relajar dichas restricciones. Las primeras restricciones se hallan en los diferentes recursos que intervienen, por ejemplo, las máquinas (Lawler, y otros, 1993). Una máquina es aquel recurso, disponible en todo el horizonte de tiempo sobre el cual se elabora la planificación, aunque en los últimos años esta condición clásica de disponibilidad se ha relajado (Potts, y otros, 2009). Las maquinas desarrollan los trabajos, en algunas ocasiones una sola máquina es suficiente, en otras, un trabajo necesita ser desarrollado por varias máquinas.
Otra restricción, se da en las características de procesamiento y restricciones. En base a la combinación entre máquinas, ambientes de procesamiento y establecimiento de funciones objetivo pudo establecerse una tipología de los problemas de scheduling, una de ellas es la notación de Graham (Graham, 1979), ![]() . Las siguientes tablas presentan las características de cada elemento en esta notación. Ver tabla 1 , tabla 2, tabla 3
. Las siguientes tablas presentan las características de cada elemento en esta notación. Ver tabla 1 , tabla 2, tabla 3
En este trabajo, el entorno de máquina es single machine. Se conoce un conjunto de n trabajos J1,...,Jn con tiempos de procesamiento Pij a ser procesados por la máquina i, pero como se trata de una sola máquina este índice puede omitirse; además los trabajos tienen pesos ![]() (prioridades que son asignadas bajo ciertas características o condiciones, por lo general determinada por expertos) tal que
(prioridades que son asignadas bajo ciertas características o condiciones, por lo general determinada por expertos) tal que ![]() . El tiempo de culminación del trabajo j en un schedule se denota por Cj.
. El tiempo de culminación del trabajo j en un schedule se denota por Cj.

El objetivo de este tipo de problemas consiste en encontrar un schedule que minimice ![]() . Usando la notación de Graham, el problema a resolver en este trabajo, se denota por
. Usando la notación de Graham, el problema a resolver en este trabajo, se denota por ![]() . Una metodologıa clásica consiste en el criterio de las proporciones de Smith (Lawler et al, 1993),, con la cual es posible encontrar un schedule óptimo ordenando de manera no decreciente las proporciones
. Una metodologıa clásica consiste en el criterio de las proporciones de Smith (Lawler et al, 1993),, con la cual es posible encontrar un schedule óptimo ordenando de manera no decreciente las proporciones ![]() , esto viene dado a través del siguiente teorema.
, esto viene dado a través del siguiente teorema.
Teorema 1. (Chanas y Kasperski, 2004). Un schedule S es óptimo para ![]() si y sólo si se cumple la siguiente condición:
si y sólo si se cumple la siguiente condición:

La demostración de este teorema se basa en un intercambio de posiciones del schedule que afectan la optimalidad (Brucker, 1998; Chanas, y otros, 2004). A nivel computacional, este teorema brinda una solución en tiempo polinomial cuyo orden está dado por O(nlog n) (Brucker, 1998).
Fuzzy Scheduling.
Fuzzy scheduling, es un tipo de problemas de scheduling en donde las variables de formulación, funciones objetivo o los ambientes de procesamiento presentan incertidumbre del tipo difusa. Para el desarrollo de este trabajo es necesario presentar algunos resultados básicos de esta teoría.
Definición 1. (Dubois et al, 1978). Un número difuso ![]() es un conjunto
es un conjunto ![]() de la recta real
de la recta real ![]() , convexo, normalizado tal que:
, convexo, normalizado tal que:


f(x) es una función semicontinua, estrictamente creciente en ![]() y g(x) otra función estrictamente decreciente en
y g(x) otra función estrictamente decreciente en ![]() . (ver Figura 1).
. (ver Figura 1).
Si las funciones semicontinuas son lineales entonces se puede hablar de dos tipos de números difusos: triangulares (c=d) y trapezoidales ![]() .
.
Dados dos números difusos ![]() y
y ![]() las operaciones aritméticas difusas se pueden realizar utilizando el principio de extensión propuesto por Zadeh (Zadeh, 1999).
las operaciones aritméticas difusas se pueden realizar utilizando el principio de extensión propuesto por Zadeh (Zadeh, 1999).

En el caso de la multiplicación por un escalar ![]() se utiliza la definición:
se utiliza la definición:

Definición 2. (Chanas y Kasperski, 2004). Si ![]() corte de un número difuso
corte de un número difuso ![]() es el conjunto:
es el conjunto:

donde ![]() corte define un intervalo cerrado.
corte define un intervalo cerrado.
Heilpern define el intervalo esperado de un número difuso ![]() utilizando las siguientes funciones inversas a partir de (3) (Heilpern, 1992):
utilizando las siguientes funciones inversas a partir de (3) (Heilpern, 1992):

así, el intervalo esperado denotado por ![]() viene dado por:
viene dado por:

El valor esperado de un número difuso, denotado por EV[![]() ] es el valor medio entre sus extremos, definido como:
] es el valor medio entre sus extremos, definido como:

Para dos números difusos ![]() y
y ![]() el intervalo esperado cumple con las condiciones de linealidad, esto es
el intervalo esperado cumple con las condiciones de linealidad, esto es


donde ![]() son los intervalos esperados de los números difusos
son los intervalos esperados de los números difusos ![]() y
y ![]() . Cuando M(
. Cuando M(![]() ;
;![]() ) = 0.5 se dice que
) = 0.5 se dice que ![]() y
y ![]() son indiferentes.
son indiferentes.
Algoritmo para ![]()
La imprecisión en los tiempos de procesamiento se representó mediante números difusos de tipo triangular ![]() , el cual está determinado por tres cantidades: P2 es el valor con más posibilidad de ocurrencia, P1 y P3 son los valores límites inferior y superior permitidos, respectivamente (ver Figura 2). Por ejemplo, estos valores límite pueden interpretarse como el más pesimista y el más optimista, en función del contexto.
, el cual está determinado por tres cantidades: P2 es el valor con más posibilidad de ocurrencia, P1 y P3 son los valores límites inferior y superior permitidos, respectivamente (ver Figura 2). Por ejemplo, estos valores límite pueden interpretarse como el más pesimista y el más optimista, en función del contexto.
El algoritmo difuso, desarrollado para resolver el problema planteado, se basó en el criterio de la proporción de Smith (Lawler et al, 1993), que resuelve el problema de scheduling single machine, pero sin contemplar imprecisión.
Sea ![]() el tiempo de procesamiento de cada trabajo j={1,.....,n} las proporciones
el tiempo de procesamiento de cada trabajo j={1,.....,n} las proporciones  obtiuvieron partir de (5). Para determinar el intervalo esperado de
obtiuvieron partir de (5). Para determinar el intervalo esperado de ![]() utilizando (7) y (8) se calculó
utilizando (7) y (8) se calculó

Se utilizó el intervalo esperado de cada proporción como medida de comparación para ordenar los trabajos en forma no decreciente. Para cada par de proporciones, la medida en que ![]() es mayor que
es mayor que ![]() se determinó usando (13).
se determinó usando (13).

Fue necesario generar un indicador para esta matriz que establezca una relación directa con el schedule óptimo. Para ello se obtiene una secuencia de escalares ![]() , tal que:
, tal que:

Mediante el ordenamiento de los escalares ![]() en un vector, se determina el schedule óptimo para el problema
en un vector, se determina el schedule óptimo para el problema ![]()
El procedimiento para determinar el schedule óptimo está dado por el siguiente algoritmo:
RESULTADOS Y DISCUSIÓN
El algoritmo se implementó en C++. Consideremos el siguiente caso de estudio, un problema de 10 trabajos a ser procesados en una máquina, con sus respectivos tiempos de procesamiento difusos y pesos (ver Tabla 4)
]]> Por ejemplo, para el trabajo 1, la duración del tiempo de procesamiento estará entre las 12 y 17 unidades de tiempo, con mayor posibilidad en las 14 unidades.Al ejecutar el algoritmo, mediante el paso 1, se obtuvo las proporciones de los trabajos. En el paso 2, se les aplicó la medida de comparación difusa. Con el paso 3, se obtuvo el vector ![]() = (0; 7; 2,8039; 9; 2,74603; 4,5; 8; 1; 6; 1,9167). De acuerdo al paso 4, con los
= (0; 7; 2,8039; 9; 2,74603; 4,5; 8; 1; 6; 1,9167). De acuerdo al paso 4, con los ![]() (i) ordenados en forma ascendente, se formó el vector
(i) ordenados en forma ascendente, se formó el vector ![]() = (0; 1; 1,9167; 2,746; 2,8039; 4,5; 6; 7; 8; 9)
= (0; 1; 1,9167; 2,746; 2,8039; 4,5; 6; 7; 8; 9)
De acuerdo al paso 5, el schedule óptimo que minimiza el máximo tiempo de culminación ponderada es: S = (1; 8; 10; 5; 3; 6; 9; 2; 7; 4)
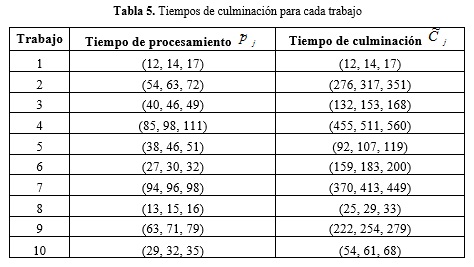
En la Tabla 5, obtenida del paso 6, se muestran los tiempos de culminación para cada trabajo. Figura 3.
El schedule obtenido para el caso de estudio se representó mediante el diagrama de Gantt difuso (ver Figura 4)
El máximo tiempo de culminación ponderada quedó minimizado por el schedule S y expresado en el número difuso triangular.
![]()
Es decir, al procesar los 10 trabajos en una máquina, el máximo tiempo de culminación ponderado puede ocurrir entre 5 681 y 7 164 unidades de tiempo, con más posibilidad de ocurrencia en 6 505 unidades de tiempo. Los tiempos de culminación también son de manera triangular, esto se evidencia en la deformación en los lados del polígono en la representación clásica del diagrama de Gantt. Puesto que se consideró la imprecisión en el tiempo de procesamiento de los trabajos, el resultado de este algoritmo también presenta un makespan robusto, el cual quedó determinado por el tiempo de culminación del trabajo con mayor proporción, para el caso de estudio, el trabajo 4.
]]> La robustez del makespan permite soportar la variabilidad de los tiempos de procesamiento de los trabajos en el schedule óptimo, siendo el makespan con más posibilidad de ocurrencia de 511 unidades de tiempo.Se ha tomado como caso de estudio un problema con 10 trabajos, pero el algoritmo se comporta de manera similar para una cantidad mayor de trabajos, demostrando en todas ellas su eficiencia para calcular el máximo tiempo de culminación ponderada y, sobre todo, la facilidad con la que se manipula la imprecisión en estos entornos.
CONCLUSIONES
El algoritmo, permite manejar la imprecisión en los tiempos de procesamiento de los trabajos en un problema de single machine donde intervienen prioridades o pesos en los trabajos. La solución óptima obtenida se refleja en un schedule robusto que soporta variaciones en los tiempos de procesamiento. De esta manera se proporciona una nueva metodología que puede modelar algunos problemas en donde una máquina sea capaz de procesar todos los trabajos que se presentan en un taller. En trabajos futuros se pretende 1) Implementar un algoritmo eficiente para problemas de single machine con restricciones de precedencia en el procesamiento de los trabajos, el cual corresponde a un problema NP-hard. 2) Extender los algoritmos difusos para single machine, a problemas de máquinas paralelas u otros entornos de máquinas.
AGRADECIEMIENTOS
Para la realización de este trabajo se ha contado con ayuda del Fondo para la Innovación Ciencia y Tecnología del Perú FINCyT (Proyecto PIBA-2-P-069-14).
REFERENCIAS BIBLIOGRÁFICAS ]]>
AHMADIZAR, F.; HOSSEINI, L. Single-machine scheduling with a position-based learning effect and fuzzy processing times. The International Journal of Advanced Manufacturing Technology, 2011, 56(5): p. 693-698.
ALHARKAN, I. Algorithms for sequencing and scheduling. Industrial Engineering Department, King Saud University, Riyadh, Saudi Arabia, 2010.
BRUCKER, P. Scheduling Algorithms. s.l.: Springer-Verlag, Osnabrück, Germany, 2004.
CADENAS, J. M.; VERDEGAY, J. L. Modelos de optimización con datos imprecisos. Universidad de Murcia, Servicio de Publicaciones, España, 1999.
CHANAS, S.; KASPERSKI, A. Minimizing maximum lateness in a single machine scheduling problem with fuzzy processing times and fuzzy due dates. Engineering Applications of Artificial Intelligence, 2001, 14(3): p. 377-386.
]]>CHANAS, S; KASPERSKI, A. Possible and necessary optimality of solutions in the single machine scheduling problem with fuzzy parameters. Fuzzy Sets and Systems, 2004, 142(3): p. 359-371.
DUBOIS, D.; PRADE, H. Operations on fuzzy numbers. International Journal of systems science, 1978, 9(6), p. 613-626.
GRAHAM, R. L., et al. Optimization and approximation in deterministic sequencing and scheduling: a survey. Annals of discrete mathematics, 1979, 5, p. 287-326.
HEILPERN, S. The expected value of a fuzzy number. Fuzzy sets and Systems, Wroclaw, Polonia, 1992. págs. 81-86.
ISHII, H.; TADA, M. Single machine scheduling problem with fuzzy precedence relation. European Journal of Operational Research, 1995, 87(2): p. 284-288.
]]>JIMÉNEZ, M. Ranking fuzzy numbers through the comparison of its expected intervals. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, España, 1996. p. 379-388.
LAWLER, E. L., et al. Sequencing and scheduling: Algorithms and complexity. Handbooks in operations research and management science, 1993, 4, p. 445-522.
POTTS, C. N.; STRUSEVICH, Vitaly A. Fifty years of scheduling: a survey of milestones. Journal of the Operational Research Society, 2009, 60(1): p. 41-68.
WANG, C, et al. The single machine ready time scheduling problem with fuzzy processing times. Fuzzy sets and systems, 2002, 127(2): p. 117-129.
ZADEH, L. A. Fuzzy sets as a basis for a theory of possibility. Fuzzy sets and systems, 1999, 100, p. 9-34.
]]>ZIMMERMANN, H. An application-oriented view of modeling uncertainty. Elsevier, 2000. 122, págs. 190-198.
Recibido: 20/07/2016
Aceptado: 30/09/2016