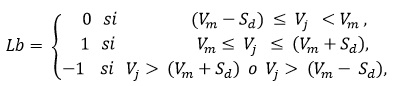Segmentación consenso y matriz de co-ocurrencia ordinal en el reconocimiento del iris
Consensus segmentation and ordinal co-occurrence matrix in iris recognition
Dailé Osorio Roig1*, Yasser Chacón Cabrera1, Eduardo Garea Llano1
1Centro de Aplicaciones de Tecnologías de Avanzada (CENATAV). 7a No. 21406 e/ 214 and 216, Siboney, Playa, La Habana, Cuba. CP 12200, dosorioroig@gmail.com, ychacon@cenatav.co.cu, egarea@cenatav.co.cu
]]>
*Autor para la correspondencia: dosorioroig@gmail.com
RESUMEN
En los últimos años la identificación biométrica de personas ha ido cobrando gran importancia en el mundo a partir de sus aplicaciones en múltiples escenarios, sobre todo aquellas aplicaciones encaminadas a la seguridad de fronteras, controles de acceso y forenses. En este trabajo se realiza una breve introducción a los sistemas de reconocimiento de personas por el iris y se abordan dos de sus temáticas, que actualmente se encuentran en proceso de investigación. El proceso de segmentación del iris, en una imagen tomada del ojo de una persona, es abordado a partir de la descripción de las investigaciones que los autores han desarrollado en el tema de la fusión de segmentaciones y su mejoramiento. En esta temática es utilizado el concepto de segmentación consenso para mejorar la robustez en el reconocimiento de iris con respecto a la realización de una simple segmentación. El proceso de extracción de rasgos del iris es abordado mediante la descripción de una representación propuesta por los autores sobre la base de los rasgos ordinales de la matriz de co-ocurrencia, para un sistema de reconocimiento de iris, que eleva la exactitud en el reconocimiento. Los resultados experimentales descritos y realizados sobre bases de datos internacionales de referencias, muestran la pertinencia y robustez de estas propuestas.
Palabras clave: Fusión de segmentaciones, segmentación en el iris, segmentación consenso, extracción de rasgos, medidas ordinales, matriz de co-ocurrencia ordinal.
ABSTRACT
In recent years, the biometric identification of people has gained great importance in the world from its applications in multiple scenarios, especially those applications aimed at border security, access controls and forensics. In this article, a brief introduction to the systems of recognition of people by the iris is made and two of their subjects are addressed, which are currently under research. The process of segmentation of the iris, in an image taken from the eye of a person, is approached from the description of the investigations that the authors have developed in the subject of the fusion of segmentations and their improvement. In this theme the concept of consensus segmentation is used to improve the robustness of the iris recognition with respect to the simple segmentation. The process of iris feature extraction is addressed by describing a representation proposed by the authors based on the ordinal features of the co-occurrence matrix, for an iris recognition system, which raises accuracy in recognition. The experimental results described and performed on international databases of references, show the relevance and robustness of these proposals.
Key words: Fusion of segmentations, iris segmentation, consensus segmentation, trait extraction, ordinal measures, ordinal co-occurrence matrix.
INTRODUCCIÓN
La biometría es definida como el estudio de los métodos para la medición de los atributos físicos, biológicos o de comportamiento, que son utilizados para la identificación de personas. Dentro del campo de la biometría, las huellas dactilares el rostro y el iris son considerados en la actualidad los métodos biométricos más utilizados.
El reconocimiento del iris es una de las modalidades biométricas que más auge ha alcanzado en los últimos 25 años, debido a su carácter único como característica biométrica y biológica (ISO/IEC, 2005), lo que hace que los sistemas de identificación y verificación basados en iris sean uno de los más exactos y muy difícil de suplantar.
El uso de la modalidad biométrica del iris en aplicaciones específicas involucra a una serie de 7 factores identificados por Jain et al., (2002, 2004, 2007) que están presentes en un sistema de identificación de esta naturaleza:
Universalidad (todo el mundo posee la característica), significa que toda persona posee las características de textura del iris.
Unicidad (la característica es diferente para todo el mundo), significa que los rasgos de textura del iris son lo suficientemente diferentes para cada individuo, de tal manera que estos pueden ser distinguidos uno del otro. El patrón del iris es epigenético (no determinado genéticamente).
Diferencialidad (alto poder discriminativo debido a su entropía). La aleatoriedad del patrón del iris tiene una alta dimensionalidad la que es superior a los 266 grados de libertad (Daugman, 1998).
Permanencia (la característica se mantiene invariante en el tiempo de vida, excepto por cambios de pigmentación en el tiempo), significa que la textura del iris se mantiene invariante en el tiempo.
Medibilidad (la característica es fácil de capturar), se refiere a la facilidad de adquisición de la imagen de la textura del iris. La imagen adquirida debe estar en un formato que permita el procesamiento subsecuente y la extracción del conjunto de rasgos relevantes.
Desempeño, se refiere a la exactitud, velocidad y robustez de la tecnología utilizada en todo el proceso.
Aceptabilidad (la característica es no invasiva), se refiere a lo bien que las personas aceptan la tecnología en la modalidad biométrica del iris. La captura de la imagen de iris es no-invasiva.
Imitabilidad (imitabilidad de la característica), relativo a la facilidad o no de que el iris humano sea imitado o falsificado utilizando artefactos o sustitutos.
Un sistema de reconocimiento de iris puede operar en dos modos. En modo autentificación-verificación el sistema realiza la comparación uno-a-uno del conjunto de rasgos del iris, capturados con una plantilla (IrisCode) almacenada en una base de datos de iris, con el objetivo de verificar si la persona es quien dice ser. En el modo de identificación el sistema efectúa una comparación de uno-a-muchos contra una base de datos de iris, para establecer la identidad de un individuo desconocido. El sistema será exitoso en la identificación de la persona si la comparación del iris de entrada con una plantilla de iris en la base de datos está dentro de un umbral previamente definido. El modo de identificación puede ser utilizado también para el “reconocimiento positivo (el usuario no tiene que brindar ninguna información sobre la plantilla a utilizar) o para el “reconocimiento negativo” de la persona donde el sistema determina si la persona es quien (implícita o explícitamente) niega ser.
El reconocimiento de iris es actualmente uno de las técnicas biométricas más exactas. Sin embargo, el desempeño de tales sistemas puede ser reducido en condiciones no-ideales, tales como la no voluntariedad, el movimiento o la no colaboración (Labati et al., 2012).
En un sistema de reconocimiento de iris, el pre-procesamiento, especialmente la localización del iris juega un papel muy importante (Sánchez et al., 2014ª). La velocidad y el desempeño de un sistema de esta índole son cruciales y están limitados en gran medida por la localización o segmentación del iris. La segmentación del iris incluye encontrar las fronteras del iris (interior y exterior) y la pestañas (superior e inferior) (Cui et al., 2004).
En este sentido recientes estudios han demostrado que la fusión en el nivel de segmentación (Sánchez et al 2014b, Garea et al., 2015) ha contribuido a la robustez en el reconocimiento de iris con respecto a la realización de una simple segmentación. En este trabajo presentamos un enfoque (Osorio y Garea, 2016) en el cual, dado un conjunto de segmentaciones iniciales, podemos establecer segmentaciones consenso que pueden mejorar los resultados de dichas segmentaciones iniciales, y además si estas son combinadas mediante la fusión, es posible superar el resultado del proceso de fusión con las segmentaciones iniciales. Este mecanismo se basa en el enfoque de la partición de la mediana pesada. La imagen de ojo es tratada como un conjunto de píxeles, las diferentes segmentaciones se tratan como un subconjunto del conjunto de píxeles, teniendo en cuenta esta modelación del problema podemos aplicar técnicas de agrupamiento de conjunto para construir segmentaciones consenso. Esta propuesta contribuye a la obtención de segmentaciones más precisas y robustas. El esquema propuesto fue evaluado en dos bases de datos internacionales Casia V3-Interval y Casia.V4-Thousand demostrando ser un enfoque prometedor para lograr sustanciales aumentos de la eficacia en el reconocimiento de personas por el iris.
Otra tarea importante en el proceso de reconocimiento del iris es la extracción de rasgos de los patrones de textura del iris. El concepto general de Proceso Biométrico de Extracción de Rasgos es definido como el proceso aplicado a la muestra biométrica con la intención de extraer números o etiquetas distintivas y repetibles que puedan ser comparables a las que se extraen de otras muestras biométricas.
Las investigaciones de los métodos de extracción de rasgos (Chacón et al., 2014) para el reconocimiento del iris han sido dirigidas a obtener técnicas y algoritmos para el reconocimiento robusto del iris. Sin embargo, un asunto clave y un tema abierto en el reconocimiento del iris es cómo lograr una mejor representación de la información de textura del iris utilizando un conjunto compacto de rasgos.
En los últimos 30 años han sido propuestos una gran cantidad de algoritmos que buscan una mejor descripción de la textura del iris humano. El problema todavía está en encontrar rasgos que sean robustos a las diferentes condiciones en las que pueden ser capturadas las imágenes. En este capítulo se describe también una representación de la textura del iris basada en los rasgos de la matriz de co-ocurrencia ordinal (OCMF) para un sistema de reconocimiento de iris que eleva la exactitud en el reconocimiento (Chacón et al, 2015). La novedad de esta propuesta está en la nueva estrategia para aplicar un método de extracción de rasgos robusto para la descripción de la textura del iris. Los experimentos en las bases de datos Casia-Interval, Casia-Thousand y Ubiris-V1 muestran que el esquema propuesto incrementa la exactitud del reconocimiento y es robusta a diferentes condiciones de captura de las imágenes.
]]> La estructura del trabajo es la siguiente, en el desarrollo se definen dos fundamentos, en el fundamento 1 se introduce el primer tema abordado relacionado con la segmentación consenso en el proceso de fusión de segmentaciones, en el fundamento 2 se introduce el segundo tema abordado relacionado con la descripción textural del iris utilizando los rasgos de la matriz de co-ocurrencia ordinal. Luego son presentados los resultados obtenidos en ambas temáticas. Finalmente se ofrecen las conclusiones de este trabajo.
MATERIALES Y MÉTODOS
Las técnicas de agrupamiento de conjunto han contribuido de una manera eficiente y eficaz para tratar con problemas de agrupamiento de datos (Vega et al. 2011). Además, se conoce que, si al mismo conjunto de datos son aplicados muchos algoritmos de agrupamiento, se obtienen diferentes resultados. En este caso la idea de buscar el mejor agrupamiento no sería la solución. A partir de esta idea es que surge la propuesta de combinar estos resultados individuales con el objetivo de obtener un consenso (Vega et al., 2010). Algunos autores (Fred et al. 2005), (Franek et al. 2011 ), (Vega, 2010) han probado esta propuesta con el objetivo de demostrar que la aplicación de algoritmos de agrupamiento de conjunto es posible en problemas de segmentación de imagen.
Específicamente en el reconocimiento del iris la segmentación de consenso (S*) es aplicada como un mecanismo para mejorar las segmentaciones antes del proceso de fusión. Esta segmentación consenso es construida a través de una técnica de agrupamiento de conjunto basada en Weighted Partition Consensus via kernels (WPCK), método introducido en (Vega et al., 2010). Inicialmente cada segmentación inicial es modelada como partición del conjunto píxeles, donde cada segmentación estará particionada por diferentes grupos de píxeles. Cada grupo de cada segmentación pertenecerá a la misma región de cada segmentación, respetando su relación espacial y el color de los píxeles de un mismo grupo. Seguidamente la segmentación consenso es calculada mediante la siguiente ecuación basada en WPCK:
![]()
Donde ![]() , debido a que k es una función kernel existe una función
, debido a que k es una función kernel existe una función ![]() que permite mapear el problema definido en la ecuación 1 a un espacio Hilbert asociado a k (Vega et al., 2010). Basado en esta definición la ecuación 1 puede ser reescrita como la ecuación 2, donde
que permite mapear el problema definido en la ecuación 1 a un espacio Hilbert asociado a k (Vega et al., 2010). Basado en esta definición la ecuación 1 puede ser reescrita como la ecuación 2, donde ![]() es la segmentación consenso teórica en el espacio Hilbert y
es la segmentación consenso teórica en el espacio Hilbert y ![]() es la función que permite mapear las particiones de entrada en el espacio. El algoritmo obtiene la segmentación más cercana a la segmentación consenso teórica (
es la función que permite mapear las particiones de entrada en el espacio. El algoritmo obtiene la segmentación más cercana a la segmentación consenso teórica (![]() ). Esta segmentación final calculada en la ecuación1 por k es llamada S*. Otra función kernel utilizada en la ecuación 1 para calcular S* es el Índice Rand (RI) (Vega et al., 2010). En este caso
). Esta segmentación final calculada en la ecuación1 por k es llamada S*. Otra función kernel utilizada en la ecuación 1 para calcular S* es el Índice Rand (RI) (Vega et al., 2010). En este caso ![]() = RI, RI es calculado en (Vega et al., 2010) y definido en (Vega et al., 2010):
= RI, RI es calculado en (Vega et al., 2010) y definido en (Vega et al., 2010):
![]()
En (Vega et al., 2010) se demuestra matemáticamente por qué fue posible utilizar RI como una función kernel para comparar particiones. El objetivo de utilizar dos criterios diferentes en la ecuación 1, es debido a la necesidad de evaluar la segmentación en dos medidas de similitud diferentes, así como analizar el comportamiento de la información entre dos segmentaciones a partir del significado de cada medida. A partir de la ecuación 2, S* es calculado mediante un problema de optimización en el que S* es la segmentación con menor distancia a la solución del espacio Hilbert. La optimalidad es encontrada mediante la metaheurística Recocido Simulado (Kirkpatrick et al., 1983).A continuación, se muestran los pasos principales para encontrar S*.
Aplicación de la metaheurística Recocido Simulado: A partir de S0 el algoritmo busca una nueva segmentación mejor que la segmentación actual.
A partir de la obtención de la segmentación final, el algoritmo sustituye cada grupo en la segmentación final por los píxeles que lo representan, con el objetivo de formar la segmentación final consenso.
Fundamentos
En el 2009 (Sun y Tan, 2009) proponen un marco general para el análisis de la textura del iris sobre la base del concepto de las medidas ordinales (OMs). En su revolucionaria propuesta codifican la relación ordinal entre varios parches (regiones) de la imagen normalizada utilizando valores cuantitativos. Dichos valores cuantitativos pueden representar el resultado de comparaciones ordinales entre un gran número de parámetros dentro de las regiones de la imagen. Por ejemplo, la forma de la región, localización de la región, promedio de intensidad de los valores de los pixeles en la región, el resultado del filtrado de la región (usando diferentes filtros como Gabor, Wavelet, etc.). Esta variedad de parámetros permite desarrollar marcos de trabajos personalizados para cada necesidad y aplicación específica. Los resultados experimentales alcanzan el primer lugar en el estado-del-arte, tanto en la eficacia como la eficiencia.
Motivados por los resultados obtenidos por las OMs y su flexibilidad para el reconocimiento biométrico del iris, se propone usar la matriz de co-ocurrencia ordinal (Partio et. al 2007) para representar los rasgos de textura del iris. La figura 1 representa el diagrama de flujo de la nueva propuesta, donde se muestran las peculiaridades del uso de OCMF en la etapa de extracción de rasgos. Los pasos principales del método serán explicados a continuación:
]]> 1 - Selección de la región. La imagen normalizada del iris T se divide en regiones solapadas Rp.donde P es el número total de regiones en T. Las regiones son solapadas tomando un valor de desplazamiento d entre los pixeles centrales cp de cada región. Cada región es un bloque rectangular de tamaño N x M.
2 - Etiquetado Ordinal. A cada pixel de la región se le asigna un código o etiqueta basado en la comparación ordinal entre los valores de intensidad de los pixeles de la siguiente manera:
donde Vm es el valor medio de intensidad de los pixeles de la región, Sd es la desviación estándar y Vj es el valor de intensidad del pixel j en la región. Los pixeles etiquetados con -1 están fuera del rango
y no son considerados en la siguiente etapa. Con esta estrategia es posible atenuar algunos problemas de ruido, causados por la iluminación, en imágenes tomadas en ambientes menos controlados.
3 - División en Sub-Regiones. Con el objetivo de acelerar el proceso de extracción de rasgos cada región Rp se divide en sub-regiones. El valor más representativo de cada sub-región es tomado como el valor de la sub-región.
4 - Extracción de las matrices de co-ocurrencia Ordinal. La idea en este paso es contar la ocurrencia de cierto patrón variando la orientación y la distancia. Como estamos trabajando con una codificación binaria (los pixeles etiquetados con -1 no son tomados en cuenta) 00, 01, 10 y 11 son los posibles valores entre dos pixeles a comparar. Para cada uno de estos patrones vamos a obtener una matriz de co-ocurrencia de tamaño N x O, donde N representa el número de distancias y O el de orientaciones utilizados. Estas 4 matrices van a representar la textura de la región.
5 - Construcción del vector de rasgos. Para representar la textura global de iris se crea un vector de rasgo de tamaño P, en cada posición van a estar las 4 matrices de co-ocurrencia de la región Rp.
RESULTADOS Y DISCUSIÓN
]]> A continuación, se muestran los resultados obtenidos en cada temática. En la primera temática relacionada con la generación de la segmentación consenso, para evaluar su validez se trabajó con el esquema experimental mostrado en la figura 2. Nuestra propuesta es un paso previo de la fusión de segmentaciones iniciales, que permite obtener el mejor conjunto de segmentaciones iniciales, sustituyendo en el conjunto inicial de segmentaciones, aquella segmentación con peor reconocimiento, por la segmentación consenso que la supera en cuanto a precisión. El esquema experimental recibe tres segmentaciones iniciales, o sea tres segmentaciones generadas por algoritmos de segmentación automática; en nuestro caso se utilizaron transformada de Hough basado en el ajuste de contraste (CHT) (Masek,2003), transformada de Hough basado en la elipse polar (WHT) (Uhl et.al 2012) y en el ponderamiento adaptativo (Viterbi) (Sutra et.al 2012). Además, se utilizaron cuatro métodos de extracción de rasgos: Daugman (Daugman, 1993), Masek (Masek,2003), Ma (Ma et.al 2003) y Monro (Monro et. Al 2007). El método de fusión utilizado en el esquema experimental fue la Pirámide Laplaciana (Garcia et al., 2015).El esquema fue validado para las bases de datos CASIA-V3-Interval y CASIA.v4-Thousand. La evaluación de desempeño y la exactitud de la segmentación fueron evaluadas por el grado de influencia en la precisión del reconocimiento de verificación. Se estimó por las curvas ROC, la tasa de falsa de aceptación (FAR), la tasa de aceptación en su versión genuina (GAR). La Tasa de Error Igual o Equal Error Rate (EER) es la localización en la curva ROC del punto en el cual la Tasa de Falso Rechazo (FRR) y la Tasa de Falsa Aceptación se hacen iguales. También utilizamos como medida de exactitud el índice de Decibilidad (d’) ampliamente utilizado en la literatura biométrica. El d’ de la tarea de reconocimiento de personas por sus patrones se obtenido mediante la comparación de distribuciones de la Distancia de Hamming.
Las siguientes tablas reportan los resultados del GAR, la tasa de error igual (ERR) y el d’ por cada segmentación automática, por las diferentes segmentaciones consenso y por el resultado fusionado. En el caso de la base de datos CASIA 3 la tabla 1 y tabla 2 muestran la comparación de los resultados obtenidos en el proceso de obtención de las segmentaciones aplicando el método propuesto con distintas medidas de similitud (Consenso kernel y Consenso Rand) con las segmentaciones simples. Los resultados demuestran que las segmentaciones consenso mejoran el resultado de la verificación cuando se utilizan en lugar de las segmentaciones iniciales.
En el caso de la base de datos CASIA 4, la tabla 3 y tabla 4 muestran el mismo comportamiento de las tablas anteriores, sólo con la diferencia de que se muestra el proceso de fusión como paso después de la obtención del mejor conjunto de segmentaciones. En este caso en el proceso de fusión se aprecia un sustancial aumento de la eficacia respecto a las segmentaciones simples y a las segmentaciones consenso por separado. Esto demuestra que el enfoque propuesto es prometedor y puede ser robusto ante varios problemas de segmentación.
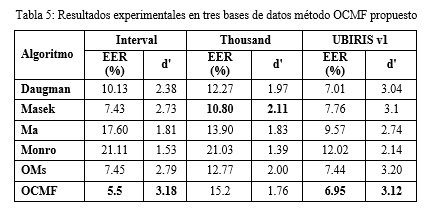
Para evaluar el método de extracción de rasgos propuesto, además de las bases de datos ya mencionadas, se utilizó UBIRIS-V1. Se adaptó el mismo método para evaluar el desempeño. La propuesta se comparó con los cuatro métodos de extracción de rasgos citados anteriormente incluyendo el método OMs utilizando la variante dos-lóbulos.
Como paso previo a la extracción de rasgos las imágenes de las bases de datos fueron segmentadas y normalizadas utilizando el método Viterbi. El proceso de comparación se realizó mediante el cotejo de las cuatro matrices correspondientes a una misma región. Se utilizó la distancia Euclidiana para la comparación entre matrices y se sumó el resultado de la comparación entre las cuatro matrices de cada región. Como resultado final se tomó la sumatoria de cada uno de los resultados locales obtenidos.
Los resultados experimentales del método de extracción de rasgo OCMF propuesto, como se muestra en la Tabla 5, permiten apreciar una reducción del EER y un aumento del índice d'. De los cinco métodos de extracción de rasgos evaluados es posible ver que el método propuesto OCMF obtiene un mejor rendimiento para dos bases de datos (Interval y UBIRIS-v1). Sin embargo, en la base de datos Thousand el comportamiento es diferente, aunque mantiene un nivel similar de precisión que el resto de los algoritmos, sólo alcanza superar al método de Monro. Este hecho podría ser causado por la presencia de lentes y las reflexiones especulares en esta base de datos. Este comportamiento también puede ser producido por una incorrecta selección de la cantidad y distribución de las regiones en la imagen normalizada del iris.
Futuras investigaciones
En futuras investigaciones se continuará trabajando con el esquema experimental propuesto en la figura 2, específicamente en el nivel de fusión de segmentación. Con el objetivo de seguir mejorando la etapa de segmentación antes de que el error cometido en esta etapa sea propagado a otras etapas del reconocimiento del iris. La idea principal es aprovechar este proceso de fusión no solamente para mejorar las tasas de reconocimiento, sino de lograr la segmentación cuando una imagen de ojo se encuentra en varios escenarios a la vez, como por ejemplo cuando el ojo está fuera de ángulo, a distancia, bajo la luz visible, presenta problemas graves de oclusión, etc. De manera general se pretende trabajar de forma independiente en cada escenario y mediante un mecanismo de fusión se combinen todos los escenarios para ganar en eficiencia y en eficacia.
]]> En el método de extracción de rasgo propuesto, como futura investigación, se pretende trabajar en varios aspectos. Primero tratar de hallar el tamaño correcto en la selección de las regiones de la imagen, tomando como referencia la calidad y resolución de las imágenes del iris. Segundo mejorar la codificación ordinal en cada una de las regiones, con el fin de lograr una mayor representación y discriminación de la textura. Por último, lograr una representación más compacta de los rasgos extraídos para mejorar la eficiencia en cuanto a tiempo de procesamiento.
CONCLUSIONES
El reconocimiento de iris es actualmente uno de las técnicas biométricas más exactas. En un sistema de reconocimiento de iris, el pre-procesamiento, especialmente la segmentación del iris juega un papel muy importante. Otra tarea importante en el proceso de reconocimiento del iris es la extracción de rasgos desde los patrones de textura del iris.
Mediante el enfoque presentado basado en la partición de la mediana pesada utilizando diferentes medidas de similitud podemos obtener diferentes segmentaciones consensos, que superan la tasa de reconocimiento de algunas de las segmentaciones iniciales generadas por diferentes algoritmos de segmentación automática.
La generación de segmentaciones consensos permitió diversificar el conjunto de segmentaciones iniciales capturando más características de la textura del iris y haciendo que la tasa de reconocimiento del proceso de fusión sea más alta que fusionando las imágenes normalizadas de las segmentaciones iniciales.
El método de extracción de rasgos basado en los rasgos de la matriz de co-ocurrencia ordinal es capaz de obtener características del iris que son invariantes a los cambios monotónicos de los niveles de grises en los valores de los pixeles, por lo tanto, se puede aplicar a las imágenes del iris que se obtienen en ambientes menos controlados, por ejemplo, bajo diferentes condiciones de iluminación.
REFERENCIAS BIBLIOGRÁFICAS
Yasser Chacón-Cabrera, José Luis Gil-Rodríguez, and Eduardo Garea-Llano. Technical Report of CENATAV . Iris Feature Extraction Methods. Update 2013. RT_060, Blue Series. Pattern Recognition. digital version. RNPS_ 2142, ISSN 2072-6287, Febrary 2014. Published on line in http://www.cenatav.co.cu/index.php/publications-cenatav/blue-seriepublications.
Yasser Chacon-Cabrera, Man Zhang, Eduardo Garea Llano, Zhenan Sun: Iris Texture Description Using Ordinal Co-occurrence Matrix Features:. In Alvaro Pardo, Josef Kittler: Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications - 20th Iberoamerican Congress, CIARP 2015, 184-191, Montevideo, Uruguay, November 9-12, 2015, Proceedings. Lecture Notes in Computer Science 9423, Springer 2015, ISBN 978-3-319-25750-1.
Cui, J., Wang, Y., Tan, T., Ma, L., Sun, Z. (2004): A fast and robust iris localization method based on texture segmentation. In: Jain, A., Ratha, N. (eds.) Biometric Technology for Human Identification, Proceedings of SPIE, vol. 5404, pp. 401–408. SPIE, Bellingham, WA. DOI: 10.1117/12.541921.
Daugman, J.G., High confidence visual recognition of persons by a test of statistical independence. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 1993. 15(11): p. 1148-1161.
Daugman, J.G. (1994): Biometric personal identification system based on iris analysis. The Computer Laboratory, University of Cambridge, Patent: 5291560.
Daugman, J.G.: Recognizing Persons by Their Iris Patterns. Technical Keynote Lecture. In http://www.cse.msu.edu/~cse891/Sect601/textbook/5.pdf. Fecha de consulta: 2 febrero de 2016.
Franek, L., et al., Image segmentation fusion using general ensemble clustering methods, in Computer Vision–ACCV 2011, Springer. p. 373-384.
]]>Fred, A.L. and A.K. Jain, Combining multiple clusterings using evidence accumulation. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2005. 27(6): p. 835-850.
Mireya S. García-Vázquez, Eduardo Garea Llano, Juan Miguel Colores-Vargas, Luis Miguel Zamudio-Fuentes, Alejandro Alvaro Ramírez-Acosta: A Comparative Study of Robust Segmentation Algorithms for Iris Verification System of High Reliability. MCPR 2015: 156-165. In Jesús Ariel Carrasco-Ochoa, José Francisco Martínez Trinidad, Juan Humberto Sossa Azuela, José Arturo Olvera-López, Fazel Famili:Pattern Recognition - 7th Mexican Conference, MCPR 2015, Mexico City, Mexico, June 24-27, 2015, Proceedings. Lecture Notes in Computer Science 9116, Springer 2015, ISBN 978-3-319-19263-5.
Eduardo Garea Llano, Juan Miguel Colores-Várgas, Mireya S. García-Vázquez, Luis Miguel Zamudio-Fuentes, Alejandro Alvaro Ramírez-Acosta: Cross-sensor iris verification applying robust fused segmentation algorithms. International Conference on Biometrics ICB 2015: IEEE. 17-22. DOI:10.1109/ICB.2015.7139042.
ISO/IEC-19794-6:2005(E): Information technology - Biometric data interchange formats. Part 6: Iris image data. Subcommittee SC 37, Biometrics, International Standard Organization, First edition, © ISO/IEC 2005.
Jain, A.K., Prabhakarb, S. and Pankantic, S.: On the similarity of identical twin fingerprints, Pattern Recognition 35 (2002) 2653 – 2663,
Jain, A.K., Ross, A., Prabhakar, S.: An introduction to biometric recognition. IEEE Trans. Circ. Syst. Video Tech. 14, 4–20 (2004). doi: 10.1109/TCSVT.2003.818349
Jain, A., Flynn, P., Ross, A.: Handbook of Biometrics. Springer-Verlag New York, Inc., Secaucus, NJ, USA (2007).
S. Kirkpatrick, C. D. Gelatt,M. P. Vecchi, et al. Optimization by simulated annealing. science, 220(4598):671–680, 1983.
]]>Labati, R.D., Genovese, A., Piuri, V. and Scotti, F.: Iris Segmentation: State of the Art and Innovative Methods, Intelligent Systems Reference Library Volume 37, 2012, pp 151-182, Chapter 8 in Cross Disciplinary Biometric Systems.
Ma, L., et al., Personal identification based on iris texture analysis. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2003. 25(12): p. 1519-1533.
Monro, D.M., S. Rakshit, and D. Zhang, DCT-based iris recognition. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2007. 29(4): p. 586-595.
Daile Osorio Roig, Eduardo Garea Llano. Segmentaciones Consenso en el reconocimiento del iris. Memorias Informática 2016.
Partio, M., Cramariuc, B., Gabbouj, M. An ordinal co-occurrence matrix framework for texture retrieval. J. Image Video Process. 2007. p1–1.
Yasiel Sanchez-Gonzalez, Yasser Chacon-Cabrera, Eduardo Garea-Llano. A Comparison of Fused Segmentation Algorithms for Iris Verification. E. Bayro-Corrochano and E. Hancock (Eds.): CIARP 2014, LNCS 8827, pp. 112–119, 2014. Springer International Publishing Switzerland 2014.
]]> Zhenan Sun, Tieniu Tan. Ordinal measures for iris recognition. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2009. 31(12): p 2211–2226.Sutra, G., S. Garcia-Salicetti, and B. Dorizzi. The viterbi algorithm at different resolutions for enhanced iris segmentation. in Biometrics (ICB), 2012 5th IAPR International Conference on. 2012. IEEE.
Uhl, A. and P. Wild. Weighted adaptive hough and ellipsopolar transforms for real-time iris segmentation. in Biometrics (ICB), 2012 5th IAPR International Conference on. 2012. IEEE.
Vega-Pons, S., J. Correa-Morris, and J. Ruiz-Shulcloper, Weighted partition consensus via kernels. Pattern Recognition, 2010. 43(8): p. 2712-2724.
Vega Pons, S., Combinación de Resultados de Clasificadores no Supervisados, 2010.
Vega-Pons, S. and J. Ruiz-Shulcloper, A survey of clustering ensemble algorithms. International Journal of Pattern Recognition and Artificial Intelligence, 2011. 25(03): p. 337-372.
Recibido: 03/09/2016
Aceptado: 30/11/2016