Estudio del comportamiento de métodos basados prototipos y en relaciones de similitud ante “hubness”
A study of the behavior of methods based on prototypes and similarity relations in the face of “hubness”
Yanela Rodríguez Alvarez1*, Rafael Bello Pérez 2,Yailé Caballero Mota1, Yailé Caballero Mota1, Yaima Filiberto Cabrera1, Yumilka Fernández Hernández1, Mabel Frías Hernández1
1 Departamento de Computación, Universidad de Camagüey, Circunvalación Norte Km 5 ½, Camagüey, Cuba. {yanela.rodriguez, yaile.caballero, yaima.filiberto, yumilka.fernandez, mabel.frias}@reduc.edu.cu
2 Departamento de Ciencias de la Computación, Universidad Central “Marta Abreu” de las Villas. Carretera a Camajuaní Km. 5 y ½, Santa Clara, Villa Clara, Cuba. rbellop@uclv.edu.cu
RESUMEN
El fenómeno hubness, es un aspecto del curso de la dimensionalidad descrito recientemente, que está relacionado con la disminución de la especificidad de las similitudes entre los puntos en un espacio de alta dimensión; lo cual va en detrimento de los métodos de aprendizaje automático. En este trabajo se evalúa el impacto del fenómeno hubness en la clasificación utilizando un enfoque basado en prototipos. El estudio experimental realizado demuestra que los métodos de generación y selección de prototipos estudiados ofrecen resultados comparables contra otros métodos basados en el enfoque kNN, encontrados en la literatura, los cuales son hubness-consientes y están diseñados específicamente para lidiar con este problema. Teniendo en cuenta los resultados alentadores de este estudio y las bondades de los métodos basados en prototipos es posible asegurar que la utilización de los mismos permitirá mejorar el desempeño de los sistemas que manejen datos de altas dimensiones y bajo la asunción de hubness.
Palabras clave: Hubness, selección de prototipos, generación de prototipos, relaciones de similitud, clasificación.
ABSTRACT
The hubness phenomenon, is an aspect of the curse of dimensionality recently described, that is related to the diminishment of specificity in similarities between points in a high-dimensional space; which is detrimental to the machine learning methods. This paper deals with evaluating the impact of hubness phenomenon on classification based on the nearest prototype. Experimental results show that the studied methods of generation and selection of prototypes offer comparable results against others methods based on kNN approach, found in the literature, which are hubness aware and are specifically designed to deal with this problem. Based on these encouraging results and the extensibility of methods based on prototypes, it is possible argue that it might be beneficial to use them in order to improve system performance in high dimensional data under the assumption of hubness.
Key words: Hubness, prototype selection, prototype generation, similarity relations, classification.
]]>
INTRODUCCIÓN
Los datos de alta dimensión plantean muchos desafíos intrínsecos para los problemas de reconocimiento de patrones como por ejemplo la maldición de la dimensionalidad que incluye la escasez, la redundancia, la concentración de las distancias, las estimaciones de densidad problemáticas, los vecinos más próximos menos significativos (Bolei, Khosla, Lapedriza, Oliva, & Torralba, 2015; Gao, Song, Nie, et al., 2015; Nguyen, Yosinski, & Clune, 2015; B. Yao, Khosla, & Fei-Fei, 2011; Zhou et al., 2015); así como la disminución de la especificidad de las similitudes entre los puntos en un espacio de alta dimensión (Choi, Pantofaru, & Savarese, 2013; Khosla, An, Lim, & Torralba, 2014; Wiskott, 2013). Específicamente, la complejidad de muchos algoritmos de minería de datos existentes es exponencial con respecto al número de dimensiones (Gao, Song, Liu, et al., 2015). Con el aumento de la dimensionalidad, los algoritmos existentes pronto se convierten en computacionalmente intratables y por lo tanto inaplicables en muchas aplicaciones reales (Gao, Song, Liu, et al., 2015).
Una alternativa para mitigar la maldición de la dimensionalidad, que implica la reducción del número de ejemplos a tener en cuenta, es la clasificación utilizando un enfoque basado en prototipos (Nearest Prototype, NP) (Bezdek & Kuncheva, 2001). La idea es determinar el valor del rasgo de decisión de un nuevo objeto analizando su similitud respecto a un conjunto de prototipos seleccionado o generado a partir del conjunto inicial de instancias. El propósito del enfoque NP es decrecer los costos de almacenamiento y procesamiento de las técnicas de aprendizaje basadas en instancias. Para reducir la cantidad de instancias, hay dos estrategias: Selección y Remplazo (Jin, Liu, & Hou, 2010). En el primer caso, se conserva una cantidad limitada de instancias del conjunto de datos original. En la segunda alternativa, se reemplaza el conjunto de datos originales por un número de prototipos que no necesariamente coincide con alguna instancia original.
El otro desafío que se deriva del aumento de la dimensionalidad de los datos y que está relacionado con la disminución de la especificidad de las similitudes entre los puntos en un espacio de alta dimensión es el conocido como: fenómeno hubness, y que se ha descrito recientemente. Este fenómeno consiste en la observación de que al aumentar la dimensionalidad de un conjunto de datos la distribución del número de veces que un punto de datos se encuentra entre los k vecinos más cercanos de otros puntos de datos se convierte en cada vez más sesgada a la derecha. Como consecuencia, los llamados “hubs” emergen, es decir, los puntos de datos que aparecen en las listas de los k vecinos más cercanos de otros puntos de datos con mucha mayor frecuencia que otros. (Low, Borgelt, Stober, & Nürnberger, 2013)
Los métodos de construcción y selección de prototipos no han sido estudiados bajo el supuesto de la presencia del fenómeno de hubness en los datos y su impacto en el aprendizaje de estos métodos. Por otro lado,
El enfoque más intuitivo de la clasificación de patrones está basado en el concepto de similitud (Duda, Hart, & Stork, 2001; Weinberger & Saul, 2009); obviamente patrones que son similares en algunos sentidos tienen asignada la misma clase.
El objetivo de este trabajo es analizar experimentalmente cómo se comportan los métodos de construcción y selección de prototipos basados en relaciones de similitud NP-BASIR-CLASS y NPBASIR SEL-CLASS ante conjuntos de entrenamiento que tengan “hubness”; comparándolos con métodos basados en kNN, enfoque más estudiado hasta el momento, pero que son “hubness-consientes”, es decir, que tienen en cuenta la presencia de los “malos hubs” y utilizan diferentes mecanismos para eliminarlos o mitigar sus efectos negativos en la clasificación.
El algoritmo NP-BASIR-CLASS (Fernández Hernández et al., 2015) es comparado en este propio articulo con 12 algoritmos mencionados en el artículo “Una taxonomía y un estudio experimental sobre la Generación de Prototipos para la Clasificación del vecino más cercano” (Triguero, Derrac, Garcia, & Herrera, 2012). Estos algoritmos son los que ofrecen mejores resultados según (Triguero et al., 2012). Los resultados experimentales muestran que el método NP-BASIR-CLASS tiene el mejor ranking y es estadísticamente superior a los otros en términos de precisión de la clasificación. El factor de reducción y el tiempo de ejecución alcanzado también fueron analizados y muestran resultados satisfactorios superiores en el caso del algoritmo NP-BASIR-CLASS (Fernández Hernández et al., 2015).
Por su parte, el algoritmo NPBASIR SEL-CLASS (Frias, Filiberto, Fernández, Caballero, & Bello, 2015) es comparado con los 4 algoritmos, mencionados en el artículo “Selección de Prototipos para la Clasificación del Vecino más Cercano: una Taxonomía y un Estudio Empírico” (Garcia, Derrac, Cano, & Herrera, 2012), que ofrecen mejores resultados. De acuerdo con los resultados presentados en este trabajo, la propuesta es estadísticamente significativa a los métodos de RMHC, SSMA, HMNEI RNG y ofrece resultados comparables con NPBASIR-CLASS en cuanto a la precisión de la clasificación. También se analiza el factor de reducción lograda, mostrando resultados satisfactorios superiores para el método NPBASIR SEL-CLASS (Frias et al., 2015).
]]>MATERIALES Y MÉTODOS
En la clasificación supervisada, la reducción de datos es una tarea importante, especialmente para clasificadores basados en instancias porque a través de ella los tiempos de ejecución se pueden reducir y obtener igual o mejor exactitud en la clasificación.
En (Fernández Hernández et al., 2015) y (Frias et al., 2015) se proponen dos métodos para la generación y selección de prototipos respectivamente que muestran buenos resultados. Estos trabajos proponen utilizar el método NPBASIR-CLASS y NPBASIR SEL-CLASS para construir y seleccionar los prototipos respectivamente para problemas de clasificación empleando los conceptos de Computación Granular (Y. Yao, 2000) basada en NPBASIR (Bello-García, García-Lorenzo, & Bello, 2012).
La granulación de un universo se realiza usando una relación de similitud que genera clases de similitud de objetos en el universo, y para cada clase de similitud se construye/selecciona un prototipo. Para construir la relación de similitud se utiliza el método propuesto en (Filiberto, Caballero, Larrua, & Bello, 2010).
Método de construcción de prototipos
El método propuesto en (Fernández Hernández et al., 2015) es un proceso iterativo en el cual los prototipos son construidos de las clases de similitud de objetos en el universo: una clase de similitud se construye usando la relación de similitud R([Oi]R) y para esta clase de similitud se construye un prototipo. Cuando un objeto es incluido en una clase de similitud, es marcado como usado y no se tiene en cuenta para construir otra clase de similitud. Se utiliza un arreglo de n componentes, llamado Usado[] donde en Usado[i] tiene valor 1 si el objeto fue utilizado o 2 en otro caso.
Este algoritmo utiliza un conjunto de instancias X={X1, X2, ....., Xn} cada una de las cuales es descrita por un vector de a atributos descriptivos y pertenece a una de k clases w = {w1, w2, ...wk} y una relación de similitud R. La relación de similitud R es construida acorde al método propuesto en (Filiberto, Bello, Caballero, & Larrua, 2010; Filiberto, Caballero, et al., 2010); que está basado en encontrar la relación que maximice la calidad de la medida de similitud. En este caso, la relación R genera una granulación considerando los a atributos descriptivos, tan similares como posibles para la granulación acorde a las clases.
En el paso P4 la función f denota un operador de agregación, por ejemplo: Si el valor en Vi es real, se puede utilizar el promedio; si son discretos, el valor más común. El propósito es construir un prototipo o centróide para un conjunto de objetos similares.
El conjunto de prototipos ProtoSet es la salida del algoritmo NPBASIR-C. Este conjunto es usado por el clasificador para clasificar nuevas instancias:
]]> En el paso 3 la clase se calcula de igual forma que en k-vecinos más similares (k-SN) para la clasificación.Método para la selección de prototipos
El método propuesto en (Frias et al., 2015) es un proceso iterativo en el cual los prototipos son seleccionados de las clases de similitud de objetos en el universo: una clase de similitud es construida usando la relación de similitud R([Oi]R) y un prototipo es seleccionado para esta clase de similitud.
El conjunto de prototipos ProtoSet es la salida del algoritmo NPBASIR SEL-CLASS. Este conjunto es usado por el clasificador para clasificar nuevas instancias:
En el paso 3 la clase se calcula de igual forma que en k-vecinos más similares (k-SN) para la clasificación.
Clasificación hubness-consiente
La clasificación hubness consiente está apoyada en el modelo de aprendizaje basado en la ocurrencia de los vecinos más cercanos en los datos de entrenamiento.
Luego, ![]() sea el conjunto de entrenamiento de puntos de datos etiquetados dibujado i.i.d. a partir de una distribución conjunta
sea el conjunto de entrenamiento de puntos de datos etiquetados dibujado i.i.d. a partir de una distribución conjunta ![]() sobre X x Y, donde X es el espacio de rasgos y Y el espacio finito de etiquetas, |Y| = C.
sobre X x Y, donde X es el espacio de rasgos y Y el espacio finito de etiquetas, |Y| = C.
Denotamos por ![]() a los k-vecinos más cercanos de xi. Para todo
a los k-vecinos más cercanos de xi. Para todo ![]() es un vecino de xi y viceversa, xi es vecino de todo
es un vecino de xi y viceversa, xi es vecino de todo ![]() . Una ocurrencia de un elemento en algunos
. Una ocurrencia de un elemento en algunos ![]() se conoce como una k-ocurrencia. El número de k-ocurrencias de un punto x se denota por Nk(x). Una k-ocurrencia se considera buena si la etiqueta de su vecino coincide con la etiqueta del punto de interés, por ejemplo
se conoce como una k-ocurrencia. El número de k-ocurrencias de un punto x se denota por Nk(x). Una k-ocurrencia se considera buena si la etiqueta de su vecino coincide con la etiqueta del punto de interés, por ejemplo ![]() es una buena ocurrencia de xij si yij = yi. Del mismo modo, los desajustes de etiquetas corresponden a las malas ocurrencias de puntos vecinos. El cómputo total de ocurrencias consiste en una suma de las buenas y malas ocurrencias,
es una buena ocurrencia de xij si yij = yi. Del mismo modo, los desajustes de etiquetas corresponden a las malas ocurrencias de puntos vecinos. El cómputo total de ocurrencias consiste en una suma de las buenas y malas ocurrencias, ![]() representa las buenas ocurrencias y las malas respectivamente. El conteo de las buenas y malas ocurrencias es también conocido como los buenos o malos hubness de un punto en particular. También es posible considerar la ocurrencia de la clase condicional que se denota como
representa las buenas ocurrencias y las malas respectivamente. El conteo de las buenas y malas ocurrencias es también conocido como los buenos o malos hubness de un punto en particular. También es posible considerar la ocurrencia de la clase condicional que se denota como ![]() y representa el número de k-ocurrencias de xi en el vecindario de ejemplos que pertenecen a la clase c.
y representa el número de k-ocurrencias de xi en el vecindario de ejemplos que pertenecen a la clase c.
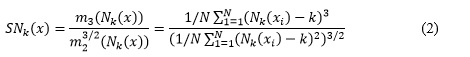
Formalmente, se dice que los hubs son puntos ![]() tales que
tales que ![]() En otras palabras, sus frecuencias de ocurrencia exceden la media (k) por más del doble de la desviación estándar. Finalmente se denota el conjunto de todos los hubs en T por
En otras palabras, sus frecuencias de ocurrencia exceden la media (k) por más del doble de la desviación estándar. Finalmente se denota el conjunto de todos los hubs en T por ![]()
Con el objetivo de aliviar la negativa influencia de los malos hubs en los datos y de obtener una robusta clasificación del k-vecino más cercano bajo el supuesto de hubness, recientemente se han propuesto varios métodos kNN-hubness-consientes: hubness-weighted kNN (hw-kNN) (Radovanović, Nanopoulos, & Ivanović, 2009), hubness-fuzzy kNN (h-FNN) (Tomašev, Radovanović, Mladenić, & Ivanović, 2014), hubness-information kNN (HIKNN) (Tomašev & Mladenić, 2012) y Naive Hubness-Bayesian kNN (NHBNN) (Tomasev, Radovanović, Mladenić, & Ivanović, 2011).
hw-kNN: Este algoritmo de ponderación es la forma más sencilla de reducir la influencia de malos hubs donde simplemente se le asignan pesos de voto inferiores. El voto de cada vecino se pondera por ![]() , donde
, donde ![]() es la mala puntuación hubness estandarizada del vecino. Todos los vecinos votan por su propio sello (a diferencia de los algoritmos considerados más adelante), lo que podría resultar perjudicial en algunas ocasiones.
es la mala puntuación hubness estandarizada del vecino. Todos los vecinos votan por su propio sello (a diferencia de los algoritmos considerados más adelante), lo que podría resultar perjudicial en algunas ocasiones.
![]() (clase hubness relativa) puede interpretarse como la fuzificación del evento de que xi haya ocurrido como un vecino. Por esta razón, h-FNN integra la clase hubness en framework difuso de k-vecinos más cercanos de votación (Keller, Gray, & Givens, 1985). Esto significa que las probabilidades de la etiqueta en el punto de interés se calculan como se expresa en la Ecuación 3:
(clase hubness relativa) puede interpretarse como la fuzificación del evento de que xi haya ocurrido como un vecino. Por esta razón, h-FNN integra la clase hubness en framework difuso de k-vecinos más cercanos de votación (Keller, Gray, & Givens, 1985). Esto significa que las probabilidades de la etiqueta en el punto de interés se calculan como se expresa en la Ecuación 3:
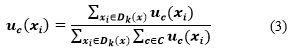
NHBNN: Cada k-ocurrencia puede ser tratada como un evento aleatorio. Lo que NHBNN hace esencialmente es que realiza una inferencia bayesiana (Naive-Bayesian inference) para estos k eventos tal como se expresa en la Ecuación 4.
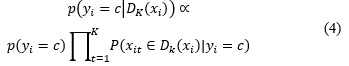
Aun cuando las k-ocurrencias están altamente correlacionados, NHBNN todavía ofrece algunas mejoras sobre el kNN básico.
]]> HIKNN: Recientemente, la clase hubness también ha sido explorada con un enfoque de la teoría de la información aplicada a la clasificación de los k- vecinos más cercanos. Las ocurrencias raras tienen mayor auto-información (Ecuación 5) y son favorecidos por el algoritmo. Los hubs, por el contrario, se encuentran más cerca de los centros de grupos y llevan menos información local relevante para la consulta en particular.
La auto-información de la ocurrencia se utiliza para definir los factores de relevancia absolutos y relativos como se expresa en la Ecuación 6:
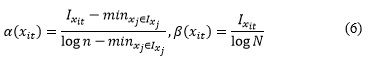
La votación difusa final combina la información contenida en la etiqueta del vecino con la información contenida en su perfil de ocurrencia. El factor de relevancia relativa se utiliza para ponderar las dos fuentes de información. Esto se muestra en la Ecuación 7:
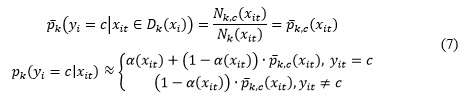
La asignación de la clase final está dada por la suma ponderada de estos votos difusos, como se muestra en la Ecuación 8. El factor de ponderación ![]() produce en su mayoría mejoras poco significativas y puede no tomarse en cuenta en la práctica.
produce en su mayoría mejoras poco significativas y puede no tomarse en cuenta en la práctica.
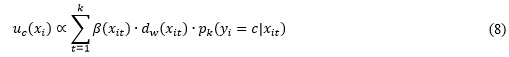
NHBNN, HIKNN y h-FNN utilizan estimaciones de frecuencia de la ocurrencia de la clase condicional para realizar una clasificación basada en los modelos de los vecinos más cercanos. En los datos de alta dimensión, esto podría ser un poco mejor que la votación por la etiqueta.
]]> RESULTADOS Y DISCUSIÓN
Para calcular la exactitud de los métodos se utilizó la métrica Accuracy, típicamente usada en estos casos por su simplicidad y aplicación exitosa y que se muestra en la expresión (9) dada en (Witten & Frank, 2005):
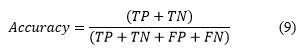
Donde TP son los verdaderos positivos, TN los verdaderos negativos, FP son los falsos positivos, y FN son los falsos negativos.
Para el análisis estadístico de los resultados se utilizaron las técnicas de prueba de hipótesis (García & Herrera, 2009). Para comparaciones múltiples, se utilizan las pruebas de Friedman y de Iman-Davenport para detectar diferencias estadísticamente significativas entre un grupo de resultados. Se emplea además la prueba de Holm con el fin de encontrar los algoritmos significativamente superiores (Alcalá et al., 2010). Estas pruebas son sugeridas en los estudios presentados en (Demšar, 2006; García, Fernández, Luengo, & Herrera, 2010), donde se afirma que el uso de estas pruebas es muy recomendable para la validación de resultados en el campo del aprendizaje automatizado.
La exactitud de la clasificación dada en la Tabla 2 para los métodos kNN, hw-kNN, h-FNN, NHBNN y HIKNN ha sido reportada en trabajos anteriores (Tomašev & Mladenić, 2012, 2014) y servirá como un punto de partida para su posterior análisis. Todos los algoritmos hubness-conscientes se probaron bajo sus configuraciones de parámetros por defecto, de acuerdo a lo especificado en sus respectivos artículos.
Para medir el desequilibrio de clases en un conjunto de datos concreto, se observan dos cantidades: p(cM), que es el tamaño relativo de la clase mayoritaria y el desequilibrio relativo de la distribución de las etiquetas (RImb), que se define como la desviación estándar normalizada de la probabilidad de la clase respecto al valor absoluto medio homogéneo de 1 / c para cada clase. En otras palabras, según la Ecuación 10:

Los malos hubs no son causados directamente por el desbalance de clases, pero si son resultado de la interrelación de varios factores.
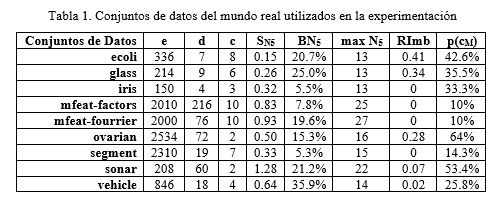
En la Tabla 1 se resumen las características de los conjuntos de datos del mundo real utilizados en la experimentación (Conjuntos de datos del Repositorio de Aprendizaje Automático de la UCI). Cada conjunto de datos esta descrito por las siguientes propiedades: número de ejemplos (e), número de rasgos (d), número de clases (c), asimetría de la distribución de la frecuencia de ocurrencia de los k-vecinos (SN5), porciento de las malas 5-ocurrencias (BN5), el grado del punto hub más grande (max N5), desequilibrio relativo de la distribución de las etiquetas (RImb) y el tamaño de la clase mayoritaria (p(cM)).
]]>
En la Tabla 2 se muestra la exactitud promedio de la clasificación obtenida con los métodos: kNN, hubness-weighted kNN (hw-kNN), hubness-based fuzzy nearest neighbor (h-FNN), naive hubness-Bayesian k-NN (NHBNN), hubness information k-NN (HIKNN), construcción de prototipos NPBASIR-CLASS y selección de prototipos NPBASIR SEL-CLASS. Todos los experimentos fueron desarrollados para k=5.
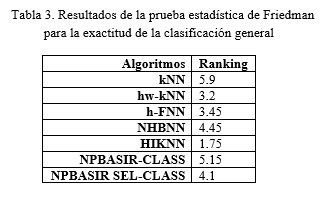
La Tabla 3 muestra el ranking obtenido por la prueba de Friedman. En este caso el p-value asociado a dicha prueba es de 7.95, el cual no es lo suficientemente bajo como para rechazar la hipótesis de equivalencia, por lo que podemos concluir que no existen diferencias significativas entre los algoritmos comparados.
La prueba de Holm (Tabla 4), respecto a la exactitud general de la clasificación haciendo un todo contra todos rechaza todas las hipótesis con valor p ≤ 0.002632: solo en el caso HIKNN vs. NPBASIR-CLASS, HIKNN es ligeramente superior a NPBASIR-CLASS. Para el resto de las combinaciones la hipótesis nula no se rechaza, esto es equivalente a decir que no hay diferencias significativas entre sus comportamientos y por lo tanto se puede concluir que son igual de eficaces. Para la Tabla 4 solo se muestran las filas donde aparece uno de los métodos basados en prototipos por ser los de interés para este estudio.
Este trabajo es el primer intento de relacionar el fenómeno de hubness, un aspecto del curso de la dimensionalidad, con los métodos de aprendizaje automático basados en prototipos. Estos métodos permiten obtener un conjunto de entrenamiento representativo con menor tamaño comparado con el original y con similar o incluso mayor exactitud en la clasificación de los nuevos datos recibidos.
El estudio experimental realizado demuestra que los métodos de generación y selección de prototipos estudiados ofrecen resultados comparables con los obtenidos en la literatura con los métodos basados en el enfoque kNN, los cuales son hubness-consientes y están diseñados específicamente para lidiar con este problema.
Teniendo en cuenta los resultados alentadores de este estudio y las bondades de los métodos basados en prototipos es posible asegurar que la utilización de los mismos permitirá mejorar el desempeño de los sistemas que manejen datos altas dimensiones y bajo la asunción de hubness.
CONCLUSIONES
]]> El fenómeno de hubness en los datos es un desafío importante del curso de la dimensionalidad pues se conoce por ser perjudicial para el aprendizaje automatizado y para las tareas de minería de datos. Los resultados de este trabajo sugieren que los acercamientos probados exhiben niveles prometedores de robustez y tolerancia ante el problema tratado. Los métodos estudiados de selección y construcción de prototipos NPBASIR SEL-CLASS y NPBASIR-CLASS ofrecen resultados comparables con los obtenidos con los métodos HIKNN, h-FNN y hw-kNN y NHBNN, los cuales son hubness-consientes y están diseñados específicamente para lidiar con este problema.El diseño de estos métodos debe extenderse para reducir el impacto negativo de los malos hubs en los datos. Una manera de hacer esto sería emplear los métodos basados en prototipos combinándolos con los acercamientos hubness-conscientes existentes. En trabajos futuros se intentará probar que, si se modifican los métodos de construcción y selección de prototipos basados en relaciones de similitud para el caso de la presencia de “hubness”, identificando los “malos hubs” y no teniéndolos en cuenta a la hora de seleccionar y construir los prototipos, se obtendrán resultados que superen a los encontrados en la bibliografía hasta el momento. Además, se pretende extender el enfoque anterior para dar tratamiento también a los “anti-hubness”.
REFERENCIAS BIBLIOGRÁFICAS
Alcalá, J., Fernández, A., Luengo, J., Derrac, J., García, S., Sánchez, L., & Herrera, F. (2010). Keel data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. Journal of Multiple-Valued Logic and Soft Computing, 17(255-287), 11.
Bello-García, M., García-Lorenzo, M. M., & Bello, R. (2012). A method for building prototypes in the nearest prototype approach based on similarity relations for problems of function approximation Advances in Artificial Intelligence (pp. 39-50): Springer.
Bezdek, J. C., & Kuncheva, L. I. (2001). Nearest prototype classifier designs: An experimental study. International Journal of Intelligent Systems, 16(12), 1445-1473.
Bolei, Z., Khosla, A., Lapedriza, A., Oliva, A., & Torralba, A. (2015). Object detectors emerge in Deep Scene CNNs.
]]> Choi, W., Pantofaru, C., & Savarese, S. (2013). A general framework for tracking multiple people from a moving camera. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 35(7), 1577-1591.Demšar, J. (2006). Statistical comparisons of classifiers over multiple data sets. The Journal of Machine Learning Research, 7, 1-30.
Duda, R., Hart, P., & Stork, D. (2001). Pattern classification. International Journal of Computational Intelligence and Applications, 1, 335-339.
Fernández Hernández, Yumilka, B., Bello, R., Filiberto, Y., Frías, M., Coello Blanco, L., & Caballero, Y. (2015). An Approach for Prototype Generation based on Similarity Relations for Problems of Classification. Computación y Sistemas, 19(1), 109-118.
Filiberto, Y., Bello, R., Caballero, Y., & Larrua, R. (2010). Using PSO and RST to predict the resistant capacity of connections in composite structures Nature Inspired Cooperative Strategies for Optimization (NICSO 2010) (pp. 359-370): Springer.
Filiberto, Y., Caballero, Y., Larrua, R., & Bello, R. (2010). A method to build similarity relations into extended rough set theory. Paper presented at the Intelligent Systems Design and Applications (ISDA), 2010 10th International Conference on.
Frias, M., Filiberto, Y., Fernández, Y., Caballero, Y., & Bello, R. (2015). Prototypes selection based on similarity relations for classification problems Paper presented at the Engineering Applications - International Congress on Engineering (WEA), Bogota
Gao, L., Song, J., Liu, X., Shao, J., Liu, J., & Shao, J. (2015). Learning in high-dimensional multimedia data: the state of the art. Multimedia Systems, 1-11.
Gao, L., Song, J., Nie, F., Yan, Y., Sebe, N., & Tao Shen, H. (2015). Optimal Graph Learning with Partial Tags and Multiple Features for Image and Video Annotation. Paper presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
Garcia, S., Derrac, J., Cano, J. R., & Herrera, F. (2012). Prototype selection for nearest neighbor classification: Taxonomy and empirical study. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 34(3), 417-435.
García, S., Fernández, A., Luengo, J., & Herrera, F. (2010). Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Information Sciences, 180(10), 2044-2064.
García, S., & Herrera, F. (2009). Evolutionary undersampling for classification with imbalanced datasets: Proposals and taxonomy. Evolutionary computation, 17(3), 275-306.
Jin, X.-B., Liu, C.-L., & Hou, X. (2010). Regularized margin-based conditional log-likelihood loss for prototype learning. Pattern Recognition, 43(7), 2428-2438.
Keller, J. M., Gray, M. R., & Givens, J. A. (1985). A fuzzy k-nearest neighbor algorithm. Systems, Man and Cybernetics, IEEE Transactions on(4), 580-585.
]]>Khosla, A., An, B., Lim, J. J., & Torralba, A. (2014). Looking beyond the visible scene. Paper presented at the Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on.
Low, T., Borgelt, C., Stober, S., & Nürnberger, A. (2013). The Hubness Phenomenon: Fact or Artifact? Towards Advanced Data Analysis by Combining Soft Computing and Statistics (pp. 267-278): Springer.
Nguyen, A., Yosinski, J., & Clune, J. (2015). Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. Paper presented at the Computer Vision and Pattern Recognition (CVPR), 2015 IEEE Conference on.
Radovanović, M., Nanopoulos, A., & Ivanović, M. (2009). Nearest neighbors in high-dimensional data: The emergence and influence of hubs. Paper presented at the Proceedings of the 26th Annual International Conference on Machine Learning.
Tomašev, N., & Mladenić, D. (2012). Nearest neighbor voting in high dimensional data: Learning from past occurrences. Computer Science and Information Systems, 9, 691-712.
Tomašev, N., & Mladenić, D. (2014). Hubness-aware shared neighbor distances for high-dimensional k-nearest neighbor classification. Knowledge and information systems, 39(1), 89-122.
]]>Tomasev, N., Radovanović, M., Mladenić, D., & Ivanović, M. (2011). A probabilistic approach to nearest-neighbor classification: naive hubness bayesian kNN. Paper presented at the Proceedings of the 20th ACM international conference on Information and knowledge management.
Tomašev, N., Radovanović, M., Mladenić, D., & Ivanović, M. (2014). Hubness-based fuzzy measures for high-dimensional k-nearest neighbor classification. International Journal of Machine Learning and Cybernetics, 5(3), 445-458.
Triguero, I., Derrac, J., Garcia, S., & Herrera, F. (2012). A taxonomy and experimental study on prototype generation for nearest neighbor classification. Systems, Man, and Cybernetics, Part C: Applications and Reviews, IEEE Transactions on, 42(1), 86-100.
Weinberger, K. Q., & Saul, L. K. (2009). Distance metric learning for large margin nearest neighbor classification. The Journal of Machine Learning Research, 10, 207-244.
Wiskott, L. (2013). How to solve classification and regression problems on high-dimensional data with a supervised extension of slow feature analysis. The Journal of Machine Learning Research, 14(1), 3683-3719.
Witten, I. H., & Frank, E. (2005). Data Mining: Practical machine learning tools and techniques: Morgan Kaufmann.
Yao, B., Khosla, A., & Fei-Fei, L. (2011). Classifying actions and measuring action similarity by modeling the mutual context of objects and human poses. a) A, 1(D2), D3.
Yao, Y. (2000). Granular computing: basic issues and possible solutions. Paper presented at the Proceedings of the 5th joint conference on information sciences.
Zhou, X., Chen, L., Zhang, Y., Cao, L., Huang, G., & Wang, C. (2015). Online video recommendation in sharing community. Paper presented at the Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data.
Recibido: 23/06/2016
Aceptado: 23/01/2017
{kind=link}