El riesgo de seguridad de la información en gestores de bases de datos basado en números difusos trapezoidales
The security risk of information in database managers based on trapezoidal fuzzy numbers
Yasser Azán-Basallo1*, Natalia Martínez Sánchez2, Vivian Estrada Senti3
1Centro Telemática, Facultad 2, Universidad de las Ciencias Informáticas. Carretera a San Antonio de los Baños km 2½, Reparto. Torrens. Boyeros, La Habana. CUBA. Correo electrónico: yazan@uci.cu
2Vicerrectoría de Formación, Universidad de las Ciencias Informáticas. Carretera a San Antonio de los Baños km 2½, Reparto. Torrens. Boyeros, La Habana. CUBA. Correo electrónico: natalia@uci.cu ]]>
3Centro Internacional del Postgrado, Universidad de las Ciencias Informáticas. Carretera a San Antonio de los Baños km 2½, Reparto. Torrens. Boyeros, La Habana. CUBA. Correo electrónico: vivian@uci.cu
*Autor para la correspondencia: yazan@uci.cu
RESUMEN
En este trabajo se plantea una solución para evaluar el riesgo de la seguridad de la información para los gestores de bases de datos. Teniendo como premisa de entrada, el riesgo cualitativo de cada parámetro de la lista de chequeo de seguridad. Para lograr este objetivo se propone la utilización de números difusos trapezoidales basado en el área. Se realiza una revisión de la literatura de nuevas funciones de semejanza, las cuales utilizan los números difusos, para argumentar la selección del modelo escogido para resolver el objetivo en este trabajo. Se muestra un caso de estudio para explicar el funcionamiento del modelo propuesto e indicar la viabilidad del mismo para manejar los términos lingüísticos de las premisas de entrada y lograr la determinación de la evaluación del riesgo de seguridad de la información igualmente de una manera cualitativa. Además, mostrar los resultados obtenidos con la propuesta a través de una herramienta desarrollada que permitió automatizar el modelo propuesto.
Palabras clave: auditoría, evaluación, lógica difusa, números difusos trapezoidales, riesgo
ABSTRACT
In this paper is proposed one solution for assessing the information security risk for database managers. It´s based on the qualitative risk of each parameter in the security checklist. To achieve this objective is proposing the use of trapezoidal fuzzy numbers based on area. A review of the literature of new similarity functions, which use the fuzzy numbers, is made to argue the selection of the chosen model to solve the objective in this work. A case study is presented to explain the operation of the proposed model and indicate its feasibility to handle the linguistic terms of the input premises and to achieve the determination of the information security risk assessment in a qualitative way. Also show the results obtained with the proposal through a tool developed that allowed to automate the proposed model.
]]> Key words: audit, evaluation, diffuse logic, diffuse trapezoidal numbers, risk
INTRODUCCIÓN
En una anterior publicación se ha abordado la evaluación del riesgo de la seguridad de la información en los sistemas gestores de bases de datos (SGBD) utilizando el razonamiento basado en casos (Azán , Y. B. y otros, 2014). En esta se proporciona una evaluación del riesgo de forma cualitativa. El cual se realizó a partir de la obtención del riesgo cuantitativo de cada parámetro de la lista de chequeo de seguridad (Broder, J. F. y Tucker, G., 2011) que utilizan los expertos en auditoría de seguridad informática para los SGBD. También se publicó otro trabajo con el mismo objetivo pero utilizando la lógica difusa (Azán, Y. B., Martínez, N. S., y Estrada, S. V., 2015). Estos trabajos muestran la viabilidad de ambas técnicas para la evaluación del riesgo de la seguridad de la información en los SGBD teniendo como premisas o entradas, valores numéricos. Sin embargo, no se ha encontrado una solución para llevar a cabo la evaluación del riesgo de seguridad de la información a partir de los valores cualitativos: Alto, Medio o Bajo y devolver estos mismos valores como resultado final.
Por tal motivo se trazó como objetivo, proponer la evaluación del riesgo de la seguridad de la información para los SGBD teniendo como premisa de entrada, el riesgo cualitativo de cada parámetro de la lista de chequeo de seguridad.
Revisión de la literatura
Se han desarrollado varias investigaciones con el objetivo de realizar la evaluación de riesgo a partir de valores cualitativos, aunque no afines a la seguridad de la información, utilizando la lógica difusa (Abbasianjahromi, H. y Rajaie, H., 2013; Patra, K. y Mondal, S. K., 2015; Schmucke, K. J., 1984; Wang, Y.-M. y Elhag, T. M., 2006; Xu, Z., Shang, S., Qian, W., y Shu, W., 2010) . Se encuentran nuevas propuestas de funciones de similitud para números difusos. Para el autor de esta investigación resultan de interés los trabajos de Patra y Mondal (2015) y de Vicente, Mateos y Jiménez (2013) por los resultados evidenciados de superioridad de su propuesta ante otras existentes como se evidencia en el trabajo de los mismos para ser utilizado en esta investigación.
Además se encontró un trabajo el cual permite tomar decisiones a partir de factores de riesgo de varios proyectos de la construcción de Abbasianjahromi y Rajaie (2013) utilizando un modelo híbrido del RBC difuso con factores de riesgos cualitativos como rasgos predictores, para decidir cuál proyecto ejecutar. Este trabajo también puede ser otro acercamiento al problema planteado por esta investigación.
En esta investigación se decide utilizar la propuesta de Vicente, Mateos y Jiménez (2013) por la superioridad demostrada en el trabajo citado con los resultados obtenidas en las comparaciones realizadas por estos autores.
]]>MATERIALES Y MÉTODOS
Se necesita para aplicar la función de semejanza de Vicente, Mateos y Jiménez (2013) primeramente determinar el número difuso del rasgo objetivo. Esto se realizó a partir de la propuesta publicada en Patra y Mondal (2015) en la cual se sustituye la operación aritmética (impacto![]() Probabilidad de ocurrencia) por la variable riesgo local (RL) de cada parámetro de la lista de chequeo. La causa de esta modificación se debe a que se tiene como premisa el valor del RL, sin la necesidad de esta operación matemática, por lo que se simplifica el proceso de cómputo. Se incorpora una nueva variable (el peso) para ajustar el valor del RL, quedando como aparece en la ecuación 1:
Probabilidad de ocurrencia) por la variable riesgo local (RL) de cada parámetro de la lista de chequeo. La causa de esta modificación se debe a que se tiene como premisa el valor del RL, sin la necesidad de esta operación matemática, por lo que se simplifica el proceso de cómputo. Se incorpora una nueva variable (el peso) para ajustar el valor del RL, quedando como aparece en la ecuación 1:
![]()
En la anterior ecuación 1, la variable R representa el valor del número difuso del rasgo objetivo, que es a su vez el riesgo del servidor tal que R= (t1, t2, t3, t4; w). Son números reales t1, t2, t3, t4 y w tal que: 0 ≤ t1 ≤ t2 ≤ t3 ≤ t4 ≤ 1, 0 ≤ w ≤ 1. La variable w representa la altura del trapecio.
Es importante utilizar en esta investigación el peso como medida de diferenciación entre los parámetros que componen la lista de chequeo de seguridad. Esto se debe a la existencia de parámetros que pueden tener igual nivel de RL, pero con contrastes más determinantes, en unos más que en otros, para la evaluación del riesgo del rasgo objetivo. Por tanto, la utilización del peso contribuye a la diferenciación y en la precisión de la estimación del valor de rasgo objetivo. El peso se determinó a través de encuestas aplicadas a los especialistas del Departamento de Seguridad Informática de la empresa ETECSA. El valor del peso está definido en el intervalo [0,1].
El número difuso generalizado R, es un subconjunto borroso de la línea real ![]() , cuya función de pertenencia
, cuya función de pertenencia ![]() cumple las siguientes condiciones (Chen, S.-J. y Chen, S.-M., 2003):
cumple las siguientes condiciones (Chen, S.-J. y Chen, S.-M., 2003):

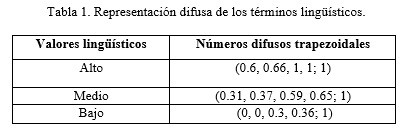
En la figura 1 se puede observar la representación gráfica de los números difusos trapezoidales generalizados de los valores lingüísticos creada con el MATLAB 7.6.0.
La función de pertenencia o miembro (![]() :
:![]()
![]() [0,1] ) trapezoidal generalizado es de la siguiente forma:
[0,1] ) trapezoidal generalizado es de la siguiente forma:
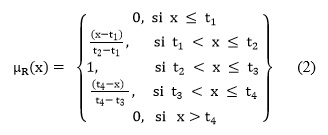
Función de semejanza
Para determinar el valor cualitativo del riesgo del rasgo objetivo, se utiliza una función de semejanza que permite comparar el riesgo del número difuso calculado por la ecuación (1) con los números difusos que están asociados a los valores lingüísticos de salida como se muestra en la tabla 1. A partir del valor de semejanza, tomar como resultado final el de mayor semejanza.
La propuesta general de función de semejanza seleccionada es la publicada por (Vicente, E. y otros, 2013):
Si ![]()
![]()
En otro caso:
![]()
Donde la variable RN es el riesgo expresado en un número difuso trapezoidal del nuevo caso de la auditoría de seguridad informática, la cual se desea diagnosticar o evaluar. La variable RO se corresponde a un número difuso de la tabla 1. El valor 1 representa la similitud exacta entre los casos, α+β<1. Las variables α y β = 1/3 para que se puedan comparar los resultados con el análisis dispuesto en Vicente, Mateos y Jiménez (2013).
El µ es la función miembro del número difuso R. Ecuacion 5
]]>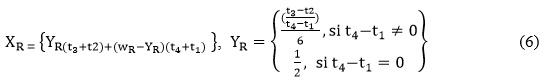
Donde la variable RN es el riesgo expresado en un número difuso trapezoidal de la auditoría de seguridad informática, la cual se desea diagnosticar. La variable RO se corresponde al número difuso de la variable lingüística con la cual se quiere determinar el nivel de semejanza.
Caso de estudio
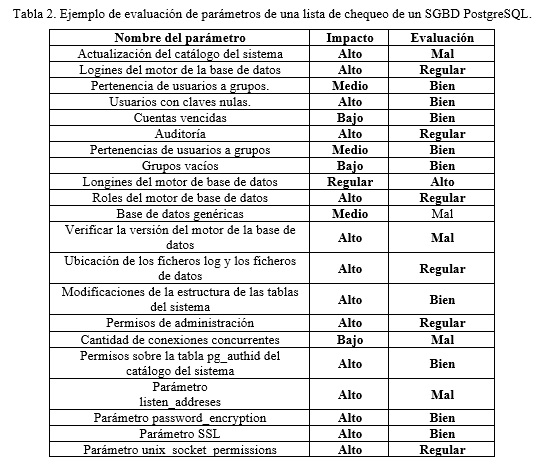
Para un mejor entendimiento de la propuesta de solución, los autores han preparado un ejemplo en un escenario real. En esta sección se ofrece en la tabla 2, un posible resultado de una auditoría a un SGBD en PostgreSQL en la cual va a tener los parámetros que fueron evaluados y el impacto correspondiente a cada uno de ellos.
Cuando se aplica la ecuación (1), se obtiene el número difuso de la evaluación del riesgo para esta auditoría R = (0.701697, 0.753032,0.884006, 0.930051,1).
El segundo paso, para obtener el diagnóstico de la evaluación de la auditoría, se emplea la ecuación (3). Obteniendo el nivel desemejanza entre la variable R con respecto a los números difusos de la tabla 1 los cuales representan los términos lingüísticos. El resultado de aplicar esta ecuación se muestra en la tabla 3, la cual muestra que el resultado del riesgo de la seguridad de la información para el SGBD PostgreSQL es de Alto.
]]>

RESULTADOS Y DISCUSIÓN
Se desarrolló una solución informática a partir de la solución propuesta (Azán , Y. B. y otros, 2014) como instancia al modelo propuesto en este trabajo. La aplicación SASGBD como se le nombró, está creada a partir de su desarrollo anterior, por tanto, tiene las mismas facultades de diagnosticar los SGBD PostgreSQL, MySQL, Microsoft SQL Server y Oracle y además de mantener las mismas funcionalidades descritas en el anterior trabajo.
La misma es capaz de proponer el resultado del diagnóstico. El auditor es quien estima el resultado final de la auditoría de mantener la evaluación o de cambiarla.
Estudio comparativo
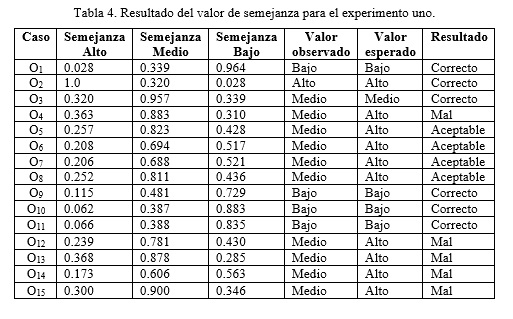
Se realizó un estudio comparativo para medir la exactitud de la propuesta de solución a través de casos de estudio proporcionados por los especialistas del Departamento de Seguridad Informática de la empresa ETECSA. Para evidenciar los resultados de la medición a través del SASGBD, los resultados fueron reflejados en la tabla 4. La columna R es de la palabra resultado, la variable C de correcto, M de Mal y A de aceptable.
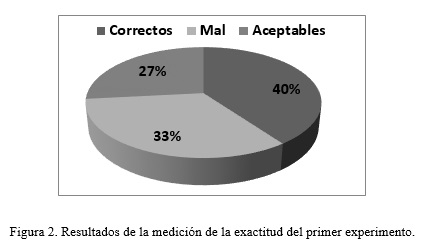
Los resultados de la medición de la exactitud del primer experimento mostrado en la figura 2 son que: de 15 casos, 6 fueron evaluados correctamente, 5 de mal y 4 de modo aceptable. Los casos de estudio valorados como correctos son aquellos donde coincide el valor esperado con el observado. Los aceptables son casos aquellos donde no coinciden los valores, pero el valor del observado es un resultado admisible. Los valorados de Mal son aquellos que los valores no coinciden y no son aceptados.
]]>CONCLUSIONES
La investigación realizada demuestra la viabilidad de realizar la evaluación del riesgo de seguridad de la información en gestores de bases de datos basado en la medida de la similitud de números difusos trapezoidales basado en el área.
Se evidencia a través de la propuesta de este trabajo, la oportunidad de manejar los términos lingüísticos que se ofrecen como premisa de entrada y de salida para la evaluación del riesgo de la seguridad de la información y mejorar la exactitud de la solución con el manejo de la ambigüedad existente en este proceso.
REFERENCIAS BIBLIOGRÁFICAS
ABBASIANJAHROMI, H. Y RAJAIE, H. (2013). Application of fuzzy CBR and MODM approaches in the project portfolio selection in construction companies. Iranian Journal of Science and Technology. Transactions of Civil Engineering, 37, 143-155. Extraído desde 20/02/2014, de http://www.sid.ir/En/VEWSSID/J_pdf/8542013C101.pdf.
]]>BRODER, J. F. Y TUCKER, G. (2011). Risk analysis and the security survey Extraído desde 12/12/2013, de http://www.google.com.cu/books?hl=es&lr=&id=fLmgIGT18jIC&oi=fnd&pg=PP1&dq=risk+assessment%2Bformula%2Bsecurity&ots=q1K-pmlGAY&sig=lwkAVW1G2jr7wkBjlR4dQftaQ2k&redir_esc=y#v=onepage&q=risk%20assessment%2Bformula%2Bsecurity&f=false.
]]>WANG, Y.-M. Y ELHAG, T. M. (2006). Fuzzy TOPSIS method based on alpha level sets with an application to bridge risk assessment. Expert Systems with Applications, 31, 309-319.
Recibido: 11/02/2017 ]]> Aceptado: 23/09/2017
]]>