
La medición del estado global de salud y la identificación de las relaciones entre el estado de salud de la población y sus determinantes puede conllevar el cumplimiento de un conjunto de propósitos generales, o parte de ellos, que pueden desglosarse en propósitos específicos que se exponen en el trabajo. Los propósitos específicos, a su vez, se pueden cumplimentar a través de procedimientos de análisis que, a los efectos de este artículo, se clasifican en siete categorías según su empleo habitual con otras finalidades: los utilizados en la vigilancia epidemiológica, los empleados en el análisis de series de tiempo, los usados en la identificación de clusters en espacio y/o tiempo, los empleados en el análisis de la economía y derivados, los sustentados en índices empleados con distintos fines, los procedimientos generales de la estadística y la epidemiología y otros procedimientos. En el trabajo se exponen 19 procedimientos agrupados en las cinco primeras categorías. Para cada procedimiento se precisa cuáles propósitos específicos permite cumplimentar, se brinda una descripción de su empleo, se dan referencias para ampliar el conocimiento sobre ellos, se proporcionan ejemplos de su utilización y se explica el programa computacional con el que puede ejecutarse o facilitarse su realización. Una síntesis de los resultados expuestos es asimismo presentada.
Palabras clave: Estado de salud de la población, medición, desigualdades.
El tema de las iniquidades en salud ha sido ampliamente tratado en épocas recientes, desde diversos ángulos: la concepción de equidad e iniquidad en salud, 1-4 en la que se incluye una conceptualización autóctona (Escuela Nacional de Salud Pública. Proyecto Monitoreo de Equidad y Salud en Cuba. Grupo Básico de Trabajo. La Habana; 2001), los enfoques filosófico-morales de equidad en salud, 5 la equidad en salud en el marco de la globalización,6 la preocupación de los organismos internacionales por la falta de equidad en salud,7-13 el monitoreo de la equidad en salud14-16 [Alianza Global para el Monitoreo de la Equidad (GEGA). El monitoreo de la equidad (equity gauges): conceptos, principios y pautas. GEGA, Health Systems Trust;2003] y l as propuestas cubanas en relación con este monitoreo.17,18
Sintetizando lo expuesto por de la Torre y otros,19 por iniquidad en salud pueden entenderse todas aquellas desigualdades, o igualdades, injustas y evitables en el estado de salud de la población o en sus determinantes. Por tanto, la iniquidad en salud no se mide, se juzga, y, justamente, el paso inicial para valorar lo injusta de una desigualdad, o de una igualdad, en el estado de salud, en sus determinantes, o en la relación entre ambos, es medirla. Si el estado de salud de la población se refiere a los niveles y/o patrones de mortalidad o morbilidad, mientras que por estado global de salud se hace referencia tanto al estado de salud de la población como a los determinantes de la salud, la identificación de las iniquidades en salud conllevaría tres acciones:
La medición del estado global de salud y la identificación de las relaciones entre el estado de salud de la población y sus determinantes puede conllevar el cumplimiento de un conjunto de propósitos generales, o de parte de ellos. A su vez, cada propósito general puede desglosarse en propósitos específicos de análisis como se muestra a continuación:
| Propósito general 1. Identificar niveles y patrones de distribución espacio-temporal de indicadores del estado de salud de la población. | |
| 1.1 | Determinar los niveles de mortalidad o morbilidad generales y por causas definidas. |
| 1.2 | Identificar los territorios con un exceso significativo de mortalidad o morbilidad de las enfermedades o daños a la salud. |
| 1.3 | Identificar las desigualdades de la mortalidad o la morbilidad de acuerdo a la distribución de la población en riesgo. |
| 1.4 | ]]> Identificar agrupaciones espaciales de territorios con valores de los indicadores de mortalidad o morbilidad notoriamente altos. |
| 1.5 | Identificar diferencias significativas entre agrupaciones de territorios en indicadores de mortalidad o morbilidad. |
| 1.6 | Evaluar tendencias y establecer pronósticos de los niveles de mortalidad o morbilidad. |
| 1.7 | Identificar patrones estacionales de mortalidad o morbilidad. |
| 1.8 | Identificar la existencia de clusters en el tiempo de niveles altos de mortalidad o morbilidad. |
| 1.9 | ]]> Detectar incrementos significativos en el tiempo de la mortalidad o la morbilidad de las enfermedades o daños a la salud. |
| 1.10 | Identificar la existencia de una interacción significativa entre los lugares y los momentos de aparición de casos de enfermedades y otros problemas de salud. |
| Propósito general 2. Identificar niveles y patrones de distribución espacio-temporal de indicadores de los determinantes del estado de salud de la población. | |
| 2.1 | Caracterizar los niveles y formas de distribución de los indicadores de recursos y servicios en salud y de otros determinantes. |
| 2.2 | Identificar los territorios con una privación significativa de recursos y servicios en salud. |
| 2.3 | Identificar las desigualdades en la distribución de recursos y servicios en salud, y de otros determinantes, de acuerdo a la distribución de la población de referencia. |
| ]]> 2.4 | Determinar la proporción y el número de recursos y servicios en salud, y de otros determinantes, que habría que redistribuir para que exista equidad de acuerdo a la población de referencia. |
| 2.5 | Identificar agrupaciones espaciales de territorios con cifras notoriamente altas de no disponibilidad de recursos y servicios en salud. |
| 2.6 | Identificar diferencias significativas entre agrupaciones de territorios en indicadores de los determinantes de la salud. |
| 2.7 | Evaluar tendencias y establecer pronósticos de indicadores de los determinantes de la salud. |
| Propósito general 3. Determinar la relación entre los niveles de mortalidad o de morbilidad y los niveles de los determinantes. | |
| 3.1 | ]]> Determinar el efecto que tienen los niveles de los determinantes sobre los niveles de mortalidad o morbilidad. |
| 3.2 | Determinar las diferencias absolutas y relativas de mortalidad o morbilidad entre cada estrato y el estrato de mejor condición del determinante u otro estrato de referencia. |
| 3.3 | Evaluar el cambio proporcional y absoluto en los niveles globales de mortalidad o morbilidad si todos los estratos experimentaran el riesgo del estrato de mejor condición del determinante u otro estrato de referencia. |
| 3.4 | Evaluar el cambio proporcional y absoluto en los niveles de mortalidad o morbilidad de cada estrato si todos experimentaran el riesgo del estrato de mejor condición del determinante u otro estrato de referencia. |
| 3.5 | Determinar la magnitud de la diferencia de la mortalidad o la morbilidad considerando las desigualdades en una cierta área de los determinantes. |
| 3.6 | ]]> Determinar las variaciones relativas entre los cambios promedios del indicador de mortalidad o morbilidad entre intervalos sucesivos de valores del indicador del determinante. |
| 3.7 | Evaluar los riesgos relativos de mortalidad o morbilidad en cada estrato respecto al estrato de mejor condición del determinante ajustado a factores que pudieran confundir el efecto de las variables tenidas en cuenta. |
| Propósito general 4. Identificar el impacto de las intervenciones que se realicen en la dinámica de las series de tiempo del estado de salud de la población o de los determinantes. | |
| 4.1 | Identificar si ha habido un cambio significativo en la dinámica de la series de tiempo en los momentos en que se han efectuado las intervenciones, o en su entorno. |
| 4.2 | Determinar el retardo entre el momento de la intervención y el instante de mayor significación del impacto, de existir un cambio en la dinámica de la serie. |
| Propósito general 5. Determinar la eficiencia de los recursos en los resultados del estado de la población o de los determinantes. | |
| 5.1 | Identificar aquellos territorios que han obtenido un resultado en áreas del estado de salud de la población o de los determinantes superior o inferior al esperado de acuerdo a recursos disponibles. |
| 5.2 | ]]> Jerarquizar a los territorios según su eficiencia relativa en la obtención de logros en el estado de salud de la población o de los determinantes. |
| Propósito general 6. Determinar la homogeneidad de los territorios en la obtención de los logros en el estado de salud de la población o de los determinantes. | |
| 6.1 | Identificar aquellos territorios con diferentes niveles de equilibrio en la obtención de sus logros en salud. |
| 6.2 | Jerarquizar a los territorios según sus niveles de homogeneidad en la obtención de los logros en salud. |
| Propósito general 7. Identificar el nivel de disparidad entre grupos humanos respecto a indicadores que los caractericen. | |
| 7.1 | Determinar el nivel de disparidad entre grupos humanos respecto a indicadores que los caractericen. |
| Propósito general 8. Evaluar a los territorios de acuerdo a su estado global de salud. | |
| 8.1 | Evaluar a los territorios mediante índices sintéticos que tomen en cuenta indicadores del estado de la población y de los determinantes. |
| 8.2 | ]]> Jerarquizar a los territorios según su grado de desarrollo global en salud. |
| 8.3 | Determinar si existen agrupaciones espaciales de territorios con valores significativamente bajos, o altos, de los índices empleados. |
| 8.4 | Determinar para cada territorio la eficiencia en el logro de su situación global de salud en función de los recursos disponibles. |
| 8.5 | Jerarquizar a los territorios según la eficiencia en logro de su situación global de salud en función de los recursos disponibles. |
Los propósitos específicos se cumplimentan a través de procedimientos de análisis que pueden clasificarse en diversas categorías según su empleo habitual con otras finalidades. Según conocimiento del autor, ningún trabajo previo ha agrupado los procedimientos de acuerdo a esta taxonomía, ni ha considerado varios de ellos como útiles con el fin de la medición del estado global de salud y para la identificación de las relaciones entre el estado de salud y los determinantes. Las categorías son las siguientes:
En la tabla 1 se presentan los procedimientos de análisis agrupados en las cinco primeras categorías y el propósito específico de análisis que cumplimenta y a continuación para cada procedimiento se brinda una descripción de su empleo, se dan referencias para ampliar el conocimiento sobre ellos, se proporcionan ejemplos de su utilización y se expone el programa computacional con el que puede ejecutarse o facilitarse su realización.
Tabla 1. Procedimientos de análisis y propósitos específicos que posibilitan cumplimentara
| Procedimientos de análisis | Propósitos específicos |
| ]]> Procedimientos utilizados en la vigilancia epidemiológica | |
| Gráfico de distribución espacial | 1.2, 2.2 |
| Corredor endémico | 1.9 |
| Canal endémico basado en el método Texas | 1.9 |
| Procedimientos empleados en el análisis de series de tiempo | |
| Regresión mínimo-cuadrática | 1.6, 1.7, 2.7 |
| ]]> Alisamiento exponencial | 1.6, 1.7, 2.7 |
| Modelación ARIMA-SARIMA | 1.6, 1.7, 2.7 |
| Prueba de punto de ruptura de Chow | 4.1, 4.2 |
| Procedimientos usados en la identificación de clusters en tiempo y/o espacio | |
| Método de Grimson | 1.4, 2.5, 8.3 |
| Método de Ohno | ]]> 1.4, 2.5, 8.3 |
| Método de Chen | 1.8 |
| Método SCAN de Naus | 1.8 |
| Método de Knox | 1.10 |
| Método de David y Barton | 1.10 |
| Procedimientos empleados en el análisis de la economía y derivados | |
| ]]> Curva de Lorenz y Coeficiente Gini | 1.3, 2.3 |
| Curva e Índice de Concentración | 3.5 |
| Procedimientos sustentados en índices empleados con distintos fines | |
| Índice de Disimilitud | 2.4 |
| Índice de Eficiencia Relativa | 5.1, 5.2, 8.4, 8,5 |
| Índice de Homogeneidad de los Logros | ]]> 6.1, 6.2 |
| Índice de Iniquidades en Salud | 8.1, 8.2 |
aVer los propósitos específicos en el texto.
El gráfico de distribución espacial posibilita identificar aquellos territorios (por ejemplo, áreas de salud) que dentro de un determinado universo (un municipio, entre otros) registran un número de casos de enfermedades definidas significativamente mayor que el esperado tomando como referencia los valores de un territorio en particular,20 o del conjunto del universo. Por ejemplo, considerando las incidencias de hepatitis viral aguda (HV), de lepra y de tuberculosis (TB) por 100 000 habitantes para el 2004 para las provincias orientales de Cuba, y tomando como referencia la incidencia global de la región oriental,21 se obtiene el resultado que se muestra en la figura 1.
Fig.1. Gráfico de distribución espacial. Área de referencia: región oriental de Cuba.
De acuerdo a estos resultados, se registra un número de casos superior al esperado -en relación con el número de casos registrado por cada 100 000 habitantes globalmente en la región oriental- de HV en las provincias de Las Tunas y de Holguín, de lepra en Camagüey, Santiago de Cuba y Guantánamo y de TB en Las Tunas. La ejecución de este procedimiento puede realizarse mediante el programa EPIDAT 3.1 elaborado en conjunto por la Xunta de Galicia, España, y la OPS. El programa puede obtenerse en la dirección http://dxsp.sergas.es. La interpretación de los resultados de este gráfico debe hacerse en conjunción con los valores observados de las tasas, ya que también se identifica como los casos observados superan a los esperados cuando lo observado es significativamente menor que lo esperado.
El corredor endémico obtenible mediante el programa EPIDAT 3.1 se sustenta en el cálculo de una medida de tendencia central y valores máximos y mínimos como el canal endémico propuesto décadas atrás 22,23 utilizando el promedio de las medias geométricas de las tasas de incidencia de los últimos años. La ventaja que se le señala al empleo de la media geométrica sobre la media aritmética es que reduce la influencia que puede tener algún brote o epidemia que haya ocurrido en el período de base.24 Para ejecutar el programa se requiere de 5, 6 ó 7 años de información para este período y los momentos del año sólo pueden ser semanas o cuatrisemanas.
Se ha propuesto un procedimiento para construir un canal endémico sustentado en el método Texas.25,26 Este método fue creado con el propósito de monitorizar la aparición de determinados problemas de salud asociados a la presencia de factores ambientales.27 El procedimiento ya aplicado a la construcción de un canal endémico se basa en el establecimiento para cada unidad de tiempo del período de observación, dígase meses, de un nivel de alerta (C1) y de un nivel de acción (C2). Los valores de C1 y C2 se pueden obtener mediante el programa CLUSTER 3.1 elaborado por el Departamento de Salud y Servicios Humanos de los Estados Unidos. La unión de los puntos C1 definen un umbral de alerta y la de los puntos C2 un umbral de acción. De esta manera, el gráfico queda estructurado en tres zonas: por encima del umbral de acción, entre el umbral de acción y el umbral de alerta, y por debajo del umbral de alerta. Una vez en uso el gráfico, se calcula para cada momento de evaluación la razón Ri entre el número observado de casos (Oi) y el número esperado (Ei) y se determina si el valor Ri se encuentra en la zona de normalidad, de alerta o de acción.
]]> La figura 2 muestra un canal endémico construido por este procedimiento para los cuatro trimestres de 2006 sustentado en un período base de 5 años previos. Obtenidos los valores C1 y C2, el gráfico puede construirse utilizando, por ejemplo, Excel.
Fig.2. Canal endémico construido por el método Texas para los cuatro trimestres de 2006.
Este gráfico es particularmente útil cuando la serie presenta una marcada tendencia. Se demuestra25 que los procedimientos simples de construcción de canales endémicos sustentado en cifras medias (dígase, la mediana) y límites definidos por métodos esencialmente sencillos (por ejemplo, las cifras inframáximas y supramínimas), y hasta los elaborados por procedimientos más complejos, como el corredor endémico que se obtiene en EPIDAT 3.1, proporcionan un diagnóstico correcto de la situación de salud, en términos de normal/epidemia, sólo cuando la serie no presenta una tendencia marcada. Si la serie tiende notoriamente a disminuir, como puede ocurrir cuando ha sido eficaz una intervención (una campaña de vacunación, por ejemplo), el canal endémico subdiagnostica la situación; por el contrario, si la tendencia es ascendente, el canal endémico sobrediagnostica la situación. Luego, una conclusión falso negativa o falso positiva depende de lo marcado de la tendencia al descenso o al ascenso existente.
Existen diversos procedimientos para evaluar tendencias en una serie histórica y establecer pronósticos. Uno de ellos es considerar el análisis como un problema de regresión y aplicar el método de los mínimos cuadrados. El método se basa en la obtención de una función que constituya un buen ajuste a la serie observada y permita modelarla. Dígase que tal función es del tipo ŷt = b0 + bi zt, donde ŷt es el valor estimado del indicador para un cierto momento t, siendo zt una transformación de la variable t, tal como t2, Ö t, ln t, 1/t, o la propia variable t sin transformar, en tanto b0 y bi son coeficientes que hay que calcular. La variable t toma valores 1, 2, ... , n, donde n es el número de momentos considerados. Habitualmente se selecciona aquella función que genera el mayor Coeficiente de Determinación (R2) teniendo en cuenta los valores observados de la variable dependiente (indicador) y las transformaciones zt .R2 es una medida de la precisión de las estimaciones, y puede adoptar valores entre 0 y 1, en ocasiones expresado en porcentaje, más alto en tanto mayor es la precisión, mide cuánto la variación de la variable dependiente se explica por la variabilidad de la, o las, variables independientes.28 En este sentido, se ha alertado25 que no debe olvidarse al determinar la función de ajuste que debe elegirse la más simple entre aquellas que produzcan resultados similares de acuerdo al principio de la parsimonia, o de la parquedad, también conocido como Ockham's Razor.29 ¿Cuántos años son necesarios para el análisis? Como regla práctica para una proyección basada en la extrapolación de una tendencia se requieren de siete a diez años de datos históricos y la proyección no debe realizarse a un tiempo mayor que la mitad del número de años considerados.30 La recomendación pareciera válida para cualquier unidad de tiempo utilizada en el análisis diferente al año.
Dos aspectos en los que algunos investigadores se confunden se examinan a continuación. Uno de ellos, es pensar que mientras más sean los años considerados en el período base, mejor será el pronóstico. Aquí no cabe el refrán de mientras más, mejor. Al momento de definir el período base, uno debe hacerse, al menos, las siguientes preguntas: ¿permanecerán, o se modificarán, en el horizonte de pronóstico las causas que generaron los valores de la serie observados en el período base?, ¿se realizarán intervenciones que modifiquen la dinámica de la serie?, ¿se modificará la presencia de otros eventos relacionados con el problema estudiado? Un ejemplo de que una serie más corta constituye un mejor período base que una más larga se verá cuando se considere la prueba de Chow para la evaluación de impacto. El otro aspecto es, que en ocasiones se dice que mediante el método de los mínimos cuadrados se obtiene la mejor ecuación de tendencia. Esto es en rigor, falso. El procedimiento de los mínimos cuadrados no garantiza la obtención de la mejor ecuación de tendencia, sólo garantiza para un modelo dado de ecuación de tendencia los valores de los coeficientes que permiten, bajo el concepto de los mínimos cuadrados, el mejor ajuste a los valores dados. Luego, si el modelo está inicialmente mal seleccionado (dígase, se emplea una transformación inadecuada de la variable t) el procedimiento no subsana este error, solamente ante los infinitos valores que pueden tomar los coeficientes b0 y b1 seleccionará aquellos que hagan que la ecuación se ajuste mejor a los datos, aunque la función obtenida no sea en forma alguna la adecuada para modelar la tendencia.
Un programa particularmente útil para aplicar el procedimiento de los mínimos cuadrados es Econometrics Views (EViews) si bien otros programas, como SPSS, también son útiles. Los principios del método se presentan con mayor o menor rigor en múltiples obras de estadística y trabajos donde se aborda el análisis de series históricas.25,31,32
Otra técnica posible de aplicar, fundamentalmente cuando las series no son muy regulares, es el alisamiento exponencial. A diferencia del método de los mínimos cuadrados que se utiliza en el análisis de series históricas extrapolando su uso del análisis de regresión, las técnicas de alisamiento exponencial están específicamente diseñadas para emplearse en el análisis de series de tiempo. De los procedimientos de alisamiento exponencial existentes, los principales son los siguientes:25
| Procedimiento | Utilización |
| ]]> Alisamiento exponencial simple | Series sin tendencia y sin estacionalidad |
| Alisamiento exponencial con 2 parámetros | Series con tendencia y sin estacionalidad |
| Alisamiento exponencial con 3 parámetros | Series con tendencia y con estacionalidad |
El programa EViews, entre otros, resulta útil para ejecutar estos procedimientos. Para profundizar sobre este método, en particular sus aspectos teóricos, puede consultarse la obra de Pulido.33
Aunque los conceptos de serie estacionaria, serie autorregresiva y serie de medias móviles no se incorporaron recientemente al arsenal de los especialistas en el tratamiento de las series de tiempo -por ejemplo, se citan trabajos que datan de la década de los años 30 del pasado siglo-, 34 innegablemente la aparición en 1970 del libro de Box GE y Jenkins GM, Time Series Analysis: Forecasting and Control abrió una nueva etapa en el análisis de series de tiempo sustentado en estos conceptos. La esencia del enfoque Box-Jenkins se basa en que toda serie de tiempo en su forma original, o resultado de ciertas transformaciones, puede ser considerada como generada por una cierta clase de modelo ARIMA. El procedimiento de análisis consiste, por tanto, en determinar cuál tipo de modelo ARIMA es el que genera la serie analizada y, una vez identificado, emplearlo a los fines de pronóstico. El término ARIMA proviene de A uto R egressive I ntegrated M oving A verage. El enfoque Box-Jenkins puede emplearse tanto en el tratamiento de series históricas de datos anuales, como en aquellos donde se considera la estacionalidad (modelo SARIMA). El número de observaciones requerido para que una serie sea susceptible de análisis es grande, no menos de 20 datos para datos anuales, y al menos de 40 a 50 datos en series estacionales. En caso de series mensuales se recomienda trabajar con no menos de seis a diez años completos de información. El terreno de aplicación de la modelación ARIMA es el de corto plazo, con suficiente disponibilidad de información.25,33 Como se ha puntualizado,25 la modelación Box-Jenkins es una técnica que mucho se usa, en ciertos casos se desusa, en ocasiones mal se usa, y frecuentemente de ella se abusa. Entre los paquetes que se pueden emplear para ejecutar este procedimiento se encuentra Statistical Software for Public Health Surveillance (SSS) desarrollado por la División de Vigilancia y Epidemiología de los Centros para el Control de Enfermedades y Prevención (CDC, por sus siglas en inglés). Programas de uso más general como SPSS y EViews también posibilitan realizar este tipo de análisis.
La evaluación del impacto de una intervención en la evolución de una serie de tiempo de un indicador se puede realizar a través de la prueba de Chow. Esta dócima es la forma más utilizada para poner a prueba si los parámetros asociados con un conjunto de datos son los mismos asociados con otro conjunto de datos.28 La figura 3, en su parte superior, muestra la serie de mortalidad infantil para un cierto territorio entre 1985 y el 2002. Se conoce que en el año 1990 se realizó una intervención con el fin de reducir aún más la mortalidad infantil. Mediante la prueba de Chow se demostraría que el impacto ocurrió 2 años más tarde. Por otro lado, este resultado permite dividir la serie en dos partes a los efectos de elaborar un pronóstico para los años subsiguientes al 2002; luego, si se deseara hacer un pronóstico, dígase, para el año 2004, se haría basado en la función de la recta que modela la serie a partir del año 1992, y no de la función que tiene su origen en 1985 (figura 3, parte inferior). Esta prueba puede ejecutarse mediante el programa EViews.
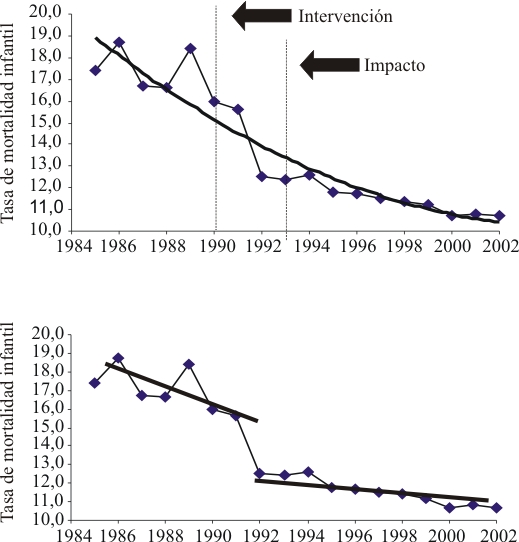 ]]>
]]>
Si bien desde hace décadas se han venido desarrollando métodos para identificar la presencia de agrupaciones no aleatorias de casos de enfermedades en el tiempo, en el espacio, o simultáneamente en tiempo y espacio como lo demuestran las revisiones que sobre el tema se han realizado,35,36 no es menos cierto que en los últimos años se ha manifestado un creciente interés en el desarrollo de métodos para el análisis espacial de eventos en salud y se han realizado investigaciones empleando estos métodos para identificar áreas donde residen grupos de población que requieren de una prioridad de intervención relacionada con la incidencia de diversas enfermedades.37-39 El método propuesto por Grimson y otros,40 permite identificar si existe una agrupación de territorios, más allá de lo que el azar puede explicar -es decir, un cluster en el espacio-, con valores de un determinado indicador que sobrepasa un cierto valor crítico. La prueba se basa en la comparación del número observado de fronteras adyacentes compartidas por los territorios (por ejemplo, municipios) con valores superiores al valor crítico -pudiera llamárseles áreas de riesgo- con una cifra esperada, asumiendo que las áreas de riesgo están distribuidas aleatoriamente dentro de una región (pudiera ser, una provincia). La aplicación de este procedimiento a un estudio de la incidencia de TB en el municipio Marianao de la provincia Ciudad de La Habana en Cuba permitió identificar un cluster de barrios con tasas altas (superior a la tasa media de incidencia del municipio) hacia el centro del municipio,41 como se ve en la figura 4 (barrios sombreados). Al igual que el método de Grimson, el propuesto por Ohno y otros 42 permite identificar la ocurrencia de agrupaciones geográficas de casos de enfermedades.
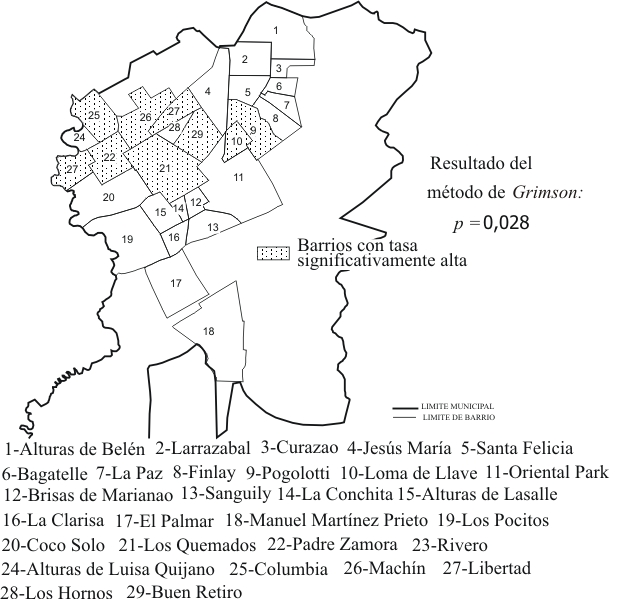
Fig.4. Barrios del municipio Marianao, La Habana, Cuba, con tasas altas de incidencia de tuberculosis.
El método sugerido por Chen y otros43 posibilita determinar para un territorio definido si existe un cluster en el tiempo de casos de una determinada enfermedad. Se sustenta en la comparación de la longitud del intervalo de tiempo observado entre casos sucesivos con un intervalo crítico basado en la tasa base de la enfermedad y el tamaño de la población en riesgo. Otro método para identificar clusters en el tiempo es el sugerido por Naus44 (scan statistics). En este procedimiento todos los casos son ordenados de acuerdo a la fecha de ocurrencia del evento estudiado, y se define un intervalo, o ventana, que se mueve a lo largo de todo el período de observación, determinándose cuántos casos hay en cada ventana. La decisión de si existe o no cluster en el tiempo se basa en el valor de la probabilidad ( p) de que el número de casos en cualquier ventana sea mayor o igual que una cierta cifra (el número máximo de casos observado en cualquier ventana) bajo la hipótesis de que la distribución en el tiempo es aleatoria. Un aspecto particularmente importante en la aplicación de este método es la determinación del tamaño de la ventana ya que de él depende el valor de p, y de este valor a su vez depende de que se concluya si existe o no cluster en el tiempo.25
Knox expuso, al parecer por primera vez, una prueba para la identificación de clusters simultáneos de casos en espacio y tiempo.45 La dócima es sencilla. Se basa en el cálculo de la probabilidad de que el número observado de casos cercanos tanto en espacio como en tiempo, dadas definiciones de lo que es cercano en una y otra dimensión, sea mayor que un cierto valor l asumiendo una distribución de Poisson. La dificultad con la aplicación de este método consiste en definir los criterios de cercanía en tiempo y en espacio. Al igual que el método de Knox, el de David y Barton posibilita identificar clusters simultáneos en tiempo y espacio detectando cambios de patrones espaciales con el paso del tiempo. El procedimiento consiste, grosso modo, en determinar si es o no aleatorio el patrón de proximidad espacial dada la proximidad temporal, y utiliza un enfoque similar conceptualmente al análisis de varianza de un criterio de clasificación.46
Todos los procedimientos expuestos basados en la identificación de clusters en espacio y/o tiempo pueden ejecutarse a través de los programas EPIDAT 3.1 y CLUSTER 3.1, excepto el de David y Barton que sólo puede realizarse empleando CLUSTER 3.1.
La Curva de Lorenz hace posible identificar, para un conjunto de territorios, las desigualdades de la distribución de un cierto evento de acuerdo a la distribución de la población de referencia al compararla con la distribución uniforme o de igualdad. En la curva se representan los porcentajes acumulados de la población (en el eje X) con los porcentajes acumulados de la variable considerada (en el eje Y), y en tanto mayor es el área entre la Curva de Lorenz y la línea diagonal de igualdad, mayor es la desigualdad en la distribución. Cuando la variable es positiva, por ejemplo, número de médicos de familia en la comunidad por cada 1 000 habitantes, la curva se sitúa por debajo de la línea de igualdad, mientras que si la variable es negativa, como la tasa de mortalidad infantil, la curva se ubica por encima de la línea diagonal de igualdad.47 La figura 5 muestra la Curva de Lorenz de la distribución de médicos por habitante para 23 países de América Latina y el Caribe.48 Entre otros resultados se observa que el 50 % de la población tiene acceso a sólo algo más del 10 % de los médicos disponibles. De existir una perfecta distribución de los médicos en los países de acuerdo a la población a atender, dígase, el 20 % de la población tendría acceso al 20 % de los médicos; el 50 % de la población, al 50 % de los médicos, entre los valores dados por la línea diagonal de igualdad. El Coeficiente Gini es una función del área entre la Curva de Lorenz y la línea de igualdad. Puede asumir valores entre 0 y 1, más alto en tanto mayor es la desigualdad del evento considerado en la población subyacente y existen diversas formas de calcularlo.47,49
Por ejemplo, si para los municipios de una provincia el Coeficiente Gini para la cobertura de médicos por habitante y la cobertura de estomatólogos por habitante resulta ser 0,237 y 0,470, respectivamente, puede decirse que entre los municipios de la provincia la cobertura de estomatólogos de acuerdo a la población a atender es más desigual que la distribución de los médicos pero no de qué forma es más desigual, cuestión que puede apreciarse mediante la curva de Lorenz. A su vez, valores similares del Coeficiente Gini pueden obtenerse con diversas formas de distribución de la desigualdad figura 5. ]]>
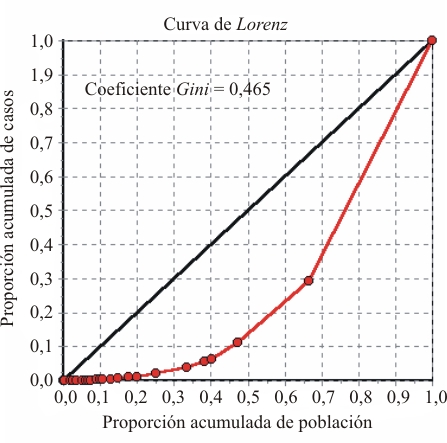
Fig.5.Curva de Lorenz y Coeficiente Gini de la distribución de médicos por habitante en países de América Latina y el Caribe/ c 2000.
La Curva e Índice de Concentración permiten el análisis de las desigualdades en salud en su relación con las desigualdades socioeconómicas. Para la Curva de Concentración se plotea en el eje Y de un gráfico la proporción acumulada de la variable adversa de salud (dígase la tasa de mortalidad por enfermedades diarreicas en menores de cinco años), y en el eje X la proporción acumulada de población expuesta (la población menor de cinco años, en el mismo ejemplo) ordenada según su nivel socioeconómico. Si cada grupo poblacional independiente de su nivel socioeconómico tiene el mismo valor de la variable de salud, la Curva de Concentración es la línea diagonal de igualdad en el gráfico. El Índice de Concentración es una función del área entre la curva y la línea de igualdad, y toma valores entre 1 y 1, con valor absoluto más alto en tanto la curva más se distancia de la línea diagonal. Si los valores del indicador adverso de salud se reduce uniformemente en tanto aumenta el nivel socioeconómico -es decir, la salud se concentra en los de mayor nivel socioeconómico- todos los puntos que definen la Curva de Concentración se ubicarán por encima de la diagonal y el Coeficiente de Concentración tomará un valor negativo, si los valores del indicador adverso de salud se incrementan uniformemente mientras aumenta el nivel socioeconómico -o sea, la salud está concentrada en los de menor nivel socioeconómico- los puntos que delimitan la curva se hallarán por debajo de la diagonal y el coeficiente adoptará un valor positivo. Si los territorios quedan ordenados de la misma manera por la variable de salud que por el indicador socioeconómico, entonces el Índice de Concentración va a tener el mismo valor que el Coeficiente Gini, lo que sugeriría que son otras las variables que explican las formas de distribución de las variables de salud en la población. Una importante ventaja del Índice de Concentración sobre el Coeficiente Gini es que hace posible el análisis no sólo de las desigualdades en salud, sino también establecer su asociación con las desigualdades socioeconómicas.50-52 (Concentration curves. Quantitative techniques for health equity analysis, Technical Note # 6 y The concentration index. Quantitative techniques for health equity analysis, Technical Note # 7. Ambas referencias, s/l; s/f y s/a).
Asuma que para 17 municipios se dispone de la siguiente información: la población, las tasas de mortalidad por accidentes por 10 000 habitantes y el porcentaje de población que vive por debajo de la línea de pobreza, esta última variable como un proxy del nivel socioeconómico del municipio. La Curva y el Índice de Concentración resultantes se muestra en la figura 6.
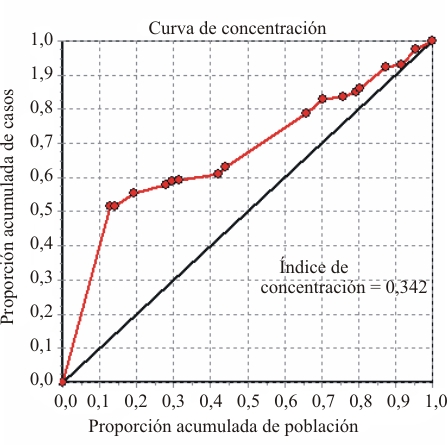
Fig.6. Curva e Índice de Concentración de la mortalidad por accidentes en 17 municipios. Indicador socioeconómico: porcentaje de población que vive por debajo de la línea de pobreza.
El gráfico informa, por ejemplo, que el 10 % de la población más pobre acumula el 40 % de las muertes por accidentes. El valor del Índice de Concentración traduce que existe una desigualdad mediana (el valor modular es alrededor de la tercera parte del total posible) en la distribución de la mortalidad por accidentes de acuerdo a los niveles de pobreza registrados.
Tanto la Curva de Lorenz y el Coeficiente Gini, como la Curva y el Índice de Concentración pueden obtenerse mediante el programa EPIDAT 3.1.
El Índice de Disimilitud cuantifica qué porcentaje (en su versión relativa) o qué número absoluto (en su versión absoluta) de casos tienen que ser redistribuido para lograr la misma tasa en todos los grupos socioeconómicos, o cualquier otra agrupación que se haga de las observaciones, por ejemplo, por municipios (Kunst AE, Mackenbach JP. Measuring socioeconomic inequalities in health. Copenhagen: WHO Regional Office for Europe.p.54. s/f), también se ha definido como la proporción de salud total que necesitaría ser transferida de los individuos cuya salud se halla por encima del promedio a aquellos cuya salud se encuentra por debajo del promedio.49 Si bien se emplea para redistribuir casos de una enfermedad,49 como ha sido expresado,47 su aplicación es dudosa para analizar desigualdades en la mortalidad o la morbilidad, porque carece de sentido práctico y ético redistribuir las defunciones o los casos de una enfermedad. Por ejemplo, en Cuba para lograr una perfecta distribución territorial de sus médicos de acuerdo a la población de cada provincia se tendría que redistribuir el 9,7 % de estos profesionales, en tanto en Bolivia habría que redistribuir el 10,2 % de los médicos en sus departamentos.19 Al igual que ocurre con el Coeficiente Gini, similares valores del Índice de Disimilitud pueden obtenerse con diversos patrones de desigualdad. El cálculo del índice relativo y absoluto puede realizarse a través del programa EPIDAT 3.1.
]]> Se entiende por eficacia la capacidad de lograr objetivos, y por eficiencia la relación entre resultados y recursos.54 El Índice de Eficiencia Relativa (IER) fue introducido por López y Calvo para cuantificar la eficiencia en el logro de la salud de la población en función del recurso económico en 310 municipios de Bolivia.55 El índice adopta valores entre 1 y +1, el primer valor denota la mayor eficiencia relativa negativa (o mayor ineficiencia relativa) y +1 la mayor eficiencia relativa positiva. Cuba, por ejemplo, considerando el gasto en salud per capita como medida de recurso, entre 25 países de las Américas, registra un IER de 1 000 en cuanto al logro de la tasa de mortalidad infantil y de 0,847 en lo que concierne a la tasa de mortalidad de menores de cinco años, y entre 17 países de 0,409 en lo referido a la razón de mortalidad materna.19 El índice ha sido empleado asimismo en otros trabajos recientes.56-59 Los programas EViews y Excel facilitan el cálculo del IER.El cálculo del Índice de Homogeneidad de los Logros posibilita medir el grado de homogeneidad interna de cada territorio considerado en el logro de un conjunto definido de indicadores. El índice toma valor entre 0 y 1, más alto en tanto mayor es tal homogeneidad.60 Este índice fue considerado en la Investigación sobre Desarrollo Humano y Equidad en Cuba 1999 estableciendo una jerarquía de las provincias de Cuba respecto al equilibrio en el logro de los ocho indicadores que conformaban el Índice Territorial de Desarrollo Humano y Equidad, y posibilitó concluir que aquellas provincias más homogéneas en cuanto a las dimensiones que integran el desarrollo humano son las que, asimismo, tienen mayor desarrollo humano integral (Ciudad de La Habana y Cienfuegos, por ejemplo) y, por el contrario, las menos homogéneas en los aspectos parciales del desarrollo humano son las que presentan menores niveles de desarrollo humano global (dígase, Guantánamo y Granma), lo que sugiere que el desarrollo global está fuertemente relacionado con el equilibrio en el logro de los aspectos parciales del desarrollo.53 El cálculo del índice se facilita con el empleo de Excel. El Índice de Homogeneidad de los Logros ha sido utilizado en otros trabajos recientemente concluidos.55,56,59
El Índice de Iniquidades en Salud (INIQUIS) es de los que se consideran como índices sintéticos, es decir aquellos que resumen indicadores simples. Fue propuesto para la medición de las desigualdades en salud entre países, o en cualquier otra escala de los territorios. El índice queda integrado por diversos indicadores seleccionados sustentado en reglas de inclusión definidas a partir de un conjunto mayor de indicadores. El índice puede adoptar valores entre 0 y 1, y toma valores más altos en tanto mayor es la desigualdad relativa de un determinado territorio respecto a los indicadores que componen el índice en el contexto de los territorios valorados. De esta manera, valores próximos a 1 indican peor situación, y viceversa, valores próximos a 0 corresponden a la mejor situación relativa.61,62 Para 23 países de América Latina y el Caribe se obtuvo el índice a partir de 20 indicadores iniciales; los valores oscilan entre 0,122 (Cuba) y 0,894 (Haití) (López C. Sistema de salud de Cuba: una visión en el contexto latinoamericano y caribeño. Presentado en: I Congreso de Economía de la Salud de América Latina y el Caribe. Río de Janeiro, 30 de noviembre- 4 de diciembre, 2004). El programa EPIDAT 3.1 posibilita calcular este índice para todos los territorios seleccionando los indicadores que lo integran.
En la tabla 2 se presenta la bibliografía que se puede utilizar para ampliar sobre los procedimientos expuestos, y los programas que se pueden emplear para su ejecución.
Tabla 2. Procedimientos de análisis para la cuantificación del estado global de salud de la población y de la identificación de las relaciones entre el estado de salud y los determinantes: referencias y programas en que se pueden ejecutar
| Procedimientos de análisis | Referenciasa | Programasb |
| Procedimientos utilizados en la vigilancia epidemiológica | ||
| • Gráfico de distribución espacial | ]]> 20, 21 | EPIDAT 3.1 |
| • Corredor endémico | 24 | EPIDAT 3.1 |
| • Canal endémico basado en el método Texas | 25-27 | [CLUSTER 3.1, Excel] |
| Procedimientos empleados en el análisis de series de tiempo | ||
| • Regresión mínimo-cuadrática | ]]> 28,29-32 | EViews, SPSS |
| • Alisamiento exponencial | 25,33 | EViews |
| • Modelación ARIMA-SARIMA | 25,33 | SSS, SPSS, EViews |
| • Prueba de punto de ruptura de Chow | 28 | ]]> EViews |
| Procedimientos usados en la identificación de clusters en tiempo y/o espacio | ||
| • Método de Grimson | 40,41 | EPIDAT 31, CLUSTER 3.1 |
| • Método de Ohno | 42 | EPIDAT 31, CLUSTER 3.1 |
| • Método de Chen | 43 | ]]> EPIDAT 31, CLUSTER 3.1 |
| • Método SCAN de Naus | 25,44 | EPIDAT 31, CLUSTER 3.1 |
| • Método de Knox | 45 | EPIDAT 31, CLUSTER 3.1 |
| • Método de David y Barton | 46 | CLUSTER 3.1 |
| ]]> Procedimientos empleados en el análisis de la economía y derivados | ||
| • Curva de Lorenz y Coeficiente Gini | 47-49 | EPIDAT 3.1 |
| • Curva e Índice de Concentración | 50-52 | EPIDAT 3.1 |
| Procedimientos sustentados en índices empleados con distintos fines | ||
| • Índice de Disimilitud | 47,49 | ]]> EPIDAT 3.1 |
| • Índice de Eficiencia Relativa | 19,55-59 | [EViews, Excel] |
| • Índice de Homogeneidad de los Logros | 53,55,56,59,60 | [Excel] |
| • Índice de Iniquidades en Salud | 61,62 | EPIDAT 3.1 |
Measurement of global health states and the identification of relationship between the population health status and its determinants can lead to the fulfillment of a number of general goals or part of them that may be broken in specific objectives described in the paper. The specific objectives may in turn be met through analytical procedures that are classified in this article into seven categories according to their regular use for other purposes: the analytical procedures used in epidemiological surveillance, time series analysis, space-time clusters identification, economic and derivative analysis, those supported on indexes for various aims, general procedures of statistics and epidemilogy, and other procedures. This paper reflected 19 procedures grouped into the first five categories. The specific purposes that each procedure allows us to attain were stated, the description of their use was provided, references to expand knowledge on them, and examples of their use were given and also the software that may help to perform them was explained. Similarly, a summary of results was submitted.
Key words: Health status of the population.
1. Whitehead M. The concepts and principles of equity. Copenhagen: WHO;1991.
2. Braveman P. Monitoring equity in health: a policy-oriented-approach in low-and-middle income countries. Geneva : WHO;1998 (Documento WHO/CHS/HSS/98.1).
3. Metzger X. Conceptualización e indicadores para el término equidad y su aplicación en el campo de la salud. Documento elaborado durante el intership realizado en el Programa Análisis de la Situación de Salud de la OPS/OMS. Washington: OPS/OMS; Octubre-diciembre de 1996.
4. Sen A. ¿Por qué la equidad en salud? Revista Panamericana de Salud Pública 2002;11:302-9.
5. Peter F, Evans T. Dimensiones éticas de la equidad en salud. En: Evans T, Margaret W, Diderichsen F, Bhuiya A, Wirth M, editores. Desafío a la falta de equidad en salud: de la ética a la acción. Washington, D.C.: Fundación Rockefeller, OPS;2002 (Publicación Científica y Técnica No. 585).
6. Chen L, Berlinguer G. Equidad en la salud en un mundo en marcha hacia la globalización. En: Evans T, Margaret W, Diderichsen F, Bhuiya A, Wirth M, ediores. Desafío a la falta de equidad en salud: de la ética a la acción. Washington DC.: Fundación Rockefeller, OPS;2002 (Publicación Científica y Técnica No. 585).
]]> 7. Organización Mundial de la Salud. Renovación de la estrategia de salud para todos. Informe del Director General. Ginebra: OMS;1995 (Documento EB95/15).8. Organización Panamericana de la Salud. Informe final de la reunión del Grupo Asesor Director de la OPS. Washington, D.C.: OPS;1995 (2-4 de abril).
9. Organización Panamericana de la Salud. Acceso equitativo a los servicios básicos de salud; hacia una agenda regional para la reforma del sector salud. Reunión Especial sobre la Reforma del Sector Salud. Washington, D.C.: OPS;1995 (29-30 de septiembre).
10. Organización Panamericana de la Salud. Salud en el desarrollo humano: perspectivas y prioridades para el nuevo milenio. Washington, D.C.: OPS;2005 (Documento OPS/HDP/97.05).
11. Organización Panamericana de la Salud. Promoción de la salud en las Américas; informe anual del Director, 2001. Washington, D.C.: OPS;2001 (Documento Oficial No. 302).
12. Pan American Health Organization (PAHO). Equity & health: views from the Pan American Sanitary Bureau. Washington, D.C.: PAHO;2001 (Occasional Publication No. 8).
13. Alleyne GAO. La equidad y la meta de salud para todos. Revista Panamericana de Salud Pública. 2002;11:291-6.
14. World Health Organization (WHO). Final report of meeting on policy-oriented monitoring of equity in health and health care, Geneva, 29 September- 3 October 1997. Geneva: WHO;1998 (Documento WHO/ARA/98.2).
15. Nunes A. Medindo as desigualdades em saúde no Brasil: una proposta de monitoramento. Brasilia: OPS;2001.
16. Málaga H. Equidad en materia de salud y oportunidad de vida en Venezuela y Colombia. En: Equity & health: views from the Pan American Sanitary Bureau. Washington , D.C. : PAHO;2001 (Occasional Publication No. 8).
]]> 17. Ramírez A, López C. A propósito de un sistema de monitoreo de la equidad en salud en Cuba. Rev Cubana Salud Pública. 2005;31:79-91.18. _____. A monitoring system for health equity in Cuba . MEDICC Review. 2005;7(9):13-20.
19. de la Torre E, López C, Márquez M, Gutiérrez JA, Rojas F. Salud para todos sí es posible. La Habana: Sociedad Cubana de Salud Pública;2004.
20. Xunta de Galicia, OPS. EPIDAT 3.1. A Coruña, Washington DC.: Xunta de Galicia, OPS;2006 (Ayuda, Gráfico de distribución espacial).
21. Ministerio de Salud Pública. Anuario estadístico de salud 2004. La Habana: MINSAP;2005 (Cuadros 51, 53, 55).
22. Amador T, Redondo C. Manual de bioestadística para trabajos epidemiológicos. Boletín Epidemiológico (Méx). 1964;27(3,4) (Reproducido por el Centro Nacional de Información de Ciencias Médicas).
23. Camel F. Estadísticas médicas y de salud pública. La Habana: Editorial Pueblo y Educación; 1985.
24. Xunta de Galicia, OPS. EPIDAT 3.1. A Coruña, Washington, D.C.: Xunta de Galicia, OPS;2006 (Ayuda, Corredor endémico).
25. López C. Análisis de series cronológicas en el estudio de la situación de salud. Washington D.C.: OPS;1994 (Documento PAHO/HDP/HDA/94-03).
26. Ramírez A, López C. Propuesta de un sistema de monitoreo de la equidad en salud en Cuba [tesis]. La Habana: Escuela Nacional de Salud Pública;2003.
]]> 27. Hardy RJ. Citado por: Aldrich TE, Drane JW. CLUSTER 3.1; Software System for Epidemiological Analysis. Atlanta : U.S. Department of Health and Human Services;1993.28. Kennedy P. A guide to econometrics, 3 rd ed. Cambridge , Massachusetts : The MIT Press;1992.
29. Vogt WP. Dictionary of statistics and methodology. Newbury Park : SAGE Publications;1993.p.158,165.
30. Harrison PJ, Pearce F. Citado por: López AD, Hakama M. Approaches to the projection of health status. En: World Health Organization. Health projections in Europe : methods and applications. Copenhagen : WHO Regional Office for Europe;1986.
31. Yamane T. Statistics; an introductory analysis. La Habana: Instituto Cubano del Libro;1970.
32. Weiss NA. Elementary statistics. 2nd ed. Reading , Massachusetts: Addison-Wesley Publishing;1993.p.581-625.
33. Pulido A. Predicción económica y empresarial. Madrid: Pirámide;1989.
34. Cansado E. Curso de estadística general. La Habana: Instituto Cubano del Libro; 1970.
35. López C. Evaluación estadística de la interacción espacio-tiempo; situación actual. Rev Cubana Administración Salud. 1980;6:357-87.
36. Centers for Disease Control. Guidelines for investigating clusters of health events. MMWR. 1990;39 .
]]> 37.Werneck GL, Struchiner CJ. Estudos de agregados de doenca no espaco-tempo: conceptos, técnicas e desafios . Cad Saúde Pública. 1997;13:611-24.38. Bailey TC. Métodos estatisticos espaciais em sáude. Cad Saúde Pública. 2001;17:1083-98.
39. Cámara G, Vieira AM. Técnicas de geocomputaçao para análisis espacial: é o caso para dados de sáude. Cad. Saúde Pública. 2001;17:1059-81.
40. Grimson RC, Wang KC, Johnson PWC. Citado por: Aldrich TE, Drane JW. CLUSTER 3.1; Software System for Epidemiological Analysis. Atlanta : U.S. Department of Health and Human Services;1993.
41. Molina I, López C, Alonso R. Un estudio ecológico sobre tuberculosis en un municipio de Cuba. Cad Saúde Pública. 2003;18:1305-12.
42. Ohno Y, Aoki K, Aoki N. Citado por: Aldrich TE, Drane JW. CLUSTER 3.1; Software System for Epidemiological Analysis. Atlanta : U.S. Department of Health and Human Services;1993.
43. Chen R, Mantel R, Connely R, Isacson P. Citado por: Aldrich TE, Drane JW. CLUSTER 3.1; Software System for Epidemiological Analysis. Atlanta : U.S. Department of Health and Human Services;1993.
44. Naus JL. Citado por: Aldrich TE, Drane JW. CLUSTER 3.1; Software System for Epidemiological Analysis. Atlanta: U.S. Department of Health and Human Services;1993).
45. Knox G. Detection of low intensity epidemicity; application to cleft lip and palate. Br J Prev Soc Med. 1963;17:121-7.
46. David FN, Barton DE. Two space-time interaction tests for epidemicity. Br J Prev Soc Med. 1966; 20:44 -8.
]]> 47. Schneider MC. Métodos de medición de las desigualdades en salud. Rev Panam Salud Pública. 2002;12:398-414.48. López C, Márquez M, Rojas F. Human development and equity in Latin America and the Caribbean . MEDICC Review. 2005;7(9):21-8.
49. Regidor E. Measures of health inequalities. P1. J Epidemiol Community Health. 2004;58:858-61.
50.Keppel K. Methodological issues in measuring health disparities. Vital and Health Statistics. 2005. Series 2, No. 141, p. 12-3.
51. Xunta de Galicia, OPS. EPIDAT 3.1. A Coruña, Washington, D.C.: Xunta de Galicia, OPS;2006 (Ayuda, Índice de Concentración y Curva de Concentración).
52. Regidor E. Measures of health inequalities.Part 2. J Epidemiol Community Health. 2004;58:900-903.
53. Centro de Investigación de la Economía Mundial (CIEM). Investigación sobre desarrollo humano y equidad en Cuba 1999. La Habana: Editorial Caguayo;2000.
54. ILO, UNOPS, EURADA, Cooperazione Italiana. Local economic development agencies. Roma: ILO, UNOPS, EURADA, Cooperazione Italiana;2000.
55. López C, Calvo A. Índice de Salud Municipal. Representación de la OPS/OMS en Bolivia. La Paz: OPS/OMS; 2001(Serie Documentos Técnicos No. 4, p. 14-5,20-1).
56. López C. Desarrollo humano en América Latina y el Caribe: eficacia y eficiencia. Revista Economía y Desarrollo. 2002;130:11-37.
]]> 57. Rojas F, López C. Desarrollo humano y salud en América Latina y el Caribe. Rev Cubana Salud Pública. 2003;29:8-17.58. Centro de Investigación de la Economía Mundial (CIEM),CITMA, UH, Instituto Nacional de Investigaciones Estadísticas (INIE), Escuela Nacional de Salud Pública (ENSAP). Investigación sobre ciencia, tecnología y desarrollo humano en Cuba 2003. La Habana: CIEM;2004.
59. López C. Desarrollo humano territorial en Cuba: metodología para su evaluación y resultados. Revista Economía y Desarrollo. 2004;136:127-49.
60. López C. Iniquidades en el desarrollo humano y en especial en salud en América Latina y el Caribe [tesis ]. La Habana: Universidad de La Habana;2000.
61. López C. Aproximación a una medición sintética de las iniquidades en salud en las Américas. Revista Instituto Juan César García. 1998;9:78-86.
62. Xunta de Galicia, OPS. EPIDAT 3.1. A Coruña, Washington, D.C.: Xunta de Galicia, OPS;2006 (Ayuda, Índice de inequidades en salud).
Recibido: 4 de septiembre de 2006. Aprobado: 18 de octubre de 2006.
Cándido M. López Pardo. Facultad de Economía, Universidad de La Habana. Calle L No. 353 e/ 21 y 23, piso 13. La Habana 10400, Cuba. e-mail: clopez@infomed.sld.cu
1DrC. de la Salud. Profesor Titular, Universidad de La Habana.
]]>