… ]]>
Distribución óptima de carga en emplazamientos de generadores
Optimal charging distribution in emplacements of generators
Dr. Sergio de la Fé DotresI, Msc. Delmar Jaime GarcíaI ]]>
Facultad de Ingeniería Eléctrica de la Universidad de Oriente. Cuba.
RESUMEN
Incorporados al Sistema Eletroenergético Nacional funcionan emplazamientos de generación distribuida que representan más del 40 por ciento de la capacidad generadora instalada. Estos grupo utilizan fuel oil o diesel como combustibles por lo que lograr su explotación eficiente constituye una necesidad económica de primer orden. Se propone un instrumento computacional para lograr la mayor eficiencia en el uso del combustible mediante la distribución económica de las cargas y se desarrolla un método de optimización basado en el criterio del costo incremental del combustible para determinar el costo total de la generación del emplazamiento. Empleando un algoritmo genético simple se minimiza la función del costo mediante la asignación de las potencias a generar por cada máquina. Se comprueba la aplicabilidad del método mediante su aplicación a un emplazamiento específico. Por su rapidez y calidad de los resultados el instrumento computacional se recomienda para su explotación en emplazamientos y el despacho.
Palabras clave: distribución económica de carga, generación distribuida, algoritmo genético.
ABSTRACT ]]>
The emplacements of distributed generation that represent over the 40 percent of the generating installed capability work to the electric national system incorporated. These group Fuel Oil or diesel utilize like fuels for that achieving his efficient exploitation constitutes a need cheap to run first-rate. Distribution cheap to run of loads proposes a computational instrument to achieve the bigger efficiency in the use of intervening fuel itself and a method of optimization based in the opinion of the incremental cost of fuel to determine the total cost of the generation of the emplacement develops. Using a genetic algorithm the assignment of potencies minimizes the show of the intervening cost itself to generate for each machine. His application finds to a specific summons the applicability of the intervening method. For his rapidity and quality of results the computational instrument is recommended to exploitation in emplacements and the dispatch.
Keys words: Distribution cheap to run, distributed generation, genetic algorithm.
INTRODUCCIÓN
La generación de energía eléctrica en el país depende principalmente de los combustibles fósiles, los cuales constituyen una fuente no renovable de energía. Al iniciarse la Revolución Energética comienza a desarrollarse la Generación Distribuida como parte esencial de la misma. Fueron instaladas una serie de baterías de grupos electrógenos utilizando fuel oil y diesel como combustibles principalmente; estos grupos han brindado un significativo aporte al Sistema Eletroenergético Nacional (SEN), constituyendo en estos momentos más del 40 por ciento de la capacidad generadora instalada. Debido a esto se hace necesaria la implementación de métodos que permitan optimizar la operación de estos grupos; entre estos métodos se encuentran los del reparto de carga entre las máquinas, de manera tal que el costo de combustible total sea mínimo. ]]>
El empleo de técnicas basadas en métodos de optimización no formales, que simplifican el modelo matemático en pos de minimizar el esfuerzo computacional y agilizar la obtención de resultados con el fin de lograr un uso racional del combustible en las plantas, ha sido una de las direcciones en las que se ha trabajado en años recientes [1-4].Entre los métodos de optimización no formales, uno de los que ha gozado de una amplia aceptación, dada la facilidad de su programación y formulación del algoritmo ha sido el de los algoritmos genéticos (AG), por lo que el objetivo del presente trabajo es exponer un método para lograr la distribución óptima de la carga entre agregados de una batería de motogeneradores utilizando esta técnica y el criterio de los costos incrementales del combustible.
DESPACHO ECONÓMICO DE CARGA
Se entiende por despacho económico de carga el reparto de la carga entre varias unidades generadoras que trabajan en paralelo, de manera que el costo total de operación sea mínimo y se satisfagan las condiciones de balance de carga, limitaciones de las máquinas generadoras y límite térmico de las líneas, [1], [3], [5-6].
Si se designa por F1, F2, Fm a los costos de combustible de las unidades 1 a la m.
![]()
![]()
… ]]>
y FT al costo total de combustible de las m unidades.
![]()
Entonces el modelo matemático para el despacho de carga sería
![]()
Sujeto al sistema de restricciones por:
¬ Balance de carga, ![]() ]]>
¬ Límites de trabajo de los generadores
]]>
¬ Límites de trabajo de los generadores ![]()
¬ Límites térmicos de las líneas, ![]()
En Cuba, en régimen normal de trabajo, las máquinas en las instalaciones de la Generación Distribuida alimentan directamente a los circuitos de distribución, por esa razón en este caso no es necesario tener en cuenta las pérdidas en las líneas ni la restricción por limite térmico en ellas a la hora de determinar la distribución optima de carga de los generadores, por ello sólo se tuvieron en cuenta las ecuaciones (4) a la (7) en el desarrollo del modelo.
La aplicación del método del multiplicador indeterminado de Lagrange a esta tarea permite definir el multiplicador λ. que recibe el nombre de costo incremental de combustible y es igual a la primera derivada del costo del consumo del combustible expresado como una función de la generación. Quiere decir que para cada unidad generadora es posible establecer una característica de costo incremental de combustible en función de la generación, obtenida a partir de la característica de costo de combustible-generación; el óptimo de la operación de las unidades se consigue cuando todas operan con el mismo valor de.
ALGORITMO GENÉTICO
Los algoritmos genéticos son un grupo de técnicas de búsqueda basadas en la teoría de la evolución de las especies de Darwin. Esta técnica se basa en los mecanismos de selección que utiliza la naturaleza, de acuerdo a los cuales los individuos más aptos de una población son los que sobreviven, al adaptarse más fácilmente a los cambios que se producen en su entorno. ]]>
Estos algoritmos hacen evolucionar una población de individuos sometiéndola a acciones aleatorias semejantes a las que actúan en la evolución biológica (mutaciones y recombinaciones genéticas), así como también a una selección de acuerdo con algún criterio, en función del cual se decide cuáles son los individuos más adaptados, que sobreviven, y cuáles los menos aptos, que son descartados.
Un algoritmo genético es un método de búsqueda dirigida basada en probabilidad. Bajo una condición muy débil (que el algoritmo mantenga elitismo, es decir, guarde siempre al mejor elemento de la población sin hacerle ningún cambio) se puede demostrar que el algoritmo converge en probabilidad al óptimo. En otras palabras, al aumentar el número de iteraciones, la probabilidad de tener el óptimo en la población tiende a 1 (uno).
El objetivo de los AGs es buscar dentro de un espacio de hipótesis candidatas la mejor de ellas. En los AGs la mejor hipótesis es aquella que optimiza a una métrica predefinida para el problema dado, es decir, la que más se aproxima a dicho valor numérico una vez evaluada por la función de evaluación.
Como los Algoritmos Genéticos se encuentran basados en los procesos de evolución de los seres vivos, casi todos sus conceptos se basan en nociones de biología y genética que son fáciles de comprender.
Se denomina Individuo al ser que caracteriza su propia especie, en este trabajo el Individuo representa una distribución de carga entre las máquinas del emplazamiento de generación distribuida. El individuo es un cromosoma y es el código de información sobre el cual opera el algoritmo. Cada solución parcial del problema a optimizar está codificada en forma de cadena o String en un alfabeto determinado, que puede ser binario. Una cadena representa a un cromosoma, por lo tanto también a un individuo y cada posición de la cadena representa a un gen, (que en el caso estudiado representa la potencia entregada por una máquina dada). Esto significa que el algoritmo trabaja con una codificación de los parámetros y no con los parámetros en sí mismos. El genotipo, es el conjunto de genes ordenados y representa las características del individuo, es decir, el genotipo representa el conjunto ordenado de las potencias generadas por las máquinas que cubren una determinada demanda. Cada individuo tiene una medida de su adecuación como solución al problema, en esta oportunidad esa medida es el costo del combustible empleado para cubrir la demanda al emplazamiento.
]]>
A un conjunto de individuos (Cromosomas) se le denomina población. El método de AGs consiste en ir obteniendo de forma sucesiva distintas poblaciones. Por otra parte un Algoritmo Genético trabaja con un conjunto de puntos representativos de diferentes zonas del espacio de búsqueda y no con un solo punto (como lo hace Hill climbing).La única restricción para usar un algoritmo genético es que exista una función llamada fitness o de adaptación, que de información de cuan bueno es un individuo dado en la solución de un problema. Esta función fitness o de adaptación es el principal enlace entre el Algoritmo Genético y un problema real, es la efectividad y eficiencia de la función de adaptación que se tome la que garantizará la calidad de la solución, por lo tanto debe procurarse que la función de adaptación sea similar, si no igual a la función objetivo que se quiere optimizar. Esta medida se utiliza como parámetro de los operadores y guía la obtención de nuevas poblaciones.
Se denominan Operadores Genéticos a los diferentes métodos u operaciones que se pueden ejercer sobre una población y que nos permite obtener poblaciones nuevas. Una vez que se ha evaluado cada individuo sobre una función de adaptación, se aplican los operadores genéticos.
Operador de selección: El paso siguiente a la evaluación es escoger los miembros de la población que serán utilizados para la reproducción. Su meta es dar más oportunidades de selección a los miembros más aptos de la población; para ello se asigna a cada individuo una probabilidad de selección Ps(i) que es proporcional al valor de su función de adaptación e inversamente proporcional a la suma de todas las evaluaciones de la población; es decir se calcula el peso ponderado de la solución de cada individuo dentro del total de la población. Así la probabilidad de selección de cada individuo será:

Empezando desde la población P(t) de n individuos se obtiene una nueva población P(t+1) aplicando n veces el operador de selección. Los individuos se seleccionan de una especie de rueda de ruleta donde cada uno tiene asignado un área proporcional a su probabilidad de selección Ps.
Este mecanismo puede causar problemas de convergencia prematura, por la aparición de un individuo que es mucho mejor que los otros de la población aunque esté lejos del óptimo; las copias de este individuo pueden dominar rápidamente a la población, sin poder escapar de este mínimo local. ]]>
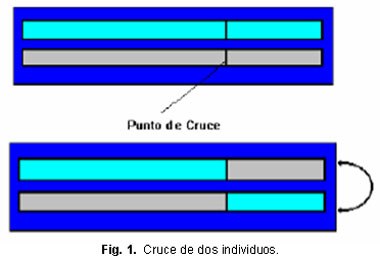
Operador de Cruce: Consiste en unir en alguna forma los cromosomas de los padres que han sido previamente seleccionados de la generación anterior para formar dos descendientes. Existen diversas variaciones, dependiendo del número de puntos de división a emplear y la forma de ver el cromosoma. El operador cruce se aplica en dos pasos: en el primero los individuos se aparean (se seleccionan de dos a dos) aleatoriamente con una determinada probabilidad, llamada probabilidad de cruce Pc; en el segundo paso a cada par de individuos seleccionados anteriormente se le aplica un intercambio en su contenido desde una posición aleatoria K hasta el final, con K Î [1, m-1], donde m es la longitud de individuo. K es el punto de cruce y determina la subdivisión de cada padre en dos partes que se intercambian para formar dos nuevos individuos (hijos), según se puede ver en la figura 1. Esto se conoce como cruce ordinario o cruce de un punto. El objetivo del operador de cruce es recombinar subcadenas de forma eficiente; esta gestión recibe el nombre de construcción de bloques.
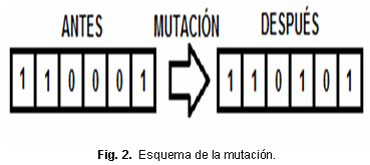
Mutación: El operador de mutación consiste en la alteración aleatoria de alguno de los genes del individuo con una probabilidad de mutación PM, como se puede ver en la figura 2.
El objetivo de la mutación es producir diversidad en la población. Si al generar aleatoriamente la población inicial o después de varias generaciones, en la misma posición de todos los cromosomas sólo aparece un único elemento del alfabeto utilizado, esto supondrá que con los operadores de reproducción y cruce, nunca cambiara dicho elemento, por lo que puede ocurrir que jamás se alcance la solución óptima al problema bajo estudio.
a probabilidad de aparición del operador de mutación no debe ser grande para no perjudicar la correcta construcción de bloques. El operador de mutación origina variaciones elementales en la población y garantiza que cualquier punto del espacio de búsqueda pueda ser alcanzado.
]]>
COSTOS INCREMENTALES Y ALGORITMOS GENÉTICOS
Para obtener el mínimo de costo de combustible entre las distintas unidades a través del método de los Costos Incrementales aplicando los Algoritmos Genéticos se creó un programa empleando el software MATLAB de tal forma que el mismo brinde los resultados de manera precisa y confiable para diferentes niveles de generación entre las unidades y con ello cumplir con el objetivo planteado en este trabajo.
Como se mencionó anteriormente un algoritmo genético es un método de búsqueda dirigida basada en probabilidad. Bajo una condición muy débil (que el algoritmo mantenga elitismo, es decir, guarde siempre al mejor elemento de la población sin hacerle ningún cambio); convergiendo en probabilidad al óptimo, para su programación se deben seguir los siguientes pasos: ]]>
1. Inicializar la población.
2. Aplicar función objetivo.
3. Seleccionar individuos para el cruce.
4. Cruce.
5. Mutación.
6. Inserción y formación de la nueva población.
7. IF se_cumple_criterio_parada THEN parar ELSE volver a 2.
]]>
DESCRIPCIÓN DEL ALGORITMO GENÉTICO EMPLEADO
A continuación se hará una breve descripción de los ficheros que conforman al programa creado para la obtención del costo mínimo de combustible.
Fichero principal OptConsComb ]]>
En este programa se garantiza el ambiente adecuado del cálculo, se forma la matriz aleatoria inicial de la población y se llaman las distintas subrutinas para la ejecución del cálculo y se ofrecen los resultados finales.
Fichero DataComb
En este fichero es donde el usuario introduce los datos que conformarán a la población base, el tamaño de esta y el número máximo de poblaciones por generación; a partir de la cual comenzará el algoritmo Genético, que para este caso en particular son los consumos específicos de combustible.
Fichero Genera
En este fichero se genera una matriz de números aleatorios con distribución uniforme, que constituye el fenotipo de la población base y que podrían ser posibles soluciones del problema.
Fichero Evalúa
En el fichero Evalúa se extraen las características de cada individuo, las cuales se evalúan, luego se toman a los mejores y se ordenan de forma descendente según sea la calidad de los mismo. Aquí se evalúa la función objetivo y se controla el cumplimiento de las restricciones y se ordena la población en función de su cercanía al óptimo. ]]>
En el caso de que se viole la restricción establecida (igualdad de potencia generada y potencia demandada al emplazamiento) por algún individuo, este no se elimina, sino que la función de evaluación que le corresponde es penalizada de manera tal que disminuya notablemente la probabilidad de que sea escogido para un nuevo cruce, de esta manera se conserva el material genético que el mismo pueda aportar.
Fichero Selecciona
En este subprograma se selecciona una población cuyo número de individuos será igual al de la población inicial, luego se repiten a los mejores adaptados en función de su cercanía al óptimo para que tengan mayores posibilidades de reproducirse y se le vuelve a dar un orden aleatorio a los individuos para asegurar que el cruzamiento sea libre.
Fichero Recombina
En Recombina se cruzan los individuos de la nueva población de manera tal que los mejores adaptados se crucen con los menos adaptados (Algoritmo de Vasconcelos), el primero con el último, el segundo con el penúltimo y así sucesivamente, esto garantiza iguales posibilidades de cruce para todos los individuos de la población seleccionada, garantizando una mayor conservación del material genético.
Fichero Muta
En este bloque se calcula el número de bits necesario para representar cada valor de la población tomándose el mayor de todos. Luego se determinan el 0.2% de los genes (puede ser otro valor pero siempre bajo), de los individuos que fueron obtenidos en la recombinación para mutarlos. Se determina de forma aleatoria la columna, la fila y el bit del fenotipo que va a ser mutado. ]]>
VALORACIÓN DE LOS RESULTADOS
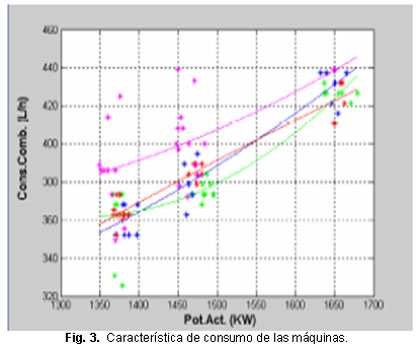
Como se mencionó anteriormente, se parte primeramente del análisis que se les realiza a las diferentes curvas de Consumo de combustible vs. Potencia Generada de las máquinas en cuestión. Las curvas presentaron una notable dispersión en varios puntos como se muestra en la figura 3.
Al evaluar la correlación de las curvas de consumo de combustible se encontraron dispersiones incluso superiores a 5 desviaciones estándar y en una de ellas el término independiente es negativo, lo cual no puede suceder en la práctica pues desde el instante en que se arranca la máquina, aunque no entregue potencia al sistema, está consumiendo combustible.
La falta de correlación entre los datos brindados puede deberse a que no son datos clasificados y en consecuencia se mezclan sin tener en cuenta el estado técnico de las máquinas ni la calidad del combustible empleado, sobre todo su poder calórico. ]]>
Las curvas dadas entonces corresponden a un combustible promedio por máquina. Es de notar, además, que no es de esperar grandes diferencias entre los consumos por máquina dado que estos son equipos relativamente nuevos y no deberían existir grandes desajustes.
Con el fin de validar la solución propuesta, se escogió el emplazamiento de generación distribuida instalado en la subestación Héctor Pavón de la ciudad de Santiago de Cuba. Se realizaron corridas del programa para seis valores de la potencia total a generar en el emplazamiento, desde 1800 hasta 6300 kW, para determinar la manera óptima de operación del mismo en base a lo que debería generar cada máquina. Para cada una de estas demandas se analizaron un total de 100 generaciones de la población (100 iteraciones) mediante las cuales se analizan un número n de corridas hasta obtener el óptimo. En cada corrida el algoritmo realiza cerca de 35000 iteraciones en un tiempo menor de 1 minuto, lo que lo hace apto para determinar los regímenes de las máquinas en el instante de ser pedidos por despacho.
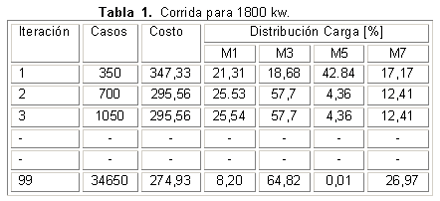
En la tabla 1, se dan a modo de ejemplos, los resultados de la aplicación del AG desarrollado al caso de la generación de 1 800 kW por el emplazamiento. Se muestra como en el proceso de trabajo del algoritmo, durante la primera iteración, las máquinas M1, M5 y M7 operan en regímenes similares de carga, llevando el mayor peso M5 con el 42,84 % de la carga total asumida, no sucediendo así durante el resto del proceso de optimización, donde se produce una variación constante de la distribución de cargas entre las máquinas, principalmente entre M1 y M5, en las cuales, al transcurrir algunas generaciones se reduce considerablemente la potencia suministrada por las mismas hasta alcanzar el óptimo. Al llegar al régimen óptimo M3 mantiene la mayor parte de la potencia, por lo cual debe ser la primera en arrancarse, luego M7 y M1 respectivamente, mientras que M5 no aporta prácticamente nada al sistema y se podría mantener fuera del mismo.
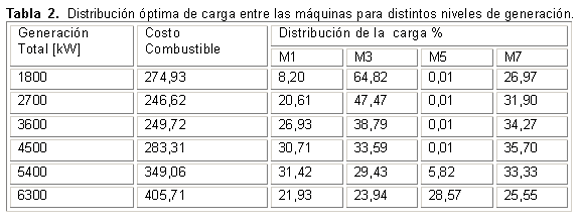
En la tabla 2, se muestra la distribución óptima de carga por máquina para cumplir con distintas potencias a cubrir por el emplazamiento. Un análisis de los resultados mostrados en la Tabla 2 muestra que para una generación de 2700 kW las máquinas M3, M7 y M1 son las que entregan la totalidad de la carga, siendo M3 la que tiene mayor peso, cargada a un 47,47 %, por lo que debe arrancarse primero a esta máquina y luego a M7, M1 y M5 respectivamente, aunque esta última, al igual que para los niveles de 1800, 3600 y 4500 kW, no representa ni el 1 % de la carga total, por lo que podría mantenerse fuera de operación.
Cuando se deben entregar 3600 KW las máquinas M1, M3 y M7 son las que mantienen un comportamiento similar, no siendo así M5 que tan solo está cargada a menos del 1 % de su capacidad nominal. Esto indica que primeramente se debe arrancar a M7, luego a M3, M1 y finalmente a M5, aunque esta última se podría mantener desconectada debido al bajo nivel de cargabilidad que presenta.
]]>
Para una generación de 4500 KW se tiene que las máquinas M1, M3 y M7 presentan similar comportamiento, entre 30 y 36 % de la capacidad generada, no sucediendo esto con M5 que solo entrega un 0,01 %, atendiendo a esto se pondría en línea primero a máquina M7 luego a M3, M1y M5 por ese orden, pudiéndose mantener desconectada a M5 si se tiene en cuenta el bajo rendimiento de la misma.Cuando se deben suministrar de 5400 KW se tiene que las máquinas M1, M3 y M7 operan en regímenes similares (29%- 33%) y M5 alcanza el nivel óptimo de operación en el 5,82 %, por lo que se debe comenzar con M7 y luego M1, M3 y M5 respectivamente.
A 6300 KW, como se puede apreciar, todas las máquinas se encuentran operando a niveles similares en un rango entre 21 y 29 % de capacidad y todas se encuentran prácticamente a plena carga. De esta forma se arrancaría a M5 primero y posteriormente a M7, M3 y M1 respectivamente.
A manera de resumen se puede concluir que a niveles por debajo de 6300 KW las máquinas que mejores condiciones de trabajo presentan son M3 y M7 mientras M1 en varios casos, excepto para 1800 KW, mantiene un rendimiento aceptable, no ocurriendo así con M5 que prácticamente en todos los casos podría permanecer fuera de línea.
CONCLUSIONES ]]>
La combinación de Algoritmos Genéticos y el criterio del costo incremental de combustible constituyen una técnica apropiada para la optimización de la distribución de la potencia a generar en las máquinas de un emplazamiento de generación distribuida. Nótese, a partir de los resultados mostrados en la tabla 2, que la máquina M5 deberá permanecer fuera de línea en todos aquellos regímenes de trabajo en que no sea imprescindible para satisfacer la demanda. Tal comportamiento se debe a su elevado consumo específico de combustible, si se compara con el resto de las máquinas del emplazamiento, como se muestra en la figura 3. En situaciones como la descrita se debe proceder a realizar acciones correctivas que permitan llevar el consumo específico de la máquina en cuestión hasta valores cercanos a los de diseño.
Según la figura 3, las mayores dispersiones en los datos que reflejan el consumo específico de combustible se presentan para los menores valores de potencia demandada. La dispersión de los datos de las curvas de consumo puede atentar contra la obtención de los resultados fiables al falsear la forma de dichas curvas. El método propuesto converge muy rápidamente a la distribución óptima de potencia entre las máquinas en emplazamientos como el empleado para la comprobación de los resultados, que es representativo de los que se emplean en el resto del país. En la tabla 1, se puede apreciar como con solo 99 iteraciones se alcanza la distribución de potencia que garantiza el menor costo del combustible, lo que a su vez se corresponde con la menor cantidad necesaria para satisfacer la demanda de potencia del emplazamiento. La rapidez del método y los resultados que a partir de este se obtienen permiten su introducción en la práctica de explotación de las baterías de Grupos Electrógenos y del Despacho de Carga del Sistema Eléctrico Nacional.
]]>
REFERENCIAS
1. HAN, X., S. G.; et al., "Dynamic Economic Dispatch: Feasible and Optimal Solutions". IEEE Transactions on Power Systems. 2001, vol.16, n.1, p. 22-28, ISSN 0885-8950.
2. WHEI-MIN, LIN; et al., "Economic Dispatch by Integrated Artificial Intelligence. "EEE Transactions on Power Systems. 2001, vol.16, n.2, p. 307-311, ISSN 0885-8950.
3. CHUN-LUNG, CHEN; N. C., "Direct Search Method for Solving Economic Dispatch Problem Considering Transmission Capacity Constraints". IEEE Transactions on Power Systems. 2001, vol.16, n.4, p. 764-769, ISSN 0885-8950.
4. SILVA, C.; et al., "Application of Mechanism Design to Electric Power Markets." IEEE Transactions on Power Systems. 2001, vol.16, n.1, p. 1-7, ISSN 0885-8950.
5. HARNISCH, I.; et al., "Despacho económico con unidades de características no convexas empleando Algoritmos Genéticos." Revista Facultad de Ingenieria, U.T.A.(Chile), 2000, vol. 7.
6. GRAINGER, J. J.; STEVENSON, W.D., "Análisis de Sistemas de Potencia" .Losano Souza, Carlos (trad.). 1ra Edición. México, Edo de Juárez. McGraw-Hill: Interamericana de México, S.A. 1996. p. 705. ISBN 970-10-0908-8.
Recibido: julio del 2011.
Aprobado: diciembre del 2011.
Sergio de la Fé Dotres. Profesor Titular, Dr. en Ciencias Técnicas, Facultad de Ingeniería Eléctrica de la Universidad de Oriente. Cuba. e-mail: sergiof@ee.fie.uo.edu.cu ]]>
NOMENCLATURA
i Índice para las unidades. ]]>
n Número de unidades en el sistema.
Fi Función del costo de combustible de la unidad.
Pi Generación de la unidad.
Pd Potencia total demandada por la carga.
ΔP Pérdida de potencia en las redes.
Pgi máx Límite superior de potencia generada por la unidad.
Pgi mín Límite inferior de generación de la unidad.
Capi máx Máxima potencia a transmitir por efecto térmico de la línea. ]]>