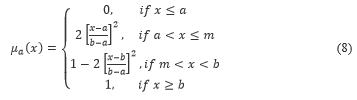Los grafos difusos han ganado en popularidad como soporte a la toma de decisiones. La determinación del nodo más importante en un grafo difuso presenta múltiples aplicaciones como ayuda a la decisión. Sin embargo el análisis estático se ha centrado en la utilización de una sola medida de centralidad, generalmente la centralidad de grado. En el presente artículo se describe un nuevo modelo para el análisis estático en mapas cognitivos difusos, con el objetivo de lograr un ordenamiento multicriterio de los nodos. El mismo hace uso del operador OWA dependiente (D-OWA) para la agregación de las distintas medidas de centralidad. Esta medida compuesta permite el ordenamiento de los nodos facilitando la selección de los conceptos en los cuales intervenir. Adicionalmente facilita y se emplea para mejorar la visualización de los grafos. Los operadores OWA brindan flexibilidad al modelo. La aplicabilidad de la propuesta es demostrada mediante dos casos de estudios referentes a redes empleadas en otras investigaciones.
Fuzzy graphs have recently grown in popularity for decision support. Finding the most important node in the model has multiple applications. Static analysis in fuzzy graphs is mainly based in only one centrality measure, degree centrality. This paper presents a new model for static analysis in fuzzy graphs, with the objective of achieving a multicriteria ordering of the nodes. It makes use of Dependent- OWA (D-OWA) operators for the aggregation of the different centrality measures. This composite measure make possible to order the nodes and select the most important. Furthermore it allows visualizing the graph in a more effective away. OWA operator brings flexibility to the model. Two case studies to show the applicability of the proposal are presented.
Recientemente la noción de relación difusa y grafo difuso ha ganado en visibilidad. Los mapas cognitivos difusos (Leyva Vázquez, et al. 2013) y el paradigma del análisis inteligente de redes sociales (PISMA por sus siglas en inglés) (Yager, 2008) constituyen dos ejemplos significativos. En los grafos difusos resulta importante analizar las características estáticas del modelo, ya que puede contribuir a determinar en qué aspectos del sistema incidir o en reducir la cantidad de criterios que se analizan.
Las propuestas realizadas se han centrado fundamentalmente en buscar la centralidad de los nodos a partir del número de conexiones directas (Altay and Kayakutlu, 2011) ignorando otras medidas de centralidad igualmente importantes. Aunque se ha abordado encontrar el nodo más importante de la red a partir de clases de equivalencia (Jun, et al. 2010) aún es insuficiente el enfoque multicriterio para lograr encontrar un orden. Adicionalmente este método provoca una gran cantidad de empates en el ordenamiento de los nodos obstaculizando tomar decisiones sobre ellos.
Los operadores de agregación son empleados para la obtención de un ordenamiento multicriterio basado en indicadores compuestos. (Yesil, et al. 2013) En este sentido se destaca la familia de operadores media ordenada ponderada (OWA por sus siglas en inglés). (Stach, et al. 2010) Sin embargo estos operadores presentan dificultades para lidiar con los valores erróneos y extremos afectando la fiabilidad de la agregación. (Yager, 2007) Surgiendo la necesidad de realizar un ordenamiento multicriterio de los nodos en grafos difusos que tenga en cuenta diversas medidas de centralidad y permita lidiar con valores erróneos/extremos. En este trabajo se presenta un modelo para la realización de análisis estático en grafos difusos basado en la composición de métricas de centralidad utilizando operadores de agregación, aportando como principal novedad la utilización de operadores de la familia neat OWA (Yager, et al. 2011) para lidiar con el ordenamiento los nodos usando diversos criterios a la vez sin verse afectado por la presencia de valores erróneos/extremos. Este trabajo está organizado de la forma que se muestra a continuación. La Sección 2 está dedicada a la metodología computacional donde se brinda una introducción al análisis estático en grafos difusos y operadores OWA. A continuación en la Sección 3 se presenta el modelo propuesto. La sección 4 está dedicada a presentar los estudios de casos. La Sección 5 aborda las conclusiones y propuestas de trabajos futuros.
]]>
MATERIALES Y MÉTODOS
En esta sección se revisan los conceptos utilizados en el modelo propuesto para el análisis estático en grafos difusos y se explica el funcionamiento de dicho modelo.
Análisis estático en Grafos Difusos
El análisis estático presenta como objetivo la determinación de los nodos más importantes del grafo. Esto se logra a partir de la aplicación de la teoría de grafos, específicamente de las métricas de centralidad.
Si bien las relaciones tradicionales son apropiadas para describir relaciones tales como padres de, los conjuntos difusos son mejores en la captura de relaciones en que existen distintos grados de pertenencia como las de amigo de. (Wierman, 2010) Una relación borrosa en X es un mapeo donde R(x,y) indica el grado de relación de x con y. (Yager, 2010) Esto permite la ampliación del concepto de las conexiones en una red al poderse referir, no solo a si dos nodos están conectados o no, sino las conexiones difusas nos permiten ver qué tanto están conectados los nodos. Se denota un grafo difuso como G=<V,E,R> siendo V el conjunto de vértices, E es el conjunto de aristas y R es una relación .
La teoría de conjuntos difusos se ha aplicado al Análisis de Redes Sociales (ARS) para modelar relaciones difusas que existen entre los vértices o nodos que componen al grafo. (Nair and Sarasamma, 2007) Una red social puede ser fácilmente representada por una relación borrosa o un grafo difuso y así extender las capacidades del analista para examinar la red. (Yager, 2008) ]]>
Con el uso de conjuntos difusos es posible formalizar variables lingüísticas. Para cualquier elemento y ∈ Y , su grado de pertenencia , W (y ) ∈ [ 0,1] indican la compatibilidad del valor y con el concepto de la variable lingüística W. (Yager, 2008) Entre las deficiencias existentes en el análisis estático se encuentran la falta de análisis de la importancia de los nodos en el flujo de información, las conexiones indirectas, la cercanía a determinados nodos y su posición en el grafo entre otros elementos y su posterior consideración en el ordenamiento de los nodos(Altay and Kayakutlu, 2011) Otro aspecto a tener en cuenta es que en muchos problemas es necesario incorporar un ordenamiento multicriterio de los nodos. (Jun, Bing and Deyi, 2010)
Operadores Owa
Los operadores de agregación son un tipo de función matemática empleada para la fusión de la información. Combinan n valores en un dominio D y devuelven un valor en ese mismo dominio. (Torra and Narukawa, 2007) Los operadores de agregación presentan múltiples aplicaciones en diversos dominios. (Beliakov, et al. 2007) En la toma de decisiones su papel fundamental está en la evaluación y en la construcción de alternativas. (Torra and Narukawa, 2007) Su empleo se enmarca fundamentalmente en la toma de decisiones multicriterio.
Una de las familias de operadores de agregación más empleadas son los operadores OWA (ordered weighted averaging o traducido al español media ponderada ordenada). (Yager, 1988) Estos operadores unifican los criterios clásicos de decisión con incertidumbre en un solo modelo. Es decir, esta unificación abarca los criterios optimistas, el pesimista, el de Laplace y el de Hurwicz en una sola expresión. (Merigó, 2008)
Un operador OWA es una función de dimensión n si tiene un vector asociado W de dimensión n con y , de forma tal que:
donde bj es el j-ésimo más grande de los aj ]]>
El vector W por otra parte es empleado para indicar el nivel de compensación entre los criterios y el nivel de optimismo del decisor. (Torra and Narukawa, 2007) Los operadores de agregación pueden ser empleados para la obtención de indicadores compuestos que resumen en un solo valor los resultados de otros indicadores. (Munda and Nardo, 2003) En el presente trabajo se propone la utilización del operador OWA dependiente (D-OWA) (Xu, 2006), donde el vector de pesos del operador OWA
Es definido como:
donde es el grado de similaridad entre el j-ésimo argumento y la media aritmética (u).
Nótese que en este caso se determinan los pesos del vector w sobre la base de los argumentos de entrada que se desean agregar por lo tanto es un operador de tipo neat OWA. (Yager, Kacprzyk and Beliakov, 2011) El nivel de compensación de la agregación (orness) puede ser calculado mediante la ecuación (Xu, 2006):
Modelo Propuesto
Los autores proponen la creación de una medida de centralidad compuesta a partir del operador D-OWA que combine un grupo de medidas seleccionadas por el decisor. La utilización de este operador permite fusionar las distintas medidas de centralidad teniendo en cuenta el nivel de compensación en el cálculo de la medida compuesta. A continuación se describen las actividades del modelo.
]]>
Seleccionar medidas: se recomienda la determinación de medidas para los siguientes aspectos: qué tan fuertemente conectado está un nodo (5), la importancia en el flujo de información (6), y la rapidez en la difusión de la información (7). Finalmente se calcula(n) la(s) medida(s) seleccionada(s).
Calcular medida compuesta: se calcula una medida compuesta de centralidad. La agregación de los valores de las medidas normalizadas se realiza mediante el operador D-OWA.
Ordenar nodos: en esta actividad se ordenan los nodos teniendo en cuenta su importancia en el modelo, de acuerdo al valor obtenido a partir de la(s) medida(s) seleccionada(s). Adicionalmente se puede visualizar el grafo para un mejor análisis.
A continuación se definen las medidas recomendadas:
Centralidad de grado.
]]>
La centralidad de grado (C(v)) se calcula a partir de la suma de su grado de entrada (id(v)) y grado de salida (od(v)), tal como se expresa en la fórmula siguiente:
La centralidad en un grafo indica qué tan fuertemente está relacionado un nodo con otros a partir de sus conexiones directas.
Intermediación.
La intermediación se calcula mediante la siguiente expresión:
donde (v) representa el número de caminos que tienen la longitud menor desde el nodo s hasta el nodo t, pasando por v y es el número de caminos de menor longitud que pasan de s a t. Indica la importancia de un nodo en el flujo de la información (2011).
Cercanía.
]]>
La cercanía se define como:
donde y dG(v,t) es el camino más corto entre v y t. Esta medida brinda la información sobre cuán rápido se difunde la información de un nodo por la red. (Samarasinghea and Strickert, 2011) Se podrán tener en cuenta además otro conjunto de medidas como la centralidad por vector propio (Borgatti, 2005), la centralidad de Bonacich (Criado, et al. 2012), entre otras. El decisor podrá tomar solo un conjunto de estas medidas de centralidad en dependencia de los factores que desea tener en cuenta.
RESULTADOS Y DISCUSIÓN
En esta sección se muestra la aplicación práctica del modelo propuesto a partir de tres estudios de casos. El estudio de caso es un método empírico empleado para demostrar la aplicabilidad de una propuesta entre otros aspectos. (Merigó and Yager, 2013).
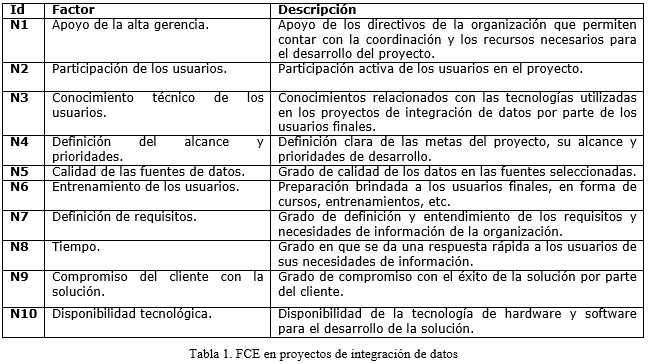
El primero es el mapa cognitivo difuso (MCD) a partir de un modelo previo, obtenido por los autores de los factores críticos de éxito (FCE) de los proyectos de integración de datos. (Leyva-Vázquez, et al. 2012) La integración de datos consiste en la combinación de los datos que residen en diferentes fuentes, y en proporcionar al usuario una visión unificada de estos. (Lenzerini, 2002) A pesar de su importancia, relativamente son pocos los estudios que se han realizado para evaluar las prácticas, y en especial los FCE en este tipo de proyectos. En la tabla 1 se muestra una descripción de los FCE seleccionados.
]]>
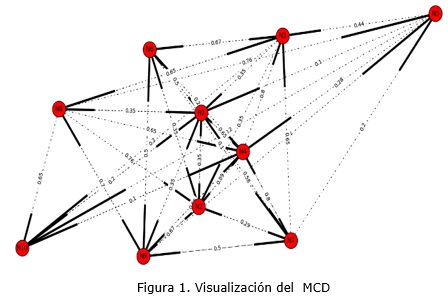
En la figura 1 se muestra una representación del MCD visualizado a partir de la utilización de las bibliotecas networkx y matplotlib de Python (Russell, 2011), las cuales además se usaron para el cálculo de las medidas de centralidad propuestas.
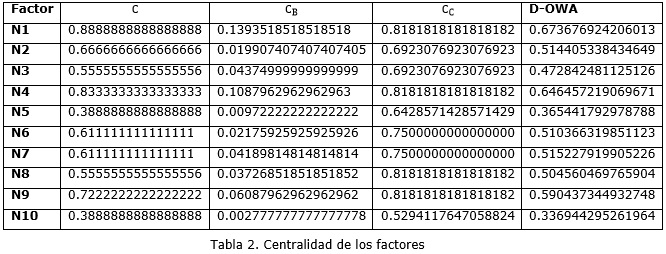
El análisis estático se realiza a partir de las tres medidas de centralidad sugeridas, las cuáles en este caso son agregadas mediante el operador (D-OWA), previa normalización de las medidas. Los resultados se muestran en la tabla 2.
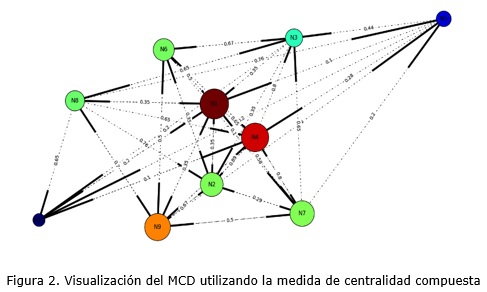
A continuación se muestra la representación gráfica del MCD haciendo uso de la medida compuesta para su visualización figura 2. Nótese como a partir del valor de dicha medida los nodos difieren en tamaño y color a partir de su importancia en el mapa.
El ordenamiento de los factores se realiza de la siguiente forma:
N1>N4>N9>N7>N2>N6>N8>N3N5>N10. En este caso se muestra un predominio de factores asociados con los aspectos humanos y de procesos (N1,N4,N9) sobre los relacionados con factores técnicos (N5,N10) lo que coincide con la experiencia de los especialistas y lo reportado en la literatura(Nasir and Sahibuddin, 2011). ]]>
Para el último estudio de caso se recurrió a la producción científica de las revistas arbitradas a nivel mundial pertenecientes al primer cuartil, de acuerdo al Scimago Journal & Country Rank(SJR), en el período de cinco años del 2006-2010, revistas de impacto indexadas por Scopus Sciverse en la subject area Computer Science y la subject category Artificial Intelligence (IA).
Scopus es una base de datos bibliográfica desarrollada por el consorcio Elsevier, una de las más importantes empresas del sector editorial de ciencia y tecnología, posee un carácter multidisciplinar, indexa más de 18.000 publicaciones y al mismo tiempo integra servicios de visualización de información, análisis de citas e indicadores bibliométricos (Falagas, et al. 2008). Desde el punto de vista idiomático el 83% de la producción se encuentra en inglés, en el otro 17% predominan el francés, chino, holandés y ruso, en menoscabo el alemán, español e italiano.
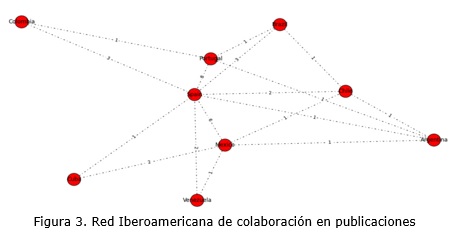
Se acude a esta base de datos para analizar los patrones de colaboración en espacios que tradicionalmente no son analizados, donde muchas de las revistas producidas en América Latina no figuran. Para la creación de esta red de colaboración se procesaron los artículos por el número de firmas (autores), la institución y el país donde se localizan, especialmente se seleccionaron los artículos que se concentran en la región Iberoamericana. Se presenta la colaboración científica entre países, considerando el origen de las adscripciones desde un contexto general (país) hasta la cooperación entre autores (artículos con más de una firma), incluyendo las frecuencias de artículos en colaboración por revista (países, instituciones y autores). La figura 3 representa dicha colaboración.
En este caso el valor de la relación entre países está dado por la cantidad de colaboraciones hechas en revistas por autores de dichos países. Para obtener el grado de colaboración usaremos la función sigmoide con parámetros a y b:
donde m=(a+b)/2
]]>
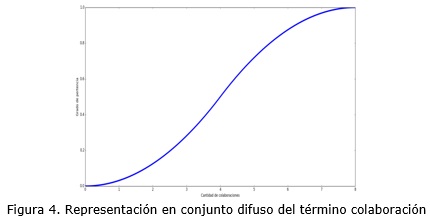
Para este caso a= 0, b= 8 teniendo en cuenta que 8 es el máximo número de colaboración en la red, como se muestra en la figura 4.
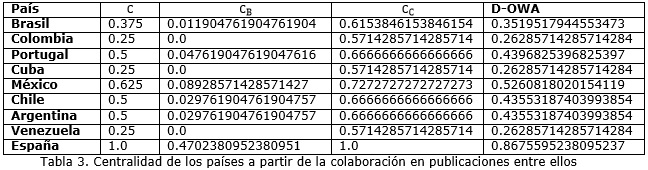
La tabla 3 muestra los valores de las medidas de centralidad propuestas en el modelo así como el resultado de la medida compuesta.
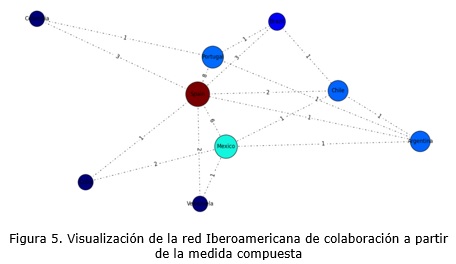
En la figura 5 se muestran los países que difieren en tamaño y color a partir de la medida compuesta.
Los nodos principales en la red se corresponden con los países de mayores niveles de productividad en el orden de España, México y Portugal, como se muestra en el ordenamiento de los países a partir de la medida compuesta propuesta por los autores:
Spain > Mexico > Portugal > Chile ~ Argentina > Brasil > Colombia ~ Cuba ~ Venezuela
Entre ellos también se mantienen las relaciones de colaboración más intensas por lo que se puede decir que en estos tres países se concentra el mayor intercambio de la actividad científica en temas relacionados con la Inteligencia Artificial, un segundo nivel incluye Brasil, Chile y Argentina, quedando alejados resto de los países identificados por estar en la periferia del grafo: Colombia, Cuba y Venezuela. ]]>
Todos los países latinoamericanos mantienen enlaces con el nodo de España (nodo principal).En el caso de Cuba se establecen relaciones con México y España, no así con Portugal. Se observan Venezuela y Colombia como los países de menor colaboración por el alejamiento de sus nodos en la red, y aunque entre ellos no existe contribución de los artículos, coinciden en relacionarse con los países más productivos España, México y Portugal. Por lo que es posible otorgar un papel de liderazgo a los países productores y de colaboración durante la ejecución, dirección o supervisión de las investigaciones (Aguado-López, et al. 2009).
CONCLUSIONES
La utilización de un grafo para representar y modelar fenómenos de la vida real mantiene una creciente atención. El análisis estático permite la selección de los nodos más importantes de la red. Sin embargo generalmente se emplea una sola de las medidas de centralidad, la centralidad de grado, dejando a un lado otro número importante de estas medidas.
En este trabajo se presentó un modelo que combina distintas medidas de centralidad en una medida compuesta de centralidad en grafos difusos para la realización del análisis estático. La utilización del operador D-OWA permite la agregación de las distintas medidas con un modo flexible. Lo cual posibilita el ordenamiento de los nodos de acuerdo a la medida de centralidad compuesta calculada para la selección de los nodos más importantes o la reducción del grafo.
La determinación de las relaciones más importantes en la red a partir de predicados compuestos y uso de la lógica difusa compensatoria, así como la creación de una herramienta informática que soporte el modelo, son áreas de trabajo futuro.
]]>
REFERENCIAS BIBLIOGRÁFICAS
AGUADO-LÓPEZ, E., R. ROGEL-SALAZAR, G. GARDUÑO-OROPEZA, A. BECERRIL-GARCÍA, et al. Patrones de colaboración científica a partir de redes de coautoría. Convergencia, 2009, 16(225-258).
ALTAY, A. AND G. KAYAKUTLU Fuzzy cognitive mapping in factor elimination: A case study for innovative power and risks. Procedia Computer Science, 2011, 3(0), 1111-1119.
BELIAKOV, G., A. PRADERA AND T. CALVO Aggregation functions: a guide for practitioners. Edtion ed.: Springer, 2007. ISBN 9783540737209.
BORGATTI, S. P. Centrality and network flow. Social Networks, 2005, 27(1), 55-71.
CRIADO, R., M. ROMANCE AND Á. SÁNCHEZ Interest point detection in images using complex network analysis. Journal of Computational and Applied Mathematics, 2012, 236(12), 2975-2980.
FALAGAS, M. E., E. I. PITSOUNI, G. A. MALIETZIS AND G. PAPPAS Comparison of PubMed, Scopus,Web of Science, and Google Scholar: Strengths and weaknesses. The FASEB Journal, 2008, 22(2), 338–342.
JUN, H., W. BING AND L. DEYI. Evaluating Node Importance with Multi-Criteria. In Green Computing and Communications (GreenCom), 2010 IEEE/ACM Int'l Conference on & Int'l Conference on Cyber, Physical and Social Computing (CPSCom). 2010, p. 792-797.
LENZERINI, M. 2002. Data integration: a theoretical perspective. In Proceedings of the Proceedings of the twenty-first ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, Dison, Wisconsin2002.
LEYVA-VÁZQUEZ, M. Y., R. ROSADO-ROSELLO AND A. FEBLES-ESTRADA Modelado y análisis de los factores críticos de éxito de los proyectos de software mediante mapas cognitivos difusos. Ciencias de la Información, 2012, 43(2), 41-46.
LEYVA VÁZQUEZ, M. Y., K. Y. PÉREZ TEUREL, A. FEBLES ESTRADA AND J. GULÍN GONZÁLEZ Modelo para el análisis de escenarios basados en mapas cognitivos difusos: estudio de caso en software biomédico. Ingenieria y Universidad, 2013, 17(2), 375-390.
MERIGÓ, J. New extensions to the OWA operators and its application in decision making. PhD Thesis University of Barcelona, 2008.
MERIGÓ, J. M. AND R. R. YAGER. Norm Aggregations and OWA Operators. In Aggregation Functions in Theory and in Practise. Springer, 2013, p. 141-151.
MUNDA, G. AND M. NARDO On the methodological foundations of composite indicators used for ranking countries. Ispra, Italy: Joint Research Centre of the European Communities, 2003.
NAIR, P. S. AND S. T. SARASAMMA. Data mining through fuzzy social network analysis. In Fuzzy Information Processing Society, 2007. NAFIPS'07. Annual Meeting of the North American. IEEE, 2007, p. 251-255.
NASIR, M. H. N. AND S. SAHIBUDDIN Critical success factors for software projects: A comparative study. Scientific Research and Essays, 2011, 6(10), 2174-2186.
RUSSELL, M. A. Mining the social web. Edtion ed.: O'Reilly Media, 2011. ISBN 9781449388348.
SAMARASINGHEA, S. AND G. STRICKERT 2011. A New Method for Identifying the Central Nodes in Fuzzy Cognitive Maps using Consensus Centrality Measure. In Proceedings of the 19th International Congress on Modelling and Simulation, Perth, Australia2011.
STACH, W., L. KURGAN AND W. PEDRYCZ A divide and conquer method for learning large Fuzzy Cognitive Maps. Fuzzy Sets and Systems, 2010, 161(19), 2515-2532.
TORRA, V. AND Y. NARUKAWA Modeling decisions: information fusion and aggregation operators. Edtion ed.: Springer, 2007. ISBN 9783540687894.
WIERMAN, M. J. An Introduction to the Mathematics of Uncertainty. Edtion ed. Omaha, Nebraska: Center for Mathematics of Uncertainty, Inc., 2010.
XU, Z. Dependent OWA operators. Modeling Decisions for Artificial Intelligence, 2006, 172-178.
YAGER, R. R. On ordered weighted averaging aggregation operators in multicriteria decisionmaking. Systems, Man and Cybernetics, IEEE Transactions on, 1988, 18(1), 183-190.
YAGER, R. R. Centered OWA operators. Soft Computing-A Fusion of Foundations, Methodologies and Applications, 2007, 11(7), 631-639.
YAGER, R. R. Intelligent social network analysis using granular computing. International Journal of Intelligent Systems, 2008, 23(11), 1197-1219.
YAGER, R. R. Concept representation and database structures in fuzzy social relational networks. Systems, Man and Cybernetics, Part A: Systems and Humans, IEEE Transactions on, 2010, 40(2), 413-419.
YAGER, R. R., J. KACPRZYK AND G. BELIAKOV Recent Developments in the Ordered Weighted Averaging Operators: Theory and Practice. Edtion ed.: Springer, 2011. ISBN 9783642179099.
YESIL, E., C. OZTURK, M. F. DODURKA AND A. SAHIN. Control engineering education critical success factors modeling via Fuzzy Cognitive Maps. In Information Technology Based Higher Education and Training (ITHET), 2013 International Conference on. IEEE, 2013, p. 1-8.