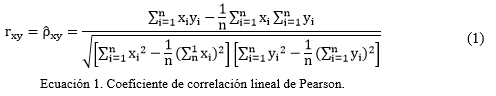
Optimización del stock de piezas de repuesto para equipos médicos
Stock optimization of spare parts for medical equipments
Zoila Esther Morales Tabares1*, Efrén Vázquez Silva2, Yailé Caballero Mota2
1 Universidad de las Ciencias Informáticas. C.P.:19370.
2 Universidad de Camagüey. C.P.:70100.
RESUMEN
Uno de los problemas más comunes durante la gestión de almacenes es la planificación de stock de piezas de repuesto para la satisfacción de las necesidades de reparación o mantenimiento de equipos médicos. En el Centro de Ingeniería Clínica y Electromedicina la planificación de piezas de repuesto para mantenimiento y recambio se realiza a través de los reportes realizados por electromédicos que laboran en las áreas de salud del territorio nacional. Actualmente la información almacenada, más el criterio de los expertos no es suficiente para realizar una buena planificación que permita suministrar la cantidad correcta de piezas en el tiempo adecuado. Teniendo en cuenta estas insuficiencias, se presenta en este trabajo un algoritmo que permita la optimización del stock de piezas de repuesto para equipos médicos. Para su conformación, se utilizaron técnicas estadísticas de estimación: Muestreo Aleatorio Estratificado, Correlación y Regresión Lineal Simple.
Palabras clave: correlación y regresión lineal simple, muestreo aleatorio estratificado, stock de piezas de repuesto
ABSTRACT
One of the most common problems for warehouse management is the spare parts stock planning to cover the repair and maintenance needs of medical equipment. At the Center for Clinical and Electro Engineering, the planning of spare parts for maintenance and replacement is carried out through reports issued by electromedical who work the health areas of the country. Nowadays the recorded information, plus expert judgment is not enough for carrying out an optimum planning that would supply the correct amount of parts demanded, in an adequate period of time. Taking into account these insufficiencies this paper presents an algorithm that allows the optimization of the stock of spare parts for medical equipment. For its conformation, statistics estimation techniques were used: Stratified Random Sampling, Correlation and Simple Linear Regression.
Key words: correlation and simple linear regression, spare parts stock, stratified random sampling
INTRODUCCIÓN
Las Tecnologías de la Información y las Comunicaciones (TIC) han facilitado la interconexión entre las personas e instituciones a nivel mundial, eliminando barreras espaciales y temporales. Casi todos los países del mundo establecen diversos proyectos, políticas y estrategias para promover el uso de las TIC y aprovechar los beneficios que estas ofrecen (Blanco, 2011). Cuba no está al margen del desarrollo mundial, pues realiza grandes esfuerzos e invierte diversos recursos para aprovechar las ventajas que trae consigo la aplicación de las TIC en las diferentes áreas de la sociedad. Uno de los sectores beneficiados en este sentido ha sido la salud pública (Sosa, 2009). Se han puesto a disposición avanzadas tecnologías médicas desplegadas por todo el territorio nacional. Para garantizar su gestión y durabilidad se hace necesario involucrar a todo el personal técnico que interactúa con los equipos médicos, así como a sus fabricantes que constituyen uno de sus responsables (Morales, 2011).
La tecnología médica no está exenta de riesgo. Por tal motivo, cuando es instalada en las unidades de salud deben efectuarse los procedimientos correspondientes según las especificaciones de su fabricante (Hernández, 2011). Durante el transcurso de su vida útil pueden sufrir fallas por afectación inesperada del fluido eléctrico, malas maniobras del operador u otras propias de ella. En correspondencia, con estos riesgos debe existir un stock de piezas destinado a la reparación y mantenimiento, así como un stock destinado a contingencias (Morales, 2011).
Cuando los equipos médicos son reportados con roturas o defectuosos, en algunos casos se han presentado grandes inconvenientes para su reparación. Ocasionado por la ausencia de un registro del histórico de fallas que se presentan durante su uso. Esto impide que se tenga un mayor control de las piezas o gastables que deben ser destinadas a la solución de estos inconvenientes. Si las fallas tienen lugar fuera de los pronósticos efectuados por los especialistas de electromedicina se analiza si el equipo tiene una alta prioridad de ser reparado, ya sea porque se utiliza en actividades de diagnóstico, tratamiento, soporte y mantenimiento de la vida. Dando lugar a una inversión no planificada en caso de que no se cuenten con las piezas necesarias en los almacenes de los centros de electromedicina para la reparación de estos equipos, representando un gasto inesperado para el país (Morales, 2011).
Según la problemática planteada se evidencia que la planificación de piezas de repuesto para equipos médicos está limitada. La información almacenada más el criterio de expertos no es suficiente para suministrar la cantidad correcta de piezas en correspondencia con las necesidades existentes en los centros de salud. Suministro que debe estar acorde con la satisfacción de roturas recogidas en las órdenes de servicio emitidas por los electromédicos que atienden dichas áreas (Morales, 2011). ]]>
Para resolver la problemática planteada se analizaron diversos algoritmos de planificación de inventarios. Ejemplo de ello se puede citar: el algoritmo de ramificación y estimación del inventario para la distribución dinámica de losas en la industria siderúrgica (Castillo, 2013); optimización de dos niveles en la cadena de suministro utilizando algoritmos genéticos multi-objetivos (Gebreslassie, et al, 2012); algoritmo diseñado para la cadena de suministro bajo oferta y demanda en la biorrefinería de hidrocarburos con la presencia de incertidumbres (Jana, et al, 2013); algoritmo diseñado para la reducción del número de recetas de mezcla de gasolina, lo cual permite crear mezclas para un cronograma por simulación interactiva (Laporte and Coelho, 2013); algoritmo evolutivo para un nuevo modelo multi-objetivo de ubicación del inventario en una red de distribución con modos de transporte y logística de terceros proveedores (Arabzad, et al, 2014); optimización de búsqueda cuco multi objetivo para los artículos de inventario en movimiento rápido (Srivastav and Agrawal, 2015); algoritmo exacto para el problema de ruteo de inventario estocástico con transbordo (Chrysochoou, et al, 2015). También fueron analizadas otras propuestas de solución a fines con el problema de optimización planteado en este trabajo (Liangjun, et al, 2009; Zheng and Tang, 2009; Niju and Radhamani, 2010; Ramezanian, et al, 2012; Huber et al, 2015).
El estudio realizado evidenció que estas soluciones pueden adaptarse y emplearse en el Sistema Nacional de Electromedicina, pero presentan el inconveniente que tienen características propias del área o sector para el cual fueron diseñados, como es el caso de las soluciones propuestas por Castillo, Jana y Laporte en 2013 que solamente pueden ser aplicadas a losas, hidrocarburos o mezclas de gasolina. La solución propuesta por (Srivastav and Agrawal, 2015) tiene la limitante que solo permite la optimización de inventarios de clase A, artículos que representan entre el 10 y 15 % del inventario total según la Ley de Pareto (Bonet, 2005).
El resto de las soluciones utilizan algoritmos genéticos como una de las técnicas robustas existentes en la actualidad. Sin embargo, los autores de este trabajo consideramos que esta técnica no es apropiada para la optimización del stock de piezas de repuesto para equipos médicos, debido a que se torna complejo delimitar el espacio de búsqueda de las posibles soluciones. Además, no permiten valorar la correlación e interacción entre las variables empleadas en la solución, asumiendo su independencia que en ocasiones puede ser dudosa.
De acuerdo a lo expuesto anteriormente en este trabajo se presenta un algoritmo de optimización del stock de piezas de repuesto para equipos médicos (ODS). Este algoritmo facilita el mantenimiento durante la vida útil de los equipos y por tanto la disminución de los niveles de stock en los almacenes de electromedicina.
El artículo está dividido en dos secciones. En la primera sección: Materiales y métodos, se explican los métodos estadísticos empleados en la solución del problema, asimismo se explica paso a paso el funcionamiento del algoritmo utilizado en la implementación. Por otra parte, en la sección: Resultados y discusión, se presenta como aporte práctico de la solución, el Módulo Predicción y gestión de stock. También, en esta sección se presenta un análisis pormenorizado del funcionamiento del algoritmo para mostrar la fiabilidad de las predicciones.
MATERIALES Y MÉTODOS
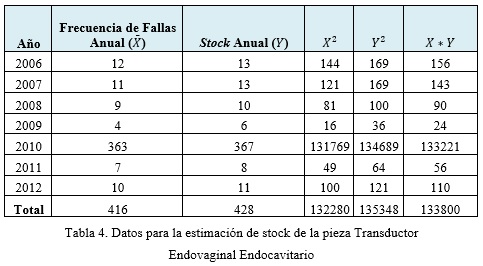
Para la definición del resto de las variables que conformaron el modelo se hizo necesaria la aplicación de una entrevista semi-estructurada para sujetos-tipos (Hernández, 2008). De los 17 especialistas encargados de la planificación y gestión tecnológica de piezas de repuesto para equipos médicos pertenecientes a los Centro de Ingeniería Clínica y Electromedicina del país se entrevistaron 5, que por su experiencia y una serie de requisitos previos lo convierten en expertos de la ingeniería biomédica. De acuerdo a esto quedaron definidas las siguientes variables a emplear en el algoritmo: frecuencia de fallas y stock anual. Considerándose como variable dependiente el stock anual porque representa el valor a predecir o estimar y como variable independiente o explicativa la frecuencia de fallas anual.
Posteriormente, fue necesario determinar si ambas variables estaban asociadas y en qué sentido se daba dicha asociación y si observando los valores de una de las variables podían ser utilizados para predecir el valor de la otra. Para comprobar dicha asociación se calculó el coeficiente de correlación lineal de Pearson (ρ):
Una vez demostrada la existencia de una relación lineal aceptable entre estas variables ![]() se expresa la misma, hallando la ecuación de Regresión Lineal de Y respecto de X; la cual expresó la relación entre el valor esperado de la variable aleatoria Y dado un valor de la variable X. Donde X es la variable independiente y Y la variable dependiente cuyo valor esperado se desea conocer a partir del conocimiento del valor de X. La función que relaciona X con E(Y/X) puede tomar distintas formas, pero en este trabajo se empleó el modelo lineal de primer orden porque solo se considera una variable independiente (Freund, et al, 1996).
se expresa la misma, hallando la ecuación de Regresión Lineal de Y respecto de X; la cual expresó la relación entre el valor esperado de la variable aleatoria Y dado un valor de la variable X. Donde X es la variable independiente y Y la variable dependiente cuyo valor esperado se desea conocer a partir del conocimiento del valor de X. La función que relaciona X con E(Y/X) puede tomar distintas formas, pero en este trabajo se empleó el modelo lineal de primer orden porque solo se considera una variable independiente (Freund, et al, 1996).
Otras de las técnicas estadísticas aplicadas para la realización del algoritmo fueron: el muestreo aleatorio estratificado y la técnica correlación y regresión lineal simple, ofreciendo la posibilidad de realizar pronósticos de futuras observaciones y la modelación de relaciones entre variables (Cochran, 1971). Para aplicar ambas técnicas se utilizaron los datos almacenados en el Sistema de Gestión para Ingeniería Clínica y Electromedicina (SIGICEM). A estos datos se le eliminaron los valores no válidos (la pieza Peltier Element TEC1-127015 es llamada Peltier Element) para mejorar su calidad a través del tiempo. En algunos casos se evidenció información ausente en algunas tuplas de la base de datos, las cuales fueron eliminadas en dependencia del atributo. Sin embargo, en otros casos se sustituyó este por la media o la moda de la clase a la que pertenecía el objeto. Obteniéndose finalmente, una muestra de estos datos, en aras de ganar mayor velocidad de respuesta durante el proceso, quedando las subpoblaciones de equipos homogéneas internamente (N1,N2,…,NL), las cuales no se solapan y en su conjunto comprenden a toda la población (N), por tanto, N1+N2+…+NL=N.
Posteriormente, se procedió a aplicar en cada uno de los estratos el muestreo aleatorio simple (Cochran, 1971). Para determinar la frecuencia de fallas de cada una de las piezas se empleó la media aritmética.
![]()
Algoritmo propuesto
Luego de explicar las técnicas estadísticas utilizadas en el diseño del algoritmo ODS se describe su funcionamiento. Este algoritmo tiene como salida una lista con los stocks de piezas de repuestos predichos según los parámetros recibidos: lista de equipos reportados con fallas o roturas y la lista de piezas.

En el algoritmo, los métodos Calcular_Termino_Dependiente, Calcular_Termino_Independiente, Calcular_Frecuencia_FallasP y Prediccion son métodos dependientes del problema y todos operan según las descripciones dadas al inicio de este acápite. La listaStock almacena las predicciones efectuadas en la ejecución del algoritmo ODS. Este tiene una complejidad O (n).
RESULTADOS Y DISCUSIÓN
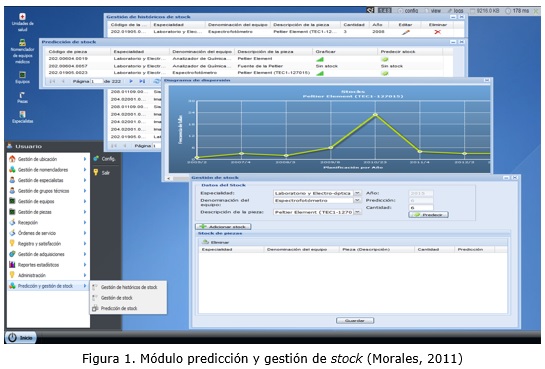
Como aporte práctico de este trabajo se implementó un Módulo que lleva por nombre Predicción y gestión de stock (Ver figura 1), el cual está integrado con el Sistema de Gestión para Ingeniería Clínica y Electromedicina. Este módulo incorpora el algoritmo desarrollado, siendo implementado con el lenguaje PHP 5 (Morales, 2011).
]]> Para validar la efectividad del algoritmo se hace uso del método experimental. En el cual se hizo necesario acotar el marco experimental a 3 equipos médicos pertenecientes a diferentes especialidades electromédicas porque los resultados son generalizables al resto de los equipos de la población en estudio (Morales, 2011).Experimento 1: Aplicar el algoritmo propuesto a los equipos médicos seleccionados.
Objetivo: Mostrar la significación de la relación lineal establecida entre las variables dependiente stock anual e independiente frecuencia de fallas anual.
Equipo 1 ]]>
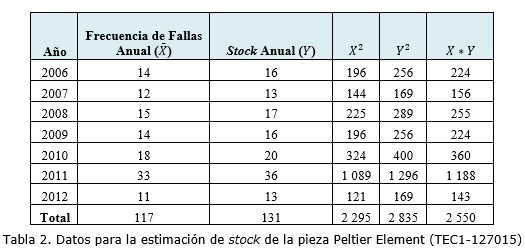
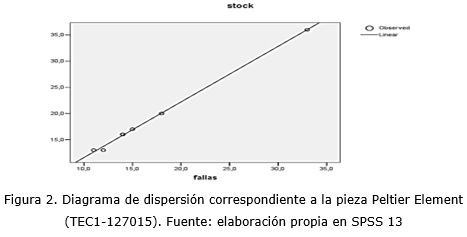
A partir de los datos representados en la tabla 1 se procede al cálculo del coeficiente de correlación lineal: ρxy= 0,99, observándose que existe una fuerte relación lineal entre las variables analizadas (Ver figura 2).
Posteriormente, se estima la ecuación de regresión, a través del cálculo de la pendiente (β1) y el término independiente (β0), obteniendo: β1= 1,06 y β1 = 0,99. Por lo que la recta (ecuación) estimada queda representada como:
Y=0,99+1,06X
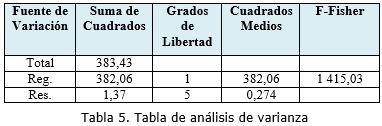
Luego se estima el stock correspondiente al año 2013, determinando la frecuencia de fallas (X) empleando como medida descriptiva la media aritmética, quedando de la siguiente forma: Para una frecuencia de fallas (X) aproximadamente de 17, donde n=7 años la estimación del stock para la pieza Peltier Element (TEC1-127015) es de 19 piezas de repuesto. Después de tener la estimación de la pieza analizada para el año 2013, se procede a calcular la fiabilidad de la predicción a partir de la Dócima de Hipótesis de la Pendiente (Flores et al, 2007). Para ello se debe calcular el coeficiente de determinación (R2) para medir la proporción de la variación total (con respecto a Y).
SCReg. (Suma de Cuadrados de la Regresión) = 382,06
SCRes. (Suma de Cuadrados Residual) = 1,37
Obteniéndose: ![]()
El resultado del coeficiente de determinación (Flores et al, 2007) representa un 99 % de la variabilidad explicada en la recta de regresión, observándose que el valor de este coeficiente es elevado y por tanto el modelo lineal es exacto aproximadamente. Asimismo, se realiza un análisis de varianza aplicando la Dócima de la Pendiente luego del cálculo del coeficiente de determinación (R2), empleando el estadígrafo F-Fisher. ]]>
Dócima de la Pendiente:
Para un nivel de significación de un 5% se tiene como región crítica: ![]()
Finalmente, de acuerdo al resultado se observa que el estadígrafo de prueba no cae en la región crítica, por lo que se rechaza la hipótesis nula, considerándose que la relación lineal establecida es significativa en su aporte a la estimación (Y).
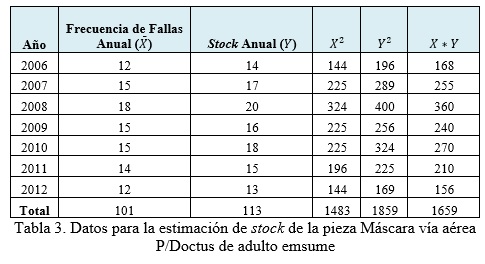
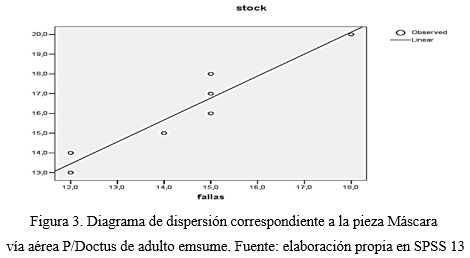
Coeficiente de correlación lineal: ρxy=0,95, observándose que existe una fuerte relación lineal entre las variables analizadas (Ver figura 3).
Ecuación de regresión, teniendo en cuenta el cálculo de la pendiente (β1) y el término independiente (β0):
β1=1,11 y β0=0,12 ]]>
Recta (ecuación) estimada queda:
El stock correspondiente al año 2013, queda de la siguiente forma: Y=0,12+1,11X
Para una frecuencia de fallas (X) aproximadamente de 14, donde n=7 años la estimación del stock para la pieza Máscara vía aérea P/Doctus de adulto emsume es de 16 piezas de repuesto.
Fiabilidad de la predicción a partir de la Dócima de Hipótesis de la Pendiente.
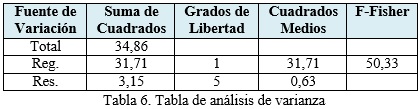
SCT (Suma de Cuadrado Total) = 34.86
SCReg. (Suma de Cuadrado Regresión) = 31,71 ]]>
SCRes. (Suma de Cuadrado Residual) = 3,15
![]()
El resultado del coeficiente de determinación representa aproximadamente un 100 % de la variabilidad explicada en la recta de regresión, observándose que el valor de este coeficiente es elevado y por tanto el modelo lineal es exacto.
Asimismo, se realiza un análisis de varianza aplicando la Dócima de la Pendiente luego del cálculo del coeficiente de determinación (R2), empleando el estadígrafo F-Fisher.
Dócima de la Pendiente:
Hipótesis: H0:β1 = 0 La relación lineal no es significativa en su aporte a la estimación.
H1:β1 ≠0 La relación lineal es significativa en su aporte a la estimación.
Para un nivel de significación de un 5% se tiene como región crítica:
![]()
De acuerdo al resultado se observa que el estadígrafo de prueba no cae en la región crítica, por lo que se rechaza la hipótesis nula, considerándose que la relación lineal establecida es significativa en su aporte a la estimación (y).
Equipo 3
Coeficiente de correlación lineal: ρxy=0,99, observándose que existe una fuerte relación lineal entre las variables analizadas (Ver figura 4).
Ecuación de regresión a través del cálculo de la pendiente (β1) y el término independiente (β0), quedando:
]]>
β1=1,00 y β0=1,71
Por lo que la recta (ecuación) estimada queda: Y=1,71+1,00X
Estimación del stock correspondiente al año 2013:
Para una frecuencia de fallas (X) aproximadamente de 59, donde n=7 años la estimación del stock para la pieza Transductor Endovaginal Endocavitario es de 61 piezas de repuesto.
Fiabilidad de la predicción a partir de la Dócima de Hipótesis de la Pendiente.
Coeficiente de determinación (R2) para medir la proporción de la variación total (con respecto a y).
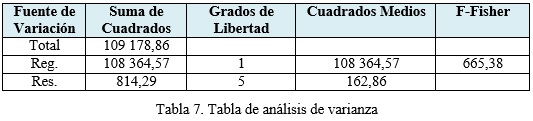
SCT (Suma de Cuadrado Total) = 109 178,86
]]>
SCReg. (Suma de Cuadrado Regresión) = 108 364,57
SCRes. (Suma de Cuadrado Residual) = 814,29
![]()
El resultado del coeficiente de determinación representa aproximadamente un 99 % de la variabilidad explicada en la recta de regresión, observándose que el valor de este coeficiente es elevado y por tanto el modelo lineal es exacto.
Análisis de varianza aplicando la Dócima de la Pendiente luego del cálculo del coeficiente de determinación (R2), empleando el estadígrafo F-Fisher.
Dócima de la Pendiente:
Hipótesis: H0:β1 = 0 La relación lineal no es significativa en su aporte a la estimación.
]]>
H1:β1 ≠0 La relación lineal es significativa en su aporte a la estimación.
Para un nivel de significación de un 5% se tiene como región crítica:
![]()
Finalmente, de acuerdo al resultado se observa que el estadígrafo de prueba no cae en la región crítica, por lo que se rechaza la hipótesis nula, considerándose que la relación lineal establecida es significativa en su aporte a la estimación (y).
Generalización del algoritmo
Experimento 2: Generalizar el algoritmo propuesto.
Objetivo: Optimizar el stock de piezas de repuesto para equipos médicos en los almacenes de electromedicina a partir de la generalización del algoritmo. ]]>
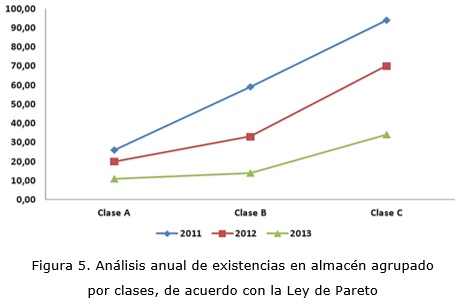
Muestra: Se tomaron 15 equipos pertenecientes a diferentes especialidades electromédicas del Centro Provincial de Electromedicina de la provincia de Pinar del Río. Estos fueron agrupados por clases según la Ley de Pareto (Bonet, 2005). La observación se hizo a partir del año 2011 hasta el 2013(ver tabla 8).
Como se observa en la gráfica (figura 5) representada anteriormente, la generalización del algoritmo permitió que las planificaciones del stock de piezas de repuesto para equipos médicos disminuyeran a partir del año 2012, lo que demuestra una optimización de la planificación según la demanda proyectada y por tanto, favorece a la disminución de ociosos en almacenes, teniendo en cuenta que resulta muy costoso tener inventarios inmovilizados. Por lo que se evidencia el aporte significativo de las variables utilizadas en la predicción (stock anual y frecuencia de fallas anual).
CONCLUSIONES
Según la caracterización del estado actual, en lo relativo a la exactitud de las estimaciones del stock de piezas de repuesto, se concluye que las soluciones consultadas se han enfocado en los pronósticos de la demanda de inventarios de manera general. No se consideran las particularidades asociadas a la predicción del stock de piezas. Además, no satisfacen las necesidades que se tienen en cuanto a su aplicación para la tecnología sanitaria, pues presentan características propias del sector para el cual fueron diseñados. Asimismo, en el análisis crítico efectuado a la revisión bibliográfica se han encontrado pocos referentes que permitan la planificación del stock de piezas de repuesto para la tecnología médica, debido a la diversidad de equipamiento médico con complejas características. La aplicabilidad de las soluciones desarrolladas en la actualidad se ha limitado al sector de la bioingeniería, pues se torna compleja la observación de las interacciones entre las variables que pudieran considerarse en un pronóstico de este tipo.
Por todo lo anteriormente expuesto, se hizo necesaria la realización de un algoritmo que aumente la exactitud de las estimaciones de stock y que permita la optimización de los pedidos según la demanda proyectada.
Al aplicar el algoritmo ODS se evidenció que es significativa en su aporte al a estimación la relación lineal establecida entre las variables dependiente stock anual e independiente frecuencia de fallas anual. De acuerdo a ello, se propone el uso de este en el Módulo Predicción y gestión de stock como herramienta de apoyo para los especialistas de los centros de electromedicina del país para lograr la satisfacción de los reportes por fallas de la tecnología y de los mantenimientos planificados.
]]>REFERENCIAS BIBLIOGRÁFICAS
ARABZAD S. M., GHORBANI M., TAVAKKOLI-MOGHADDAM R. An evolutionary algorithm for a new multi-objective location-inventory model in a distribution network with transportation modes and third-party logistics providers, International Journal of Production Research, vol. 53, pp. 1038-1050, 2014.
BLANCO, L J. La informática en la dirección de empresas, La Habana: Félix Varela, 2011. 334 p.
BONET C. M., Ley de Pareto aplicada a la Fiabilidad, Revista de Ingeniería Mecánica, vol. 8, pp. 1-9, 2005.
CASTILLO P. A. Inventory Pinch Algorithms for Gasoline Blend Planning, AIChE Journal, vol. 59, pp. 3748–3766, 2013.
CHRYSOCHOOU E. C., Ziliaskopoulos A. K., Lois. A. An Exact Algorithm for the Stochastic Inventory Routing Problem with Transhipment, Conference Transportation Research Board 94th Annual Meeting, pp. 15-31, 2015.
COCHRAN W. G. Muestreo Aleatorio Estratificado. En: Técnicas de Muestreo, Compañía Editorial Continental, S.A, México, pp. 125-149, 1971.
COCHRAN W. G. Muestreo Aleatorio Estratificado. En: Muestreo Aleatorio Simple, Compañía Editorial Continental, S.A, México, pp. 41-73, 1971.
FLORES, D., RAMOS, J., SOSA, A. Estadística Descriptiva. Probabilidad y Pruebas de Hipótesis. En: Prueba de Hipótesis, pp. 92-94, 2007.
FLORES, D., RAMOS, J., SOSA, A. Estadística Descriptiva. Probabilidad y Pruebas de Hipótesis. En: Coeficiente de Determinación R2, pp. 137, 2007.
FREUND J., MILLER I., JOHNSON R. Probabilidad y Estadística Para ingenieros. En: Ajuste de Curvas. Tomo II, Editorial Felix Varela, pp. 326-385, 1996.
]]> GEBRESLASSIE B. H., YAO Y., YOU F. Design under uncertainty of hydrocarbon biorefinery supply chains: Multiobjective stochastic programming models, decomposition algorithm, and a Comparison between CVaR and downside risk, Aiche Journal, vol. 58, No. 13844, pp. 2155–2179, 2012.HERNÁNDEZ, D. J. SLD238-SIGICEM: Sistema de Gestión para Ingeniería Clínica y Electromedicina. VIII Congreso Internacional de Informática en la Salud. II Congreso Moodle Salud, pp. 1-9, Febrero 2011.
HERNÁNDEZ R. En: ¿Cómo seleccionar una muestra? Los sujetos-tipo. Tomo I, Editorial Felix Varela, pp.213-236, 2008.
HUBER S., GEIGER M. J., SEVAUX M. Interactive Approach to the Inventory Routing Problem: Computational Speedup Through Focused Search, Logistics Management, pp. 339-353, 2015.
JANA D. K, DAS B, ROY T. K. A Partial Backlogging Inventory Model for Deteriorating Item under Fuzzy Inflation and Discounting over Random Planning Horizon: A Fuzzy Genetic Algorithm Approach, Advances in Operations Research, vol. 2013, No. 973125, 2013.
LAPORTE G., COELHO L. A branch-and-cut algorithm for the multi-product multi-vehicle inventory-routing problem, International Journal of Production Research, vol. 51, pp. 7156-7169, 2013.
LIANGJUN M, ZHANG P, SUN K. Optimization of a Two-Echelon Supply Network Using Multi-Objetive Genetic Algorithms, Computer Science and Information Engineering, IEEE, vol. 5, No. 10794001, pp. 406 – 413, 2009.
MORALES, Z. E. Predicción del stock de piezas de repuesto para equipos médicos [Tesis MSc], Universidad de Camagüey, Camagüey, Cuba, 2011.
NIJU P. J., RADHAMANI G. Determining robust solutions in supply chain using genetic algorithm, Data Storage and Data Engineering (DSDE), IEEE, No. 11260552, pp. 275 – 277, 2010.
SOSA, D. Biblioteca Virtual de Derecho, Economía y Ciencias Sociales. [en línea]. 2009. [Consultado el: 24 de marzo de 2015]. Disponible en: http://www.eumed.net/libros-gratis/2009c/585/Cuba%20y%20el%20uso%20masivo%20de%20las%20TIC.htm
SRIVASTAV A., AGRAWAL. S. Multi Objective Cuckoo Search Optimization for Fast Moving Inventory Items, Advances in Intelligent Systems and Computing, vol. 320, pp. 503-510, 2015.
RAMEZANIAN R., RAHMANI D., BARZINPOUR F. An aggregate production planning model for two phase production systems: Solving with genetic algorithm and tabu search, ScienceDirect Journals, vol. 39, pp. 1256–1263, 2012.
ZHENG Y, TANG L. A Branch-and-Price. Algorithm for the Dynamic Inventory Slab Allocation Problem in the Steel Industry, Computational Sciences and Optimization, IEEE, vol. 2, No. 10817874, pp. 867 – 870, 2009.
]]>
Recibido: 16/02/2015
Aceptado: 13/04/2015