Las alternativas anteriores requieren tablas auxiliares en el DWH para almacenar la información referente a la última fecha en la cual los datos fueron cargados o el último número recuperado de la secuencia (Bouman and Van Dongen, 2009; Casters et al., 2010). Una práctica común es crear estas tablas ya sea en un espacio separado o en el DSA, pero nunca en el almacén o mercado de datos. Esta técnica es considerada por (Bouman and Van Dongen, 2009; Casters et al., 2010) la más simple de implementar; sin embargo, esta simplicidad es discutida, debido a la ausencia de algunas capacidades esenciales que pueden encontrarse en opciones más avanzadas:
- Distinción entre inserciones y actualizaciones: Solamente cuando la fuente de datos contiene dos timestamps, uno para inserciones y otro para las actualizaciones, esta diferencia puede ser detectada.
- Detección de registros eliminados: Esto no es posible, a menos que el sistema fuente sólo borre un registro de forma lógica. La columna tiene una fecha de eliminación pero no está físicamente borrado de la tabla.
- Detección de múltiples actualizaciones: Cuando un registro es actualizado múltiples veces durante el período comprendido entre las cargas inicial y actual, estas actualizaciones intermedias se pierden durante el proceso.
- Capacidades de tiempo real: Timestamp o extracción basada en secuencias de datos es siempre una operación batch y por consiguiente inadecuado para ser usado en tiempo real.
Técnicas de CDC basada en disparadores ]]>
Los disparadores de una base de datos pueden usarse para desencadenar acciones ante la ocurrencia de eventos insert, update o delete (Bouman and Van Dongen, 2009; Casters et al., 2010). Además, pueden utilizarse para capturar los cambios en los datos y colocar los registros cambiados en tablas intermedias en las fuentes, para luego extraerlos o ponerlos directamente en el DSA del DWH. Esta técnica no es implementada muy a menudo porque agregar disparadores a una base de datos se prohíbe por seguridad y eficiencia. Esta técnica es considerada la más intrusiva, pero tiene la ventaja de detectar todos los cambios en los datos, permitir cargas en tiempo real (Bouman and Van Dongen, 2009; Casters et al., 2010) y capturar los cambios en los datos a través de la interfaz ODBC sin necesidad de crear o comprar herramientas especializadas (Eccles, 2013).
Las desventajas de esta técnica son: la necesidad de permisos por parte de los administradores de la base de datos [acrónimo del inglés Database Administrator (DBA)] para poder modificar la fuente, la sintaxis específica de las declaraciones de los disparadores y esto conlleva a un alto costo de procesamiento y espacio de almacenamiento adicional (Bouman and Van Dongen, 2009; Casters et al., 2010). Una alternativa a utilizar los disparadores directamente en las fuentes de datos es establecer una solución de replicación donde todos los cambios detectados en las tablas seleccionadas son duplicados hacia las tablas receptoras en el lado del DWH.
Técnica de CDC basada en snapshot
La técnica snapshot guarda una copia exacta de cada extracción previa en el DSA para su uso futuro y durante la siguiente corrida, el proceso lleva la tabla fuente entera al DSA donde se compara con los datos cargados durante el último proceso (Kimball and Caserta, 2004). Si bien no es la técnica más eficiente, es la más confiable de todas las técnicas incrementales de extracción para capturar cambios en los datos porque hace una comparación fila por fila en busca de cambios y es casi imposible la pérdida de datos. Adicionalmente, tiene la ventaja que las filas borradas en la fuente de datos pueden ser detectadas. Esta técnica, conocida también como snapshot differential, es además apropiada para todos los tipos de fuentes de datos (Jörg and Dessloch, 2008; Jörg and Dessloch, 2009) Castellanos et al. (2009). Según estos autores, los datos extraídos, después de guardados en el snapshot actual Lnew, son comparados contra un snapshot previo (Lold), para discriminar inserciones, eliminaciones y actualizaciones recientes en los registros. Esta comparación es realizada a través de un operador de diferencia, [Diff (Δ)], que revisa en busca de igualdad sólo en un cierto subconjunto de atributos de los registros (generalmente la llave primaria). Considerando A, como un conjunto de atributos y B un subconjunto de estos se pueden encontrar los registros recién insertados, mediante la expresión: ΔB (Lnew, Lold) = ![]() donde b1,…,bn ∈ B.
donde b1,…,bn ∈ B.
Para encontrar un registro actualizado, se considera que para cada registro de Lnew existe un registro en Lold con los mismos valores para B y al menos un atributo perteneciente a A con un valor diferente. (Si A=B entonces se puede utilizar el operador de diferencia de relaciones clásico). Invirtiendo el uso del operador de diferencia, se obtienen los registros borrados. El último paso de esta fase es reemplazar la snapshot Lold con Lnew. Varios métodos pueden servir para eso. Uno de ellos borra la snapshot más antigua y simplemente renombra Lnew como Lold (primero una supresión lógica es realizada para no afectar la carga de trabajo del sistema, y entonces en un punto posterior inactivo, la supresión física se hace). Otro método es actualizar Lold con los registros que cambiaron. El uso de snapshot tiene un doble propósito. Puede ser considerada como una solución de respaldo cuando se cometen errores o servir de DSA. ]]>
Técnicas poco intrusivas
Las técnicas poco intrusivas son aquellas que tienen un bajo impacto en el desempeño de la fuente donde se recuperan los datos.
Técnica de CDC basada en archivos log
La forma más avanzada y menos intrusiva entre las técnicas de CDC es usar una solución basada en archivos log; en los cuales puede ponerse cada operación de inserción, actualización y eliminación manejada en una base de datos (Bouman and Van Dongen, 2009; Casters et al., 2010). Esta técnica es típicamente utilizada en conjunto con Sistemas Gestores de Bases de Datos (SGBD). (Jörg and Dessloch, 2008; Jörg and Dessloch, 2009). Cuando un archivo log es vaciado, todas las transacciones dentro de él son irrescatables. Para evitar esto se aconseja que el DBA cree un archivo log especial específicamente para esta técnica de CDC porque solo se necesitan transacciones para algunas tablas específicas de la base de datos fuente (Kimball and Caserta, 2004). Existen algunas variantes para la implementación de estas técnicas de CDC: log scraping o log sniffing (Kimball and Caserta, 2004). Log scraping analiza gramaticalmente los archivos log y recupera los cambios de interés (Labio and García-Molina, 1995; Labio and García-Molina, 1996; Jörg and Dessloch, 2008; Jörg and Dessloch, 2009; Jörg and Dessloch, 2010). Log sniffing, en contraste, recorta el archivo log y captura los cambios muy de prisa. Mientras estas técnicas tienen poco impacto en la base de datos fuente, implican alguna latencia entre la transacción original y los cambios capturados. Obviamente, esta latencia es más alta para el acercamiento log scraping (Jörg and Dessloch, 2010).
Comparación entre las técnicas de CDC ]]>
La tabla 1 muestra una comparación entre las técnicas CDC analizadas. En la cual se puede apreciar la eficiencia de las técnicas basadas en archivos log y disparadores (triggers) cuando las fuentes son bases de datos. Sin embargo las basadas en snapshot son independientes del DBMS, lo que implica que se puede aplicar en cualquier fuente de datos, además permite distinguir entre actualizaciones e inserciones y es capaz de detectar las eliminaciones. Por tanto la técnica seleccionada para ilustrar el procedimiento de la implementación de procesos ETL para mantener actualizado un DWH o mercado de datos de manera automática es la basada en snapshot.
Uno de los algoritmos más usados para la implementación de esta técnica es el MergeSort (Labio and García-Molina, 1996). Su idea general es tomar dos snapshots, F1 y F2, compararlos y devolver uno nuevo, denominado Fout.
La herramienta PDI en el paso Merge rows (diff) utiliza un algoritmo similar al MergeSort. Este paso toma dos conjuntos ordenados de entrada y los compara en las llaves especificadas (K). Las columnas a ser comparadas pueden ser seleccionadas (B) y debe especificarse un nombre para el campo que contiene la bandera de salida la cual puede tomar uno de los siguientes valores: identical, new, changed o deleted (Casters et al., 2010).
Proceso de transformación
El segundo paso en cualquier proceso ETL es la transformación de los datos (Vassiliadis, 2009). Este paso realiza la limpieza y conformación de los datos entrantes para obtener datos precisos, correctos, completos, coherentes, y no ambiguos. También incluye depuración de datos, su transformación e integración.
]]>
La limpieza es la corrección en los datos de posibles errores, por ejemplo: datos incompletos, duplicados, formatos inconsistentes en cuanto a descripción, abreviaturas y unidades de medidas, falta de datos de entrada o que violen las restricciones de integridad del sistema. Esta etapa es una de las más importantes, ya que garantiza la calidad de los datos en el DWH y en ella se deben corregir las anomalías que se detecten en el proceso de integración de los datos. La calidad de los datos es un término que abarca el estado de los datos, así como el conjunto de procesos para lograrla. Cuando la información se encuentra limpia y con calidad, ésta es unificada, conformada y normalizada. Los indicadores son calculados de una forma racional, lo mismo que los atributos de las dimensiones, para que estén unificados y en todos los sitios donde aparezcan tengan la misma estructura y el mismo significado (Kimball and Caserta, 2004; Díaz et al., 2013).
Proceso de carga
La carga de los datos para la estructura dimensional seleccionada es el paso final del proceso ETL (Vassiliadis, 2009). En este paso, los datos extraídos y transformados son escritos en las estructuras dimensionales a las que acceden los usuarios finales y aplicaciones de software. El paso de carga incluye las tablas de dimensiones y las de hechos.
Carga inicial
En la carga inicial, los datos extraídos y transformados de las fuentes de datos son cargados en el DWH (Jörg and Dessloch, 2009). Este proceso no es complejo de implementar porque el DWH debe estar vacío.
]]>
Carga incremental
Los procesos ETL diseñados para implementar la carga incremental utilizan las técnicas de CDC para capturar los cambios en las fuentes de datos (Jörg and Dessloch, 2008). Durante la misma es necesario tener en cuenta el manejo de las dimensiones lentamente cambiantes [acrónimo del inglés Slowly Changing Dimension (SCD)] que se corresponde con el subsistema nueve de los propuestos por (Kimball and Caserta, 2004; Jörg and Dessloch, 2008).
Las dimensiones SCD pueden cambiar de manera ocasional o constante, siendo de gran importancia el registro de los cambios históricos realizados para mantener la veracidad de la información cargada en el DWH (Tellez et al., 2012). Existen varios tipos de SCD, los más conocidos, estudiados y frecuentes son los tipos 1, 2 y 3 propuestos por (Kimball and Caserta, 2004; Tellez et al., 2012), sin embargo (Ross, 2013) corrobora el uso de los tipos 0, 4, 5, 6 y 7.
RESULTADOS Y DISCUSIÓN
Los procesos de extracción, transformación y carga comprenden varios aspectos que son determinantes en el proyecto de inteligencia de negocio, por lo que para su diseño e implementación se propone seguir un conjunto de pasos para su correcto desarrollo (Villarreal, 2013) usando la técnica CDC basada en snapshot.
Paso 1: Extracción inicial. ]]>
El diseño para implementar la extracción inicial se divide en dos fases (ver figura 1): en la primera, se extraen los datos desde las fuentes de datos hacia el DSA y en la segunda, se extraen los datos del DSA para su utilización por parte del paso de transformación (Mundy, 2008).

Paso 2: Extracción incremental.
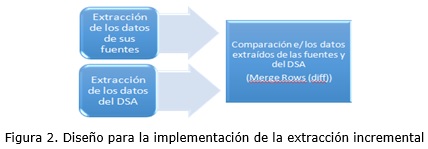
La extracción incremental debe tener en cuenta los datos extraídos de las fuentes y los datos del DSA para luego compararlos mediante el paso Merge Rows (diff), como se muestra en la figura 2.
Paso 3: Transformación.
En el paso de transformación se realiza la limpieza y conformación de los datos. Para ello es necesario realizar un análisis profundo de las fuentes y aplicar transformaciones a cada inconsistencia detectada. Esto es, la ejecución del paso de transformación ya sea por la ejecución del flujo de trabajo de ETL para la carga o por la ejecución de las consultas sobre las fuentes. En la tabla 2 se muestran algunas de las anomalías más frecuentes, se proponen posibles soluciones y se sugieren pasos de la herramienta de integración de datos PDI para su implementación.
La implementación de los procesos ETL para poblar un DWH se basa en lo planteado en el paso 2 y 3 como se aprecia en la figura 3.
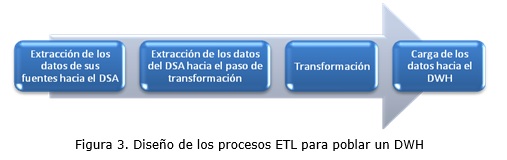
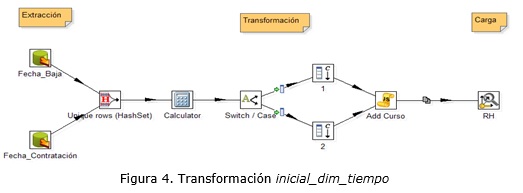
En los procesos ETL diseñados para poblar un DWH, se recomienda utilizar los pasos del software PDI Combination Lookup/Update y Dimension Lookup/Update en las tablas de dimensiones e Insert/Update para las tablas de hechos. Como se aprecia en la figura 3, primero se implementan las transformaciones que extraen los datos de sus fuentes hacia el DSA. Luego se implementan las transformaciones que realizan la extracción de los datos del DSA, su limpieza y homogeneización y la carga dentro del mercado de datos. En la figura 4 se ilustra la transformación inicial_dim_tiempo correspondiente al caso de estudio del mercado de datos Recursos Humanos de la UCLV (García, 2014; Masó and Castellón, 2013) para poblar la tabla de dimensiones Tiempo, que junto a otras, suelen ser orquestadas mediante la implementación de trabajos.
Paso 5: Carga incremental.
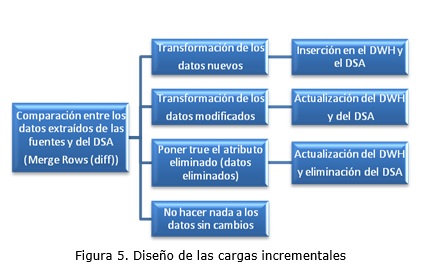
El diseño de los procesos ETL encargados de realizar la carga incremental hacia el DWH es más complejo porque se debe tener en cuenta los tipos de SCD, como se muestra en la figura 5. Los procesos ETL diseñados para realizar la carga incremental hacia el DWH utilizan los pasos del software PDI Combination Lookup/Update, Dimension Lookup/Update y Update para el tratamiento de los tipos de SCD.
La figura 7 muestra la implementación de una de las sub-transformaciones implementadas en dicho caso de estudio denominada subtransformación_dim_persona.
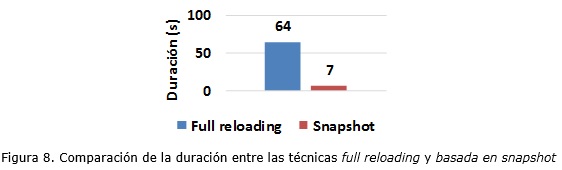
1.6 Comparación entre las técnicas full reloading y basada en snapshot.
Con el objetivo de evaluar el rendimiento de las técnicas full reloading y basada en snapshot, se realiza una comparación en cuanto a duración entre las transformaciones inicial_dim_persona (full reloading) e incremental_dim_persona (basada en snapshot) ejecutadas para capturar cambios en los datos luego de la carga inicial. En la figura 8 se aprecia como la duración de la técnica basada en snapshot muestra una reducción significativa con respecto a full reloading. Esta diferencia puede aumentar en la medida que aumenten los registros de las fuentes utilizadas. Los beneficios de la técnica basada en snapshot comparada con full reloading son dobles: primero, el volumen de datos cambiados en las fuentes es muy pequeño comparado con el volumen global y por otra parte, la mayoría de los datos dentro del DWH permanecen ilesos durante la carga incremental, ya que los cambios son sólo aplicados donde son necesarios.
CONCLUSIONES
Los procesos ETL son el centro del almacén de datos y su calidad es de importancia significativa para la exactitud, operatividad y usabilidad. Por razones de eficiencia los DWH son típicamente actualizados de forma incremental, es decir, los cambios son capturados en las fuentes y propagados para el DWH regularmente. Es por ello, que se considera de importancia vital las técnicas de CDC. En el presente trabajo, dichas técnicas se caracterizan de acuerdo con la clasificación de intrusivas y poco intrusivas, se comparan y se selecciona como la más apropiada para implementar los procesos ETL la basada en snapshot. La técnica escogida permite realizar una comparación fila a fila evitando la pérdida de información, se puede aplicar a cualquier tipo de fuente de datos, distingue entre inserciones y actualizaciones y detecta las eliminaciones. Además se propone un conjunto de pasos a seguir para aplicar dicha técnica a un problema real. No obstante, a la simplicidad teórica que presenta el snapshot, la extracción de los datos continúa siendo un problema difícil debido mayormente a la naturaleza heterogénea de las fuentes, lo cual afecta al rendimiento de la integración de los datos y plantea campos de investigación abiertos.
]]> REFERENCIAS BIBLIOGRÁFICAS
BERSON, A. & SMITH, S. J. 1997. Data Warehousing, Data Mining, and OLAP, McGraw-Hill, Inc.
BOUMAN, R. & VAN DONGEN, J. 2009. Pentaho Solutions: Business Intelligence and Data Warehousing with Pentaho and MySQL, Indianapolis, Indiana, Wiley Publishing, Inc.
CASTELLANOS, M., SIMITSIS, A., WILKINSON, K. & DAYAL, U. 2009. Automating the Loading of Business Process Data Warehouses. Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology. ACM.
]]>
CASTERS, M., BOUMAN, R. & VAN DONGEN, J. 2010. Pentaho Kettle Solutions: Building Open Source ETL Solutions with Pentaho Data Integration, Indianapolis, Indiana, Wiley Publishing, Inc.
DÍAZ, L., LÓPEZ, B., GONZÁLEZ, L., GALINDO, Y. & LÓPEZ, D. 2013. Integración de Datos. “Universidad Central “Marta Abreu” de las Villas”.
ECCLES, M. J. 2013. Pragmatic Development of Service Based Real-Time Change Data Capture. Aston University.
EL-SAPPAGH, S. H. A., HENDAWI, A. M. A. & EL BASTAWISSY, A. H. 2011. A proposed model for data warehouse ETL processes. Journal of King Saud University-Computer and Information Sciences, 23, 91-104.
GARCÍA, J. L. 2014. Automatización de los procesos de carga en el mercado de datos Recursos Humanos de la UCLV. Universidad Central “Marta Abreu” de Las Villas. ]]>
JÖRG, T. & DESSLOCH, S. 2008. Towards generating ETL processes for incremental loading. In: DESAI, B. C. (ed.) Proceedings of the 2008 international symposium on Database engineering & applications. Coimbra [Portugal]: ACM.
JÖRG, T. & DESSLOCH, S. 2009. Formalizing ETL Jobs for Incremental Loading of Data Warehouses.
JÖRG, T. & DESSLOCH, S. 2010. Near Real-Time Data Warehousing Using State-of-the-Art ETL Tools. Enabling Real-Time Business Intelligence, Lecture Notes in Business Information Processing. Springer-Verlag Heidelberg.
KIMBALL, R. & CASERTA, J. 2004. The Data Warehouse ETL Toolkit, Indianapolis, Indiana, Wiley Publishing, Inc.
KIMBALL, R., REEVES, L., ROSS, M. & THORNTHWAITE, W. 1998. The Data Warehouse Lifecycle Toolkit: Expert Methods for Designing, Developing, and Deploying Data Warehouses, Indianapolis, Indiana, Wiley Publishing, Inc.
KIMBALL, R. & ROSS, M. 2002. The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling, New York, John Wiley and Sons, Inc.
KIMBALL, R., ROSS, M., THORTHWAITE, W., BECKER, B. & MUNDY, J. 2008. The Data Warehouse Lifecycle Toolkit, John Wiley & Sons.
LABIO, W. J. & GARCÍA-MOLINA, H. 1995. Comparing very large database snapshots. Stanford University.
LABIO, W. J. & GARCÍA-MOLINA, H. 1996. Efficient Snapshot Differential Algorithms for Data Warehousing. Proceedings of VLDB ’96.
MASÓ, A. & CASTELLÓN, Y. 2013. Mercado de datos en apoyo a la toma de decisiones sobre el personal docente e investigativo en el departamento de Recursos Humanos de la UCLV.
Universidad Central “Marta Abreu” de Las Villas.
MUNDY, J. 2008. Design Tip #99 Staging Areas and ETL Tools. Available: http://www.kimballgroup.com/2008/03/04/design-tip-99-staging-areas-and-etl-tools/ .
RAM, P. & DO, L. 2000. Extracting Delta for Incremental Data Warehouse Maintenance. Proceedings. 16th International Conference on Data Engineering (ICDE). IEEE.
ROSS, M. 2013. Design Tip #152 Slowly Changing Dimension Types 0, 4, 5, 6 and 7. Available: http://www.kimballgroup.com/2013/02/05/design-tip-152-slowlychanging-dimension-types-0-4-5-6-7/ .
TELLEZ, Y., MEDINA, D. & TORRES, R. E. 2012. Propuesta para la Implementación de las Dimensiones Lentamente Cambiantes con Pentaho Data Integration.
VASSILIADIS, P. 2009. A survey of Extract–transform–Load technology. International Journal of Data Warehousing & Mining, 5, 1-27.
VILLARREAL, R. X. 2013. Estudio de metodologías de Data Warehouse para la implementación de repositorios de información para la toma de decisiones gerenciales., Universidad Técnica del Norte.
YUAN, G., LI, B. & XIAO, T. 2011. Improvement of Snapshot Differential Algorithm Based on Hadoop Platform. Cross Strait Quad-Regional Radio Science and Wireless Technology Conference (CSQRWC). IEEE.
Recibido: 28/08/2014
Aceptado: 22/06/2015