MFuzzyPred : Algoritmo Multi-objetivo para extraer predicados difusos
MfuzzyPred: Multi-objective algorithm for extracting fuzzy predicates
Dailé Osorio Roig1*, Orenia Lapeira Mena2, Taymi Ceruto Cordovés2, Alejandro Rosete Suárez2.
1 Centro de Aplicaciones de Tecnologías Avanzadas, 7ª A #21406 esq. 216, Rpto. Siboney, Playa. C.P. 12200, La Habana, Cuba.
2 Facultad de Ingeniería Informática, Instituto Superior Politécnico “José Antonio Echeverría” (CUJAE), 114 # 11901 e/ Ciclovía y Rotonda, Marianao, La Habana, Cuba.
RESUMEN
En el Instituto Superior Politécnico “José Antonio Echeverría” (CUJAE) se propuso un método para el descubrimiento de predicados difusos en forma normal en bases de datos, utilizando metaheurísticas. Este método responde a un problema de optimización combinatorio, que hoy solo maximiza un único objetivo: el valor de verdad del predicado. Esta medida de calidad tiene algunas limitaciones de cara a la posterior toma de decisiones y es por ello que recientemente se han propuesto otras medidas para evaluar la calidad de los predicados. Este trabajo toma como antecedente este método, pero lo convierte en un problema de optimización multiobjetivo (optimizar varias funciones objetivos a la vez) que contribuye a una mejora en los resultados. Los experimentos efectuados y el análisis de los mismos, así lo confirman.
Palabras clave: Predicados Difusos, Metaheurísticas, Medidas de Calidad, Optimización multiobjetivo.
ABSTRACT
In the Higher Technical Institute "José AntonioEcheverría"(CUJAE) was proposed a method for discover fuzzy predicates in normal form in databases, using metaheuristic. This method answers to a combinatorial problem of optimization, that today it only maximizes a unique objective: the truth value of the predicate. This quality measure has some limitations, to take some decision later and for that reason other measures have recently proposed to evaluate the quality of the predicates. This paper takes this method like antecedent, but turns it into a multi-objective problem of optimization (optimizing several objective functions at the same time) that contributes to an improvement in the results. The executed experiments and the analysis of the them, confirm it.
]]>
Keywords: Fuzzy Predicates, Metaheuristics, Quality Measures, Multi-objective optimization.
INTRODUCCIÓN
La necesidad de procesar grandes volúmenes de datos ha motivado el desarrollo de técnicas y herramientas que posibiliten la extracción de conocimiento de dichos datos (Hernández & et al., 2004). Es por esto que surgen los sistemas de extracción de información útil y comprensible desde diversas fuentes de datos, que han sido utilizados en muchas aplicaciones de la vida real. El descubrimiento de relaciones entre variables es una de las técnicas de la minería de datos que más ha sido utilizada para extraer conocimiento interesante a partir de sistemas de datos muy grandes.
El proceso de descubrimiento de conocimiento en bases de datos (Knowledge Discovery in Databases, KDD) consta de varias etapas, que transcurren desde la preparación de los datos, hasta la presentación de los resultados obtenidos. Dentro de estas etapas se encuentra la Minería de Datos (Data Mining, DM), la cual puede definirse como el proceso no trivial de extracción de información implícita, previamente desconocida y potencialmente útil, a partir de datos (Fayyad & et al., 1996).
FuzzyPred es un método de DM propuesto en el año 2010 en el Instituto Superior Politécnico “José A. Echeverría” como resultado de una tesis de maestría (Ceruto, 2010). Este método tiene como objetivo la obtención de predicados difusos y está modelado como un problema de optimización combinatoria monobjetivo (aplica una sola métrica para conocer cuan bueno o cuan malo puede ser el patrón obtenido). Para realizar el proceso de búsqueda utiliza algoritmos metaheurísticos, los que serán encargados de explotar y explorar el espacio de búsqueda una vez modelado el problema. Para la representación de sus modelos, utiliza la Forma Normal Conjuntiva (FNC) y Disyuntiva (FND), en combinación con diferentes modificadores lingüísticos (Ceruto & et al., 2013).
Actualmente en FuzzyPred la única métrica de calidad que se utiliza es el valor de verdad del predicado. Esta métrica presenta algunas limitantes, que están asociadas al criterio del veto (hace cero la conjunción de varios valores, si uno de ellos es cero) y al uso del cuantificador universal (restringe el resultado al tratar de que todos cumplan la condición a través de una conjunción). La presencia de cada uno de estas limitaciones, trae como consecuencia que muchos predicados que si son buenos, sean desechados por el algoritmo. Por esta razón fueron propuestas con posterioridad otras medidas de calidad que ayudan a mitigar los problemas antes mencionados, pero la búsqueda se continúa guiando por un único objetivo (Ceruto & et al., 2014).
Por esta razón se decidió desarrollar el método MFuzzyPred, donde la evaluación obtenida no se basa únicamente en el valor de verdad, sino que incorpora otras métricas de calidad. Para la generación y búsqueda de cada predicado se utilizaron procedimientos metaheurísticos de naturaleza multiobjetivo. Esta variante permite a los usuarios poder guiar la búsqueda basándose en otras métricas, brindándole a cada una la misma importancia.
]]> En la siguiente sección se abordan las distintas técnicas de optimización, por la importancia que las mismas revisten en la propuesta que en este trabajo se presenta. Los elementos que caracterizan a MFuzzyPred se describen en la sección 2. La sección 3 muestra los resultados experimentales sobre la bases de datos Basketball y Stock del repositorio UCI, además se muestra un análisis de las pruebas estadísticas no paramétricas para observar el comportamiento de las metaheurísticas. Finalmente, en la sección 4 se muestran algunas conclusiones a las que se pudo arribar luego de realizados los experimentos.
MATERIALES Y MÉTODOS
Optimización
La optimización es una rama de la matemática que intenta dar respuesta a un tipo general de problemas matemáticos donde se desea elegir el mejor conjunto de soluciones (Hillier & Lieberman, 2006). Se encuentra relacionada a la Investigación de Operaciones, Inteligencia Artificial, Ingeniería de Software, Teoría de Algoritmos y la Teoría de la Complejidad Computacional. En un problema de optimización combinatoria existen diversas soluciones optimizando la función objetivo, donde el objetivo a seguir es encontrar cuál solución puede ser la mejor (Sunar & Kahraman, 2001; Coello & Veldhuizen, 2007; Boussaïd & Lepagnot, 2013).
Existen dos tipos de problemas de optimización: los mono-objetivos y los multi-objetivos, la diferencia entre estos es en el número de objetivos. En el caso de los problemas mono-objetivos buscan obtener el mejor diseño o decisión, o sea un máximo o un mínimo en dependencia de cómo se va a optimizar (maximizar o minimizar) (Boussaïd & Lepagnot, 2013). Un ejemplo clásico puede ser que se requiere hacer un programa que sea rápido y eficiente, en este caso existirían dos funciones a tener en cuenta, tiempo de respuesta y eficacia, este problema necesita poder optimizar cada una de sus funciones objetivos con la misma importancia. Debido a la necesidad de poder optimizar a la vez más de una función objetivo y de esta manera obtener más de una solución factible, surgen los problemas de optimización multiobjetivo.
Técnicas de optimización Multi-Objetivos
En los problemas de optimización multiobjetivo existen diversas maneras de representar las preferencias del decisor (Coello & Veldhuizen, 2007). Algunas de las técnicas más simples proponen transformar el problema multi-objetivo en un problema escalar, ponderando las funciones objetivos, como es el caso del método combinación lineal de pesos. Otros proponen, tratar el problema como mono-objetivo seleccionando solo una de las funciones objetivos y tratando las restantes como restricciones o considerar varios objetivos simultáneamente. Los problemas de optimización multiobjetivo no obtienen como resultado de la búsqueda una única solución, sino un conjunto de soluciones, por lo que requieren del decisor para elegir una de las soluciones del conjunto.
Óptimo de Pareto:Una solución x є Ω es llamada óptimo de Pareto con respecto a Ω si y solo si, no existe x´ є Ω para el domina a ![]() . Es decir x´ es un óptimo de Pareto si no existe ningún vector factible x que disminuya algún criterio sin causar un aumento simultáneo en al menos uno de los otros criterios.
. Es decir x´ es un óptimo de Pareto si no existe ningún vector factible x que disminuya algún criterio sin causar un aumento simultáneo en al menos uno de los otros criterios.
Dominancia de Pareto:Un vector u = (u1,…,uk) se dice que domina a otro vector v = (v1,…,vk) si y solo si u es parcialmente menor que v (denotado por u <= v). En otras palabras, x domina a y si x es mejor que y en al menos una de las funciones objetivos y no es peor en ninguna de las restantes.
En la Figura 1 se muestra un ejemplo de cómo es aplicada esta técnica en un Problema de Optimización Multiobjetivo que propone maximizar dos funciones objetivo f1 y f2, donde los puntos (X, Y, Z) son todas las soluciones posibles de las funciones a maximizar. Se observa que X y Y son soluciones no dominadas entre sí, ya que supera a Y en f2 pero Y supera a X en f1, es decir cada una se supera en una función objetivo y Z está dominada por X, debido a que X es mejor que Z en ambas funciones objetivos, Z supera a X en f2 y Y supera a Z en f1 pero como X ya había superado a Z en ambas, Z es una solución dominada, por lo que X y Y son parte de las soluciones óptimas de Pareto (soluciones no dominadas).
RESULTADOS Y DISCUCIÓN
]]>
Como resultado de la Evaluación del Desempeño de roles, actividad que se deberá realizar de forma sistemática, es posible obtener numerosos y valiosos indicadores, entre estos se encuentran: las variables que miden la calidad de los artefactos elaborados (como resultado de la evaluación de las habilidades técnicas) y las variables que miden las habilidades genéricas desarrollas por los estudiantes durante su formación. Estos indicadores deberán ser analizados en profundidad con el propósito de:
La minería de datos, enriquece el proceso de análisis, descubriendo relaciones ocultas entre los datos e información desconocida; por lo que se propone la aplicación de técnicas de minería de datos para el análisis de dichos indicadores. Para ello, es necesario realizarlas siguientes tareas: definir las variables a utilizar en la minería de datos, definir la variable objetivo y seleccionar las técnicas de minería de datos a ser empleadas.
Aplicación de la Minería de Datos: definición de las variables para la minería de datos
Previo a la definición de las variables de entrada para la aplicación de las técnicas de minería de datos, es conveniente detallar los objetivos que se persiguen con el análisis de los datos disponibles. Estos objetivos son los siguientes:
A partir de los objetivos planteados, es posible definir los siguientes grupos de variables a utilizar en la minería de datos:
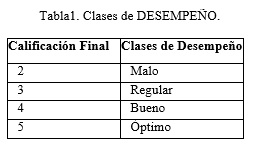
En correspondencia con los objetivos planteados anteriormente, se define “DESEMPEÑO” como variable objetivo, a partir de la Valoración Final y la Calificación Final:
La variable objetivo DESEMPEÑO Valoración Final, según la propuesta, toma valores nominales (Óptimo, Bueno, Regular, Malo); mientras que, la variable objetivo DESEMPEÑO Calificación Final, toma valores numéricos (5, 4, 3, 2), por lo que, en este caso, se decidió categorizar dicha variable como se muestra en la tabla 1:
Una vez definidos los objetivos y las variables necesarias, es preciso seleccionar las técnicas y algoritmos de minería de datos a emplear.
Selección de técnicas de Minería de Datos y herramientas
Para cumplir los objetivos antes enunciados se propone la aplicación conjunta de las siguientes técnicas de minería de datos: Clustering o agrupamiento, Determinar grupos afines o reglas de asociación y Clasificación (HAN, 2006) (HERNANDEZ, 2004) (WITTEN, 2005) (SUGANTHI, 2014) (LIAO, 2012) SREEVIDYA, 2014) (WESLEY, 2013) (FOSTER, 2013) (ZAKI, 2014).
Para la implementación de la propuesta de análisis de la calidad del proceso de formación de roles en la carrera de ingeniería informática, se propone un sistema que integra las herramientas: EvalSoft y KNIME (Konstanz Information Miner).
EvalSoft se encarga de automatizar las fases de recopilación, preparación y pre-procesamiento de los datos, con el objetivo de proporcionarle a una herramienta de minería de datos, las fuentes de datos necesarias para la aplicación de las técnicas de minería de datos seleccionadas (WILFORD, 2006).
KNIME es una plataforma de exploración de datos modular que guía el proceso de descubrimiento de conocimiento en bases de datos. Fue desarrollada originalmente en el departamento de bioinformática y minería de datos de la Universidad de Constanza, Alemania. Es una herramienta de código abierto, multiplataforma, y compuesta por módulos ensamblables que permiten extenderla. Se basa en el diseño de flujos de trabajo (workflows) de forma visual, y permite además ejecutar selectivamente algunos o todos los pasos de análisis, para luego investigar los resultados a través de vistas interactivas de los datos y modelos (BERTHOLD, 2007).
El sistema propuesto permitirá identificar las fortalezas y debilidades de la carrera en relación al proceso de formación de los roles que precisa la Industria Nacional de Software, así como descubrir posibles relaciones entre las variables definidas, ayudando a proponer mejoras con el objetivo de perfeccionar la enseñanza de la ingeniería informática en Cuba.
CONCLUSIONES
Actualmente se trabaja en la actualización de las listas de chequeo a utilizar para evaluar la calidad de los artefactos creados por los estudiantes en cada corte evaluativo de las asignaturas. Una vez que se disponga de las listas de chequeo actualizadas se procederá a aplicar la propuesta mediante un caso de estudio. En trabajos futuros se pretende analizar resultados experimentales que permitan valorar la aplicabilidad del sistema propuesto y de las técnicas de minería de datos seleccionadas.
REFERENCIAS BIBLIOGRÁFICAS
FERNÁNDEZ, JA Páramo. 2014 La arteriosclerosis en el siglo XXI. Angiología, 2014, vol. 66, no 3, p. 109-111.
]]>
HARWELL, T. S., OSER, C, S., OKON, N. J. HELGERSON, S. D., GOHDES, D. 2005 Defining Disparities in Cardiovascular Disease for American Indians Circulation, 2005, 112 (15): p. 2263-2267.
NASIFF, A. Las lipoproteínas en el riesgo de enfermedad coronaria. En: Intervencionismo Cardiovascular 2009. La Habana: 2009.
PÉREZ DEL TORO, J. M. Simposio: Intervencionismo Coronario Percutáneo en el Síndrome Coronario Agudo sin elevación del ST. En: Intervencionismo Cardiovascular 2009. La Habana: 2009.
POLONSKY, TAMAR S., MCCLELLAND, ROBYN L., JORGENSEN, NEAL W., BILD, DIANE E., BURKE, GREGORY L., GUERCI, ALAN D., GREENLAND, PHILIP. Coronary artery calcium score and risk classification for coronary heart disease prediction. Jama, 2010, p. 1610-1616. ]]>
AGATSTON, A. S., JANOWITZ, W. R., HILDNER, F. G., ZUSMER, N. R., VIAMONTE, M., DETRANO, R 1990 Quantification of coronary artery calcium using ultrafast computed tomography. Journal of the American College of Cardiology, 1990, 15 (4): p. 827-832.
LLERENA ROJAS, L. R. 2010 Aspectos polémicos, limitaciones y perspectivas del estudio de las arterias coronarias por tomografía computarizada. Revista Cubana de Cardiología y Cirugía Cardiovascular, 2010, 16(2): p. 118-122.
MENDOZA RODRÍGUEZ, V.; LLERENA ROJAS, L. R.; TORRES MIRANDA, S.; OLIVARES AQUILES, E. W.; CABRERA REGO, J. O.; FERNÁNDEZ HERRERA, K.; LINARES MACHADO, R. 2010 Utilidad del score de calcio en el diagnóstico de enfermedad coronaria obstructiva. Revista Cubana de Investigaciones Biomédicas, 2010, 29 (4): p. 403-416.
KEMMER, N.; CASE, J.; CHANDNA, S.The Role of Coronary Calcium Score in the Risk Assessment of Liver Transplant Candidates. En Transplantation Proceedings. Elsevier, 2014. p. 230-233.
DIRECCIÓN DE REGISTROS MÉDICOS Y ESTADÍSTICAS DE SALUD. Anuario Estadístico de Salud 2013. [En línea]. Estadísticas de Salud. 2014, [Consultado el: 10 de junio de 2014]. Disponible en: http://www.sld.cu/sitios/dne/ ]]>
OBREGÓN SANTOS, ÁNGEL G. Entrevista realizada por A. Rodríguez Bonet, La Habana, 2009.
MÉNDEZ PERALTA, T. Entrevista realizada por A. Rodríguez Bonet, La Habana, 2009.
GARCÍA BAYATE, ELOY. Algoritmo para la Identificación de Calcificaciones en las Arterias Coronarias. Trabajo de Diploma. Universidad de las Ciencias Informáticas. La Habana. 2012.
STANFORD, W., THOMPSON, B. H., BURNS, T. L., BURR, M. C. Coronary Artery Calcium Quantification at Multi-Detector Row Helical versus Electron-Beam CT. 2004.
]]>
SIRAKOV, NIKOLAY M. 2006 A new active convex hull model for image regions. Journal of Mathematical Imaging and Vision, 2006, 26 (3): p. 309-325.
MENDOZA RODRÍGUEZ, V. Entrevista realizada por A. Rodríguez Bonet, La Habana, 2009.
Recibido: 05/01/2015
Aceptado: 20/02/2015