MPREDSTOCK : Modelo multivariado de predicción del stock de piezas de repuesto para equipos médicos
MPREDSTOCK : Multivariate prediction model stock of spare parts for medical equipments
Zoila Esther Morales Tabares1*,Alcides Cabrera Campos1, Efrén Vázquez Silva2, Yailé Caballero Mota3
1Universidad de las Ciencias Informáticas. La Habana, Cuba. C.P.:19370. zemorales@uci.cu, alcides@uci.cu
2Universidad Politécnica Salesiana. Cuenca, Ecuador. C.P.:010102. evazquez@ups.edu.ec ]]>
*Autor para la correspondencia: zemorales@uci.cu
RESUMEN
La demanda del stock de piezas de repuesto es una de las mayores fuentes de incertidumbre y la selección del mejor método de predicción para cada referencia es un problema complejo. Los métodos a utilizar en su pronóstico se seleccionan de acuerdo a la cantidad de datos y los diferentes patrones de comportamiento. En la última década el desarrollo de modelos matemáticos para el pronóstico de la demanda de piezas de repuesto ha dado proyección a un sin número de aplicaciones en diversas esferas de la sociedad, con la utilización de técnicas de análisis de series de temporales, métodos causales de regresión y técnicas de Soft-Computing. Sin embargo, se ha observado la carencia de aplicaciones prácticas para el pronóstico del stock de piezas de repuesto de equipos médicos, en relación con las proposiciones teóricas relevantes desarrolladas en esta área de aplicación. Además, las soluciones existentes no siempre logran mejorar la exactitud de los pronósticos, debido a la preferencia por la utilización de métodos de alta complejidad. En la presente investigación se propone el modelo MPREDSTOCK para el proceso de predicción del stock de piezas de repuesto para equipos médicos mediante la Regresión Lineal Múltiple como método de solución. El modelo incluye algoritmos que permiten la predicción del stock de piezas y disponibilidad técnica de un equipo médico, el cálculo de su confiabilidad operacional y la frecuencia de fallas de una de sus piezas y forma parte del “Módulo Predicción y gestión de stock” del SIGICEM.
Palabras clave: stock de piezas de repuesto, pronóstico de la demanda, modelo, exactitud.
ABSTRACT
]]> The demand for the stock of spare parts is one of the largest sources of uncertainty and selecting the best prediction method for each reference is a complex task. The methods to use in the prognosis are selected according to the amount of data and the different behavior patterns. In the last decade, the development of mathematical models for predicting the demand for spare parts has opened a path for several applications in different areas of society, using techniques for analyzing series of temporal, causal regression methods and Soft-Computing techniques. However, it has been observed a lack of practical applications for making a prognosis of the stock of spare parts for medical equipment, in relation to the relevant theoretical proposals developed in this application area. In addition, existing solutions do not always manage to improve the accuracy of the prognosis, due to the preference for the use of highly complex methods. In this research paper, the MPREDSTOCK model is proposed. It is responsible for the process of predicting the stock of spare parts for medical equipment through the multiple linear regressions as the method of solution. The model includes algorithms for predicting the stock of parts and technical availability of a piece of medical equipment, the calculation of operational reliability and failure frequency of one of its devices and it is part of the " Prediction and stock management Module " belonging to the SIGICEM.Key words: demand forecasting, stock of spare parts, model, accuracy.
INTRODUCCIÓN
El pronóstico de la demanda del stock de piezas de repuesto juega un papel fundamental en la estrategia de numerosas organizaciones de manufactura o servicios. En cualquier sector de la sociedad, las piezas necesarias para el mantenimiento pueden ser difíciles de adquirir, por limitaciones de presupuesto o dificultades cuando son compradas en el exterior. En este sentido, se han desarrollado soluciones (Cruz et al., 2014; Saleh, 2014) para el pronóstico de la demanda de piezas de repuesto a pesar de ser un proceso complejo, debido a su comportamiento intermitente (Syntetos et al., 2015).
Existen diversos métodos para estimar la demanda intermitente, los cuales se seleccionan en dependencia de la cantidad de datos y los diferentes patrones de comportamiento. Estos métodos se clasifican en: cualitativos y cuantitativos. En los últimos años, se han aplicado ambos tipos de métodos para pronosticar la demanda en diversas áreas. Métodos sencillos y elementales como las medias móviles o alisado exponencial hasta otros sofisticados y complejos, de tipo causal como los de regresión y técnicas de soft-computing: lógica difusa, algoritmos genéticos y redes neuronales artificiales (Chackelson, 2013). En la literatura no existe un consenso sobre qué método es mejor que otro; simplemente depende de cada situación. No obstante, algunos investigadores han realizado grandes esfuerzos en la búsqueda de un método óptimo para predecir la demanda intermitente (Petropoulos and Kourentzes, 2014; Syntetos et al., 2015; Hemeimat et al., 2016).
Todo pronóstico lleva implícito un margen de error y en dependencia de su magnitud, será el grado de exactitud de la estimación. Para cuantificar las mejoras obtenidas en un pronóstico se aplican diversos indicadores definidos en la literatura a nivel mundial (Corres et al., 2014): error estándar de la estimación (SEE), desviación media absoluta (MAD), error cuadrático medio (RMSE), porcentaje del error medio absoluto (MAPE), error medio absoluto (MAE), desviación Standard (SD), entre otros. Algunos indicadores son medidos de acuerdo al método de pronóstico empleado, como es el caso de los métodos cuantitativos de tipo causal, en los que se mide el coeficiente de determinación corregido ![]()
En la última década el desarrollo de modelos matemáticos para el pronóstico de la demanda, ha dado proyección a un sin número de aplicaciones informáticas en diversas esferas de la sociedad: la industria petroquímica, la aviación, telecomunicaciones, empresas de ventas y distribución de automóviles, industria minera del cobre, entre otras (Godoy, 2008; Huang et al., 2010; Jianfeng et al., 2011; Rosas and Cortes, 2013; Frazzon et al., 2014; Vasumathi and Saradha, 2015). Sin embargo, se ha denotado la carencia de aplicaciones prácticas para el pronóstico del stock de piezas de repuesto de equipos médicos, en relación con las proposiciones teóricas relevantes desarrolladas para el proceso de pronóstico de la demanda de piezas de repuesto.
Los dispositivos médicos son bienes con un efecto directo sobre la vida humana. Exigen una inversión considerable y muchas veces tienen altos costos de mantenimiento. Por lo que es importante contar con un programa de mantenimiento planificado y gestionado adecuadamente, ya que los recursos necesarios para el mantenimiento son difíciles de proyectar. Para hacerlo se requieren antecedentes de mantenimiento y conocimiento acerca de cuándo un equipo puede fallar (OMS, 2012). En este sentido, autores como Godoy (2008), Huang y otros (2010) y Jianfeng y otros (2011) desarrollaron sus modelos de pronóstico a partir de indicadores que se relacionan con las actividades de mantenimiento, como: confiabilidad operacional, probabilidad de fallas, consecuencias de no disponibilidad, costo unitario de las piezas, entre otros. Aunque en la literatura se propone junto a estos últimos: el tiempo medio entre fallas (MTBF), tiempo medio de reparo (MTTR) y disponibilidad técnica (Azoy, 2014).
]]> En la planificación de un programa de mantenimiento es posible prever qué piezas será necesario reemplazar y con qué frecuencia, consultando las recomendaciones del fabricante. Aunque la demanda de piezas de repuesto para equipos médicos puede variar, con relación a las condiciones geográficas que presenta cada región, de acuerdo a la localización de la institución de salud o por otras causas de índole social o político (Rosas and Cortes, 2013).El Centro Nacional de Electromedicina (CNE), centro rector normativo metodológico del Sistema Nacional de Salud (SNS), ha realizado pronósticos visionarios junto al método de regresión lineal simple (LRS) para la predicción del stock de piezas de repuesto en equipos médicos (Morales, 2011). Para los pronósticos visionarios, los especialistas del CNE se apoyan en las prescripciones de los fabricantes de los equipos, más la experiencia adquirida en la gestión de las tecnologías de atención sanitaria. Muchas de las compras de piezas de repuesto se han realizado con un estimado que no se ajustan a la realidad nacional, lo cual conlleva al fracaso en la etapa de aplicación. Por este motivo, con los métodos actuales de automatización del pronóstico no se han obtenido los resultados esperados en cuanto a la mejora de la exactitud de las predicciones.
En correspondencia con los planteamientos anteriores, se trazó como objetivo general: desarrollar un modelo multivariado que mejore la exactitud de las predicciones del stock de piezas de repuesto para equipos médicos. Para alcanzar el objetivo propuesto y teniendo como base el problema a resolver, se formuló la siguiente hipótesis: la fundamentación y aplicación de un modelo multivariado para la predicción del stock de piezas de repuesto para equipos médicos contribuirá a la mejora de la exactitud del pronóstico.
MATERIALES Y MÉTODOS
La demanda se pronostica según la disponibilidad de datos históricos a partir de la utilización de métodos cualitativos y cuantitativos. Los métodos cualitativos se utilizan cuando los datos son escasos, por lo que involucran intuición y experiencia. Por el contrario, los métodos cuantitativos se utilizan bajo tres condiciones: existe información del pasado, la información puede cuantificarse en forma de datos y se supone que el patrón del pasado se repetirá en el futuro (Montemayor, 2012). Los métodos más utilizados en este proceso se especifican a continuación (Chakelson, 2013):
Métodos cualitativos: método de Delphi, consenso de un panel y pronóstico visionario.
Métodos de análisis de series de tiempo: medias móviles, suavizado exponencial, metodología Box-Jenkins y otros.
Métodos causales: métodos de regresión y econométricos.
Métodos basados en Soft-computing: lógica difusa, redes neuronales artificiales y algoritmos genéticos.
Se aplicó una entrevista a profundidad a expertos del CNE encargados de la gestión tecnológica de equipos médicos en Cuba, los cuales manifestaron que actualmente no se aplican modelos de pronóstico en el proceso de planificación del stock de piezas de repuesto. Estos expertos ratificaron la necesidad de perfeccionar este proceso a partir de un sistema automatizado, que incorpore nuevas estrategias que se ajusten a las características de la tecnología para mejorar la planificación en cuanto a la exactitud en los pronósticos.
En la entrevista fueron identificadas como causas de la demanda del stock anual: 1) la disponibilidad técnica y 2) la frecuencia de fallas de la pieza. Los expertos del CNE argumentaron con respecto a estas causas que el equipo médico deja de estar disponible cuando se presentan fallas propias de la tecnología, por afectación del fluido eléctrico y por malas maniobras del operador, lo que implica una disminución de la confiabilidad el equipo al no poder cumplir con las funciones establecidas. Luego se requiere de las actividades de mantenimiento para mitigar las fallas, en las que se solicitan gastables, ya sea para lubricación del equipo, stock de piezas o ambos. En ocasiones el tiempo de reparación del equipo se afecta si no se cuenta con un stock de seguridad en el almacén o por los altos costos de adquisición de la pieza en el mercado (Franco, 2014).
Las causas identificadas por los expertos del CNE corroboran que la demanda del stock de piezas de repuesto se origina como parte de las actividades de mantenimiento, ya sea para prevenir o corregir fallas en los equipos médicos. Este criterio coincide con lo planteado por los autores Godoy (2008), Huang y otros (2010), Jianfeng y otros (2011).
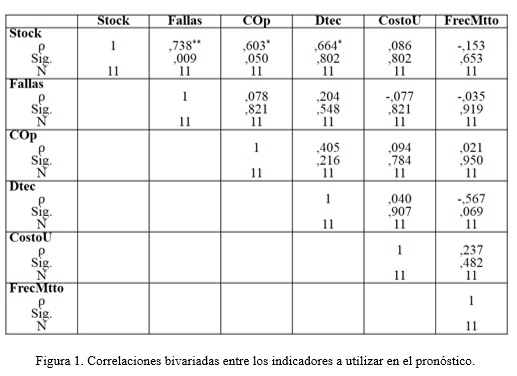
Además de los indicadores anteriores, se toman como referencia de los modelos de pronóstico analizados, los propuestos por Godoy (2008), 3) confiabilidad operacional y 4) frecuencia de mantenimiento y del modelo propuesto por Jianfeng y otros (2011) el indicador: 5) costo unitario. Los cinco indicadores propuestos por Godoy (2008), Jianfeng y otros (2011) y expertos del CNE parecen estar relacionados con el comportamiento de la demanda del stock de piezas de repuesto, relación que fue comprobada con el coeficiente de correlación lineal de Pearson (p) mediante el SPSS 13 como se muestra en la figura 1, que de igual forma se comporta para el resto de las piezas de la muestra seleccionada.
Los resultados obtenidos en el análisis de correlación bivariada evidenciaron que los indicadores: frecuencia de fallas de la pieza, confiabilidad operacional y disponibilidad técnica muestran una relación significativa con el stock anual (valor a predecir), con un p_valor ![]() 0,05. Por lo que se decidió no incluir en el modelo dos de los indicadores: costo unitario y frecuencia de mantenimiento. Además, los coeficientes de correlación entre las variables explicativas del stock anual en todos los casos resultaron ser no significativos con p_valor > 0,05 , por lo que se descartan problemas de colinealidad.
0,05. Por lo que se decidió no incluir en el modelo dos de los indicadores: costo unitario y frecuencia de mantenimiento. Además, los coeficientes de correlación entre las variables explicativas del stock anual en todos los casos resultaron ser no significativos con p_valor > 0,05 , por lo que se descartan problemas de colinealidad.
A partir del análisis realizado se consideran como variables explicativas del stock anual, las siguientes: frecuencia de fallas de la pieza, confiabilidad operacional y disponibilidad técnica del equipo. Unido al análisis anterior se observó que el stock anual de pieza analizadas no muestra un patrón de tendencia, sino un comportamiento cíclico, con decrecimiento y crecimiento, lo que dificulta la aplicación de métodos de series temporales para realizar el pronóstico de la demanda del stock de piezas. Posteriormente, se evaluó utilizando la herramienta Weka 3.7.10, la serie de datos históricos de las 36 pieza seleccionadas con métodos causales como la Regresión Lineal Múltiple (LRM) y otros métodos de soft-computing: red Perceptrón multicapa (MLP) y árboles de decisión (REPTree). La comparación se realizó a partir de los indicadores de exactitud: coeficiente de correlación, MAD, RMSE y MAPE. Según se muestra en la tabla 1 los mejores resultados se alcanzaron con el método LRM, ya que arrojó los mayores valores del coeficiente de determinación y menores indicadores de error.
]]> Los resultados anteriores, más el criterio de los expertos del CNE corroboran la necesidad de desarrollar un modelo multivariado mediante la LRM, como método para la predicción del stock de piezas de repuesto de equipos médicos, que permita mejorar la exactitud en los pronósticos. Debido a esto, se definió el MPREDSTOCK, como modelo multivariado de predicción del stock de piezas de repuesto para equipos médicos.MPREDSTOCK: Modelo multivariado de predicción del stock de piezas de repuesto para equipos médicos
El MPREDSTOCK cuenta con una estructura abierta porque establece intercambio con el entorno general y específico: macroentorno y microentorno, respectivamente. Está constituido por tres componentes: información, técnico y de negocio. Las cualidades que lo distinguen son: flexibilidad, integralidad, facilidad de uso y mejora continua. Está sustentado bajo los principios de:
La actualización permanente mediante la retroalimentación de la información que nutre al modelo.
El enfoque a procesos para definir las actividades necesarias que permitan alcanzar el resultado deseado, identificar las posibles entradas y salidas, así como la evaluación de posibles riesgos.
El enfoque hacia la gestión para identificar, entender y gestionar un conjunto de procesos interrelacionados, que permita mejorar la eficiencia en la gestión tecnológica de equipos médicos.
La utilización del MPREDSTOCK (figura 2) incluye tres fases: evaluación del pronóstico del año precedente, aplicación del modelo y evaluación y ajuste de la planificación del año consecutivo al actual.
Fase I: evaluación del pronóstico del año precedente.
En esta fase se chequea si la planificación del año anterior ha sido satisfactoria; es decir, si los reportes por fallas han sido solucionados de acuerdo al plan en un 95% o superior; de ser así se mantiene la planificación precedente. Posteriormente, se chequean las cantidades máximas y mínimas de piezas que hay en existencia en el almacén, con el propósito de mover las mismas al inventario de seguridad para contingencias, finalizando así el plan para el próximo año. Si la fase I no cumple con los requisitos descritos anteriormente, se procede a la ejecución de la fase II.
Fase II: aplicación del MPREDSTOCK.
En esta fase se ejecuta el MPREDSTOCK. El modelo tiene como entrada: la especialidad, marca, modelo, denominación de equipo y descripción de la pieza a planificar.
El MPREDSTOCK inicia con la ejecución del componente de información. Este constituye el de más bajo nivel en el modelo, pero tiene una marcada importancia porque es donde se encuentra la lista de datos que se manejan para las estimaciones del stock, la relación existente entre ellos y en qué aplicaciones se encuentran.
Lista de aplicaciones que gestionan los datos especificados: Módulo Gestión de Órdenes de Servicio, Módulo Gestión Tecnológica, Módulo Gestión de Mantenimiento, Módulo Gestión de Almacén y Módulo Predicción y Gestión de Stock.
El dominio de integración de aplicaciones se lleva a cabo en el componente técnico. En el mismo se realiza el procesamiento de los datos y a su vez se responde a las peticiones realizadas en el componente de negocio para la ejecución de los procesos: predicción de la disponibilidad técnica del equipo, cálculo de la frecuencia de fallas de la pieza, cálculo de la confiabilidad operacional y estimación del stock anual de la pieza de repuesto correspondiente al equipo médico en análisis. Las salidas de estos procesos constituyen las variables utilizadas para la estimación del stock anual con el método LRM.
Proceso de cálculo de la frecuencia de fallas de una pieza de un equipo médico: se realizó a partir del algoritmo FFP según los reportes en las órdenes de servicio registradas en el sistema. Para ello, se utiliza la media aritmética de forma condicionada. La salida de este proceso constituye la variable X1i para la ejecución del método LRM.
![]()
donde,
![]() frecuencia de fallas de la pieza.
frecuencia de fallas de la pieza.
xi: cantidad de roturas o defectos por año.
]]> n: cantidad de años en el que el equipo o componente ha transitado por los estados: defectuosos o rotos.Proceso de cálculo de la confiabilidad operacional de un equipo médico: se realizó a partir del algoritmo CONFEM, el cual se basa en los fundamentos teóricos descritos por Espinosa (2011). Este algoritmo construye la secuencia de estados absorbentes por los que ha transitado un equipo médico, selecciona las fechas en las que el equipo transitó de un estado F a un estado D o R hasta alcanzar nuevamente el estado F. Posteriormente, cuenta el tiempo en días de las ocurrencias ![]() dividido por la cantidad de ocurrencias de ese tipo presentes en la cadena. De esta forma se calcula el MTBF.
dividido por la cantidad de ocurrencias de ese tipo presentes en la cadena. De esta forma se calcula el MTBF.
![]()
donde,
CDías: cantidad de días transcurridos en la ocurrencia ![]()
Oc: cantidad de ocurrencias.
El MTTR se calculó teniendo en cuenta la cantidad de días transcurridos en las ocurrencias ![]() , dividido por la cantidad de ocurrencias de ese tipo presentes en la cadena.
, dividido por la cantidad de ocurrencias de ese tipo presentes en la cadena.
![]()
La salida de este proceso constituye la variable X2i para la ejecución del método LRM.
Proceso de predicción de la disponibilidad técnica de un equipo médico: se realiza a partir del algoritmo DISTEM propuesto por Morales y Vázquez (2015), el cual se sustenta sobre la Cadena de Markov en tiempo discreto. Este algoritmo tiene como salida un vector fila con la predicción de la disponibilidad técnica para los estados F, D y R respectivamente. Para aplicar el método LRM, se toma porcentualmente el primer valor (X3i) del vector, que corresponde a la probabilidad de que el equipo médico esté en estado F.
]]> Proceso de estimación del stock: se realiza con el algoritmo PREDSTOCK (figura 3) de acuerdo a la salida de los procesos: frecuencia de fallas de la pieza (X1i), confiabilidad operacional (X2i) y disponibilidad técnica de un equipo médico (X3i). Este algoritmo parte de k + 1 variables cuantitativas, siendo y, la variable de repuesta (stock anual) y X1i , X2i ,........Xki las variables explicativas e implementa el método de mínimos cuadrados ordinarios (MCO) para estimar los parámetros poblacionales en laLa interacción de cada uno de los componentes que conforman el modelo mediante el método LRM permite generar una salida que es el plan del stock de piezas al año consecutivo al actual, en aras de satisfacer los reportes de piezas de repuesto de equipos médicos, ya sea para mantenimiento, reparación o recambio.
Fase III: evaluación y ajuste de la planificación del año consecutivo al actual.
El plan de adquisición de piezas de repuesto se planifica sobre un 90% del monto total asignado para su adquisición (Franco, 2014). Cuando se predice el stock de una pieza en el MPREDSTOCK, la cantidad a solicitar puede ajustarse según las existencias en el almacén como parte del stock de seguridad para contingencias o por pronóstico visionario. Aunque de manera general, el plan del stock de piezas de todos los equipos médicos se evalúa y ajusta según las prioridades del Ministerio de Salud Pública (MINSAP) y de acuerdo al financiamiento asignado para la compra de las piezas de repuesto en el mercado internacional. Figura 3
RESULTADOS
Como soporte al MPREDSTOCK se desarrolló el “Módulo Predicción y gestión de stock”, el cual forma parte de los módulos del Sistema de Gestión para Ingeniería Clínica y Electromedicina (SIGICEM). El módulo se utilizó como instrumento de medición durante la aplicación práctica de la propuesta. Además, cuenta con cuatro funcionalidades o submódulos: “Gestión de históricos”, “Gestión de stock”, “Predicción de stock”, “Disponibilidad y confiabilidad del equipo”. A continuación se exponen los resultados alcanzados en la evaluación del MPREDSTOCK.
Evaluación del MPREDSTOCK
En el proceso de evaluación del MPREDSTOCK se partió de la hipótesis causal bivariada definida anteriormente. Este proceso estuvo guiado por el método de trabajo científico experimental. Este método responde a la siguiente interrogante:
¿Mejorará la exactitud de las predicciones del stock de piezas de repuesto para equipos médicos a partir de la aplicación del MPREDSTOCK?
Para dar respuesta a la interrogante planteada se diseñaron dos experimentos del tipo pre-experimento con pre-prueba y post-prueba (Hernández, et al. 1998):
RG O1 x O2
Simbología del diseño experimental:
R: los 12 equipos médicos fueron seleccionados aleatoriamente en cada racimo.
G: 36 piezas de repuesto de los 12 equipos médicos seleccionados.
x: condición experimental (variable independiente de la hipótesis).
O: medición de la variable dependiente de la hipótesis (preprueba O1' y postprueba O2')
a) variable independiente de la hipótesis: fundamentación y aplicación de un modelo multivariado de predicción del stock de piezas de repuesto para equipos médicos (MPREDSTOCK).
b) variable dependiente de la hipótesis: mejora de la exactitud del pronóstico.
Los instrumentos de medición utilizados para la medición en la pre y post-prueba fueron: el Módulo Predicción y gestión de stock del SIGICEM, el SPSS 13.0 y el Weka 3.7.10. En el análisis de los resultados se utilizó como método estadístico la prueba t Student para muestras relacionadas (Castañeda et al., 2010).
Experimento uno: comparar con el grupo experimental seleccionado el stock observado (real) y el stock pronosticado por el MPREDSTOCK respecto a sus medias aritméticas.
Objetivo: demostrar que el stock observado ( ![]() ) y el stock pronosticado por el MPREDSTOCK
) y el stock pronosticado por el MPREDSTOCK ![]() no difieren estadísticamente (p_valor > 0,05).
no difieren estadísticamente (p_valor > 0,05).
Método: determinar que no hay diferencia estadísticamente significativa entre las medias aritméticas del stock observado y el stock pronosticado (![]() =
=![]() ) mediante la prueba paramétrica t de Student para muestras relacionadas.
) mediante la prueba paramétrica t de Student para muestras relacionadas.
Experimento dos: demostrar que existen diferencias estadísticamente significativa (p_valor ![]() 0,05.) en el pronóstico del stock de piezas de repuesto antes y después de la aplicación del MPREDSTOCK.
0,05.) en el pronóstico del stock de piezas de repuesto antes y después de la aplicación del MPREDSTOCK.
Objetivo: determinar que hay diferencia estadísticamente significativa entre los indicadores de exactitud (MAD, RMSE, MAPE, ![]() ) medidos antes
) medidos antes ![]() y después
y después ![]() de la aplicación del MPREDSTOCK.
de la aplicación del MPREDSTOCK.
Método: medir la diferencia entre las medias aritméticas de los indicadores de exactitud obtenidos antes y después de la condición experimental ![]() mediante la prueba t de Student para muestras relacionadas.
mediante la prueba t de Student para muestras relacionadas.
Resultados del experimento uno: se comparó el stock observado (real) y el stock pronosticado por el MPREDSTOCK para el grupo seleccionado, mediante la prueba paramétrica t de Student para muestras relacionadas.
Medición
Stock observado (pre-prueba).
Stock pronosticado con el MPREDSTOCK (post-prueba).
Hipótesis de la prueba t
H0: No hay diferencias entre las medias del stock observado y pronosticado por el MPREDSTOCK ![]()
Regla de decisión: si p > 0,05 no se rechaza H0.

Los resultados experimentales de la tabla 3 muestran un p > 0,05 por tanto, no se rechaza la hipótesis nula, la cual indica que no hay diferencias estadísticamente significativa entre los valores del stock observado y pronosticado con la aplicación del MPREDSTOCK para t(35) = 1,077, p > 0,05 = 0,289.
Resultados del experimento dos: para evaluar si los valores de los indicadores (SEE, MAD, RMSE, MAPE) de exactitud son menores con la aplicación del MPREDSTOCK se compararon sus medias ![]() ) mediante la prueba paramétrica t de Student para muestras relacionadas. Para llevar a cabo el experimento se tuvo en cuenta que los pronósticos del stock de piezas de repuesto para equipos médicos efectuados por el CNE se realizaban con el método de RLS como se describe en la introducción del presente trabajo.
) mediante la prueba paramétrica t de Student para muestras relacionadas. Para llevar a cabo el experimento se tuvo en cuenta que los pronósticos del stock de piezas de repuesto para equipos médicos efectuados por el CNE se realizaban con el método de RLS como se describe en la introducción del presente trabajo.
Hipótesis de la prueba para todas las mediciones
H0: No hay diferencias entre las medias de los indicadores de exactitud medidos antes y después de la aplicación del MPREDSTOCK ( ![]() =
= ![]() ).
).
H1:Hay diferencias entre las medias de los indicadores de exactitud medidos antes y después de la aplicación del MPREDSTOCK ![]() .
.
Regla de decisión: si p_valor ![]() 0,05 se rechaza H0.
0,05 se rechaza H0.
Los indicadores SEE, MAD, RMSE, MAPE y mostraron valores más bajos con la aplicación del MPREDSTOCK, lo que indica una tendencia de concentración de datos cerca de la media, lo cual es deseado; por lo que el 92,92% de la variabilidad del stock a su promedio es explicado por el modelo de regresión ajustado. Por tal motivo, el MPREDSTOCK mediante el método de regresión múltiple resulta un modelo adecuado para describir la relación existente entre las variables utilizadas en el pronóstico, lo cual favorece a una mejora en la exactitud de las predicciones.
CONCLUSIONES
Proyecciones futuras
]]> Los autores pretenden encaminar este trabajo a futuras líneas de investigación, es por ello, que recomiendan: extender el modelo de Markov para el proceso de disponibilidad técnica de un equipo médico a métodos basados en aprendizaje como es el caso de los Modelos Ocultos de Markov, para medir a través de efectos externos u observaciones estados pocos visibles en forma directa.REFERENCIAS BIBLIOGRÁFICAS
AZOY, A. Método para el cálculo de indicadores de mantenimiento. Revista Ingeniería Agrícola, ISSN-2326-1545, RNPS-0622, Vol. 4, No. 4, pp. 45-49, 2014.
CABRERA, O. Reportech: Gestión de tecnología médica. VII Congreso de la Sociedad Cubana de Bioingeniería, La Habana. 2007.
CASTAÑEDA, M. B; CABRERA A. F.; NAVARRO, Y.; DE VRIES, W. Procesamiento de datos y análisis estadísticos utilizando SPSS: un libro práctico para investigadores y administradores educativos. ISBN 978-85-7430-973, EDIPUCRS. 2010.
CORRES, G.; PASSONI, L.I.; ZÁRATE, C.; ESTEBAN, A. Estudio comparativo de modelos de pronóstico de ventas. Iberoamerican Journal of Industrial Engineering, Florianópolis, SC, Brasil, vol. 6, No. 11, p. 113-134, 2014.
]]>CRUZ, A.M; RIOS, A., HAUGAN, L. Outsourcing versus in-house maintenance of medical devices: a longitudinal, empirical study. Rev Panam Salud Pública. Vol. 35, No. 3, pp. 194-199. 2014.
CHACKELSON C. Metodología de diseño de almacenes: Fases, herramientas y mejores prácticas, [Tesis Dr.C.], Universidad de Navarra, Donostia-San Sebastián. 2013.
ESPINOSA, F. Confiabilidad operacional de equipos: Metodologías y herramientas. Universidad de Talca. 2011.
FLORES D., RAMOS J., SOSA A. (Compiladores) Estadística Descriptiva, Probabilidad y Pruebas de Hipótesis I. Universidad Autónoma de Campeche. Facultad de Ciencias Químicas y Biologícas. 2007.
FRANCO, A. Gestión tecnológica de equipos médicos en el Sistema Nacional de Electromedicina, Centro Nacional de Electromedicina, Audio. 2014.
]]>FRAZZON, E.M; ISRAEL, E.; ALBRECHT, A.; PEREIRA, C.E.; HELLINGRATH, B. Spare parts supply chains operational planning using technical condition information from intelligent maintenance systems. Annual Reviews in Control. Science Direct Elsevier. 2014.
GODOY M.C. Modelo de interacción de elementos de confiabilidad e inventario de seguridad de partes y repuestos de equipos mediante análisis multivariante, [Tesis MSc]. Universidad del Zulia, Maracaibo, Venezuela. 2008.
HEMEIMAT, R.; AL-QATAWNEH, L.; ARAFEH, M.; MASOUD, S. Forecasting Spare Parts Demand Using Statistical Analysis. American Journal of Operations Research, Vol. 6, pp. 113-120. 2016.
HERNÁNDEZ R., FERNÁNDEZ C., BAPTISTA P. Metodología de la Investigación. Segunda Edición, Cámara Nacional de la Industria Editorial Mexicana, Reg. No. 736. 1998.
HUANG, Y., XING G., CHANG H. Criticality Evaluation for Spare Parts Based on BP Neural Network, International Conference on Artificial Intelligence and Computational Intelligence, IEEE Computer Society, pp. 204-206. 2010.
]]>JIANFENG H., JINGYING Z., XIAODONG W. Research on the Optimization strategy of Maintenance Spare Parts Inventory Management for Petrochemical Vehicle, International Conference on Information Management, Innovation Management and Industrial Engineering, IEEE Computer Society, pp. 45-48. 2011.
MONTEMAYOR, E. Métodos de pronósticos para negocios. Editorial Digital, Instituto Tecnológico y de Estudios Superiores de Monterrey, México. 2012.
MORALES Z. E., VÁZQUEZ, E. Algorithm for prediction of the technical availability of medical equipment. Applied Mathematical Sciences vol. 9, No. 135, pp. 6735-6746. 2015.
MORALES, Z. E. Predicción del stock de piezas de repuesto para equipos médicos [Tesis MSc], Universidad de Camagüey, Camagüey, Cuba, 2011.
MUÑOZ, M. C. Las tecnologías médicas al servicio de la salud cubana. Segunda Convención Internacional Tecnología y Salud. [Disponible en: http://www.radiorebelde.cu/noticia/las-tecnologias-medicas-servicio-salud-cubana-20140402/] Radio Rebelde. 2014.
OMS. Introducción al programa de mantenimiento de equipos médicos. Serie de documentos técnicos de la OMS sobre dispositivos médicos [En línea: http://www.who.int/about/licensing/copyright_form/en/index.html]. 2012.
]]>PETROPOULOS, F., KOURENTZES, N. Forecast Combinations for Intermittent Demand, Journal of the Operational Research Society, Vol. 66, pp. 914-924. 2014.
ROSAS, J. A.; CORTES, E.L. Propuesta de una metodología de planeación de la demanda y de los inventarios de medicamentos y dispositivos médicos de uso en pacientes hospitalizados en una IPS de cuarto nivel. [Tesis MSc]. Facultad de Ingeniería, Universidad ICESI, Cali. 2013.
SALEH, N.; Comprehensive frameworks for decision making support in medical equipment management. [Tesis Dr]. Facultad de Ingeniería de la Universidad de El Cairo Giza, Egipto. 2014.
SYNTETOS, A. A; ZIED, M.; LUO, S. Forecasting of compound Erlang demand. Journal of the Operational Research Society, Vol. 66, pp. 2061-2074. 2015.
VASUMATHI, B; SARADHA, A. Enhancement of Intermittent Demands in Forecasting for Spare Parts Industry. Indian Journal of Science and Technology, Vol 8, No.25. 2015.
]]>
Recibido: 15/03/2016
Aceptado: 04/07/2016