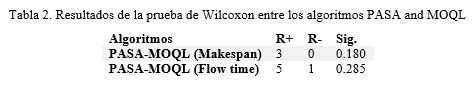Enfoque bi-objetivo basado en Aprendizaje Reforzado para Job Shop scheduling
Bi-objective approach based in Reinforcement Learning to Job Shop scheduling
Beatriz M. Méndez-Hernández1*, Liliana Ortega-Sánchez1, Erick D. Rodríguez-Bazán1, Yailen Martínez-Jiménez1, Yunior C Fonseca-Reyna2
1 Universidad Central Marta Abreu de Las Villas. Carretera a Camajuaní km. 5 ½ . Santa Clara, Villa Clara, Cuba.
2 Universidad de Granma. Carretera de Manzanillo Km 17½. Granma, Cuba.
*Autor para la correspondencia: bmendez@uclv.edu.cu
RESUMEN
Los problemas de secuenciación de tareas requieren organizar en el tiempo la ejecución de tareas que comparten un conjunto finito de recursos, y que están sujetas a un conjunto de restricciones impuestas por diversos factores. Este tipo de problemas aparecen con frecuencia en la vida real en numerosos entornos productivos y de servicios. El problema consiste en optimizar uno o varios criterios que se representan mediante funciones objetivo. En este artículo se analizaron los problemas de secuenciación tipo Job Shop con los principales objetivos a optimizar para este tipo de problemas, seguidamente se propuso un algoritmo desde un enfoque bi-objetivo basado en la Frontera de Pareto y utilizando Aprendizaje Reforzado para optimizar dos de los objetivos analizados, el tiempo de terminación de todos los trabajos y la suma del tiempo de finalización de todos los trabajos, y se aplicó a un conjunto de instancias de prueba. Por último, se describen los resultados satisfactorios obtenidos de acuerdo a dos métricas propuestas en la literatura para la evaluación de algoritmos bi-objetivo.
Palabras clave: Job Shop, multi-objetivo, Pareto, Aprendizaje Reforzado.
ABSTRACT
Scheduling problems require organizing the execution of tasks which share a finite set of resources, and these tasks are subject to a set of constrains imposed by different factors. This kind of problems frequently appears in many production and service environments. The problem is to optimize one or more criteria represented by objective functions. In this paper, the main objectives to optimize were analyzed for Job Shop scheduling problems. After that, a bi-objective algorithm was proposed based on the Pareto Front and using Reinforcement Learning, which optimizes two objectives: the makespan and the total flow time, and this algorithm was applied to benchmarks. To finish, successful results of the algorithm are described according to two metrics proposed in the literature.
Key words: Job Shop, multi-objective, Pareto, Reinforcement Learning.
INTRODUCCIÓN
Los problemas de secuenciación de tareas consisten en la programación temporal de las operaciones o tareas en las que se descomponen un conjunto de trabajos teniendo en cuenta que éstas deben ser ejecutadas en varias máquinas y que cada máquina solamente puede ejecutar una tarea simultáneamente. Se busca aquella solución que dé lugar a un tiempo total de ejecución (Cmax) mínimo, aunque pueden existir otras funciones objetivo.
El Job Shop Scheduling Problem (JSSP) consta básicamente de un grupo de trabajos, donde cada uno tiene un conjunto de operaciones a ser procesadas en un conjunto de recursos limitados, a los que denominaremos máquinas. Cada trabajo tiene un orden en el que se deben ejecutar las operaciones, dichas operaciones tienen un tiempo de procesamiento en cada una de las máquinas y este no es modificable. Se trata de uno de los problemas de optimización combinatoria más difíciles de resolver. No sólo es del tipo NP-Completo, sino que de entre los que pertenecen a esta tipología, es de los más difíciles de resolver.
Muchos problemas de la vida real, como el JSSP, persiguen varios objetivos a la vez, por lo que han hecho de la optimización multi-objetivo un área interesante de investigación. Un enfoque común es combinar los objetivos dentro de una función de escalarización donde se optimiza la suma de estos usando un vector de peso. Esta combinación no siempre muestra un buen desempeño debido a que se necesitan hacer varias iteraciones para obtener un buen resultado. Un enfoque multi-objetivo adecuado permitiría buscar la Frontera Óptima de Pareto.
Uno de los paradigmas más usados ha sido el de los algoritmos evolutivos, principalmente los algoritmos genéticos, de estos se pueden citar varios ejemplos que han mostrado soluciones satisfactorias como son el Vector Evaluated Genetic Algorithm (VEGA) (Schaffer, 1985), el Multi-objective Genetic Algorithm (MOGA) (Fonseca and Fleming, 1993), el Niche Pareto Genetic Algorithm (NPGA) (Zitzler et al., 1999), el Pareto-Archived Evolutionary Strategy (PAES) (Knowles and Corne, 2000a), Pareto converging genetic algorithm (PCGA) (Kumar and Rockett, 2002) y por último el Modified micro Genetic Algorithm (MmGA) (Jun Tan et al., 2015).
También se encuentran algunas meta-heurísticas enfocadas a resolver problemas multi-objetivo como son Multi-objective Tabu Search (MOTS) (Hansen, 1997), Pareto Simulated Annealing (PSA) (Czyżak and Jaszkiewicz, 1997), Memetic Pareto Archived Evolutionary Strategy (M-PAES) (Knowles and Corne, 2000b), entre otros (Silva et al., 2004). También la Optimización basada en colonia de hormigas (ACO) ha sido utilizada para la optimización multi-objectivo en problemas Job Shop (Rudy, 2014).
Recientemente el Aprendizaje Reforzado (RL por sus siglas en inglés) ha recibido considerable atención. En (Gabel and Riedmiller, 2007) y (Gabel, 2009), los autores sugieren y analizan la aplicación de RL para resolver problemas de secuenciación de tipo Job Shop. En estos trabajos se demuestra que interpretar y resolver este tipo de escenarios a través de sistemas multi-agente y RL es beneficioso para obtener soluciones cercanas a las óptimas y puede muy bien competir con enfoques de solución alternativos.
En este artículo se presenta un nuevo algoritmo, llamado MOQL, el cual optimiza el tiempo de terminación de todos los trabajos y la suma del tiempo de terminación de todos los trabajos. Este algoritmo está basado en el algoritmo Q-Learning y en la Frontera de Pareto.
]]> En la primera sección de este artículo se describen algunos de los objetivos que se persiguen optimizar en este tipo de problemas y a continuación en la próxima sección se introduce un nuevo enfoque bi-objetivo que optimiza dos de los principales objetivos descritos anteriormente usando Aprendizaje Reforzado y basado en la Frontera de Pareto. Por último, se muestra a través de pruebas experimentales, utilizando dos métricas propuestas en la literatura, como nuestro enfoque es capaz de competir con un enfoque basado Recocido Simulado propuesto en (Suresh and Mohanasundaram, 2006).Objetivos a optimizar en un JSSP
Los objetivos en problemas de este tipo pueden tomar diversas formas, por ejemplo, la minimización del tiempo de fin de la última tarea (éste es el criterio de optimización más típico y se le conoce con el nombre de makespan), u otra posible función objetivo pueden ser el flow time total (que no es más que minimizar la suma de los tiempos de finalización de todos los trabajos).
A continuación se listan una serie de objetivos que pueden ser optimizados en problemas de secuenciación de tareas tipo Job Shop (Rivera and Eléctrica, 2004) .Ver Lista
El makespan es la función objetivo por excelencia, y en general es la más estudiada en la literatura. Se desea obtener una planificación factible de forma tal que el tiempo de culminación de todos los trabajos, es decir, el makespan, denotado Cmax, sea mínimo. Este problema entonces se denotaría por J|Sij|Cmax según la notación ![]() (Graham et al., 1979).
(Graham et al., 1979).
Esta minimización generalmente garantiza una alta utilización de los recursos de producción, una rápida satisfacción de la demanda de los clientes y la reducción de inventarios en curso.
El flow time total es otra función objetivo que puede tener mucho interés en problemas reales, por ejemplo, en aplicaciones en donde sea muy importante el servicio al cliente. Esta función no considera las fechas de entrega, sino que consiste en minimizar la suma del tiempo de finalización de todos los trabajos. Uno de los problemas con encontrados aquí es que apenas se pueden encontrar en la literatura métodos específicos para resolverla.
El flow time total se define como la suma de los tiempos de finalización de todos los trabajos, es decir, se pretende minimizar ∑Ci. este problema se denota J|Sij|∑Ci.
A continuación, se muestra mediante un ejemplo la diferencia entre el makespan y el flow time. El problema a resolver cuenta con 4 trabajos y 3 máquinas. En la figura se muestra los datos de la instancia utilizada además de las dos secuenciaciones óptimas obtenidas para el makespan (19) y el flow time (51) respectivamente.
Q-Learning
]]> Un algoritmo muy conocido dentro del RL es el Q-Learning (QL) (Watkins, 1989), el cual se basa en aprender una función “acción-valor” que brinda la utilidad esperada de tomar una acción determinada en un estado específico. El centro del algoritmo es una simple actualización de valores, cada par (s;a) tiene un Q-valor asociado, cuando la acción a es seleccionada mientras el agente está en el estado s, el Q-valor para ese par estado-acción se actualiza basado en la recompensa recibida por el agente al tomar la acción. También se tiene en cuenta el mejor Q-valor para el próximo estado s’, la regla de actualización completa es la siguiente:![]()
En esta expresión, α representa la velocidad del aprendizaje y “r” la recompensa o penalización resultante de ejecutar la acción “a” en el estado “s”. La velocidad de aprendizaje “a” determina el ‘grado’ por el cual el valor anterior es actualizado. Por ejemplo, si α=0, entonces no existe actualización, y si α=1, entonces el valor anterior es reemplazado por el nuevo estimado. Normalmente se utiliza un valor pequeño para la velocidad de aprendizaje, por ejemplo α=0,1. El factor de descuento (γ) toma un valor entre 0 y 1 (0≤γ≤1), si está cercano a 0 entonces el agente tiende a considerar solo la recompensa inmediata, si está cercano a 1 el agente considerará la recompensa futura como más importante.
Q-L tiene la ventaja de que se ha demostrado que converge a la política óptima. Sin embargo, esto sólo es cierto para los Markov Decision Process (MDPs). El pseudocódigo de este algoritmo se muestra en la figura 2.
El algoritmo Q-L es usado por los agentes para aprender de la experiencia o el entrenamiento, donde cada episodio es equivalente a una sesión de entrenamiento. En cada iteración el agente explora el ambiente y obtiene señales numéricas hasta que alcanza el estado objetivo. El propósito del entrenamiento es incrementar el conocimiento del agente, representado en este caso a través de los Q-valores. A mayor entrenamiento mejores serán los valores que el agente puede utilizar para comportarse de una forma más óptima.
Q-Learning aplicado a JSSP
En (Jiménez, 2012) se propone un enfoque basado en el algoritmo Q-Learning para JSSP pero desde un punto de vista mono-objetivo. Para introducir el Q-Learning al problema de secuenciación JSSP desde un enfoque multi-objetivo, existen elementos importantes que deben ser definidos y que pueden ser descritos como se muestra a continuación:
Estrategia de selección de la acción: Para seleccionar las acciones la estrategia que se usa es ε-Greedy, pues el uso de la misma evita caer en óptimos locales proporcionando mayor exploración del espacio de soluciones.
Q-Valores: De acuerdo a (Gabel, 2009) el conjunto de estados para el agente “i” se denota como ![]() , esto dará un total de |Si| = 2n estados locales para cada agente “i”, donde n es la cantidad de trabajos del problema a resolver. Debido a las restricciones de orden del problema, muchos de estos estados puede que nunca sean alcanzados. Por ello el MOQL solo almacena los estados que pueden ser alcanzados, es decir, la combinación de operaciones que pueden estar a la misma vez en las colas del sistema. Estas combinaciones se van almacenando a medida que aparecen. Por ejemplo, si el algoritmo es ejecutado por solo una iteración, entonces solo se guardarán n estados, que son los estados en los que el agente se encontraba cuando fueron seleccionadas las acciones. Otras ejecuciones pueden conllevar a la creación de otros estados.
, esto dará un total de |Si| = 2n estados locales para cada agente “i”, donde n es la cantidad de trabajos del problema a resolver. Debido a las restricciones de orden del problema, muchos de estos estados puede que nunca sean alcanzados. Por ello el MOQL solo almacena los estados que pueden ser alcanzados, es decir, la combinación de operaciones que pueden estar a la misma vez en las colas del sistema. Estas combinaciones se van almacenando a medida que aparecen. Por ejemplo, si el algoritmo es ejecutado por solo una iteración, entonces solo se guardarán n estados, que son los estados en los que el agente se encontraba cuando fueron seleccionadas las acciones. Otras ejecuciones pueden conllevar a la creación de otros estados.
Recompensa: El objetivo de este trabajo es lograr optimizar los dos objetivos a la vez, el makespan (Cmax) que es la longitud de la planificación y el flow time que es la suma de los tiempos que demoraron en procesarse todos y cada uno de los trabajos. La principal diferencia que se tuvo en cuenta entre estos objetivos a la hora de implementar el algoritmo Q-L es específicamente las funciones de recompensa.
]]> En el caso del makespan:Para lograr alcanzar el óptimo se deben tener tan pocos recursos inactivos como sea posible, esto hará que las operaciones en cola en las máquinas disminuyan y por tanto el tiempo de finalización del sistema disminuirá. Para lograr esto el MOQL utiliza dos actualizaciones locales y una global.
Las actualizaciones locales se basan en los tiempos de procesamientos de las operaciones y dan un estimado del beneficio de seleccionar una acción específica. En el primer caso la recompensa es 1/tiempo de procesamiento de la operación (nótese que a mayor tiempo de procesamiento menor recompensa se le dará a esa acción), lo que dará mayor prioridad en el sistema a las operaciones que más rápido se procesan. Cada vez que una operación es seleccionada se actualiza el estado local de la máquina en que se ejecutó dando 1/tiempo de procesamiento de la operación como recompensa. En el segundo caso se utiliza como recompensa la suma total de los tiempos de ejecución de las operaciones en cola de la máquina menos el tiempo de procesamiento de la operación seleccionada y en este caso también a mayor tiempo de procesamiento menor recompensa se le dará a esa acción.
Por otra parte, la actualización global se basa en dar una recompensa a partir del resultado final de un episodio, por lo que se modificará el Q-valor (calculado a partir de las actualizaciones locales explicadas anteriormente) de las acciones tomadas en este, teniendo en cuenta el beneficio real al que ellas conllevaron. Nótese que el hecho de que una acción en particular obtenga una buena señal de recompensa no es definitivo, ya que al finalizar el episodio el conjunto de acciones tomadas por los agentes puede haber resultado en una buena o mala secuencia, por tanto, se van a estimular o penalizar respectivamente las acciones involucradas. La forma de dar esta recompensa se definió como recompensa 1/makespan, nótese que a medida que el makespan de la secuencia sea mayor, menor será la recompensa para la acción seleccionada. Cabe señalar entonces que el mayor Q-valor determina la mejor acción en un estado cualquiera.
En el caso del flow time:
La actualización local en este caso se basa al igual que en el makespan en los tiempos de procesamientos de las operaciones y dan un estimado del beneficio de seleccionar una acción específica. La recompensa será 1/tiempo de procesamiento de la operación (nótese que a mayor tiempo de procesamiento menor recompensa se le dará a esa acción), lo que dará mayor prioridad en el sistema a las operaciones que más rápido se procesan. Cada vez que una operación es seleccionada se actualiza el estado local de la máquina en que se ejecutó dando 1/tiempo de procesamiento de la operación como recompensa.
Después de obtenido el flow time de un episodio dado se hace una actualización a todos los estados por los que el sistema pasó durante este proceso, estos estados son almacenados en una lista y la recompensa dada a cada uno de ellos será 1/flow time la cual da una buena medida y mejora las soluciones obtenidas ya que es proporcional a la calidad de la solución encontrada.
A continuación, se muestra en la figura 3 el pseudocódigo del algoritmo propuesto.
A continuación, se muestra un diagrama para una mejor ilustración del funcionamiento del algoritmo donde i es la iteración actual, niters y mmaq son el número de iteraciones y el número de máquinas respectivamente. Ver figura 4
]]> RESULTADOS EXPERIMENTALES
El algoritmo fue implementado en el lenguaje java JDK 1.7, como entorno de desarrollo (IDE) se utilizó NetBeans 7.4 y los experimentos fueron ejecutados en un procesador Intel Pentium IV a 3.40 GHz, con 3 GB de RAM. En el funcionamiento del algoritmo Q-L intervienen parámetros que pueden tomar diferentes valores:
α es la proporción de aprendizaje, es un valor entre cero y uno y determina el grado en que se va a actualizar el q-valor si α=0, no habrá actualización; si α=1 el valor antiguo es remplazado por el nuevo estimado. Usualmente es utilizado un valor pequeño para la proporción de aprendizaje, por ejemplo, α=0.1.
γ es el factor de descuento que tiene el rango de valores desde 0 hasta 1. Si γ es cercano a cero el agente tiende a considerar solamente la recompensa inmediata. Si γ es cercano a uno, el agente considerará la recompensa futura en mayor medida. Se reporta γ=0.8 como un valor frecuentemente utilizado en el algoritmo.
ε es un umbral que permite el balance entre la explotación y la exploración. Todas las acciones a realizar tienen asociadas una probabilidad generada aleatoriamente, si esta probabilidad está por debajo de ε se selecciona una acción aleatoria, de lo contrario se selecciona una acción de acuerdo con la política del agente. El valor 0.2 es usualmente utilizado para este parámetro en la literatura.
El número de ciclos es el parámetro de parada del algoritmo.
El algoritmo fue aplicado instancias de diferentes tamaños de la biblioteca OR-Library disponible en Internet. Las instancias utilizadas cuentan con diferentes configuraciones. La instancia ft06 tiene 6 máquinas y 6 trabajos, las instancias la01-la05 tienen 5 máquinas y 10 trabajos, las últimas 5 instancias (la06-la10) tienen 10 trabajos y 10 máquinas. A estas instancias se le halló el Frente de Pareto y se compararon los resultados obtenidos de acuerdo a dos métricas propuestas en la literatura (Grosan et al., 2003, Knowles and Corne, 2002) con un algoritmo basado en la técnica de Recocido Simulado llamado Pareto archived simulated annealing for Job Shop scheduling with multiple objectives (PASA) propuesto en (Suresh and Mohanasundaram, 2006). Este genera una solución inicial aleatoria, luego usa un nuevo mecanismo de perturbación llamado Segment-Random Insertion (SRI) para generar un conjunto de soluciones ubicadas en la vecindad de la solución actual. Se agruparon las instancias de acuerdo al número de trabajos y de máquinas.
Por ciento de incremento medio relativo (MRPI)
Esta métrica mide la efectividad del frente de Pareto encontrado considerando las soluciones extremas (mejor makespan y mejor flow time encontrado) como referencia. Para calcular esta métrica se obtiene el error medio relativo como la diferencia entre lo alcanzado por nuestro algoritmo y la mejor cota superior reportada en la literatura, esta diferencia se divide entre la cota y el resultado se multiplica por 100.
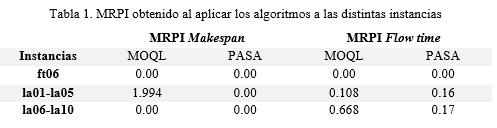
En la tabla siguiente se muestra los resultados obtenidos al evaluar esta métrica a los resultados obtenidos por los dos algoritmos analizados. Tabla 1 y Tabla 2
Al aplicar la prueba de Wilcoxon a estos resultados se obtuvo una significación en el caso del makespan de 0.180 y en el caso de flow time de 0.285, no siendo significativas ninguna de ellas, por lo que el comportamiento de los dos algoritmos de acuerdo a esta métrica es similar (ver Tabla 2).
Net front contribution ratio (NFCR)
Suponga que se quieren evaluar dos algoritmos A1 y A2, se tiene un frente a resultante del algoritmo A1 y un frente b obtenido mediante el algoritmo A2. Se forma entonces un frente c que está compuesto por la combinación de las soluciones de los frentes a y b que no se dominan entre ellas. Por tanto, se tienen n1 y n2 que son la cantidad de soluciones no dominadas del frente a y del frente b respectivamente que pasaron a formar parte del frente c. El NFCR de cada algoritmo se calcula mediante las siguientes fórmulas:
]]> NFRCA1=n1/ndonde n es la cantidad de soluciones no dominadas que forman el frente c. En la tabla 3 se muestran los NFCR de los dos algoritmos para las instancias analizadas.
Al aplicar la prueba de Wilcoxon a estos resultados se obtuvo una significación de 0.905, lo cual implica que no existen diferencias significativas entre estos dos algoritmos de acuerdo a esta métrica tampoco. Tabla 4
CONCLUSIONES
Se implementó un algoritmo bi-objetivo para la optimización del makespan y el flow time en problemas de secuenciación de tareas usando Aprendizaje Reforzado y con soluciones basadas en la Frontera de Pareto probando de esta forma que el Aprendizaje Reforzado es una buena elección para resolver también problemas multi-objetivo. Este enfoque no necesita una configuración inicial compleja como los algoritmos genéticos, pero sin embargo en las pruebas experimentales que se realizaron se demostró que nuestro enfoque brinda resultados tan buenos como uno de los mejores algoritmos multi-objetivo reportado en la literatura.
REFERENCIAS BIBLIOGRÁFICAS ]]>
]]> ]]> ]]>WATKINS, C. J. C. H. 1989. :earning from Delayed Rewards. Ph.D., Cambridge.
]]>
Recibido: 09/09/2016
Aceptado: 25/04/2017