










 Custom services
Custom services Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
Cuba es uno de los países del tercer mundo con mayor tasa de incidencia de cáncer y en ese ámbito el de pulmón constituye la primera causa de mortalidad.1 El cáncer de pulmón es, además, uno de los de peor pronóstico, debido a que durante la fase inicial de su desarrollo los síntomas de esta dolencia se manifiestan de forma inespecífica. En general, cuando se establece el diagnóstico, el tumor ya se encuentra en un estadio avanzado con extensión a ganglios linfáticos regionales o con diseminación a órganos distantes.2 Sin embargo, en un estadio precoz, donde el cáncer de pulmón cursa de manera asintomática, se manifiesta con frecuencia como nódulo pulmonar solitario (NPS). En estos casos es posible encontrar procedimientos terapéuticos que lleguen a una completa recuperación del paciente.3,4,5,6
El NPS (vistos como una opacidad redondeada, relativamente bien definida y cuyo diámetro mayor es inferior a 30 mm) es uno de los problemas más frecuentes en el ejercicio del radiólogo, lo que constituye un hallazgo incidental frecuente en los estudios torácicos realizados durante la práctica clínica diaria.4,5,6
La tomografía computarizada (TC) multicorte representa a las últimas generaciones de tomógrafos y constituyen, hoy en día, la técnica más útil para medir los nódulos pulmonares de forma exacta y reproducible.2,4,5 Sin embargo, esta tecnología en dependencia del espesor del corte programado, genera una gran cantidad de imágenes que deben ser revisadas por especialistas en cada estudio. Analizar estos volúmenes de imágenes toma gran cantidad de tiempo y requiere de alto grado de detenimiento cuando se desconoce la presencia de las anormalidades, y más aún si estas son de pequeño tamaño. Además el proceso de detección puede verse afectado por factores humanos como el cansancio, la falta de experiencia y otros.
Incluso teniendo tiempo y experiencia para revisar minuciosamente cada corte, existen casos de difícil detección. Estudios anteriores refieren que los radiólogos algunas veces no notan la existencia de algún nódulo cuando analizan un examen de TC, debido a la existencia de situaciones de complicada determinación y caracterización.2,7,8,9,10 Ejemplo de esto son los nódulos de pequeño tamaño, los no sólidos y semisólidos, los nódulos subpleurales y los que aparecen adheridos a otras estructuras (generalmente vasos sanguíneos).
La gran cantidad de imágenes que ha de ser analizada y las dificultades que presenta en ocasiones la visualización de algunos tipos de nódulos por los especialistas, han servido de justificación para el desarrollo de algoritmos de detección automática de NPS. Un sistema típico para la detección automática de estos contiene la siguiente secuencia de pasos de procesamiento: adquisición de las imágenes, mejoramiento de las imágenes, segmentación del parénquima pulmonar, detección de los objetos candidatos, reducción de falsos positivos y clasificación.6,11,12 Algunos de estos pasos y como fueron implementados son explicados en las secciones siguientes.
Métodos
Para la construcción del sistema fue utilizado Matlab, por ser una herramienta que brinda gran ayuda en el procesamiento de imágenes, y sobre todo para el caso de imágenes médicas en el formato estándar de imagen digital y comunicación en medicina (DICOM). Para el sistema CAD se implementó una arquitectura modular que está compuesta de una etapa de extracción de las regiones de interés (ROI por sus siglas en inglés), una de extracción de características atendiendo a la forma de los objetos, y finalmente una etapa de detección y reducción de falso positivos (FP). Para esta última etapa se probaron tres de las familias de algoritmos más ampliamente utilizados en el reconocimiento de patrones usando aprendizaje supervisado: las redes neuronales artificiales (RNA), las máquinas de soporte vectorial (MSV) y los árboles de decisión (AD).
Extracción de las regiones de interés
Para la extracción de las ROI se realiza un análisis en dos dimensiones a cada imagen. La densidad del pulmón en las imágenes de TC no es uniforme y sufre variaciones. Estas pueden deberse a la variación del espesor a lo largo del cuerpo y a los parámetros de calibración del escáner.14 Para resolver este problema, se ha empleado un umbral adaptativo usando el método de Otsu, que automáticamente converge a un valor de nivel de gris para cada imagen en particular y permite separar dentro de la imagen las regiones de alta y de baja densidad traducidas en niveles de intensidad de gris.13,14
Existen imágenes para las que dicho método no produce un resultado adecuado, debido a la existencia de unas zonas muy oscuras fuera del círculo de reconstrucción de la imagen (Fig. 1 A). Para obtener una imagen más adecuada se realiza un ajuste del contraste en la imagen realizando un mapeo de los valores de intensidad entre -400 HU y -1024 HU (números de Hounsfield) a todo el rango de salida.15 Estos valores de ventana se determinaron de manera experimental durante la investigación y con estos se logra además una mejor inclusión de los nódulos con bajo contraste como los semisólidos y en vidrio deslustrado (Fig. 1 B).
Tras calcular el valor umbral para una imagen en concreto con su respectivo aumento de contraste, se crea una imagen binaria (Fig. 1 C). Sobre dicha imagen se realiza la operación morfológica de erosión con un elemento estructural en forma de disco, con el objetivo de eliminar los objetos ajenos al cuerpo del paciente (camilla, ruido y otros).16 Después se realiza una reconstrucción morfológica usando como máscara la primera imagen binaria obtenida, la cual devuelve a su tamaño original los elementos que quedaron (Fig. 1 D).17 Posteriormente, se rellenan los huecos de la imagen y se obtiene una máscara binaria sin camilla, ruido y otros artefactos (Fig. 1 E). Estas imágenes se sustraen y de esta forma se obtiene el interior del parénquima pulmonar, al que se le rellenan los huecos (Fig. 1 F).
Un elemento importante en la segmentación es como incluir los nódulos subpleurales en la máscara del pulmón. Para ello se usó una técnica propuesta por Suárez14 que utiliza como base el cierre morfológico. Luego se realiza un etiquetado de regiones y se eliminan las de pequeño tamaño, de manera que queda una máscara como la que se muestra en la figura 1G.
El paso que sigue es la utilización de esta máscara para extraer los pulmones de la imagen original con aumento de contraste. El resultado es la obtención de una imagen que posee los lóbulos pulmonares con todos sus elementos internos adecuadamente realzados (Fig. 1 H). Esta imagen se binariza usando el umbral adaptativo obtenido a través del método de Otsu, extrayendo así los elementos de mayor intensidad (más claros) dentro de los pulmones.
Posterior a este paso se realiza una apertura morfológica con un elemento estructural en forma de disco, con el objetivo de cubrir toda el área interna de los nódulos no sólidos y semisólidos. De esta forma es posible en etapas posteriores darle un tratamiento de elemento sólido. Este resultado se puede observar en la figura 1 I.
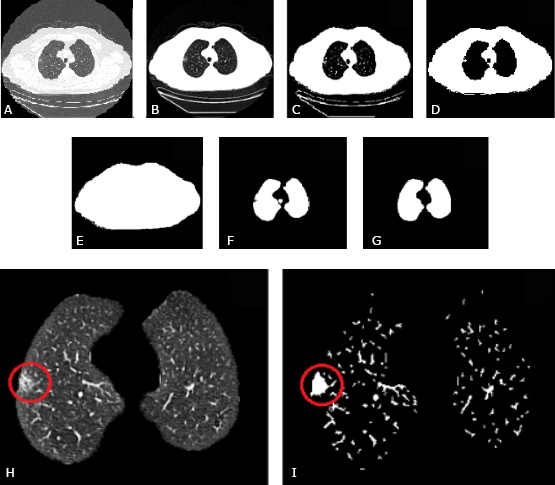
Fig. 1 Resultados de la segmentación. A - Imagen inicial. B - Realce de contraste. C - Imagen binarizada. D - Aplicación de la erosión morfológica más una reconstrucción morfológica. E - Relleno de huecos F - Substracción a la imagen E de la imagen D. G - Aplicación del cierre morfológico y eliminación de regiones de pequeño tamaño. H - Segmentación del parénquima pulmonar con un nódulo no sólido y subpleural. I - Máscara de las estructuras internas al pulmón con el nódulo subpleural no sólido completamente incluido y rellenado.
Conexión y etiquetado de regiones
El resultado de la segmentación de cada imagen de una serie analizada se almacena en un arreglo de memoria como “matriz de imágenes”. A este volumen de imágenes se le aplican técnicas de conectividad y etiquetado de regiones 3D con vecindad 26. A partir de este punto las regiones quedan etiquetadas con los índices desde uno hasta el número total de regiones diferentes, otorgando el valor cero al fondo.
Extracción de características
Las características más utilizadas para la detección del NPS son descriptores geométricos relacionados con su forma aproximadamente esférica. Es posible utilizar además características estadísticas relacionadas con los niveles de gris de la imagen, manejadas fundamentalmente para darle tratamiento diferenciado a los nódulos no sólidos, que por lo general no se encuentran bien circunscritos.10,11 En nuestro caso, el proceso de rellenar el interior de los nódulos no sólido y semisólidos posibilita que la detección pueda realizarse únicamente en base a la forma (buscando esfericidad). Las características utilizadas como descriptores de los objetos en nuestra investigación se detallan a continuación.
Para cada región, el volumen se calculó como el producto del número de los vóxeles de dicha región por el volumen del vóxel en cada caso. Este último es determinado por el espaciado entre píxeles de las imágenes y el grosor de corte de la serie, ambos atributos implícitos en los metadatos de los ficheros DICOM.14,18
A su vez el área superficial del objeto se calculó sumando el área de la cara de cada vóxel que contribuía al perímetro del objeto.10,14,18
Para obtener la densidad esférica, que mide la compactación del objeto, se sitúa sobre el centro de masa de la región, una esfera ficticia, con un volumen igual al volumen de la región de análisis. La relación entre la intersección de los volúmenes se utiliza como medida de densidad esférica.10,14,18
La esfericidad del objeto, que da una representación de cuanto se aproxima el objeto a una esfera se calculó como:10,14,18
 (1)
(1)
Un parámetro que mide la regularidad de los bordes es la desproporción esférica calculada a través de la ecuación:18
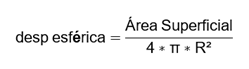 (2)
(2)
La desproporción esférica asume valores pequeños para objetos aproximadamente esféricos con superficie regular y valores altos para objetos irregulares y alargados.
La compacidad da la medida de la ocupación espacial del objeto, y de cómo se podría reducir para que ocupe menor dimensión y menor espacio, pero sin tener que disminuir su volumen. Esta propiedad es mínima para objetos esféricos y se mide por la siguiente ecuación:18
 (3)
(3)
La desproporción esférica y la compacidad son invariantes en relación a la rotación, traslación y escalamiento de los objetos.18
El alargamiento o asimetría del objeto, parámetro conocido como elongación se obtuvo mediante la expresión:10,14,18
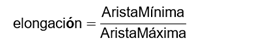 (4)
(4)
Donde AristaMínima y AristaMáxima son las longitudes de las aristas mínima y máxima respectivamente del cubo mínimo que encierra totalmente al objeto analizado.
Etapa de detección y reducción de falsos positivos.
Una vez identificadas las posibles regiones se toma la decisión sobre si se ofrecen o no como salidas del sistema. Esto genera un sistema de clasificación binario en el que cada ROI se evalúa de acuerdo a las características que se le han extraído, para determinar si pertenece a la clase nódulo, o no nódulo. La figura 2 muestra un esquema ilustrativo de este proceso.
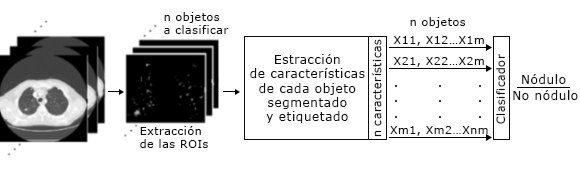
Árbol de decisión
Se escogió como primer modelo de clasificador a probar un árbol de decisión. Los clasificadores basados en árboles de decisión reparten el espacio de características en un grupo de regiones rectangulares utilizando una serie de valores constantes o umbrales de decisión adecuadamente escogidos, lo que representa un modelo simple de clasificador como concepto, pero muy poderoso en la práctica.19 Dentro de la familia de estos algoritmos se encuentra el árbol de decisión restringido a particiones binarias recursivas, el cual fue el utilizado en este trabajo.
Red neuronal artificial
Para el desarrollo del segundo clasificador a probar, se eligió el uso de las redes neuronales artificiales. En este trabajo fue utilizada una red neuronal pre-alimentada (feedforward neural network, FNN).20 Se analizaron para este tipo de red varias configuraciones, obteniéndose los mejores resultados con una configuración 5-18-1, es decir con una capa de entrada con 5 neuronas, una capa oculta con un total de 18 neuronas y una capa de salida con una única neurona por tratarse de un clasificador binario.
Máquinas de soporte vectorial
El último de los clasificadores probados fue una máquina de soporte vectorial con kernel gaussiano para la transformación del espacio de características. En el entrenamiento del modelo se requirieron definir los hiperparámetros: penalización C (factor utilizado para ajustar el modelo cuando hay clases desbalanceadas) y ancho de banda γ (relacionado con el kernel).19 Este proceso fue realizado mediante una búsqueda de maya y validación cruzada, donde los hiperparámetros con menor error de validación cruzada fueron los utilizados para el modelo.
Base de datos
La base de datos utilizada para implementación, entrenamiento y prueba de los algoritmos fue obtenida del proyecto TCIA (The Cancer Imaging Archive) y se denomina LIDC-IDRI.21,22 Se seleccionó un conjunto de 12 series de diferentes pacientes y equipos, para un total de 673 imágenes que contenían 138 nódulos. De ellas, 4 fueron seleccionadas para entrenamiento, conteniendo 44 nódulos y 298 imágenes lo que representa un 44 % del total, una cantidad que se estimó suficiente para entrenar, ya que cada serie genera un alto número de regiones de interés debido a que las etapas de detección y reducción de FP están unidas. Las series restantes se eligieron para pruebas. En base a las anotaciones de los especialistas se verificó dentro de ambos conjuntos la existencia de diversos tipos de nódulos, tanto sólidos, como subpleurales y en vidrio deslustrado, así como de tamaños y formas variadas. Teniendo en cuenta que los NPS son con frecuencia hallazgos secundarios, se tomaron series cuyo grosor del corte varía entre 0,675-3 mm, lo que resulta importante para observar el comportamiento del sistema ante los cambios de resolución que ocurren por las variaciones de dicho parámetro en los estudios médicos con TC asociados a diversas enfermedades.
Evaluación
El sistema a evaluar no es precisamente de clasificación de nódulos, sino de detección y localización de la lesión. Además, en ocasiones pueden observarse más de una anormalidad dentro de una misma imagen. Debido a esto fue más adecuado para la evaluación, expresar los resultados basados en la curva FROC por sus siglas en inglés Free Receiver Operating Characteristic.6,12,14,18 Este método muestra la relación entre la sensibilidad del sistema frente al número medio de falsos positivos por imagen (FPI). De manera complementaria se analizaron otros parámetros como la exactitud y el tiempo medio de ejecución.
Resultados
La evaluación de los algoritmos se realizó con un conjunto de prueba compuesto por 9 series de imágenes de pacientes diferentes, que contenían un total de 375 imágenes y 94 nódulos. Para determinar el tiempo de ejecución promedio de los algoritmos se utilizó una computadora con las siguientes características:
Se utilizaron los mismos datos para cada uno de los algoritmos de clasificación y se obtuvieron los resultados observados en la tabla 1. Como se puede apreciar en dicha tabla, el clasificador más rápido es el árbol de decisión, que logra la clasificación de todas las estructuras en un tiempo promedio de 4,8 segundos por serie analizada, lo que da un resultado de 2,15 minutos totales al ser sumado al tiempo de la segmentación y extracción de características.
Tabla 1 Tiempo de ejecución promedio y exactitud de los clasificadores
| Diseño | Tiempo de ejecución promedio en segundos. | Exactitud (%) |
|---|---|---|
| Red neuronal | 8,1 | 97,3 |
| Árbol de decisión | 4,8 | 96,4 |
| Máquina de soporte vectorial | 4,9 | 95 |
Se calcularon además los valores de exactitud de cada algoritmo, lo que ofrece una concordancia entre las estructuras que fueron correctamente clasificadas, ya sean nódulos o no nódulos, y el total de objetos. Los resultados se muestran en la columna tres de la tabla 1. Debe notarse que precisamente el algoritmo con mayor exactitud es el que mayor tiempo de cómputo requiere.
En la curva FROC de la figura 3 se aprecian los valores de sensibilidad/FPI obtenidos al variar determinados parámetros de los clasificadores. Para la SVM se utilizó la función de kernel gaussiana y se construyó la curva ajustando la escala del kernel a través del parámetro γ. En los dos clasificadores restantes se varió el umbral que determina a partir de qué valor las salidas de los clasificadores se pueden considerar como nódulo pulmonar. De esta forma se evalúa el comportamiento de los clasificadores en cuanto a sensibilidad y especificidad medida como FPI. Los datos marcados con rombo indican los valores que se consideraron más adecuados y, por tanto, indican los umbrales escogidos para comparar los diseños.

Finalmente fue escogido el AD como clasificador a utilizar y todo el procesamiento fue aunado en una interfaz gráfica generada en Matlab a la que se le denominó Toráx 2.0. Entre otras funcionalidades la aplicación permite ejecutar el algoritmo de detección que finalmente devuelve una serie de coordenadas (x, y, z) correspondientes a los cubos que encierran a los nódulos detectados dentro del volumen de imágenes. Estas coordenadas se le presentan al usuario en recuadros amarillos a medida que se mueve por las diferentes imágenes de la serie analizada como se muestra en la figura 4.

Fig. 4 Resultado de la detección de nódulos pulmonares en una serie de imágenes de TC. A - Interfaz gráfica “Tórax2.0”. B - Área de visualización con un nódulo encontrado y un falso positivo. C - Área de visualización con dos nódulos encontrados (entre los que se incluye uno de muy pequeño tamaño) y dos falsos positivos.
Discusión
En el desarrollo de los algoritmos se lograron implementar los pasos más generales de un sistema CAD. El método de segmentación empleado permitió generar la división de las imágenes originales en regiones significativas, en las que quedaron bien definidos primeramente los lóbulos pulmonares, y segundo, las estructuras con mayor densidad dentro de ellos, consideradas como las regiones de interés que se podrían asociar con nódulos pulmonares. El método propuesto es capaz de adecuarse a los cambios de contraste e iluminación que ocurren en las series de imágenes de TC debido a las variaciones del espesor a lo largo del cuerpo y a otros parámetros de calibración del sistema de adquisición. Se comprobó que con operaciones sencillas como el cierre morfológico y el ajuste de histograma en las imágenes utilizando valores de Hounsfield, se pueden mejorar la inclusión de los nódulos subpleurales y los no sólidos como regiones de interés. Además, el proceso de rellenar el interior de los nódulos no sólido y semisólidos para que puedan ser analizados como sólidos, permite que la detección pueda realizarse en base a la forma y volumen (buscando esfericidad).
En cuanto a los algoritmos probados para la detección, la red neuronal ofrece el mejor porcentaje de exactitud, pero éste no es precisamente el parámetro fundamental en este tipo de algoritmos relacionados con la medicina, y que además presenta clases desbalanceadas. Pues la cantidad de verdaderos positivos es notablemente pequeña con respecto al total de verdaderos negativos. Por tal motivo el mejor parámetro para calificar estos algoritmos es la sensibilidad, para una cantidad de falsos positivos lo más pequeña posible. Debido a esto el clasificador que resulta más adecuado es el AD que mostró además de buena exactitud (de 96,4 %), el mejor balance de sensibilidad/FPI con un valor de 91,5 % de nódulos correctamente detectados contra una tasa de 0,4 FPI.
El tiempo de ejecución promedio del algoritmo escogido es además el menor. Para una serie de 100 imágenes el sistema de detección completo tiene un tiempo de ejecución promedio de 2,15 minutos, para una computadora con las características descritas en el apartado de resultados, lo que resulta adecuado para ser utilizado en un software de tipo CAD que procese un alto número de imágenes.
El trabajo de investigación y la implementación de los algoritmos, integrados en la interfaz gráfica Toráx 2.0, representan un prototipo del sistema de diagnóstico asistido por computadora con condiciones suficientes para contribuir a detectar más fácilmente el NPS en los estudios médicos con imágenes de TC.

