










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
In recent decades, strict quality standards and competitive pressure have forced industrial companies to transform their maintenance strategies and plans. These changes include the emergence of maintenance departments whose function is to ensure the employment of advanced techniques and practices to maintain the productivity of the company. The implementation of predictive maintenance strategies to increase component life, improving availability and reliability of their equipment, has an impact on the productivity of the plant [1, 2], and has become an increasingly important issue for large and medium-sized companies. The Internet of Things (IoT) helps the strategies; however, it also introduces technological challenges, one of them being the necessary processing of large volumes of data. This high processing loads has led to the increasing employment of computer clusters [3, 4]. Failure detection in industrial equipment is one of the interesting applications in this field [1, 2].
Creating algorithms and systems that can process and store large amounts of data represents a great scientific, economic, and practical challenge. The application of machine learning (ML) to these problems is not trivial, and even less so if the processing of these algorithms needs to be distributed to handle the large computational load of data analysis and decision making [3, 4].
This is added to the challenges involved in obtaining accurate and robust results in the detection of failures [5, 6, 7]. Most of the architectures developed so far are only used in the training process, and not in the online execution of algorithms [8, 9, 10, 11, 12]. Another important aspect is that these architectures do not contain integrated modules that measure the robustness and performance of the algorithms out of box. This negatively impacts the ability to train, deploy and predict failures quickly and effectively. There is a current trend towards the democratization of machine learning, which means making it more accessible to a wider range of organizations and enterprise customers. Right now, there is a limited number of machine learning specialists. To generalize the use of ML solutions, tools must be generated to facilitate the applications in a simple, effective, and fast way [13].
The era of distributed processing has seen the emergence of several architectures for distributed processing of large amounts of data (Bigdata) [8, 9, 10, 11, 12]. These distributed architectures possess a collection of independent entities that cooperate to solve a problem that cannot be solved individually. Selecting the right architecture requires quantifying applicability and performance. There are several parameters used to characterize the performance of algorithms, such as processing time, accuracy and robustness, the latter is defined as the ability to fulfill its function in the presence of certain irregularities in the data. Different measures are used to quantify this evaluation of the algorithms, usually expressed by a score that meets the indicated parameters.
Among these architectures is Spark, which has multiple benefits, such as usability, flexibility, scalability, and high fault tolerance. Spark is a distributed system that possesses properties including generality, fault tolerance, high in-memory data processing performance, and scalability. It adopts a flexible programming model using Resident Distributed Data (RDD), with a set of action and transformation operators whose operational functions can be customized by users according to their applications. It is positioned as a fast and general data processing system [9]. However, Spark has several disadvantages, among them are the limited ability to run algorithms online, limited lightweight runtime mode to process algorithms at the edge, and does not have out of the box capabilities for auto selection of algorithm pipelines based on Robustness Index and Precision Score. Spark was designed for generic use, without considering the particularities of distributed processing of machine learning algorithms [9].
Another alternative is Smart Operational Realtime Big Data Analytics (SORBA). This is a patented architecture [14] that meets the operational elements related to flexibility, scalability, fault tolerance, general deployment, and execution mechanisms. SORBA’s distributed architecture is prepared for training, deployment, and execution of machine learning algorithm pipelines (MLAP). Still, SORBA was designed without considering the specificities on the Robustness Index of the algorithms for incomplete observations and lacks an out of the box MLAP auto selection based on robustness.
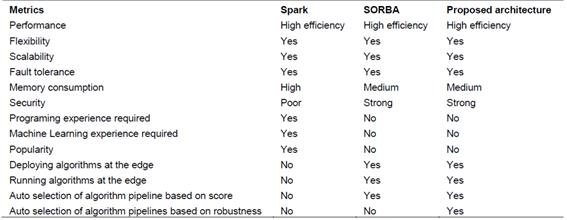
The proposed architecture is based on SORBA and it builds upon it by using Precision Score and Robustness Index to optimize the self-selection, execution, and deployment of machine learning algorithms pipelines for failure detection in industrial equipment. Table 1 shows the benefits and shortcomings of Spark, SORBA and the proposed architecture for training, deployment, and execution of algorithms [9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]. When compared to Spark, the added capabilities of the proposed architecture improve the performance of ML failure detection algorithms for industrial equipment, as it can be concluded from the three case studies presented in the paper.
Characterists of the proposed architecture
The proposed architecture is based on the idea of training, executing, and deploying algorithm pipelines in a distributed way, using the resources of multiple devices. The different components of the architecture are illustrated in Figure 1 and 2. The components can be defined as follows:
Executor: These are the processes that execute the calculation operations.
Worker nodes: They have several executors working in parallel and can be physical servers, virtual machines or dockers.
Cluster Handler: This component is extremely important since it is the one that controls all the exchange of messages between the worker nodes.
Resource Handler: Regulates the use of worker nodes based on existing hardware resources.
Manager Handler: Like the cluster handler, but in this case the program handler is responsible for distributing and properly controlling the jobs sent to the cluster.
RESTful API: It is the interface that allows sending jobs to the cluster and the reception of results from the cluster.
Applications: They are the ones that send the jobs to the cluster, and they are the ones that use the generated results to solve problems of various kinds, such as failure detection.
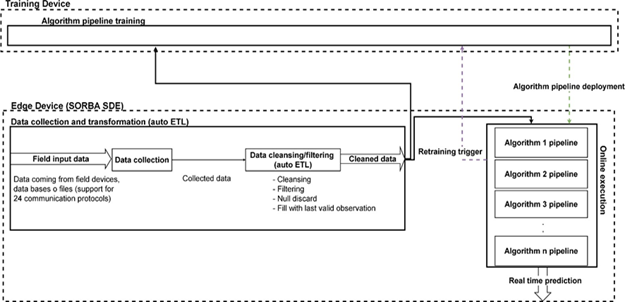
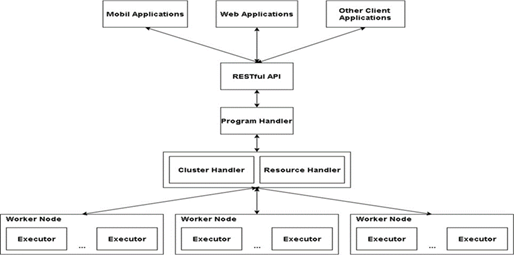
Table 1 compares the proposed architecture with Spark and SORBA. It also highlights the benefits of the proposed architecture addressed in this paper.
Methods
To quantify the effects of the auto MLAP selection layer added to the new architecture three industrial failure detection cases were performed applying Spark and the Proposed architecture. The results were compared in terms of Precision Score and Robustness Index [22]. Then Shapiro-Wilk’s test [23] was performed to check data normality and Friedman’s test [24] was used to validate the statistical significance of the results.
Failure detection evaluation case studies
Two experiments were conducted. The first experiment consisted of failure detection in an industrial motor. Industrial motors provide great capacity to intervene in different industrial processes and it is precisely what makes them vulnerable to different operating problems [5]. For this reason, their maintenance is a key and a recurring theme among professionals who intervene in the industrial field [5]. In the experiment, the industrial motor was connected to a Siemens PLC 1200 and the SDE was used to collect, clean/filter the data, and execute in real time the algorithm pipelines. The experiment used a period of 6 months of data for training, which contains 17 million observations. The industrial motor had multiple variables available including current (1), frequency (2), power (3), speed (4), torque (5) and AC voltage (6). In the experiment, several supervised algorithm pipelines were trained to classify a failure in the motor bearings.
The second experiment consisted of failure detection in a locomotive battery. Batteries are widely used in multiple industrial applications [25], especially in locomotives, where the starting system is highly dependent on them. The cost of a locomotive is approximately $3 million USD, which implies that predictive maintenance on the locomotive would help save top dollars in the long term [25]. The industrial locomotive battery used in the experiment is connected to a SDE that collected, clean/filtered the data, and executed the algorithm pipelines. A total of 38 million observations in a period of 5 months were used to train the algorithm pipelines. The variables monitored in the battery are speed (1), voltage (2) and current (3). In the experiment, several supervised algorithm pipelines are trained to classify a failure in the battery.
The following identifiers are used for each algorithm:
SMOTE: Synthetic minority oversampling technique
TOMEKLINKS: Tomek links for under sampling
SMOTETOMEK: Synthetic minority oversampling technique and tomek links
ZS: Z-Score
SS: Standard scaling
RS: Robust scaling
PCA: Principal components analysis
KPCA: Principal components analysis with kernels
IPCA: Incremental principal components analysis
SPCA: Sparse principal components analysis
RPCA: Randomized principal components analysis
LRC: Logistic regression classifier
SVMC: Support vector machine classifier
RFC: Random forests classifier
DTC: Decision tree classifier
GBC: Gradient boosting classifier
KRC: Kernel ridge classifier
SPP: SORBA Post-processing
The above algorithms were classified according to their functionality in the following way:
Data balancing stage: None, SMOTE, TOMEKLINKS and SMOTETOMEK
Pre-processing stage: None, ZS, SS and RS
Dimensionality reduction stage: None, PCA, KPCA, IPCA, SPCA and RPCA
Machine learning estimator stage: LRC, SVMC, RFC, DTC, GBC and KRC
Post-processing stage: SPP
As a first step, the auto MLAP functionality of the proposed architecture was used to select the best four algorithm pipelines in terms of Precision Score and Robustness Index. Then they were tuned using the auto hyperparameter tunning available on the proposed architecture. As a result of this step the four best algorithm pipelines are:
As a second step, the same four algorithm pipelines that the proposed architecture found were trained using Spark and Grid Search for the hyperparameter optimization.
A comparison of the four algorithm pipelines is made for the training process using Spark and the proposed architecture, using the Precision Score and Robustness Index. The training using Spark and the proposed architecture was performed with three virtual machines that form a cluster, each node has 4 CPUs, 8GB of RAM and 256GB of storage.
To simplify the naming of the algorithm pipelines a short naming convention is used on the following sections:
SMOTE-PCA-RFC-SPP trained using the proposed architecture (Alg 1)
SMOTE-PCA-DTC-SPP trained using the proposed architecture (Alg 2)
SMOTE-KPCA-RFC-SPP trained using the proposed architecture (Alg 3)
SMOTE-ZS-PCA-RFC-SPP trained using the proposed architecture (Alg 4)
SMOTE-PCA-RFC-SPP trained using Spark (Alg 5)
SMOTE-PCA-DTC-SPP trained using Spark (Alg 6)
SMOTE-KPCA-RFC-SPP trained using Spark (Alg 7)
SMOTE-ZS-PCA-RFC-SPP trained using Spark (Alg 8)
Performance indices
There are many performance metrics that are used on ML such as precision, accuracy, and f1 score [26, 27]. In this paper we use Precision Score and Robustness Index based on incomplete observations, which are typically used for supervised distributed algorithms pipelines. The Precision Score most of the time is used on supervised training where the features and target observations are available [27]. The Precision and Accuracy Scores are calculated using equations 1 and 2 respectively:
 (1)
(1)
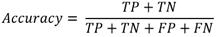 (2)
(2)
Where 𝑇𝑃 is defined as true positive, 𝐹𝑃 false positive, 𝑇𝑁 true negative, and 𝐹𝑁 false negative. The Robustness Index based on incomplete observations is introduced to quantify the effect on accuracy of the lack of observations in machine learning algorithms [22]. It is defined by equation 3:
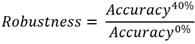 (3)
(3)
Where 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦0% and 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦40% are the accuracies obtained during the validation process with the test data group, when all the data is available and when 40% the data is missing.
Validating the performance evaluation
As part of the experiments and performance evaluation, the Shapiro-Wilk normality test was performed to determine if the Precision Score and Robustness Index are normally distributed [23]. The hypothesis is:
𝐻0: The Precision Score and Robustness Index are not normally distributed.
𝐻𝑎: The Precision Score and Robustness Index are normally distributed.
When the p-value is greater than 0.05 the null hypothesis cannot be rejected, and it is concluded that the Precision Score is normally distributed. Then the experimental results regarding the Precision Score and Robustness Index were validated using Friedman test (FT) [24]. The validation assumes a general hypothesis that the Precision Score and Robustness Index for all supervised algorithm pipelines are the same:
𝐻0: The Precision Score and Robustness Index for all supervised algorithm pipelines are the same.
𝐻𝑎: The Precision Score and Robustness Index for all supervised algorithm pipelines are not the same.
Then considering α = 0.05, 𝐹𝑇 can be calculated using the Equation 4:
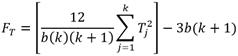 (4)
(4)
Where 𝑘 is the number of algorithms, 𝑏 is number of experiments and 𝑇2 the sum squared of the ranks of the algorithm. If the critical value is within a given range the null hypothesis can be rejected, and it can be concluded that the Precision Score and Robustness Index of the supervised algorithm pipelines are not statistically equal.
Results
The following section presents the results for the Industrial motor and Locomotive battery experiments. Four different MLAPs optimized and trained using Spark and the proposed architecture are applied to each case. The results indicate that the MLAP auto- selection and hyperparameter optimization based on Precision Score and Robustness Index improves the failure detection performance.
Industrial motor failure detection
Table 2 shows the comparison of the supervised algorithm pipelines trained using Spark and the proposed architecture for the bearing failure detection on the industrial motor. The Precision Score and Robustness Index based on incomplete observations were used for the comparison.
Table 2 Comparison of the supervised algorithm pipelines trained using Spark and the proposed architecture for failure detection in an industrial motor.

Figures 3 and 4 show that industrial motor failure worsened over time. Alg 3 provided the best failure detection results, predicting the failure 6 days in advance as can be seen in Figure 4. The nature of the failure is multiplicative, it was sudden in various parameters of the equipment and is related to a structural failure. It can be classified as a multiple failure situation because various elements of the equipment were affected. It can also be classified as an abrupt failure because it evolved rapidly. According to expert reports, the reason for the failure was due to the motor bearing and it was related to the lack of lubrication in the bearing. This condition is very common, critical and affects many mechanical equipment, causing rapid deterioration of the mechanical parts of the system.

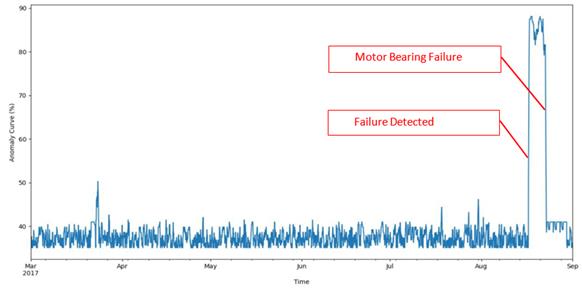
Figure 4 Anomaly curve of the motor bearing failure for the best supervised algorithm pipeline (Alg3).
Locomotive battery failure detection
Table 3 shows a comparison of the supervised algorithm pipelines trained using Spark and the proposed architecture for the locomotive battery failure detection. The Precision Score and Robustness Index based on incomplete observations were used for the comparison.
Table 3 Comparison of the supervised algorithm pipelines trained using Spark and the proposed architecture for failure detection in a locomotive battery.

Figures 5 and 6 show that the failure worsens over time. Alg 2 provided the best failure detection results, predicting the failure 3 days in advance as can be seen in Figure 6. The nature of this failure is of a multiplicative type, it was a gradual failure in various parameters of the equipment and is related to a structural failure. It was a multiple failure type because various elements of the system were affected. The reason for the failure is related to the disuse of the battery according to the criteria of the engineers who participated in the discovery and troubleshooting of this event. As in the other cases, this failure is very common and affects many systems that use batteries as secondary power or starting systems.


Analysis
The objective of the study was to determine if the MLAP auto selection and hyperparameter optimization capabilities based on Precision Score and Robustness Index improved the results achievable with Spark and Grid Search. The analysis allows concluding that the proposed architecture has superior performance.
Performance evaluation
Firstly Shapiro-Wilk normality test was performed to determine if the Precision Score and the Robustness Index obtained are normally distributed. The Precision Scores p-value were 0.1575 and 0.1575, and for the Robustness Index they were 0.6889 and 0.6889. In both cases they were greater than 0.05, therefore the null hypothesis could not be rejected, allowing us to conclude that they were normally distributed.
Then the results obtained for the Precision Scores and Robustness Index were validated using the Friedman test. The analysis is presented in Table 4 and Table 5 respectively. In Friedman test as a general hypothesis is that results for all supervised algorithm pipelines are the same:
𝐻0: The Precision Score for all supervised algorithm pipelines is the same.
𝐻𝑎: The Precision Score for all supervised algorithm pipelines is not the same.

Considering α = 0.05, 𝐹𝑇 for the scores can be calculated using the following equation:
 (5)
(5)
Where 𝑘 is 8, 𝑏 is 3 and 𝑇2 the sum squared of the rank column. The critical value is 14.067 and 17.222 > = 14.067, therefore, the null hypothesis can be rejected and conclude that the Precision Score of the supervised algorithm pipelines is not statistically equal. We can then conclude that the supervised distributed algorithm pipelines trained using the proposed architecture present an improvement in the Precision Score.
In the case of the Robustness Index a test was performed to determine the impact of incomplete observations on the accuracy obtained for the algorithm pipelines on the three experiments [22]. Several trainings were performed using a portion of the data, where 0%, 10%, 20%, 30%, and 40% of the total available observations were removed. The algorithm pipelines that were trained using the proposed distributed architecture show less reduction in Accuracy when there are incomplete observations, see Figure 7. Table 5 shows the results for the Robustness Index Friedman test. Considering α = 0.05, 𝐹𝑇 was calculated using the following equation:
 (6)
(6)
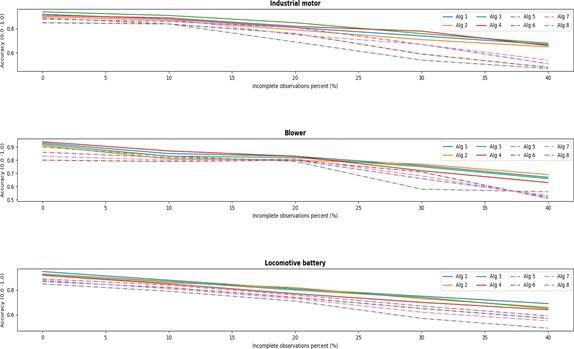
Figure 7 Comparison between algorithm pipelines reduction in accuracy when there are incomplete observations.

From Equation 6 the critical values are 14.067 and 15.111 > = 14.067, therefore, the null hypothesis could be rejected, making it possible to conclude that the Robustness Indexes of the supervised algorithm pipelines are not statistically equal. Then we can conclude that the supervised distributed algorithm pipelines trained using the proposed architecture present an improvement in the Robustness Index based on incomplete observations.
Conclusions
In this paper, a novel distributed and robust architecture for failure detection in industrial equipment has been presented. The incorporation of the Robustness Index, together with Precision Score, in the optimization process for automatic selection of industrial failure detection machine learning algorithm pipelines and their hyperparameters, not only streamlines the implementation of solutions, but improves the performance of this indicators with respect to the solutions currently available in the MLlib Spark. Finally, the results obtained allow concluding that:
The supervised algorithm pipelines that were trained with the proposed architecture perform better in detecting industrial equipment failures. This can be determined by the experiments performed in previous sections where an average Precision Score improvement of 28.76% and 10.94% on the Robustness Index was accomplished.
The automatic algorithm selection, combined with the hyperparameter auto tunning mechanisms simplifies the implementation algorithms with optimal results, therefore helping democratize access to machine learning solutions when compared to MLlib Spark.
The integrated mechanism of deployment and online execution of the algorithm pipelines helps to simplify the process of implementing applications related to the detection of failures in industrial equipment.

