










 Custom services
Custom services Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
La sociedad actual genera datos de manera exponencial y se requiere de herramientas, procedimientos y nuevos métodos de análisis que permitan extraer el conocimiento subyacente a dichos datos y ajustarlos a modelos comprensibles por el ser humano, que permitan predecir información futura.1El desarrollo apreciable de las matemáticas, de las técnicas informáticas y de las ciencias básicas, permiten plantear modelos matemáticos cada vez más cercanos al comportamiento real del proceso salud-enfermedad.2
Un ejemplo de ese desarrollo es el análisis estadístico implicativo, conocido por la sigla ASI de Analyse Statistique Implicative del idioma francés donde se originó, es una herramienta de la minería de datos basada en las técnicas estadísticas multivariadas, la teoría de la cuasi-implicación, la inteligencia artificial y el álgebra booleana, para modelar la cuasi-implicación entre los sucesos y variables de un conjunto de datos. 3
Esta técnica surgió para solucionar problemas de la Didáctica de la matemática y fue creada por el francés Régis Gras,4-6 profesor emérito de la Universidad de Nantes, Francia, quien comenzó sus trabajos en este campo en 1980, y desde entonces ha venido estudiando el fenómeno de la creación de reglas inductivas no simétricas y de la cuantificación de la probabilidad de que se presente una cierta característica b si se ha observado otra característica a en la población. El ASI contempla la estructuración de datos, interrelacionando sujetos y variables, la extracción de reglas inductivas entre las variables y, a partir de la contingencia de estas reglas, la explicación y en consecuencia una determinada previsión en distintos campos del saber.7
El objetivo de este trabajo es identificar los aspectos teóricos y prácticos que justifican el empleo de esta técnica en los estudios de causalidad en medicina para lo cual se llevó a cabo una exhaustiva revisión de la literatura sobre el tema en las bases de datos bibliográficas alojadas en la Internet para sintetizar y sistematizar la bibliografía encontrada.
Implicación y cuasi-implicación como antecedentes del ASI
Los hechos y fenómenos de la realidad están concatenados por las llamadas relaciones causales. Estas relaciones causales son captadas por el pensamiento humano de acuerdo a los hechos pasados y las expectativas, son expresadas en el lenguaje mediante las oraciones condicionales y formalizadas según la Lógica mediante expresiones llamadas implicaciones. Una implicación es una afirmación que conlleva a otra afirmación relacionando una causa (A) con un efecto (B), y se escribe, formalmente, según la lógica proposicional como A ⇒ B, donde A es una causa o conjunto de causas y B el efecto o conjunto de efectos esperados de esa causa.8
La implicación A ⇒ B puede ser expresada como “si A entonces B” y si esa proposición es verdadera se dice que “A es condición suficiente para B”, por el contrario, si la implicación B ⇒ A es verdadera, “A es condición necesaria para B”. Cuando se satisface la implicación en ambos sentidos (coimplicación), B es verdadera si y sólo si lo es A, caso que se puede denotar como A ⇔ B, y significa que A es condición necesaria y suficiente para B.
En las matemáticas el determinismo es total por lo que toda regla (teorema) no sufre de excepción; en cambio en las situaciones naturales, sociales o de las ciencias biomédicas no existe un determinismo total por lo que los teoremas del tipo “si a entonces b” no pueden establecerse a causa de las excepciones que los niegan. Es por eso que la epidemiología denomina factor de riesgo al factor que aumenta la probabilidad de que ocurra un desenlace y no a la causa de un desenlace. Esa imposibilidad (contradicción) motivó la necesidad de profundizar en los datos para encontrar reglas fiables del tipo teoremas parciales surgiendo así la teoría de la cuasi-implicación o implicación estadística a partir de la dialéctica “ejemplos-contraejemplos”.1
En la teoría cuasi implicativa las reglas del tipo “si a entonces b” son aceptables y aplicables, mientras que el número de contraejemplos sea "admisible“, por ejemplo, se sabe que el hábito de fumar constituye un factor de riesgo para el cáncer de pulmón pero no se puede esperar de manera absoluta que “si fuma entonces padecerá cáncer de pulmón” pero, el hecho de que algunos pacientes fumadores no desarrollen el cáncer de pulmón (contraejemplo) no invalida el hecho de que el tabaquismo sea un factor de riesgo para desarrollar dicha enfermedad.
El concepto de cuasi-implicación relaja al de implicación, de modo que se trata de una regla que admite contraejemplos: "cuando un individuo presenta el rasgo a, entonces, generalmente, también presenta el rasgo b". La validez de la regla depende entonces de la probabilidad o fuerza de la cuasi-implicación, la cual se determina al comparar el número de contraejemplos presentes, con los que aparecerían bajo una ausencia de relación estadística.
Como se plantea en Gras,1,9 el estudio de este concepto de cuasi-implicación como objeto matemático, en los campos de las Probabilidades y de la Estadística, permitió construir las herramientas teóricas en que se fundamenta el ASI, que permiten identificar una posible relación causal y formular hipótesis con fines descriptivos y, si es posible, predictivos.
Principales categorías del ASI
En el ASI la validez de la regla a ⇒b depende de la probabilidad o fuerza de la cuasi-implicación, que se determina al comparar el número de contraejemplos presentes que invalidan dicha regla con los que aparecerían bajo una ausencia de relación estadística.
El ASI consta de tres procedimientos:
La implicación, donde se destacan tres conceptos básicos:
La intensidad implicativa: medida probabilística de la validez de la regla
 . La decisión de aceptar o no la regla está en función del nivel de significación
. La decisión de aceptar o no la regla está en función del nivel de significación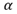 elegido por el investigador y se dirá que la regla
elegido por el investigador y se dirá que la regla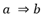 es admisible para undado si la cantidad de contraejemplos esperados es menor que los observados.
es admisible para undado si la cantidad de contraejemplos esperados es menor que los observados.El índice de implicación: indicador de la no implicación de a sobre b. Este índice es no simétrico y no coincide con el coeficiente de correlación u otros índices simétricos que miden asociación.
El índice de implicación-inclusión o de implicación entrópica: versión entrópica del índice de implicación que supera la poca discriminación de este en muestras grandes. Este índice permite determinar el criterio entrópico al integrar la información a partir de la presencia de un escaso número de contraejemplos, tanto por la regla
 como por su negación
como por su negación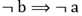
La cohesión, que permite estructurar el conocimiento en forma de reglas y meta reglas y superar la simple articulación de las partes de una tipología clásica, a fin de alcanzar un todo significativo al ser de carácter no lineal, asimétrico, jerárquico y dinámico. Las reglas y meta reglas que surgen se pueden presentar en tres esquemas:
La similaridad como medida de correspondencia o semejanza entre los objetos que van a ser agrupados. A diferencia de los métodos de clasificación usualmente empleados, en el ASI se emplea el índice de similaridad de Lerman, que es la probabilidad de que el número observado de copresencias entre dos variables sea mayor o igual que el de las copresencias esperadas por el azar.
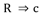
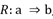

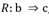
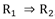
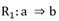
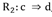
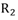

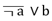
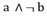
Además de los procedimientos antes descritos, el ASI permite cuantificar el aporte de cada individuo en la formación de las estructuras que se obtienen a partir de los índices de cohesión y de similaridad, para lo cual emplea la contribución o la tipicalidad de cada sujeto. La tipicalidad es un índice porcentual que mide cómo se comporta un individuo en relación a la regla o a la clase, llamando sujeto típico a aquél que verifica todas las implicaciones (similaridades) que poseen mayor intensidad de implicación (índice de similaridad) en la formación de las reglas (clases). La contribución cuantifica el aporte de un determinado individuo en la formación de la regla o de la clase.
Razones que hacen posible el empleo del ASI en el estudio de la causalidad en salud
Hechos concretos hacen posible la utilización de esta técnica en la identificación de factores pronósticos o de riesgo. Entre ellos estas autoras han identificado los siguientes:
Existe la herramienta informática que permite el procesamiento automatizado para la aplicación del ASI: es un software específico designado por el acrónimo CHIC (del francés: Classification Hiérarchique Implicative et Cohésitive que significa Clasificación Jerárquica, Implicativa y Cohesitiva), el cual proporciona de forma rápida, gran cantidad de cálculos y gráficos.10-12
No requiere del cumplimiento de supuestos para que sus resultados sean válidos.
Admite el tratamiento de variables medidas en cualquier escala, binarias, modales, frecuenciales, de intervalo y hasta difusas, sin distinción entre variables dependientes e independientes o covariables.
No tiene restricción en cuanto al número de variables o requisitos que deben cumplir para entrar o salir del análisis.
Las variables pueden ser analizadas como variables principales o suplementarias, tanto en el análisis cohesitivo como en el de similaridad.La variable suplementaria es extrínseca al estudio, no interviene directamente en las relaciones entre las variables principales, pero permite esclarecer la importancia o la superfluidad de estas categorías en la formación de las reglas o meta reglas. Generalmente se emplean variables modales como variables suplementarias. Esta posibilidad puede ser aprovechada en los estudios de causalidad en biomedicina para determinar cuánto contribuyen los casos o los controles a la formación de las relaciones entre las variables, empleando las variables que representan el desenlace como suplementarias.
No hay criterios restrictivos en cuanto al tamaño de muestra para la aplicación. Se puede trabajar con muestras pequeñas o extremadamente grandes. En dependencia del tamaño de muestra se seleccionará una distribución u otra a la hora de estimar los índices en el análisis. La distribución que siguen estas variables aleatorias depende del patrón asumido para seleccionar los subconjuntos, pudiendo ser la hipergeométrica (cuando la población es finita y la muestra es de tamaño fijo), binomial (población infinita y tamaño de muestra fijo) o Poisson (población infinita y tamaño de muestra aleatorio). Bodín13 detalla los modelos y pruebas de hipótesis para cada distribución. El trabajo con muestras grandes requiere que el investigador elija el enfoque entrópico a la hora de llevar a cabo el análisis implicativo. El cálculo del tamaño de muestra dependería del diseño empleado en el estudio, generalmente caso y control o cohorte.14,15
Permite estimar la relación existente entre una variable dependiente y una o más variables independientes, así como la relación entre las propias variables independientes, es decir, muestra todas las relaciones entre las variables con diferentes intensidades de implicación. A medida que el investigador selecciona una intensidad de implicación menor aparecen nuevas variables y nuevas relaciones entre ellas.
Permite el trabajo con cuatro niveles de intensidad implicativa a la vez, que se modifican según el criterio del investigador y que permiten un análisis más amplio y una interpretación más completa del fenómeno de la causalidad. A medida que el investigador decide disminuir este nivel pueden aparecer nuevas relaciones y/o nuevas variables se incluyen en la trama causal.
Por restringirse a sucesos frecuentes desoye lo trivial, por lo que no se afectan sus resultados frente a observaciones raras o atípicas.
Aporta información diferente al resto de los análisis estadísticos mediante sus tres índices básicos: de similaridad, de cohesión y de implicación. Además muestra indicadores como: la frecuencia absoluta de ocurrencia de cada variable, su media y desviación estándar, la frecuencia de ocurrencia de cada pareja de variables que se pueden formar y sus coeficientes de correlación.
Los resultados se presentan en tres gráficos que facilitan la interpretación de los mismos: arboles de similaridad, de cohesión y el grafo implicativo que puede ser general y también en modo cono según decida el investigador. Estas autoras consideran apropiado formar dos grafos en modo cono para la identificación de factores de riesgo o pronóstico ubicando en cada cono el peor y mejor desenlace. También se muestran múltiples cuadros donde constan las frecuencias absolutas de ocurrencia de cada variable, sus medias y desviaciones estándares, las frecuencias de ocurrencias de cada par de variables que se pueden formar, así como sus coeficientes de correlación, los índices de similaridad, de cohesión implicativa y de implicación inclusión, las tipicalidades y contribuciones de los individuos.
Es muy atractivo al brindar índices y gráficas, creados automáticamente, donde es fácil apreciar las relaciones entre todo el conjunto de variables. Los grafos implicativos generados son similares a los diagramas causales (grafos acíclicos dirigidos o DAG de sus siglas en inglés Directed Acyclic Graphs) que permiten plantear posibles rutas de asociación entre causas y efectos, así como otras rutas alternativas que pueden ocasionar sesgos por lo que facilitan también el control de posibles sesgos.16-19) Los DAG permiten identificar los factores que influyen sobre un desenlace pero no permiten identificar si influyen a favor o en contra de este. Sin embargo, estas autoras consideran que mediante el grafo implicativo en modo cono del ASI se puede reconocer cuando un factor es protector o de riesgo.
Puede servir como método gráfico para el análisis exploratorio de datos, por ejemplo, para decidir entre las variables a incluir en un modelo de regresión.
Este análisis no se contradice con el análisis actual, sino que lo complementa y enriquece desde una perspectiva diferente. El mismo está acorde con el paradigma de la complejidad que se propone actualmente, ya que cumple con sus principios tales como: el principio dialógico al asociar nociones contradictorias que forman parte del mismo fenómeno como los ejemplos y contraejemplos, el principio hologramático al suponer las partes en el todo y el todo en las partes y ver el todo como algo complejo, no como la simple suma de sus partes y el principio de la recursividad que rompe con la relación lineal entre causa y efecto. Por tanto resulta atrayente su empleo, teniendo en cuenta que los fenómenos biomédicos pueden ser complejos, abiertos, dinámicos, sensibles a pequeñas variaciones de sus condiciones iniciales, de sus fluctuaciones internas y/ o fluctuaciones externas que los desestabilizan.2,20
Ventajas del ASI con respecto a las técnicas estadísticas tradicionales
Algunas diferencias del ASI con las técnicas estadísticas tradicionales constituyen ventajas que justifican su empleo y reafirman su utilidad, por ejemplo:
Las técnicas tradicionales de asociación, como las pruebas de independencia y homogeneidad de chi cuadrado, dadas dos variables A y B, se basan en la estimación de la frecuencia de ocurrencia de “A y B” y de “no A y no B”, sin embargo, no tienen en cuenta la rareza de ocurrencia de “A y no B”, lo cual las invalidan para descubrir sucesos raros.3 El ASI encuentra sucesos raros, que pasan inadvertidos a medidas como el soporte y la confianza.
Los coeficientes de correlación paramétricos y no paramétricos están basados en medidas lineales y simétricas. Las demás técnicas multivariadas de análisis de conglomerados, análisis factorial y análisis de correspondencias están basadas en matrices de covarianzas o de correlaciones, o las nociones simétricas de similaridad y distancia. En el ASI todos los índices son asimétricos, no lineales, en correspondencia con la complejidad de los procesos naturales como la salud-enfermedad.
El análisis de senderos, el modelo multivariado más empleado en las ciencias sociales para probar conjuntos de supuestos causales entre variables, solo tiene en cuenta las relaciones entre variables de tipo lineal o aditiva y excluye las relaciones curvilíneas y multiplicativas (de interacción). Además requiere como supuestos la homocedasticidad de varianzas y baja multicolinealidad.21Estos requerimientos son superados en el ASI.
La regresión logística binaria, la más popular y empleada de las técnicas estadísticas para el estudio de la causalidad en ciencias médicas, identifica solamente factores con fuerte asociación a un desenlace a partir de un reducido conjunto de posibles factores causales, no permite visualizar las relaciones existentes entre el conjunto completo de variables estudiadas, ya que al considerar la no existencia de multicolinealidad como supuesto básico conlleva a excluir del modelo las covariables correlacionadas. Algunos autores como Silva22 coinciden que el modelo logístico requiere de la existencia de una relación lineal entre el logit de la probabilidad del suceso de interés y las variables independientes, que algunas observaciones “raras” pudieran tener una influencia exagerada en las estimaciones de los parámetros del modelo o que otra función distinta de la logística fuese mejor para describir las observaciones a pesar de un buen ajuste del modelo a los datos. Dunkler23 plantea que el procedimiento paso a paso hacia detrás puede excluir confusores del modelo o dejar falsos confusores, dado que la selección se realiza a través de algoritmos basados en el valor p (índice decreciente de la fiabilidad de un resultado), sin la opinión del investigador. Además, si se incluyen muchas variables, se requiere un tamaño de muestra grande, de al menos 10 sujetos por cada variable independiente para lograr estimaciones adecuadas. Como se planteó antes, todas estas dificultades son superadas por el ASI.
Investigaciones de causalidad en salud que demuestran la utilidad del ASI
Relativo a la aplicación de esta técnica para estudiar causalidad en el campo de las ciencias médicas, al explorar vía internet, los catálogos de publicaciones, sitios y las bases de datos de carácter biomédico, se encontró el estudio de La Spada24de seguimiento de pacientes positivos al virus de la hepatitis C con transaminasas séricas persistentemente normales y las investigaciones previas de estas autoras conducentes a la formación de especialistas en Bioestadística de las provincias orientales Santiago de Cuba, Guantánamo y Granma. Estos últimos trabajos han validado la efectividad del ASI en la identificación de factores pronósticos o de riesgo utilizando como estándar de oro la regresión logística binaria al ser aplicada en estudios observacionales de tipo casos y controles clásicos o anidados en una cohorte. Para realizar la validación de la capacidad diagnóstica del ASI se han estimado en cada estudio realizado indicadores como: sensibilidad, especificidad, valores predictivos, razones de verosimilitud, índice de validez, odds ratio de diagnóstico, entre otros.25-29
Los resultados obtenidos de estas investigaciones reafirman la utilidad de esta técnica en el contexto médico.
Consideraciones Finales
En el ASI se establece una cuasi-implicación entre variables, que es una relación asimétrica, donde los conjuntos de reglas obtenidas pueden conducir a hipótesis de causalidad sin restricción con respecto al número de variables y al tamaño de la muestra. Basado en el número de contraejemplos, tiene capacidad predictiva y sus resultados son extrapolables a distintos tamaños de muestras, encuentra sucesos raros, que pasarían desapercibidos a medidas como el soporte y la confianza, por restringirse a sucesos frecuentes y no se afecta por observaciones atípicas, todo lo cual constituye una ventaja inminente sobre las técnicas estadísticas clásicas empleadas para identificar posibles factores causales.
La identificación de las razones anteriores y algunas ventajas del ASI con respecto a las técnicas estadísticas tradicionales, unido a los resultados de los estudios clínico-epidemiológicos para la identificación de factores pronósticos y de riesgo llevados a cabo con el empleo de esta técnica han demostrado su validez y posibilidades de empleo en este campo.

