










 Custom services
Custom services
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
Introducción
La Neurociencia es una disciplina conformada por un sin número de ciencias, está aportando investigaciones valiosas, principalmente porque todas están enfocadas a estudiar desde distintas direcciones la estructura y organización funcional del sistema nervioso, particularmente el cerebro. 1 Dentro de las Ciencias Biomédicas, el término neurociencias es relativamente reciente, su actual empleo corresponde a la necesidad de integrar las contribuciones de las diversas áreas de la investigación científica y de las ciencias clínicas para la comprensión del funcionamiento del sistema nervioso. Esta ciencia cobija un área del conocimiento que se encarga desde el funcionamiento neuronal hasta el comportamiento de un ser vivo. Obviamente, la comprensión del funcionamiento del cerebro normal favorece el conocimiento y la comprensión de anormalidades neurobiológicas que causan desórdenes mentales y neurológicos. [2)
Dentro de la Neurociencia se encuentran disímiles términos, uno de ellos los neurodatos; los cuáles son el conjunto de información relativa a la actividad cerebral obtenida mediante el empleo de neurotecnologías avanzadas. Estas llamadas neurotecnologías son el conjunto de herramientas que sirven para analizar e influir sobre el sistema nervioso del ser humano, especialmente sobre el cerebro. 3
Se han desarrollado múltiples plataformas y proyectos a nivel mundial basados en las neurociencias. Estos han sido desarrollados bajo las premisas del análisis y procesamiento de los datos del cerebro, para su posterior estudio, en ellos se tiene como objetivo principal el reconocimiento de enfermedades. Entre los proyectos desarrollados se encuentra el proyecto BRAIN, el cual se basa en realizar un mapeo cerebral para el descubrimiento de enfermedades degenerativas. (4 Del anterior surgió su homólogo, el proyecto HUMAN BRAIN; este pretende elaborar un modelo computarizado del cerebro humano que permita simular su funcionamiento en condiciones y situaciones extraordinarias. (5 HUMAN BRAIN utiliza tecnologías de la información y la comunicación (TICs ) avanzadas en neurociencia para comprender mejor el encéfalo y sus enfermedades. En cuanto al manejo de neurodatos tenemos a la plataforma CBRAIN que se encarga principalmente de la investigación de neuroimágenes y los estudios de enfermedades neurológicas. (6
El Centro de Neurociencias de Cuba (CNEURO), es la institución cubana encargada de este tópico en la isla, está dedicado a la investigación traslacional en neurociencia, neurotecnología y otras tecnologías médicas. Abarca desde la investigación básica hasta el desarrollo, producción y comercialización de tecnologías. La entidad lleva a cabo investigaciones en una amplia gama de temas que incluyen neurociencia cognitiva, neuroinformática, neuroimagen funcional, análisis de señal bioeléctrica, modelación matemática, investigación neuroquímica, genética molecular e impresión 3D para dispositivos médicos. Entre sus áreas de especial interés se encuentran: desarrollo de nuevos métodos de neuroimagen, búsqueda de nuevos biomarcadores, enfoques de diagnóstico y moléculas terapéuticas para la enfermedad de Alzheimer, el desarrollo de tecnologías basadas en neuroinformática para el análisis de datos de electroencefalogramas (EEG) y resonancias magnéticas (MRI) en condiciones cerebrales normales y patológicas.
La institución es la coordinadora del Programa Nacional de Ciencia y Tecnología de Neurociencia y Neurotecnologías, por lo que trabaja en estrecha colaboración con distintas entidades, una de ellas la Universidad de las Ciencias Informáticas, la cual a partir de las investigaciones conjuntas con CNEURO desarrolló y aprobó un proyecto de investigación nacional denominado BrainSSys. El proyecto tiene entre sus objetivos desarrollar una plataforma digital para la estructuración, manejo de bases de datos multimodales de neurociencias y análisis de datos estandarizados del cerebro.
Del proyecto anterior se derivó un repositorio de datos de neurociencias para el almacenamiento y manejo de neurodatos, teniendo en cuenta la gran cantidad de datos que se procesan, como ficheros o datos en formatos diferentes como dcm, edf, nii, plg, mnc, entre otros, generándose una gran variedad de extensiones. Los estudios de neuroimágenes y señales dan como resultado datos complicados que se pueden organizar de muchas formas diferentes. Esta variedad de extensiones y cantidad de datos dificulta el análisis y la estandarización de las fuentes de datos aptas para el proceso de investigación. Otro de los conflictos presentados es que procesar estadísticamente el cúmulo de datos se hace extremadamente difícil sin el uso de herramientas y mecanismos automatizados que lo faciliten.
Los repositorios de datos surgieron como solución a la problemática del almacenamiento de grandes cantidades de datos. Con el paso del tiempo, los datos se vuelven cada vez más importantes para la toma de decisiones. Esto significa que se precisa de plataformas que puedan recopilar, almacenar y analizar datos. Un repositorio de datos es una de esas entidades de almacenamiento virtual que puede ayudar a consolidar y gestionar datos empresariales. 7
Un repositorio de datos, a menudo denominado archivo o biblioteca de datos, es una terminología genérica que se refiere a un conjunto de datos segmentados que se utiliza para realizar informes o análisis. Los repositorios de datos permiten el desarrollo de investigaciones, el descubrimiento de conocimiento y la prueba de nuevos algoritmos de aprendizaje.
El repositorio de neurodatos actualmente se encuentra en fase de implantación contiene un grupo de bases de datos integradas y almacenadas, aunque en este se imposibilita el acceso a la cantidad de datos, cantidad de base de datos, sus características y la obtención de metadatos. En este repositorio la toma de decisiones se ve comprometida debido a que no se puede visualizar gráficamente su comportamiento general, en cuanto al volumen de información que se almacena, lo cual dificulta los análisis por tipos de base de datos y cantidad de participantes de un estudio realizado.
Las neurociencias tienen un campo de acción extenso, incluyendo ciertas subdisciplinas como neuroimagen, neurobioquímica, neuroanatomía y biología molecular, en donde se trabaja con diferentes especies como; ratones, ratas y seres humanos; que requieren de la gestión y organización de grandes colecciones de datos de muchas modalidades y fuentes como grabaciones neurológicas, estímulos externos, grabaciones de respuestas y eventos externos.
Neurociencia y neuroinformática
Como se ha planteado el término neurociencia, hace referencia a campos científicos y áreas de conocimiento diversas, que, bajo distintas perspectivas de enfoque, abordan los niveles de conocimiento vigentes sobre el sistema nervioso. Es, por tanto, una denominación amplia y general, su objeto es extraordinariamente complejo en su estructura y funciones, tanto como en las interpretaciones científicas de ambas. No sólo debe ser considerada como una disciplina, sino que es el conjunto de ciencias cuyo sujeto de investigación es el sistema nervioso con particular interés en cómo la actividad del cerebro se relaciona con la conducta y el aprendizaje. 8
Dos de los términos relacionados son neuroinformática y neuroimágenes. Las neuroimágenes (Nimg) constituyen un medio no invasivo de estudiar la estructura y funcionamiento cerebral. Se dividen en estructurales (cuando brindan información anatómica) y funcionales cuando se relacionan con su funcionamiento, ya esté expresado a través de la actividad eléctrica, magnética y/o metabólica del cerebro. A su vez, la Neuroinformática (Ninf) es una disciplina que facilita el procesamiento de las Nimg para establecer su relación con datos conductuales o estados particulares de grupos o sujetos de observación. 9.
Neuroinformática es un término utilizado en relación al campo de investigación de la neurociencia mediante la aplicación de modelos computacionales y herramientas analíticas. Estas áreas de investigación son importantes por la cada vez mayor integración y análisis de grandes volúmenes de datos en detalle. Los neuroinformáticos cumplen la función de creación y desarrollo de herramientas computacionales, modelos matemáticos y base de datos interoperables para sus usos científico, clínico y de investigación. 10
Las plataformas y recursos en la Web basadas en las neurociencias son cada vez más importantes debido a que han llegado como una nueva propuesta a la hora de diagnosticar e intervenir diferentes patologías físicas, psicológicas y emocionales, ofreciendo alternativas a las opciones tradicionales como la psiquiatría, permitiendo a las personas tener un nivel de entendimiento más profundo y a la vez orgánico de sus síntomas o dificultades. 3
Teniendo en cuenta los problemas planteados con anterioridad se definió como objetivo del presente trabajo desarrollar funcionalidades para el repositorio de datos de neurociencias que propicien la generación de estadísticas y reportes.
Materiales y métodos
Para el desarrollo de la presente investigación se emplearon métodos teóricos:
Método analítico-sintético: Permitió analizar los principales conceptos relacionados con los repositorios de datos y datos de neurociencias, extrayendo los aspectos fundamentales que sirvieron de apoyo para el desarrollo de la investigación.
Método histórico-lógico: Se utilizó para estudiar y determinar la evolución, comportamiento y tendencias actuales de las tecnologías y herramientas existentes para repositorios de datos y sistemas que gestionan reportes y estadísticas.
Método inductivo-deductivo: Permitió determinar la problemática y elementos particulares en el estudio del repositorio de datos de neurociencias.
Además los siguientes métodos empíricos:
Entrevista: posibilitó la recolección de información a través de conversaciones planificadas con especialistas de Neurociencias.
Observación: se utilizó como método para validar la propuesta de solución.
Modelación: se empleó como recurso auxiliar en la búsqueda teórica para caracterizar y representar mediante diagramas el campo de acción de la investigación.
Se realizó una amplia revisión y análisis de la información existente para actualizar el estado del arte de las herramientas que permiten generar reportes y estadísticas de los datos almacenados en un repositorio o en una base de datos.
Se seleccionó la metodología de desarrollo Extreme Programming (XP), debido a las características de la solución a desarrollar. Para el modelado se utilizó UML en su versión 2.0, la herramienta CASE Visual Paradigm 16.3 y Matplotlib, una biblioteca completa para crear visualizaciones estáticas, animadas e interactivas en Python. Para la permanencia de los datos se utilizó PostgreSQL en su versión 13.0.
Como lenguaje de programación se utilizó Python 3.9 por la legibilidad de su código y por ser un lenguaje interpretado, dinámico y multiplataforma. Como entorno integrado de desarrollo se utilizó PyCharm en su versión 20.1.
Como marco de trabajo se utilizó Angular en su versión 12.1.4 y el marco Web de alto nivel Django en su versión 3.2 por fomentar un desarrollo rápido y un diseño limpio y pragmático, además de ser gratuito y de código abierto.
Resultados y Discusión
A continuación, se realiza un análisis del estado del arte de las herramientas que permiten generar reportes y estadísticas de los datos almacenados en un repositorio o en una base de datos. Este análisis fue útil para identificar las formas de gestión de reportes y estadísticas, así como su interacción con todos los flujos de datos. El análisis se realizó de acuerdo a las siguientes características:
Trabajo con datos de neurociencias.
Generación de estadísticas a partir de datos almacenados.
Generación de reportes para el análisis.
Si es una plataforma de acceso gratuito.
Si es de código abierto o no.
GeReport es una herramienta destinada al diseño, generación y configuración de los reportes relacionados con los datos históricos almacenados en una fuente de datos. Además, luego de contar con toda la información del reporte es posible exportarlo como imagen y en los formatos HTML, PDF y Excel. Para la interacción con las aplicaciones externas, el sistema implementa un servicio que expone los metadatos de los reportes para poder utilizarlos sin restricciones de lenguajes y plataformas. El sistema se creó sobre un entorno Web y se desarrolló siguiendo lo establecido por el Proceso Unificado de Desarrollo (RUP), utilizando UML como lenguaje de modelado. Para la gestión de la base de datos se seleccionó PostgreSQL, en la implementación se utilizaron los lenguajes de programación PHP, con CodeIgniter 2.0 como marco de trabajo del lado del servidor y JavaScript con Dojo Toolkit 1.8 para el trabajo del lado del cliente. Se utiliza en la Universidad de Cienfuegos por analistas y programadores del Grupo de Estudios y Desarrollo de Ingeniería y Sistemas, perteneciente a la Facultad de Ingeniería. 11
GeReport no trabaja con datos de neurociencias. Permite generar estadísticas a partir de datos almacenados, así como reportes sobre los cuales se pueden realizar análisis. No es una plataforma de acceso gratuito y no posee código abierto ni utiliza tecnologías libres.
El Instituto Donders para el Cerebro, la Cognición y el Comportamiento, de los Países Bajos es un centro de investigación líder en el mundo dedicado a comprender los fundamentos mecánicos de la cognición y el comportamiento humanos en la salud y la enfermedad. Allí se desarrolló un repositorio de nombre Donders, que es utilizado por 2 331 investigadores para gestionar sus datos de investigación, estos datos están organizados en 780 colecciones de adquisición de datos en curso y 121 finalizadas, 553 colecciones de documentación de investigación en curso y 68 finalizadas y 237 colecciones de intercambio de datos en curso y 189 publicadas. Todo el mundo puede solicitar el acceso a las colecciones de intercambio de datos publicadas, publicar datos a la comunidad científica en general, archivar de forma segura los datos que no se pueden compartir públicamente para promover la integridad científica y la reutilización interna, colaborar con colegas dentro y fuera de la Universidad de Radboud, sede del Instituto Donders, hacer que los datos sean localizables y citables asignando un identificador de objetos digitales (DOI) y metadatos enriquecidos a cada colección, gestionar fácilmente quién tiene acceso para ver y/o editar los datos, cumplir con los recientes movimientos de gestión de datos de investigación y con las políticas actuales de la Universidad de Radboud. 12
Donders trabaja con datos de neurociencias. No permite generar estadísticas a partir de datos almacenados, pero permite generar reportes sobre los cuales se pueden realizar análisis. Es una plataforma de acceso gratuito y no posee código abierto ni utiliza tecnologías libres.
OpenNeuro es una plataforma gratuita y abierta para analizar, validar y compartir datos de neuroimágenes como MRI (resonancia magnética), PET (tomografía por emisión de positrones), MEG (magnetoencefalografía), EEG (electroencefalograma) e iEEG (electroencefalograma intracraneal) compatibles con BIDS (estructura de datos de las imágenes cerebrales), el cual es un estándar emergente para la organización de datos de neuroimágenes. 13
OpenNeuro (antes conocido como OpenfMRI) es un repositorio de datos de neuroinformática de ciencia abierta que almacena conjuntos de datos de estudios de investigación de imágenes del cerebro humano. La base de datos está disponible en línea. Los investigadores de neuroimagen que hayan realizado un estudio de este tipo pueden cargar sus datos en el sitio. Los investigadores de terceros pueden descargar los datos y utilizarlos, por ejemplo, para reanalizarlos.
OpenfMRI fue precedido por otras dos bases de datos de neuroimagen en línea: fMRI Data Center (fMRIDC) y el 1000 Functional Connectomes Project (FCP), disponible a través del Neuroimaging Informatics Tools and Resources Clearinghouse Image Repository. El fMRIDC recoge el mismo tipo de datos que OpenfMRI, pero los distribuye a través de soportes físicos. Ya no acepta el envío de datos. El FCP recogía datos de estudios de fMRI en estado de reposo. En febrero de 2018, OpenfMRI pasó a llamarse oficialmente OpenNeuro para reflejar una gama más amplia de datos aceptados y cambió a una nueva plataforma de envío y gestión de datos. 14
OpenNeuro trabaja con datos de neurociencias. No permite generar estadísticas a partir de datos almacenados, mas, permite generar reportes sobre los cuales se pueden realizar análisis. Es una plataforma de acceso gratuito, posee código abierto y utiliza tecnologías libres.
Mediante el análisis de los sistemas informáticos vinculados a los sistemas de gestión de reportes y estadísticas, se determina que sirven de base de conocimiento para la definición de las funcionalidades y características que debe tener la solución de esta investigación. Aun cuando no todos trabajan con neurodatos, tienen como principal objetivo generar reportes, lo cual constituye la base de las funcionalidades a desarrollar. Además, el hecho de que algunos de estos sistemas no sean de código abierto impide conocer a profundidad las particularidades de los mismos. Imposibilitando garantizar su soporte y sostenibilidad, lo cual limita su desarrollo e innovación con nuevas funcionalidades específicas para el contexto de las investigaciones cubanas en neurociencias.
Una vez realizado este análisis se determina que, para las necesidades de estadísticas y reportes de datos de neurociencias, ninguno de los sistemas cumple con todas las características funcionales que necesita el cliente, por lo cual no se podría trabajar sobre uno de ellos. Dadas estas condiciones se decidió utilizar el sistema OpenNeuro como guía para desarrollar las funcionalidades necesarias, siendo este el más adecuado debido a que presenta la mayoría de las características deseadas.
Las funcionalidades propuestas en esta investigación permiten generar estadísticas y reportes de datos de neurociencias para el repositorio cubano. Se crea con el objetivo de responder a la necesidad de propiciar el correcto uso de la información relevante para la toma de decisiones y subsanar las deficiencias del problema existente.
Un modelo de proceso de negocio describe cómo funciona el negocio y las actividades involucradas, así como la manera en que se relacionan unas con otras e interactúan con los recursos necesarios para lograr la meta del proceso, especifica además sus datos, roles y reglas. Sirve para facilitar la comprensión de los mecanismos claves de un negocio y de base para la creación de sistemas de información apropiados que den soporte al mismo. En el modelo del negocio se identifican como procesos del negocio la gestión de reportes y de estadísticas.
El proceso de generar reportes inicia una vez que este sea solicitado por un usuario anteriormente autenticado en el repositorio. Para su solicitud el usuario solo tiene que seleccionar la opción del reporte que desea generar. Al generarse un reporte se le muestran al usuario todos los datos según los criterios de búsqueda que este haya seleccionado. En algunos casos es necesario que el usuario introduzca o seleccione algunos campos obligatorios para que se pueda generar dicho reporte.
El proceso de graficar estadísticas comienza cuando se cuenta con los datos pertinentes alojados en el repositorio, en caso contrario no se podrá graficar estas estadísticas. El usuario debe de seleccionar la modalidad a graficar, una vez hecho esto se le mostrarán en pantalla las estadísticas.
Los actores del negocio son las personas que interactúan con el negocio para beneficiarse de sus resultados. Ellos se agrupan en diferentes roles, descritos a continuación:
Tabla 1 Personas que intervienen en el negocio. Fuente: los autores.
| Nombre | Descripción |
|---|---|
| Investigador | Solicita un reporte de los datos y estadísticas seleccionando el tipo o tipos de datos que desee. |
| Administrador | Solicita un reporte de los datos y estadísticas seleccionando el tipo o tipos de datos que desee. Puede modificar los datos de los reportes y estadísticas. |
El análisis de requisitos es una de las tareas más importantes en el ciclo de vida del desarrollo de software, puesto que en ella se determinan los “planos” de la nueva aplicación. El análisis de requisitos se puede definir como el proceso del estudio de las necesidades de los usuarios para llegar a una definición de los requisitos del sistema, hardware o software, así como el proceso de estudio y refinamiento de dichos requisitos. En la presente investigación se identificaron 18 requisitos funcionales y seis requisitos no funcionales relacionados con las estadísticas de las bases de datos, los datos y metadatos del repositorio.
Las metodologías ágiles como XP generan artefactos ingenieriles como las Historias de Usuario (HU) que sustituyen a los documentos de especificación funcional, y a los casos de uso. Se utilizaron con el fin de especificar los requisitos del software y fueron escritas por el cliente, en su propio lenguaje, como descripciones cortas de lo que el sistema debe realizar. 15
A partir de varias tablas fueron descritas brevemente las características deseadas. Las HU también se utilizaron para estimar el tiempo que le tomó al equipo de desarrollo para realizar las entregas, se programaron en un tiempo aproximado de nueve meses.
El término arquitectura de la información es un concepto utilizado en su forma más amplia para expresar el diseño, organización y distribución de los sistemas informáticos. La arquitectura de la información brinda muchos beneficios al ubicar rápidamente la información, encontrar con el menor esfuerzo, establecer relaciones o enlaces, además de reducir costos de mantenimiento y procesos de reingeniería.
Para el diseño del sistema se utilizará el patrón Modelo Vista Controlador (MVC), garantizando así la organización del código fuente de la aplicación, dividiéndola en tres componentes, el modelado del dominio, la presentación y las clases controladoras. En este patrón, el "Modelo" referencia el acceso a la capa de datos, la "Vista" se refiere a la parte del sistema que selecciona qué mostrar y cómo mostrarlo, y el "Controlador" implica la parte del sistema que decide qué vista usar, dependiendo de la entrada del usuario, accediendo al modelo si es necesario.
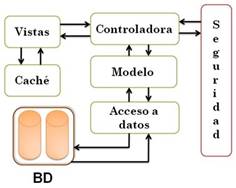
Se hizo uso también del modelo CRC (Clase-Responsabilidad-Colaboración) que utiliza tarjetas de índices reales o virtuales para la descripción de las principales clases desarrolladas. La característica más sobresaliente de las tarjetas CRC es su sencillez y adaptabilidad, en donde se representan cada una de las clases del sistema.
Las responsabilidades se representaron como los atributos y operaciones relevantes para la clase. Los colaboradores se representaron como aquellas clases que se requieren para dar a una clase la información necesaria a fin de completar una responsabilidad, es decir, una colaboración implica una solicitud de información o de cierta acción. 16
Los patrones de diseño son soluciones a problemas típicos y recurrentes que se pueden encontrar a la hora de desarrollar una aplicación. Establecen un lenguaje común para programar. Identifica clases, instancias, roles, colaboraciones y distribución de responsabilidades. Provee un esquema para refinar componentes de un sistema de software y la forma en que se relacionan entre sí. 17
Describe una estructura generalmente recurrente de comunicación de componentes que resuelve un problema de diseño general dentro de un contexto particular, lo cual permite un lenguaje de programación de alto nivel. Los patrones de diseño utilizados: GRASP Creador, Controlador, Experto, Bajo Acoplamiento y Alta Cohesión, en conjunto con los estándares de codificación especificados permitieron estructurar la solución respondiendo a diversos problemas en la implementación de los requisitos funcionales.
El patrón creador ayuda a identificar quién debe ser el responsable de la creación (o instanciación) de nuevos objetos o clases. La nueva instancia deberá ser creada por la clase que tiene la información necesaria para realizar la creación del objeto, o usa directamente las instancias creadas del objeto, o almacena o maneja varias instancias de la clase. Una de las consecuencias de usar este patrón es la visibilidad entre la clase creada y la clase creador.
El GRASP de experto en información es el principio básico de asignación de responsabilidades. Consiste en la asignación de una responsabilidad a la clase que cuenta con la información necesaria para llevarla a cabo. Determina cuál es la clase que debe asumir una responsabilidad a partir de la información que posee cada una. En pocas palabras la creación de un objeto o la implementación de un método, debe recaer sobre la clase que conoce toda la información necesaria para crearlo.
Un controlador es un objeto de interfaz no destinada al usuario que se encarga de manejar un evento del sistema. Sirve como intermediario entre una determinada interfaz y el algoritmo que la implementa, de tal forma que es la que recibe los datos del usuario y la que los envía a las distintas clases según el método llamado. Sugiere que la lógica de negocios debe estar separada de la capa de presentación, esto permite aumentar la reutilización de código y a la vez tener un mayor control.
En la perspectiva del diseño orientado a objetos, la cohesión o cohesión funcional es una medida que muestra que tan relacionadas y enfocadas están las responsabilidades de una clase. Una alta cohesión caracteriza a las clases con responsabilidades estrechamente relacionadas que no realicen un trabajo enorme, clases con responsabilidades moderadas en un área funcional que colaboran con las otras para llevar a cabo las tareas.
El acoplamiento es una medida de la fuerza con que una clase está conectada a otras clases, con que las conoce y con que recurre a ellas. Propone tener las clases lo menos ligadas entre sí, de tal forma que, en caso de producirse una modificación en alguna de ellas, se tenga la mínima repercusión posible en el resto de clases. El bajo acoplamiento soporta el diseño de clases más independientes y reutilizables, lo cual reduce el impacto de los cambios y acrecienta la oportunidad de una mayor productividad.
Los patrones GOF (Gang of Four) constituyen una herramienta fundamental para cualquier programador. Estos son utilizados para resolver problemas de creación de instancias, abstrayendo dichas creaciones. 18
El patrón Observador (Observer) define una dependencia uno a uno entre dos o más objetos para transmitir todos los cambios de un objeto de la forma más sencilla y rápida viable. Se empleó en la clase DiagnosticInformer, para informar al usuario sobre los cambios que se realizan sobre los participantes.
El patrón Plantilla (Template) busca definir el esqueleto de un algoritmo para una operación, dejando para sus subclases la capacidad de redefinir el funcionamiento de los pasos de este. Se utilizó en vistas genéricas permitiendo que las subclases de esta puedan redefinir los pasos de un algoritmo sin alterar la estructura de dicho algoritmo.
Los modelos de datos aportan la base conceptual para diseñar aplicaciones que hacen un uso intensivo de datos. El diseño de una base de datos consiste en definir la estructura de los datos que debe tener un sistema de información determinado. Para ello se suelen seguir por regla general unas fases en el proceso de diseño, definiendo para ello el modelo conceptual, el lógico y el físico. Generalmente es usado para describir la representación lógica y física de la información persistente manejada por el sistema.
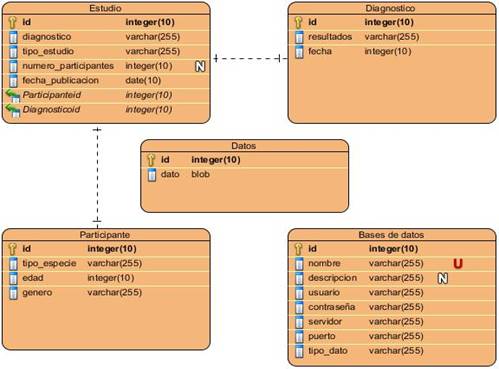
La especificación de las tareas de programación permitió obtener un desglose por unidades de las funcionalidades encapsuladas mediante las historias de usuario. Los diseños de los casos de prueba de aceptación y unidad permitieron guiar la ejecución de las actividades de verificación y validación para un correcto funcionamiento de la aplicación. Las no conformidades resultantes por iteraciones permitieron realizar un análisis incremental sobre las funcionalidades desarrolladas, logrando así todos los objetivos propuestos.
Conclusiones
El análisis de las tecnologías y soluciones homólogas internacionales demostró que estas no pueden ser utilizadas como propuesta de solución, debido a ello la necesidad de implementar funcionalidades de estadísticas y reportes para satisfacer las necesidades del cliente.
El análisis de los procesos del negocio permitió definir las funcionalidades asociadas a las estadísticas y reportes, junto a su integración al repositorio de datos de neurociencias facilitando la toma de decisiones en la utilización de información relevante.
La definición de metodologías, tecnologías y herramientas permitieron una fácil integración de las funcionalidades a desarrollar.
Los artefactos obtenidos al aplicar la metodología definida propiciaron la comprensión de los elementos a tener en cuenta para su ejecución; esto permite codificar la solución en una propuesta ajustada a las necesidades de desarrollo del cliente.
Se definió una estrategia de pruebas a seguir para validar la propuesta de solución y garantizar la calidad final del producto.

