










 Custom services
Custom services
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
El aprendizaje supervisado tradicional, como uno de los paradigmas de aprendizaje automático más adoptados en sistemas y aplicaciones inteligentes del mundo real, favorece la toma de decisiones rápidas y precisas para las tareas de regresión y predicción. El aprendizaje supervisado se caracteriza por utilizar ejemplos del dominio de aplicación, previamente etiquetados, y con ello aprender modelos que permitan estimar nuevos ejemplos no empleados en el conjunto de entrenamiento. El Aprendizaje supervisado estándar asume que los ejemplos son autocontenidos, esto es, que toda la información necesaria para hacer una predicción está contenida en la descripción del objeto. La descripción del objeto, en general, está dada en forma de pares ordenados (atributo, valor) donde los valores pueden ser numéricos, categóricos o una mezcla de ellos. La naturaleza de la etiqueta asignada a un ejemplo tiene grandes implicaciones en los algoritmos supervisados.
Dependiendo de la naturaleza de la variable objetivo, los problemas de aprendizaje pueden ser clasificados en predicción, para valores reales, o clasificación, para datos categóricos. Si la etiqueta puede tomar valores con tinuos entonces la tarea de predicción se conoce como Regresión. En ambos casos, el algoritmo de aprendizaje debe sintetizar un modelo que sea capaz de predecir la etiqueta de un ejemplo desconocido a partir de sus variables predictoras (James et al., 2013). Entre las áreas de aplicación de los modelos de regresión podemos mencionar los siguientes ejemplos: viscosidad de crudos a partir de los niveles de temperatura, gravedad API y el porcentaje de asfaltenos (Velásquez, 2017). En educación se analiza el rendimiento académico en la disci plina de matemática a partir de calificaciones obtenidas en matemática en los últimos 6 años (Jeylin Meybelin Pérez Obregón and Díaz, 2018). En economía para predecir la probabilidad de riesgo de quiebra en función del tiempo a partir de razones financieras (Castro et al., 2019). En la predicción de inundaciones fluviales en un núcleo costero a partir de los hidrogramas y el nivel de marea prescritos como variables predictoras (Bermúdez et al., 2017). En la predicción de gravedad de accidentes de tránsito: a partir de la información del lugar del accidente (dirección, datos de georeferencia y localidad), clase de accidente (atropello, choque, caída de ocu pante, incendio, volcamiento, autolesión u otro), fecha y hora de ocurrencia, condición de la víctima (peatón, pasajero, motociclista, ciclista o conductor), edad y género de la víctima (Sonia E. Monroy Varela, 2018).
En ocasiones se presentan problemas que involucran predicciones con más de una variable en estudio, normalmente representadas mediante varias etiquetas relacionadas entre sí, en forma de un vector. Por ejemplo, En la visión por computadora con frecuencia se necesita asociar una imagen a varias categorías de manera simultánea, o incluso requerir una lista clasificada de anotaciones (Bucak et al., 2009). En el procesamiento del lenguaje natural, hay que traducir oraciones de un lenguaje específico a otro, donde cada oración es una secuencia de palabras (Koehn, 2005). En la modelación de la relación entre las variables de temperatura, luz, pH y oxígeno disuelto, y el crecimiento del cultivo de microalgas (Carrasquilla-Batista et al., 2016). En bioinformática, se analiza la secuencia de proteínas (estructura primaria) para predecir las estructuras de las proteínas, incluidos los elementos de estructura secundaria, la disposición de los elementos y la asociación de cadenas (Liu et al., 2005). En metalurgia se estiman varios factores de flotación a partir de la ubicación espacial de los datos. (Gonzales, 2018).
Estos problemas que involucran predicciones simultaneas de un vector de números reales suelen ser tratados en el contexto del aprendizaje de salidas múltiples (Multi-Target Prediction; MTP) (Xu et al., 2019). Este nuevo paradigma de aprendizaje automático emergente, que apunta a predecir simultáneamente múltiples salidas a partir de un conjunto de variables de entrada a tenido un popular auge en los últimos años (Borchani et al., 2015); (Zhen et al., 2018a,b); (Spyromitros-Xioufis et al., 2016). En comparación con el aprendizaje tradicional de salida única, tiene una naturaleza multivariable y las salidas múltiples pueden tener interacciones complejas que solo pueden manejarse mediante una inferencia bien estructurada. Los valores de salida tienen diversos tipos de datos en diversos problemas de aprendizaje automático (Waegeman et al., 2019). Por ejemplo, los valores de salida binarios pueden referirse al problema de clasificación de múltiples etiquetas Zhang and Zhou (2014), valores de salida nominales a problema de clasificación multidimensional (Bielza et al., 2011), valores de salida ordinales para etiquetar problema de clasificación (Fürnkranz and Hüllermeier, 2010) y salidas de valores continuos al problema de regresión con salidas múltiples (Multi-Target Regression; MTR) (Borchani et al., 2015).
La enorme cantidad de datos recolectados por las empresas en la actualidad y el incremento en la diversidad de sensores incorporados en la industria han traído consigo problemas de predicción que involucran grandes volúmenes de datos, ya sea en ejemplos de entrenamiento o cantidad de variables. Este contexto impone serios problemas en términos de eficiencia a las técnicas clásicas de predicción y sobre todo a las que involucran múltiples variables de salida, es decir, tiempos de procesamiento computacional, excesivamente grandes y en algunos casos intolerables. Aunque en la literatura ya se puede notar una tendencia al aumento de las investigaciones para solucionar este problema, aún se evidencia una dificultad para encontrar técnicas que aborden el problema de MTR desde la perspectiva de Big Data (Bahri et al., 2019); (Prabhu, 2019); (Shafique et al., 2019); (Li et al., 2019); (Asch et al., 2018). Por lo tanto, el objetivo que este artículo de revisión consiste en
ofrecer un análisis de las principales técnicas de MTR y sus posibilidades de ser escalados, mediante un enfoque distribuido, para entornos con grandes volúmenes de datos. Para argumentar estas posibilidades seguidamente se abordan varios trabajos referentes a las técnicas de regresión lineal múltiple y los principales modelos de optimización que sustentan los algoritmos de aprendizaje supervisado en el contexto de Big Data.
MATERIALES Y MÉTODOS
Recientemente, la tarea de MTR ha sido ampliamente estudiada en la comunidad de investigación de minería de datos. Esta puede verse como una extensión de la tarea de predicción simple, pero donde en lugar de un solo rasgo objetivo, cada ejemplo está asociado con múltiples rasgos objetivos. Este enfoque resuelve aquellos problemas donde para cada ejemplo del conjunto de aprendizaje se presentan varias variables dependientes del resto, cuyos valores deben ser estimados de manera simultanea. Problemas como este, se presentan a menudo en diferentes áreas como la predicción del mercado de valores, el pronóstico de generación de energía, el modelado ecológico, el procesamiento del lenguaje natural, para estimar la calidad de la vegetación (Kocev et al,. 2009), en la predicción del espectro de audio de ruido del viento (representado por varias variables de presión de sonido) de una componente dada de los vehículos (Struyf, 2009), entre otros.
En la predicción con salidas múltiples, el trabajo propuesto en (Borchani et al., 2015) establece dos grandes enfoques. El primer enfoque, basado en transformación del problema, consiste en emplear cada variable objetivo de conjunto con las variables predictoras, siguiendo determinadas heurísticas para conformar nuevos conjuntos de entrenamientos. En este nuevo espacio se conforman múltiples problemas de salidas simples asumiendo que estas son independientes. Un segundo enfoque basado en adaptación de método, permite adaptar los enfoques clásicos de aprendizaje al nuevo contexto y con ello construir un único modelo para predecir todas las variables de salida simultáneamente. En ambos enfoques se toma en cuenta en alguna medida la posible dependencia inherente entre las variables de salidas. La manera en que ambas familias de algoritmos son capaces de tratar la dependencia entre las variables de salidas, ha sido poco debatido en los trabajos precedentes y hay aspectos que no han sido considerados de manera muy sencilla. Por ejemplo en las estrategias basadas en transformación se emplean diferentes heurísticas para combinar las variables de salidas y luego incluirlas en el conjunto de variables predictoras transformado el problema a uno de salida simple. En este escenario el nuevo conjunto de metavariables dejan de ser independientes e idénticamente distribuidas (iid como se conoce por sus siglas en inglés) lo cual es un presupuesto teórico de varios modelos de aprendizaje automático. De igual manera los modelos basados en transformación presuponen que el problema se pueda descomponer por el conjunto de variables de salidas. En tal sentido los modelos basados en adaptación tienen una naturaleza más apropiada para tomar en cuenta la dependencia entre el conjunto de variables de salidas debido a que los algoritmos son adaptados para predecir de manera simultánea el conjunto de variables.
Los algoritmos de MTR obtienen mejores resultados en cuanto al error predictivo cuando se explota la interdependencia entre las variables de salida. En este sentido, los primeros resultados fueron propuestos en (Xioufis et al., 2012), cuyos resultados de predicción pueden ser mejorados en algunas de las bases de datos de dominio
específico donde han sido evaluados. Los enfoques más recientemente en el campo de la regresión con salidas múltiples (Lu et al., 2012); (Rothman et al., 2010); (Zhen et al., 2018b,a); (Diez et al., 2018) tienen en cuenta la dependencia entre el conjunto de variables de salidas. Para ello utilizan diferentes estructuras matriciales, generalmente de rango deficiente o matrices dispersas, dependiendo de los regularizadores empleados. Una for ma de promover matrices dispersas puede ser proyectando a un espacio de mayor dimensión como en el caso de (Tsoumakas et al., 2014), donde se generan subespacios aleatorios para formar nuevas variables combinando linealmente el conjunto de las q variables de salidas con pesos aleatorios extraídos de una distribución normal. En los problemas de predicción con salidas múltiples, donde se ha estudiado rigurosamente el problema de la dependencia entre variables de salidas se han utilizado dos pasos de predicción, introduciendo variables latentes y regularizadores convenientes (Chen et al., 2011). Estos enfoques compuestos generalmente conducen a for mulaciones no convexas que requieren estrategias de resolución particulares. Otros trabajos para la predicción simultánea de todas las variables objetivo al mismo tiempo (el enfoque global) se ha considerado en la configu ración de lotes (Struyf and Dzeroski, 2005). Además, en (Appice and Dzeroski, 2007) se propuso un algoritmo para la inducción paso a paso de modelos de árboles para múltiples objetivos. En el contexto de streaming, también se han hecho algunos trabajos en regresión con múltiples objetivos como es el caso de (Ikonomovska et al., 2011).
Regresión lineal multivariada.
En esencia, el objetivo de aprender una regresión lineal con múltiples salidas no es más que aprender un modelo matemático capaz de predecir múltiples variables numéricas de forma simultanea (Osojnik et al., 2017) o, formalmente, la tarea de estimar un vector de valores reales y ∈ R q , donde q es el número de variables para una determinada instancia x de un espacio de entrada X
Dado un conjunto de entrenamiento con N ejemplos, p variables predictoras y q variables de salidas, cada instancia i se caracteriza como un vector de variables descriptivas x
i
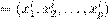 y un vector variables de salida y
i
y un vector variables de salida y
i
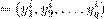 para i = 1,...,N. La tarea de aprender un modelo de regresión multi-objetivo a partir de una matriz de ejemplos D entonces consiste en encontrar una función h que transforme cada variable de entrada, dada por el vector x
i
, en un vector de salida y
i
conformado por los q rasgos h: X → R
q
.
para i = 1,...,N. La tarea de aprender un modelo de regresión multi-objetivo a partir de una matriz de ejemplos D entonces consiste en encontrar una función h que transforme cada variable de entrada, dada por el vector x
i
, en un vector de salida y
i
conformado por los q rasgos h: X → R
q
.
En general, un problema de regresión lineal multivariada puede ser expresado como un problema de optimización con o sin restricciones donde, se combina una función de perdida L(D,W) y una función de regularización R(W) que controla el sobre ajuste del modelo, dependiendo de la naturaleza de los mismos, en la forma:
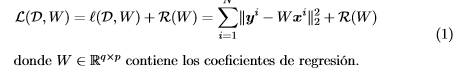
Predicción con salidas múltiples
Entre las técnicas no convencionales de MTR que mayor desarrollo han tenido en los últimos años se encuen tra la predicción estructurada (Structured Prediction) (Bakir et al., 2007), cuya diferencia con los métodos convencionales radica en que la variable de salida es modelada como una estructura de datos compleja. Estas estructuras, para la variable de salida, pueden ser modeladas como grafos, jerarquóas, secuencias, cadenas de texto o vectores, dependiendo del tipo de problema que se desea estudiar. En particular, aquellos problemas que se componen por vectores en la variable de salida son conocidos como problemas de clasificación multietiqueta (cuando son vectores con valores binarios) o predicción con salidas múltiples (cuando las salidas están formadas por vectores reales) (Borchani et al., 2015).
Entre los algoritmos representativos basados en transformación del problema, se destacan los trabajos de (Spyromitros-Xioufis et al., 2012) y (Spyromitros-Xioufis et al., 2016), en los mismos se extienden enfoques clásicos de clasificación multi-etiqueta conocidos como Stacking y Regressor Chain para proponer los algoritmos Multi-Target Stacking (MTS) y Ensemble of Regressor Chains (ERC) respectivamente y sus variantes corregidas MTSC y ERCC, que constituyen el estado del arte en esta área. Para analizar los modelos matemáticos que dan soporte a estos algoritmos se plantea la siguiente notación:
Sea x = [x 1 ,...,x p ] ∈ R p , y = [y 1 ,...,y q ] ∈ R q , dos vectores aleatorios correspondientes a los espacios de entrada y salida respectivamente. Cada instancia de entrenamiento puede ser escrita como:
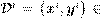 X × R
q
. Un problema de predicción con salidas múltiples en su forma general permite aprender un modelo h: X → R
q
sobre el conjunto de entrenamiento D que permita predecir el conjunto de variables de salida de forma simultánea yˆ = h(x). En lo sucesivo se describen los métodos representativos que constituyen el estado del arte de estos enfoques.
X × R
q
. Un problema de predicción con salidas múltiples en su forma general permite aprender un modelo h: X → R
q
sobre el conjunto de entrenamiento D que permita predecir el conjunto de variables de salida de forma simultánea yˆ = h(x). En lo sucesivo se describen los métodos representativos que constituyen el estado del arte de estos enfoques.
El algoritmo MTS (Spyromitros-Xioufis et al., 2016), fue desarrollado tomando como base el generalized stacked para clasificación multi-etiqueta. El proceso de entrenamiento de este algoritmo consta de dos etapas. En la primera etapa, se aprenden q modelos independientes h j : R p → R tomando cada conjunto de variables predictoras con cada variable objetivo en forma de relevancia binaria. La segunda etapa del algoritmo MTS aprende q meta-modelos h ∗ j : R p+q−1 → R añadiendo a las predictoras, las q − 1 predicciones de la primera etapa y −j excepto la variable j, para obtener p + q − 1 meta-variables y con ello aprender el predictor en este nuevo espacio. Cada meta-modelo h ∗ j se estima sobre la base del conjunto de datos de entrenamiento
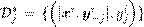 que se amplía con las predicciones de la primera fase con el algoritmo de relevancia binaria. Nótese que se ha denotado por
que se amplía con las predicciones de la primera fase con el algoritmo de relevancia binaria. Nótese que se ha denotado por 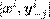 al conjunto ampliado de variables predictoras usando el vector de estimaciones iniciales y
i
−j
sin tomar en cuenta el valor de la variable en estudio.
al conjunto ampliado de variables predictoras usando el vector de estimaciones iniciales y
i
−j
sin tomar en cuenta el valor de la variable en estudio.
Al mismo tiempo el algoritmo ERC propuesto en (Spyromitros-Xioufis et al., 2016), se basa en la idea de modelos de encadenamiento para problemas de aprendizaje con salidas simples. El entrenamiento del ERC tiene como punto de partida un ordenamiento aleatorio de las variables de salida Q
c
(y
1
,y
2
,...,y
q
) a partir de establecer permutaciones aleatorias. Luego, el modelo de aprendizaje sigue dos pasos en forma análoga al MTS para el primer paso. Esto significa que se establece un primer nivel de predicción usando el algoritmo relevancia binaria para cada variable de salida de manera independiente. En la segunda etapa del aprendizaje se van incorporando variables de salida en el proceso de aprendizaje de modo que para estimar la salida yˆ
j
se tomarán en cuenta las anteriores predicciones yˆ1
,...,yˆ
j−1
como entradas para ese modelo. Luego, el algoritmo aprende un primer modelo con las variables predictoras y los restantes modelos 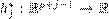 se aprenden sobre el conjunto de entrenamiento
se aprenden sobre el conjunto de entrenamiento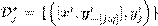 transformado en forma de cadena. El principal inconveniente del algoritmo ERC es que depende del ordenamiento de las variables de salida por lo que en (Spyromitros-Xioufis et al., 2016) se ejecutan todas las permutaciones posibles del conjunto de variables de salida.
transformado en forma de cadena. El principal inconveniente del algoritmo ERC es que depende del ordenamiento de las variables de salida por lo que en (Spyromitros-Xioufis et al., 2016) se ejecutan todas las permutaciones posibles del conjunto de variables de salida.
Diversos han sido los trabajos que han sido adaptados en el contexto de máquinas de soporte vectorial para regresión destacándose en los más recientes los trabajos (Melki et al., 2017); (Chang and Lin, 2011); (Do and Bui, 2019). El primero implica la creación de modelos independientes de SVR para cada variable de salida. El segundo, Support Vector Regression with Random Chains (SVRRC), construye un conjunto de cadenas aleatorias utilizando el primer método como modelo base. El tercero, Support Vector Regression with Correlation Chaining (SVRCC), calcula las correlaciones de los objetivos y forma una cadena de correlación máxima, que se utiliza para construir un modelo de SVR de cadena única. Los resultados de estos trabajos muestran que el enfoque de SVR de correlación máxima mejora el rendimiento del uso de conjuntos de cadenas aleatorias.
Los algoritmos basados en adaptación consideran un modelo único capaz de predecir de manera simultánea el conjunto de variables de salida sin modificar las condiciones del problema. Los primeros trabajos en este campo provienen del aprendizaje estadístico o estadística multivariada como es el caso de la regresión por contracción (ridge regression) (Hoerl and Kennard, 1970). De igual manera, en (Izenman, 1975) se aprende una estructura de bajo rango en la propuesta de algoritmo Reduced Rank Regression que usa un modelo de regresión lineal.
En Breiman and Friedman (1997) proponen la contracción simultánea tanto en el espacio de entrada como en el de salida. En general, para q variables de respuesta y = (y 1 ,...,y q ) con una predicción basada en regresión lineal simple para cada variable de salida, se obtienen yˆ = (yˆ1 ,...,yˆ q ). Si las variables de salida se encuentran correlacionadas es posible obtener un predictor más preciso, denotado como y˜ i para cada variable de salida, usando una combinación lineal,
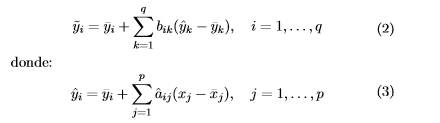
Para estimar los coeficientes de la matriz de regresión lineal aˆ ij se utiliza el método de los mínimos cuadrados ordinarios y como regularizador la norma l 2 o Ridge Regression
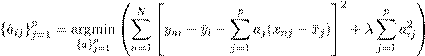 ,(4)
,(4)
Se asume, además, que las variables predictoras y las variables objetivo están centradas por la media corres pondiente del conjunto de entrenamiento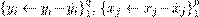 , as como, todas las variables objetivo estimadas son centradas por la media correspondiente de la muestra
, as como, todas las variables objetivo estimadas son centradas por la media correspondiente de la muestra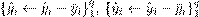 .
.
Una propuesta para dar solución al problema de dependencia condicional entre las variables de salida se presenta en (Zhen et al., 2018a). En este trabajo, se propone un algoritmo denominado Multi-layer Multi-target Regression (MMR), que permite modelar simultáneamente las correlaciones intrínsecas entre las variables de salida y las relaciones no lineales de entrada-salida en un marco general a través de un aprendizaje robusto de bajo rango. Específicamente, el MMR puede codificar explícitamente las correlaciones entre las variables de salida en una matriz de estructura mediante redes elásticas matriciales (Matrix Elastic Nets; MEN). El MMR combina una variante con kernel y la regresión lineal multivariada para determinar las relaciones entre el espacio de entrada-salida, posiblemente con dependencia no lineal. Este algoritmo se resuelve mediante un método de optimización desarrollado de manera alternada con convergencia garantizada y descrita en (Zhen et al., 2018a). En resumen esta propuesta presenta un nuevo paradigma de aprendizaje de múltiples capas para la regresión de múltiples variables que está dotado de alta generalidad, flexibilidad y capacidad expresiva. No obstante, el empleo en esta propuesta de un kernel de Hilbert de espacio de dimensión infinita (reproducing kernel Hilbert space; RKHS) (Xu et al., 2015) conduce a un costo computacional relativamente elevado. Un
aporte similar, lo constituye el algoritmo Multitarget Sparse Latent Regression (MSLR) presentado en (Zhen et al., 2018b) el cual aborda este problema al implementar una matriz de con estructura de rango deficiente que permite codificar explícitamente las correlaciones entre las variables de salida utilizando la norma l 2,1 .
Otra trabajo del estado del arte que resuelve el problema de regresión lineal multivariada de manera eficiente, introduciendo un espacio de variables latentes o un aprendizaje en capaz, lo constituye el método propuesto en (Diez et al., 2018). Esta propuesta, llamada Generalized Multitarget Linear Regression with Output Dependence Estimation (GMLR) constituye un esquema general, flexible y adaptable a diferentes escenarios y esquemas de regularización. Este se basa en la proyección de las variables a un espacio de variables latentes y el uso de un método flexible y escalable de optimización mediante la modelación de un problema Biconvexo soluble de manera alternada. Su principal ventaja es la escalabilidad para considerar disímiles situaciones aprovechando las bondades del método de optimización gradiente proximal acelerado. Para exponer esta propuesta se presenta la siguiente notación:
Sean, x ∈ X ⊆ R p y y ∈ Y ⊆ R q dos vectores aleatorios definidos en los espacios de entrada y salida, respectivamente, de un determinado problema de aprendizaje automático con salidas múltiples reales de dimensión q. Para el conjunto de datos, con N instancias de entrenamiento D = {(x 1 ,y 1),...,(x N ,y N )}, se define un modelo de regresión con múltiples salidas que tome en cuenta las relaciones entre las variables de entrada y salida y en el conjunto de variables de salida, siguiendo un modelo de regresión lineal cuya función de predicción es y = xSW. Este modelo define un conjunto de variables latentes z ∈ R r entre el conjunto de variables de entrada y salida. Las variables latentes son estimadas a partir de la matriz W p×r que establece las relaciones entre el conjunto de entrada y salida. En el caso en r = q se dice que W es una estructura de rango completo. Luego, para relacionar el conjunto de variables de salida a travs de las variables latentes se incluye en el modelo la estructura matricial S r×q que combina linealmente el conjunto de predicciones individuales en el modelo de regresión lineal.
En términos generales, para estimar las estructuras que relacionan el conjunto de variables de entrada y salida y entre variables de salida se define un problema de optimización para minimizar el funcional de pérdida 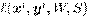 y una función de regularización R(W,S) que controla la generalización del modelo y al mismo tiempo establece las estructuras de cada matriz,
y una función de regularización R(W,S) que controla la generalización del modelo y al mismo tiempo establece las estructuras de cada matriz,
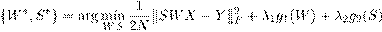 (5)
(5)
donde g 1 y g 2 representan el término asociado al regularizador para la matriz W y S respectivamente. Vale resaltar que en este contexto g 1 y g 2 pueden ser genéricos, permiten utilizar varios tipos de normas y son escalables a diferentes esquemas de regularización.
Medidas de Evaluación
En el contexto de la predicción con salidas múltiples se han utilizado como medidas de evaluación más comunes las siguientes:
Average Relative Root Means Squared Error. aRRMSE
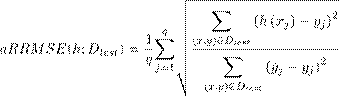
Average Root Means Squared Error. aRMSE
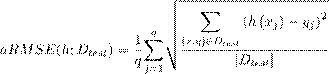
Means Squared Error. MSE
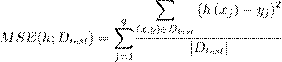
Todas estas medidas evalúan cada variable de salida de manera independiente, lo cual da una idea del poder predictivo por cada variable y a su vez una medida global del conjunto de variables. En el caso de las medidas MSE y aRMSE tienen como limitación fundamental que para bases de datos con variables en intervalos de medición con escalas diferentes, es necesario normalizar dichas escalas de medición haciendo uso de sus valores medios y la varianza, lo cual no ocurre con la medida aRRMSE.
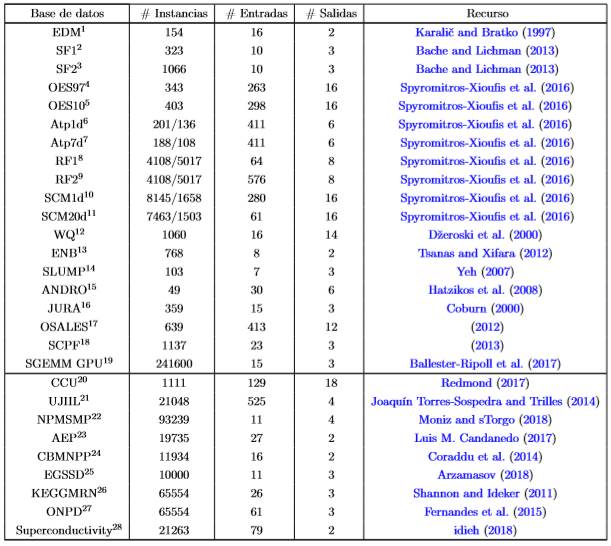
Base de Datos
Un aspecto a tener en cuenta ante toda tarea de MTR es el conjunto de datos a procesar. Si las dimensiones de este es pequeña basta seleccionar un algoritmo cuyo modelo se ajuste al tipo de los datos y al tipo de función que siguen los datos de salida. En otro caso, cuando los conjuntos de datos son a gran escala, dígase gran número de instancias, gran número de variables de entrada, o gran número de variables de salida, entonces se presentan serias limitaciones en cuanto a eficiencia de los algoritmos. Hay muchos trabajos de investigación que se centran en resolver los problemas de escalabilidad causados por un gran número de instancias de datos,
como los métodos de selección de instancias (Brighton and Mellish, 2002), o la alta dimensionalidad del espacio de características, como los métodos de selección de características (Zhai et al., 2014). La causa de las altas dimensiones de salida ha recibido mucha menos atención.
En la literatura se pueden encontrar desde bases de datos pequeñas (Yeh, 2007) a bases de datos con cientos de miles de instancias (Joaquín Torres-Sospedra and Trilles, 2014). La siguiente tabla permite observar la diversidad dimensional de algunas de las bases de datos que pueden ser utilizadas para MTR. En la primera columna se indica el nombre de la base de datos, la segunda se refiere al número de observaciones de la base de datos. La tercera y cuarta columna indican la cantidad de atributos en el espacio de entrada y salida respectivamente.
Por último, se señala la fuente de la que fue tomada la base de datos.Tabla 1
EDM1 (Electrical Discharge Machining): Es una base de datos que representa los tiempos de descarga eléctrica de ciertos tipos de maquinarias. Este problema consta de dos variables de salida y 16 variables de entrada continuas. Cada variable de salida puede tomar 3 valores distintos (-1,0,1) en dependencia del estado en que se encuentre cada equipo.
SF12 y SF23 (Solar Flare): Son dos base de datos que contiene 3 variables de salida correspondientes a la intensidad, en 3 niveles, de los rayos solares (común, moderada y severa). Los datos recopilados representan los valores observados durante 24 horas de variables relacionadas con indicadores físico-químicos del sol. Hay dos versiones de esta base de datos, SF1 contiene los datos del ao 1969 y SF2 del ao 1978.
OES974 y OES105 (Occupational Employment Survey): Son bases de datos obtenidas en los años 1997 (OES97) y 2010(OES10) del Occupational Employement Survey compiladas por US Bureau of Labor Statistics. Cada instancia (responde a una ciudad) provee el estimado de tiempo laboral de los empleados en cada tipo de oficio para el rea metropolitana de cada ciudad. Existen 334 y 403 ciudades (instancias) en la base de datos de 1997 OES97 y 2010 OES10 respectivamente. Las variables de entrada, en estas bases de datos, son una secuencia aleatoria de empleos (ejemplo: doctor, dentista, mecánico) observados en al menos el 50% de las ciudades. Las variables de salida fueron seleccionadas, aleatoriamente, del conjunto de categorías para las cuales se supera el 50% del umbral.
Atp1d6 y Atp7d7 (The Airline Ticket Price): Los conjuntos de datos se refieren a la predicción de los precios de los billetes de avión. Las filas son una secuencia de observaciones en tiempo, ordenado a lo largo de varios das. Cada muestra en esta base de datos representa un conjunto de observaciones de una fecha de salida. Las variables de entrada para cada muestra son valores que pueden ser útiles para la predicción de los precios de los billetes de avión para una fecha de salida específica. Las variables objetivo en estos conjuntos de datos representan los precios al da siguiente (ATP1d) o el precio mínimo observado en los próximos 7 das (ATP7d) para seis preferencias de vuelo estudiadas. La base de dato se compone de 411 características o variables de entrada descritas claramente en Groves and Gini (2011). La naturaleza de estos conjuntos de datos es heterogénea con una mezcla de varios tipos de variables como pueden ser booleanas, de precios o cantidades enteras.
RF18 y RF29 (The river flow): Los conjuntos de datos, sobre fluido de los ros, se refieren a la predicción del comportamiento en las próximas 48 horas de la red fluvial, para zonas geográficas especificas. El conjunto de datos contiene los datos de las observaciones de flujo por hora de 8 sitios en la red del ro Mississippi tomados del Servicio Meteorológico Nacional de Estados Unidos. Cada fila incluye la observación más reciente para cada uno de los 8 sitios, as como observaciones en tiempo de 6, 12, 18, 24, 36, 48 y 60 horas en el pasado. En RF1, cada punto de observación, aporta 8 variables para conformar la base de datos. Hay un total de 64 variables de entrada y 8 variables de salida. El conjunto de datos RF2, extiende al conjunto RF1 mediante la adición de información del pronóstico de precipitación para cada uno de los 8 sitios (lluvia esperada reportado como valores discretos: 0,0, 0,01, 0,25, 1,0 pulgadas). Los dos conjuntos de datos contienen más de 1 ao de observaciones horarias (>9000 horas) recogidas a partir de septiembre de 2011 hasta el ao 2012.
SCM1d10 y SCM20d11 (The Supply Chain Management): El conjunto de datos de la gestión de la cadena de suministro se obtiene de la CompetenciaTrading Agent Competition in Supply Chain Management (TAC SCM) en el ao 2010. Los métodos para pre-procesamiento y normalización de los datos se describen en Groves and Gini (2013). Algunos valores de referencia, para medir la eficacia de la predicción en este tipo de problema, estn disponibles en Pardoe and Stone (2010). Las variables de entrada de esta base de dato se corresponden con un da específico del torneo de 220 das recopilados. Además, se incluyen 4 observaciones de mediciones temporales para cada producto observado y el componente (1,2,4 y 8 das de retardado) para facilitar cierta anticipación de las tendencias de los productos. Los conjuntos de datos contienen 16 variables de salida las cuales se corresponde con el valor medio del da siguiente para la base de datos (SCM1d) o el valor medio para 20 das en la base de datos (SCM20d).
WQ12 (Water Quality): Es una base de datos que contiene 14 variables de salida que representa las especies de plantas y animales representativos de los ros de Eslovenia y 16 variables de entrada que se refieren a los parámetros físicos-químicos que determinan la calidad del agua de estos ros.
ENB13 (The Energy Building): El conjunto de datos relacionado con la energía en edificios (enb) se utilizó para estudiar el efecto de ocho indicadores (compacidad relativa, superficie, superficie de pared, superficie del techo, altura total, orientación, superficie de cristales, distribución de la superficie de cristales) sobre las variables carga térmica (HL) y carga de enfriamiento (CL), de varios edificios residenciales.
SLUMP14 (Concrete Slump): Este conjunto de datos permite predecir tres propiedades del hormigón (asentamiento, flujo y resistencia a la compresión) en función del contenido de siete ingredientes (cemento, cenizas volantes, escoria de alto horno, agua, superplastificante, áridos gruesos y áridos finos).
ANDRO15 (Andromeda): El conjunto de datos de Andrómeda se utilizó para predecir los valores de seis variables de calidad del agua (temperatura, pH, conductividad, salinidad, oxígeno, turbidez) en el Golfo de Thermaikos de Hessaloniki, Grecia. Las mediciones de las variables objetivo se toman desde sensores submarinos con un intervalo de muestreo de 9s y luego se determina el valor medio de todas las mediciones para un día.
JURA16 (Jura): El conjunto de datos de Jura contiene las mediciones de las concentraciones de siete metales pesados (cadmio, cobalto, cromo, cobre, níquel, plomo y zinc), registradas en 359 lugares en la capa superior del suelo de una región del Jura suizo. Adicionalmente, se incorpora información sobre el uso de la tierra (Bosque, Pasto, Pradera y Labranza) y el tipo de roca (Argoviano, Kimmeridgiano, Secuaniano, Portlandiano y Cuaternario). Específicamente, la concentración de tres metales (cadmio, cobre y plomo) es más cara de medir que la de otros metales. Por lo tanto, la concentración de éstos metales se trata como variables objetivo, mientras que el resto de los metales se tratan como variables predictoras de conjunto con variables producidas por información adicional.
OSALES17 (Online Product Sales): Esta base de datos que fue empleada en la competencia Kaggles 2012 para predecir el consumo mensual de ventas en línea de productos. Cada línea, en el conjunto de datos, representa un producto de consumo que se describe por sus diversas características, as como indicadores relacionados con una campaña publicitaria (413 características de entrada en total). Hay 12 variables de salida correspondientes a las ventas mensuales tras el lanzamiento del producto.
SCPF18 (See Click Predict Fix): Este conjunto de datos permite cuantificar y predecir la cantidad de opiniones, votos y comentarios que podrá recibir un tema específico, a partir de 23 características o variables de entrada. Algunas de estas características son: el número de días que un problema permaneció en línea, la fuente a partir del cual se creó el problema (por ejemplo, androide, iphone, api remoto, etc.), las coordenadas geográficas del problema, entre otros. Los datos han sido tomados en muestras de cuatro ciudades (Oakland, Richmond, New Haven, Chicago) en los EE.UU. y abarcan un período de 12 meses
(01/2012-12/2012).
SGEMM GPU19 (Sobol Tensor Trains for Global Sensitivity Analysis): Este conjunto de datos mide el tiempo de ejecución de un producto de matriz-matriz A * B = C, donde todas las matrices tienen un tamaño de 2048 x 2048, utilizando un kernel SGEMM GPU parametrizable con 241600 combinaciones de parámetros posibles. Para cada combinación probada, se realizaron 4 ejecuciones y sus resultados se informan como las 4 últimas columnas. Todos los tiempos se miden en milisegundos.
CCU20 (Communities and Crime Unnormalized): Los datos combinan datos socioeconómicos del Censo ’90, datos policiales de la década de 1990, estadísticas administrativas y datos de delitos de la UCR del FBI de 1995. Se incluyen muchas variables para que se puedan probar los algoritmos que seleccionan o aprenden de las variables independientes. El FBI señala que el uso de estos datos para evaluar comunidades es demasiado simplista, ya que no se incluyen muchos factores relevantes. Por ejemplo, las comunidades con un gran número de visitantes tendrán un mayor crimen percápita (medido por los residentes) que las comunidades con menos visitantes, en igualdad de condiciones.
UJIIL21 (UJIIndoorLoc): El UJIIndoorLoc es una base de datos de localización de interiores de varios pisos para varios edificios para probar el sistema de posicionamiento en interiores que se basa en la huella digital de WLAN / WiFi. Esta cubre tres edificios de la Universitat Jaume I con 4 o más pisos y casi 110.000m2. Puede ser utilizado para la clasificación, por ejemplo, identificación real de edificios y pisos, o regresión, por ejemplo, Estimación de longitud y latitud reales. Fue creado en 2013 por medio de más de 20 usuarios diferentes y 25 dispositivos Android. La base de datos consta de 19937 registros de entrenamiento / referencia (archivo trainingData.csv) y 1111 registros de validación / prueba (archivo
validationData.csv).
NPMSMP22 (News Popularity in Multiple Social Media Platform): Este es un gran conjunto de datos de noticias y sus respectivos comentarios sociales en múltiples plataformas: Facebook, Google+ y LinkedIn. Los datos recopilados se refieren a un período de 8 meses, entre noviembre de 2015 y julio de 2016, que representan alrededor de 100.000 noticias sobre cuatro temas diferentes: economía, Microsoft, Obama y Palestina. Este conjunto de datos está diseñado para comparaciones evaluativas en tareas de análisis predictivo, aunque permite tareas en otras áreas de investigación como detección y seguimiento de temas, análisis de sentimientos en texto corto, detección de la primera historia o recomendación de noticias.
AEP23 (Appliances energy prediction): Contiene datos experimentales utilizados para crear modelos de regresión del uso de energía de los aparatos en un edificio de bajo consumo energético. El conjunto de datos es de 10 min durante aproximadamente 4,5 meses. Las condiciones de temperatura y humedad de la casa se controlaron con una red de sensores inalámbricos ZigBee. Cada nodo inalámbrico transmitió las condiciones de temperatura y humedad alrededor de 3.3 min. Luego, los datos inalámbricos se promediaron durante períodos de 10 minutos. Los datos de energía se registraron cada 10 minutos con medidores de energía de m-bus. El clima de la estación meteorológica del aeropuerto más cercano (Chievres Airport,
Bélgica) se descargó de un conjunto de datos públicos de Reliable Prognosis (rp5.ru) y se combinó con los
conjuntos de datos experimentales utilizando la columna de fecha y hora. Se han incluido dos variables aleatorias en el conjunto de datos para probar los modelos de regresión y para filtrar los atributos no predictivos (parámetros).
CBMNPP24 (Condition Based Maintenance of Naval Propulsion Plants): Los experimentos se han llevado a cabo mediante un simulador numérico de un buque naval (Fragata) caracterizado por una planta de
propulsión de turbina de gas (Gas Turbine; GT). Los diferentes bloques que forman el simulador completo se han desarrollado y afinado a lo largo del ao en varias plantas de propulsión reales similares. En vista de estas observaciones, los datos disponibles concuerdan con un posible buque real. En esta versión del simulador también es posible tener en cuenta la disminución del rendimiento a lo largo del tiempo de los componentes de GT, como el compresor GT y las turbinas. Los datos almacenan una serie de medidas (16 características) que representan indirectamente el estado del sistema sujeto a deterioro del rendimiento.
EGSSD25 (Electrical Grid Stability Simulated Data): Este conjunto de datos contiene catos simulados de la estabilidad de la red eléctrica. Estos corresponden al análisis de estabilidad local de un sistema de 4 nodos donde el productor de electricidad se encuentra en el centro, implementando el concepto de control descentralizado de redes inteligentes.
KEGGMRN26 (KEGG Metabolic Reaction Network (Undirected)): El conjunto de datos se refiere a una variedad de características gráficas presentadas en larvas metabólicas según la enciclopedia de genes y genomas de Kyoto (Kyoto Encyclopedia of Genes and Genomes; KEGG) (Kanehisa and Goto, 2000) modeladas como una red de reacción no dirigida
ONPD27 (Online News Popularity Data): Este conjunto de datos resume un conjunto heterogéneo de caractersticas sobre los artículos publicados por Mashable en un período de dos años. El objetivo es predecir el número de acciones en las redes sociales (popularidad).
Superconductivty28: Este conjunto de datos está formado por dos archivos: train.csv contiene 81 ca racterísticas extraídas de 21263 superconductores junto con la temperatura crítica en la columna 82, unique_m.csv contiene la fórmula química dividida para todos los 21263 superconductores de train.csv.
Las dos últimas columnas tienen la temperatura crítica y la fórmula química.
MTR. Una revisión para Big Data
Actualmente se siguen desarrollado una gran cantidad de trabajos orientados a resolver los problemas de MTR que reportan muy buenos resultados en sus áreas de aplicación, pero ya sea desde el enfoque adaptativo o desde el de transformación, no se encontraron trabajos que hicieran referencia a la solución de problemas con grandes volúmenes de datos. A pesar de ello, existen problemas reales que ameritan ser estudiados en el contexto de Big data. Ejemplos de estos problemas son las 10 últimas bases de datos caracterizadas en la tabla 1. Estas bases de datos cuentan con gran número de instancias y algunas de ellas de alta dimensionalidad en el espacio de atributos de entrada. Se impone entonces, realizar un análisis de las principales técnicas descritas en este ámbito y su escalabilidad a Big data. En nuestro estudio enfatizaremos en los métodos de optimización disponibles que pueden ser adaptados al contexto de la predicción con salidas múltiples.
Big Data es una disciplina emergente y en pleno auge, la cual se ocupa de todas las actividades relacionadas con los sistemas que manipulan grandes conjuntos de datos. Vale destacar ese sentido las dificultades más habituales vinculadas a la gestión de estas cantidades de datos se centran en la recolección y el almacenamiento (Kusnetzky, 2010), búsqueda, compartición y análisis (Vance, 2010), siendo en esta última en la que incurren la mayoría de los modelos de MTR existentes.
En este sentido algunos de los principales trabajos aquí expuestos enfrentan varias limitaciones. En MTS por ejemplo, se puede esperar que en presencia de miles de atributos predictores la influencia de tomar una, dos y hasta un número n mucho menor que q de variables de salida como predictoras resulte irrelevante en el esquema de aprendizaje. Eso se acentúa principalmente en los problemas donde p es mucho mayor que q, de manera análoga se vería muy afectado el algoritmo ERC. Cabe mencionar que si N es muy grande y p y q son pequeñas, estas variantes inspiradas en la regresión lineal simple pueden sufrir un problema de redundancia en los datos de entrada, lo que llevaría a un problema de eficiencia computacional en la convergencia de los métodos de optimización y una pobre eficacia.
Desde la disciplina de Big Data, particularmente incorporados en la plataforma Apache Spark Jinliang Wei, 2016); (Zaharia et al., 2010), ya se pueden encontrar algunos trabajos que, si bien no abordan el problema de MTR, sí resuelven el problema clásico de regresión con una variable de salida. Otros trabajos en ese marco se centran en la solución de problemas de optimización, como por ejemplo el método Limited-memory BFGS (L BFGS) (Ge et al., 2018); (Livieris et al., 2018) y el del Gradiente Descendiente Estocástico (Stochastic Gradient Descent; SGD) (Zhang et al., 2018) del que cabe señalar, parte el método del gradiente proximal acelerado empleado en GMLR.
La siguiente tabla detalla una síntesis de los principales trabajos de MTR y su relación con los modelos de optimización y los métodos de solución empleados. Sobre esta base es posible extender los algoritmos de MTR al escenario de grandes volúmenes de datos.
Métodos de optimización en Big Data
El método más simple para resolver problemas de optimización de la forma minw∈R d f(w) es el Gradiente Descendiente (Gradient Descent, GD) (Wang and Hu, 2019); (Ma et al., 2018). Este, como los demás métodos de optimización de primer orden (Vakili and Zhao, 2019) (incluidas las variantes estocásticas de los mismos) son muy adecuados para el cálculo a gran escala y distribuido.Tabla 2
Los métodos de descenso de gradiente tienen como objetivo encontrar un mínimo local de una función dando pasos de forma iterativa en la dirección del descenso más pronunciado, que es el negativo de la derivada (llamada gradiente) de la función en el punto actual, es decir, en el valor del parámetro actual. Si la función objetivo f no es diferenciable en todos los argumentos, pero sigue siendo convexa, entonces un sub-gradiente es la generalización natural del gradiente, y asume el papel de la dirección del paso. En cualquier caso, calcular un gradiente o un sub-gradiente de f es costoso: requiere un pase completo a través del conjunto de datos completo para calcular las contribuciones de todos los términos de pérdida. Los problemas de optimización cuya función objetivo f se escribe como una suma son particularmente adecuados para resolverse utilizando el descenso de gradiente estocástico (SGD). Un problema de optimización convexa en aprendizaje supervisado generalmente se define como,
 (6)
(6)
Un subgradiente estocástico selecciona aleatoriamente de un vector un conjunto reducido de datos, sin afectar el valor del sub-gradiente. Para lograr la convergencia se realizan las selecciones aleatorias en cada iteración del problema de optimización. Seleccionando un punto de datos i ∈ [1..n] de manera uniforme al azar, obtenemos un subgradiente estocástico de (7), con respecto a w de la siguiente manera:
 0w(7)
0w(7)
donde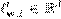 es un subgradiente de la parte de la función de pérdida determinada por el i-ésimo punto de datos, que es
es un subgradiente de la parte de la función de pérdida determinada por el i-ésimo punto de datos, que es 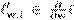 (w;xi,yi). Además, es un subgradiente del regularizador R(w), es decir, . El término
(w;xi,yi). Además, es un subgradiente del regularizador R(w), es decir, . El término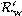 no depende de qué punto de datos aleatorio se elija. Claramente, en la selección aleatoria de i ∈ [1..n] se tiene que
no depende de qué punto de datos aleatorio se elija. Claramente, en la selección aleatoria de i ∈ [1..n] se tiene que 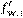 es un subgradiente de la función objetivo f, o lo que es equivalente
es un subgradiente de la función objetivo f, o lo que es equivalente
h i
La búsqueda del SGD consiste en encontrar un nuevo punto en la dirección del subgradiente estocástico negativo sobre la función objetivo en la forma:
El SGD distribuido implementado en Apache Spark utiliza una muestra simple (distribuida) de los datos de ejemplos. Dado que esto requeriría acceso al conjunto completo de datos, el parámetro miniBatchFraction especifica qu fracción de los datos completos se debe usar en su lugar. El promedio de los gradientes sobre este subconjunto, es decir, 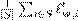 , es un gradiente estocástico. Aqu S es el subconjunto muestreado de tamaño |S| = miniBatchFraction∗n. En cada iteración, el muestreo sobre el conjunto de datos distribuido, as como el cálculo de la suma de los resultados parciales de cada máquina, se realiza mediante las rutinas de Spark estándares. Si miniBatchFraction se establece en 1 (predeterminado), el paso resultante en cada iteración es exactamente el subgradiente descendiente. En este caso, no hay aleatoriedad ni variación en las direcciones de los pasos. En el otro extremo, si se elige miniBatchFraction muy pequeño, de modo que solo se muestrea un solo punto, es decir, |S| = miniBatchFraction ∗ n = 1, entonces el algoritmo es equivalente al SGD estándar. En ese caso, la dirección del paso depende de la muestra aleatoriamente uniforme del punto.
, es un gradiente estocástico. Aqu S es el subconjunto muestreado de tamaño |S| = miniBatchFraction∗n. En cada iteración, el muestreo sobre el conjunto de datos distribuido, as como el cálculo de la suma de los resultados parciales de cada máquina, se realiza mediante las rutinas de Spark estándares. Si miniBatchFraction se establece en 1 (predeterminado), el paso resultante en cada iteración es exactamente el subgradiente descendiente. En este caso, no hay aleatoriedad ni variación en las direcciones de los pasos. En el otro extremo, si se elige miniBatchFraction muy pequeño, de modo que solo se muestrea un solo punto, es decir, |S| = miniBatchFraction ∗ n = 1, entonces el algoritmo es equivalente al SGD estándar. En ese caso, la dirección del paso depende de la muestra aleatoriamente uniforme del punto.
Se han desarrollado otros algoritmos inspirados en el SGD para el procesamiento eficiente de grandes volúmenes de datos; un ejemplo lo constituye el algoritmo Accelerated Mini-batch Randomized Block Coordinate Descent Method (MRBCD) propuesto en (Zhao et al., 2014). MRBCD emplea una función de regularización separable por bloques, lo que permite resolver los problemas de minimización mediante un descenso coordinado de bloques al azar (Randomized Block Coordinate Descent; RBCD). Los métodos RBCD existentes generalmente disminuyen el valor objetivo al explotar el gradiente parcial de un bloque de coordenadas seleccionado al azar en cada iteración. Sin embargo, tal configuración de "batch"puede ser computacionalmente costosa en la práctica. Para superar este inconveniente anterior, el método MRBCD es doblemente estocástico, en el sentido de que no solo selecciona aleatoriamente un bloque de coordenadas, pero también muestrea aleatoriamente un mini-lote de funciones de componentes de todos los fi. Dado que la varianza introducida por el muestreo estocástico sobre las funciones de los componentes no va a cero a medida que aumenta el número de iteraciones, este utiliza una secuencia de tamaños de pasos decrecientes.
Como ya se haba mencionado, otro algoritmo de optimización disponible en Apache Spark es L-BFGS. Este es un algoritmo de optimización en la familia de métodos cuasi-Newton para resolver los problemas de optimización de la forma minw∈Rd f(w). El método L-BFGS aproxima la función objetivo localmente como una acción cuadrática sin evaluar las segundas derivadas parciales de la función objetivo para construir la matriz Hessiana. La matriz Hessiana es aproximada por a las evaluaciones de gradientes anteriores, por lo que no hay un problema de escalabilidad vertical (el número de funciones de entrenamiento) cuando se calcula explícitamente la matriz Hessiana en el método de Newton. Como resultado, L-BFGS a menudo logra una convergencia más rápida en comparación con otros problemas de optimización de primer orden.
En (Chen et al., 2014) se propone un nuevo algoritmo L-BFGS, llamado VL-BFGS, que evita las operaciones de productos de puntos costosos en la recursión de dos bucles y mejora en gran medida la eficiencia del cálculo con un alto grado de paralelismo. Este algoritmo se escala muy bien y permite una variedad de algoritmos de aprendizaje automático para manejar un gran número de variables en grandes conjuntos de datos. La recursión central de dos bucles en VL-BFGS es independiente sobre el número de variables. Esto permite que sea fácilmente paralelizado en Map-Reduce (Mu et al., 2018) y escalar hasta miles de millones de variables.
En resumen, el algoritmo VL-BFGS tiene una complejidad general similar, pero nace con un grado masivo de paralelismo.
En (Najafabadi et al., 2017) siguen el principio básico de que para implementar un algoritmo L-BFGS a gran escala donde la longitud del vector de parámetros x es muy grande, una solución natural sera almacenar y manipular el vector x en varias máquinas. Si se utilizan N máquinas, el vector de parámetros se divide en N particiones no superpuestas. Cada partición se almacena y manipula localmente en cada máquina. La distri bución del almacenamiento y los cálculos en varias máquinas beneficia tanto los requisitos de memoria como los tiempos de ejecución computacionales. Siguiendo esta idea cada máquina manipula la porción del vector de parámetro asignado localmente. Los cachs L-BFGS (pares si, yi) también se almacenan en las máquinas localmente. Por ejemplo, si la máquina j-ésima almacena la j-ésima partición del vector de parámetros, también termina almacenando la j-ésima partición de los vectores si y yi, realizando todos los cálculos localmente. Cada máquina realiza la mayoría de las operaciones de forma independiente. Por ejemplo, la suma de dos vectores que están ambos distribuidos en varias máquinas, incluye sumar sus particiones correspondientes en cada máquinalocalmente.
Una técnica que como se ha visto, está estrechamente vinculada a los algoritmos de MTR basados en transfor mación y suele emplear algoritmos de optimización conexa es la regresión lineal múltiple.
Regresión Linear Múltiple desde Big Data
Como muchos métodos de aprendizaje automático, la Regresión Lineal Múltiple (Multiple Linear Regression; MLR) (Salleh et al., 2017); (Sherimon and Cherian, 2017) se puede formular como un problema de optimización convexo. Formalmente, esto se puede escribir como el problema de optimización. m´ınw∈Rd f(w) ,donde la función objetivo es de la forma:
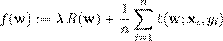 .(9)
.(9)
Aquí los vectores x i ∈ R d son los ejemplos de datos de entrenamiento, para 1 ≤ i ≤ n, y y i ∈ R que son los valores a predecir. En la regresión lineal, caso múltiple, la función de pérdida en la formulación dada por la pérdida al cuadrado.
Diversos métodos de regresión relacionados se derivan utilizando diferentes tipos de regularización: mínimos cuadrados ordinarios o mínimos cuadrados lineales no utiliza la regularización; la regresión ridge utiliza la regularización de L2; y Lasso usa la regularización de L1. Para todos estos modelos, la pérdida media o error de entrenamiento,, mejor conocida como MSE. En ese sentido la biblioteca MLlib (Assefi et al., 2017) de Apache Spark ya incorpora esta técnica utilizando como método de optimización SDG o L-BFGS.
Otros trabajos en Big Data para resolver problemas de MLR se basan en la descomposición el problema de optimización en varios subproblemas. En (Jun et al., 2015) por ejemplo, dividen el conjunto de datos de aprendizaje en M sub-conjuntos, entrenar los M modelos y combinar los w
i
, i ∈ [1..n/M] vectores resultantes como la media de cada una de sus componentes, es decir, 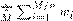 y por último evaluando la calidad del modelo final obtenido mediante el MSE. El trabajo (Adjout and Boufares, 2014), se basa en la misma idea de descomponer el problema en N subproblemas pero resuelve cada uno de estos mediante la doscomposición QR (Benson et al., 2013) de la matriz de valores de entrada X asociada; luego se obtienen la matrices Q y R asociadas al problema original mediante la concatenación de las resultantes de cada subproblema.
y por último evaluando la calidad del modelo final obtenido mediante el MSE. El trabajo (Adjout and Boufares, 2014), se basa en la misma idea de descomponer el problema en N subproblemas pero resuelve cada uno de estos mediante la doscomposición QR (Benson et al., 2013) de la matriz de valores de entrada X asociada; luego se obtienen la matrices Q y R asociadas al problema original mediante la concatenación de las resultantes de cada subproblema.
En (Tejasviram et al., 2015) se propone un modelo híbrido que combina la Máquina de Aprendizaje Extremo Asociativo Automático (Auto Associative Extreme Learning Machine; AAELM) con MLR (AAELM+MLR) para realizar la regresión en Big Data. Este funciona utilizando el modelo de computación paralela Hadoop Mapreduce que se implementa en Python utilizando la API Dumbo. Funciona en dos fases. En la primera fase, se entrena AAELM de tres capas. La salida de los nodos ocultos de AAELM se trata como NLPC. En la segunda fase, el modelo MLR se ajusta utilizando estos NLPC como variables de entrada. La efectividad del modelo AAELM + MLR se demuestra en dos grandes conjuntos de datos, a saber, el conjunto de datos de retardo de vuelo de la aerolínea y el conjunto de datos de sensores de gas, tomados de la web. Se observa que AAELM + MLR superó el rendimiento del modelo MLR al producir menos error de media al cuadrado promedio (MSE) y valores MAPE en el marco de validación cruzada de 10 veces. Una prueba estadística confirma su superioridad a un nivel de significación del 1
Otros trabajos utilizan el framework MapReduce (Sona and Mulerikkal, 2017). Por ejemplo en (Meng and Mahoney, 2013) describen un algoritmo con mejor propiedades de comunicación que es eficientes para resolver problemas de regresión l p fuertemente sobre-determinados a precisión moderada en MapReduce. Este algoritmo se basa en 4 aspectos de particular interés: utiliza un algoritmo de redondeo rápido recientemente desarrollado (que toma O(mn 3 logm) tiempo) para construir un redondeo 2n de un conjunto convexo centralmente simétrico en R n (Clarkson et al., 2016) para construir un algoritmo de condicionamiento determinístico de una sola pasada para la regresión l p , mediante el uso de una forma restringida de la regresión ` p (que también se utilizó recientemente (Clarkson et al., 2016), se muestra que el método de muestreo aleatorio para preservar el sub espacio (Dasgupta et al., 2009) se puede implementar (fácilmente) en el marco de MapReduce en una sola pasada, al utilizar múltiples soluciones de sub-muestreo del muestreo aleatorio de un solo paso, se puede construir una pequeña región de búsqueda inicial para los métodos de plano de corte de puntos interiores (interior point cutting-plane methods; IPCPM) Naoum-Sawaya (2011), por último, al realizar en paralelo múltiples consultas en cada iteración, obtienen un IPCPM aleatorio para resolver el problema de regresión l p convexo. En este trabajo adems de describir el algoritmo básico, también se presentan los resultados empíricos de una implementación numérica de este algoritmo aplicado a los problemas de regresión l 1 en conjuntos de datos de hasta un terabyte de tamaño.
CONCLUSIONES
En esta revisión se logró resumir las principales técnicas de MTR y su factibilidad en problemas con grandes volúmenes de datos, concluyendo que estas presentan serias deficiencias en este tipo de tareas. Cabe señalar que no se encontró ninguna literatura sobre trabajos del área para problemas de Big Data. Se debe resaltar, que el enfoque de transformación presenta la posibilidad de partiendo de una técnica de regresión lineal, desarrollar algoritmos para MTR, lo que ligado a la existencia de exponentes de esta técnica para Big Data, como la incorporada en el framework Apache Spark, sugiere la posibilidad de desarrollar nuevos trabajos de MTR basados en estos exponentes que permitan afrontar el manejo de grandes volúmenes de datos. En cambio, algunos algoritmos como GLMR están basados en la optimización de funciones convexas, área en la que se
han desarrollados varios trabajos para problemas con muchos datos algunos de los cuáles también cuentan con implementaciones para Big Data como las implementadas en el mencionado framework. Por lo tanto se sugiere replantear aquellas técnicas cuya esencia ya ha sido afrontada desde Big Data, de modo que surjan nuevos trabajos orientados a la solución eficiente de problemas de MTR en este campo.

