










 Custom services
Custom services Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
Los estudios de fiabilidad tradicionales han estado orientados al hardware. La mayor parte de los métodos y modelos desarrollados en esta disciplina se refieren básicamente a los elementos de hardware de los sistemas. Sin embargo, en los sistemas y equipos modernos el software desempeña un papel fundamental unido a la labor humana. Desde este punto de vista se podría estar hablando de tres tipos de fiabilidad: fiabilidad de hardware, fiabilidad humana y la fiabilidad del software (Solarte, y otros, 2009); siendo esta última la de interés en esta investigación.
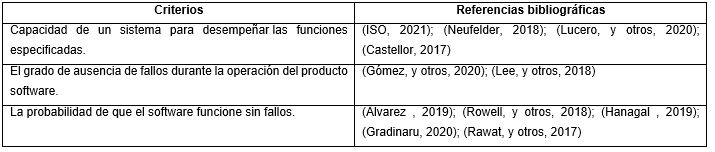
La Norma ISO/IEC 25010 define la fiabilidad como la capacidad de un sistema o componente para desempeñar las funciones especificadas, cuando se usa bajo unas condiciones y periodo de tiempo determinados. Esta característica se subdivide a su vez en las siguientes subcaracterísticas (ISO, 2021):
Madurez: capacidad del sistema para satisfacer las necesidades de fiabilidad en condiciones normales.
Disponibilidad: capacidad del sistema o componente de estar operativo y accesible para su uso cuando se requiere.
Tolerancia a fallos: capacidad del sistema o componente para operar según lo previsto en presencia de fallos hardware o software.
Capacidad de recuperación: capacidad del producto software para recuperar los datos directamente afectados y reestablecer el estado deseado del sistema en caso de interrupción o fallo.
La fiabilidad es la capacidad del software para cumplir los requisitos (Neufelder, 2018). Por su parte
(Álvarez , 2019) expresa que la fiabilidad es la probabilidad de que el producto (dispositivos, sistemas y subsistemas) cumplan las funciones para las que fueron diseñadas, bajo especificaciones dadas.
Para (Lucero, y otros, 2020) el concepto más simple de fiabilidad, es aquel que comprueba que el producto cumple ciertas especificaciones, y cuando esto ocurre, es enviado al cliente.
(Gómez, y otros, 2020) en su libro “Aproximación a la Ingeniería del Software” hacen referencia a la fiabilidad como es el grado de ausencia de fallos durante la operación del producto software. Puede estimarse como el número de fallos producidos o el tiempo durante el que permanece inutilizable durante un intervalo de operación dado.
Otros estudios sostienen que la fiabilidad se refiere a la probabilidad de que el software funcione sin fallos durante un periodo de tiempo determinado en un entorno específico (Rowell, y otros, 2018) ; (Hanagal, y otros, 2021).
(Gradinaru, 2020) define la fiabilidad como la probabilidad de que el software se ejecute durante un periodo de tiempo determinado sin que se produzca un fallo, ponderada por el coste para el usuario de cada fallo que se produzca.
Como se muestra en la Tabla 1, son diversos los criterios que se utilizan por los autores para definir la fiabilidad de software, resaltando la importancia de que el software funcione libre de fallos.
Los autores de la presente investigación asumen que, en las definiciones descritas sobre la fiabilidad del software, aparecen tres aspectos esenciales y que deben estar definidos de manera precisa:
1. ¿Qué función debe desempeñar?
2. ¿En qué condiciones debe desempeñar las funciones?
3. ¿Cuánto tiempo debe desempeñar de manera satisfactoria las funciones en esas condiciones?
Concluyen los autores que además de las definiciones anteriores, existen muchas otras, pero todas ellas relacionan un conjunto de características que determinan como elementos fundamentales de la fiabilidad del software la probabilidad de que el software funcione como se espera por el usuario, bajo determinadas condiciones en un periodo de tiempo determinado.
Modelos de estimación de la fiabilidad
Un modelo de crecimiento de la fiabilidad es un modelo numérico de la fiabilidad del software, que predice cómo debería mejorar la fiabilidad del software con el tiempo a medida que se descubren y reparan los errores (JavaTpoint, 2018).
El modelado de la fiabilidad del software ha ido madurando durante los últimos años hasta el punto de que se puede obtener información muy útil a la hora de desarrollar una aplicación informática, mediante la aplicación de un modelo determinado a cada problema. Son muchos los modelos que pueden ser empleados en el análisis de la fiabilidad de una aplicación informática, el principal problema radica en que no se puede encontrar un modelo que funcione bien en cualquier situación. Es tarea de los ingenieros adaptar un método o componer uno nuevo a partir de los ya existentes para conseguir una solución que se amolde al problema en particular que se está tratando (Lucero, y otros, 2020) .
Existen diversos modelos de crecimiento de fiabilidad que han sido derivados de experimentos de fiabilidad en varios dominios de aplicación, a continuación, se presentan una representación:
Modelo Jelinski-Moranda: fue uno de los primeros modelos de crecimiento de la fiabilidad del software. Asume que hay n defectos de software inicialmente al comienzo del procedimiento de prueba y cada uno de ellos es independiente de los demás defectos. Un defecto se elimina con seguridad y no se introducen otros nuevos defectos durante la fase de depuración (Kumar , y otros, 2017).
Tiene como inconveniente que supone que las reparaciones del software se implementan siempre correctamente, sin embargo, en la práctica esto no sucede así ya que al reparar un defecto se pueden introducir uno o varios defectos.
Modelo Schick-Wolverton: se basa en la misma hipótesis que el modelo Jelinski-Moranda, salvo que se supone que la función de riesgo es proporcional al contenido de fallos actual del programa, así como al tiempo de fallo transcurrido desde el último fallo (Hanagal , 2019). Dado que se mantiene la hipótesis de que todos los defectos son similares y por tanto tienen la misma probabilidad de manifestarse, la intensidad de fallos del programa según este modelo simula que durante una primera fase es cuando se detectan un mayor número de defectos, alcanzándose un máximo a partir del cual disminuye el número de fallos que ocurren ya que se ha reducido el número de defectos existentes, como consecuencia de las acciones de corrección.
Este modelo tiene como inconveniente que consideran la independencia entre fallos, que el número de fallos que ocurren es igual al número de defectos que se corrigen, siendo por tanto un número finito, y que todos los defectos tienen igual probabilidad de manifestarse en un momento dado.
Modelo Littlewood-Verall: trata de tener cuenta la incertidumbre de la fiabilidad del sistema tras una acción de corrección de fallos. La idea subyacente es que cada acción de reparación puede llevar al sistema a un estado mejor o peor en comparación con el estado anterior del sistema en funcionamiento (Stefano, y otros, 2018) . Este modelo tiene en cuenta los inconvenientes del modelo propuesto por Jelinski-Moranda introduciendo un elemento aleatorio en la mejora del crecimiento de la fiabilidad conseguida por una reparación del software. Además, modela el hecho que a medida que los defectos son reparados, el promedio de mejora en cuanto a fiabilidad por reparación disminuye.
A continuación, en la Tabla 2 se realiza una comparación de los modelos antes mencionados teniendo en cuenta los criterios de crecimiento de la fiabilidad, corrección de errores y probabilidad de los defectos a partir del comportamiento probabilístico de los diferentes modelos.
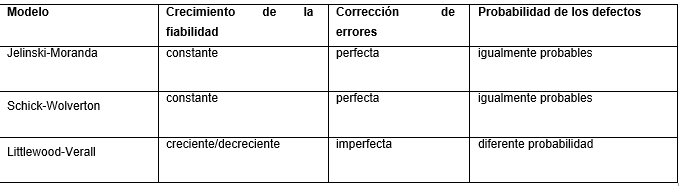
Del análisis de la tabla 2 se puede llegar a la conclusión que los modelos Jelinski-Moranda y Schick-Wolverton consideran que los fallos de un sistema son independientes entre sí, que la intensidad del proceso de fallo es proporcional al número de defectos existentes en el sistema, y que la corrección es perfecta. Cada defecto tiene la misma probabilidad de manifestarse, siendo constante entre fallos, y por tanto también es constante entre fallos la intensidad de fallos del sistema, la cual disminuye cada vez que se produce un fallo en una cantidad constante, ya que se supone que al producirse un fallo siempre se corrige el defecto que lo origina, y además no se cometen nuevos errores. Siendo en el proceso de desarrollo de software poco probable que los sistemas mantengan ese comportamiento. Por lo que se propone emplear el modelo Littlewood-Verall el cual establece que la intensidad de los fallos no decrece de manera constante cada vez que se produce un fallo, sino que considera que la intensidad de fallos es también una variable aleatoria, que depende del número de fallos.
MÉTODOS O METODOLOGÍA COMPUTACIONAL
En esta investigación se emplearon como métodos científicos el analítico sintético, la modelación y el método experimental. El método analítico sintético permitió el análisis y síntesis de la literatura relacionada con la fiabilidad de software y los modelos de estimación de la fiabilidad. La modelación permitió representar la aplicación del modelo de estimación de la fiabilidad. El método experimental se utilizó para desarrollar dos experimentos, uno de tipo preexperimento estudio de casos con una sola medición y el otro de Pre y Post prueba con un solo grupo.
Teniendo en cuenta el análisis de los modelos se decide utilizar en la propuesta de solución para estimar la fiabilidad del software el modelo Littlewood-Verall.
Este modelo intenta tener en cuenta la generación de defectos en el proceso de corrección considerando la posibilidad de que un programa sea menos fiable al corregir un defecto. El mismo introduce una diferencia importante respecto a los modelos descritos anteriormente, los cuales asumen un proceso de depuración de defectos perfecto.
Formalmente, las premisas de este modelo son:
Tiempo de ejecución sucesivo entre fallas; por ejemplo: X 𝑖 , i=1, 2, 3..., son variables aleatorias independientes con funciones de densidad probable.
Donde 𝜆 𝑖 es la tasa de fallo. Se asume que 𝑋 𝑖 es exponencial con 𝜆 𝑖 como parámetro.
se satisface para toda 𝑖. Esto refleja que la intención es construir un programa mejor después de que un defecto sea detectado y corregido. También refleja la realidad de que en ocasiones las correcciones harán que el programa sea peor. Para la función 𝛹 𝑖 , Littlewood and Verrall sugieren que cualquiera de las dos formas: 𝛽 0 +β 0 𝑖 ó 𝛽 0 +β 0 𝑖 2 . Asumiendo a priori una distribución uniforme para 𝛼, los parámetros 𝛽 0 y 𝛽 1 pueden ser encontrados por la estimación de máxima verosimilitud.
3- Durante la prueba, el software se ejecuta bajo condiciones similares a como se prevee que funcione.
El tiempo medio entre la falla 𝑖−1 y la 𝑖ésima falla,𝛩 𝑖 , se expresa:
RESULTADOS Y DISCUSIÓN
Se realizaron dos experimentos en el proyecto teniendo en cuenta las etapas de implementación y despliegue con el objetivo de analizar el futuro comportamiento del sistema ante posibles fallos. Tabla 3
Etapa de Implementación
Experimento 1: Análisis de la tolerancia ante fallos en la etapa de pruebas.
G: Grupo de experimentación compuesto por el proyecto.
X: Análisis de la tolerancia ante fallos en la etapa de pruebas.
O1: Observación del total de fallos detectados en la etapa de pruebas.
G X O1

Utilizando el juego de datos de los fallos detectados en las pruebas funcionales se aplicó el modelo de Littlewood-Verall. Utilizando la herramienta SMERFS3 se obtuvieron los siguientes resultados representados en la Figura 1, en el eje de las abscisas se manifiestan los fallos detectados y en el eje de las ordenadas el tiempo entre fallos.
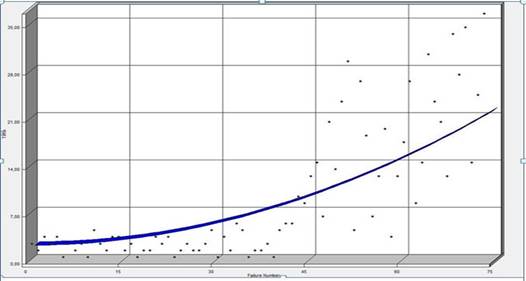
En la Figura 1 mediante una gráfica se obtiene una función creciente como resultado del método Littlewood-Verall, donde se evidencia en su comportamiento que a medida que aumentan los fallos detectados a la vez aumenta el tiempo entre fallos permitiendo de esta manera reflejar el posible comportamiento antes posibles fallos que puedan ocurrir.
Experimento 2. Pre y Post prueba con un solo grupo
G: Grupo de experimentación compuesto por el proyecto.
X: Análisis de la tolerancia ante fallos.
O1: Observación del total de fallos detectados en la etapa de prueba.
O2: Observación del total de fallos detectados en la etapa de despliegue.
G O1 X O2
A continuación, en la Tabla 4 se muestran los fallos detectados en la etapa de despliegue.
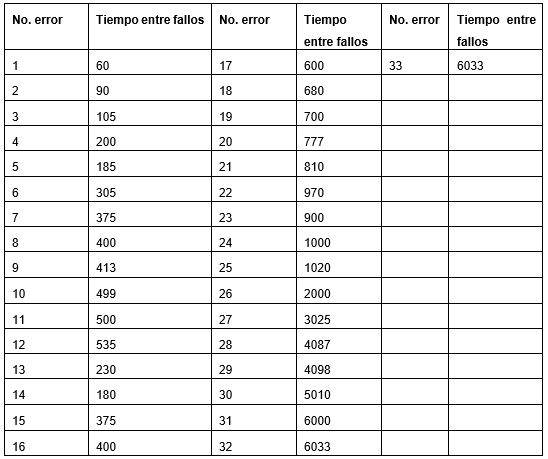
Utilizando el juego de datos de los fallos detectados en la etapa de despliegue se aplicó el modelo de Littlewood-Verall. Utilizando la herramienta SMERFS3 se obtuvieron los siguientes resultados representados en la Figura 2, en el eje de las abscisas se manifiestan los fallos detectados y en el eje de las ordenadas el tiempo entre fallos.
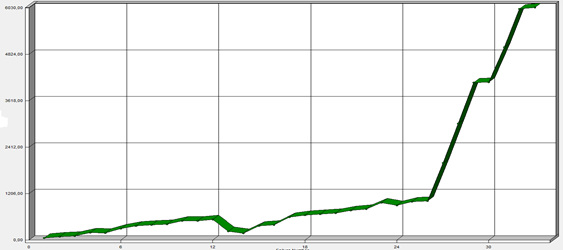
Se puedo observar que los resultados obtenidos en la etapa de despliegue son superiores a los obtenidos en la etapa de implementación cuando se analizan los fallos detectados en ambas etapas, disminuyendo el número de fallos en 41 lo que representa un 55% de los fallos detectados en la etapa de implementación. Se evidencia mediante la gráfica una función con un crecimiento más lento de los fallos detectados con respecto al tiempo entre fallos, correspondiéndose este comportamiento con la observación realizada anteriormente respecto a ambas etapas de implementación y despliegue y así lo demuestran ambas funciones mediante las gráficas.
CONCLUSIONES
Al definir la fiabilidad como una probabilidad lleva implícito que los resultados solo puedan obtenerse de tratamientos estadísticos basados en pruebas y la estimación de dichos resultados tendrá el riesgo asociado al tratamiento estadístico. Por tal motivo, resulta especialmente interesante la cuantificación de dicha fiabilidad, de forma que sea posible hacer estimaciones sobre el comportamiento del software.
La aplicación del modelo Littlewood-Verall en un proyecto real demostró la necesidad en las pruebas de software de recopilar datos precisos del comportamiento del sistema para estimar su comportamiento en la etapa de despliegue. Evidenciando a través de la modelación del comportamiento del software un salto de fiabilidad en la etapa de despliegue comparado con la etapa de implementación. Lo que permitió considerar un mejor desempeño del software en su vida útil.

