










 Custom services
Custom services Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
El transporte aéreo es una infraestructura crítica que realiza cerca de 7 mil millones de embarques de pasajeros al año. Este sistema complejo depende de la correcta interacción entre varios recursos limitados como son el espacio aéreo y del aeropuerto, miles de aeronaves, controladores de tráfico aéreo, entre otras y las condiciones climáticas (Gopalakrishnan y Balakrishnan, 2017).
Si bien el aumento del tránsito aéreo es una señal de desarrollo, el crecimiento descontrolado puede aumentar los riesgos de seguridad operacional (OACI, 2016). Es por ello que la gestión y la predicción del comportamiento del tráfico aéreo es relevante. Dentro de esta rama, varias son las soluciones existentes y diversos los objetivos de las mismas (Pavlyuk, 2019; Tealab, 2018). La mayoría opta por utilizar soluciones empleadas para predecir series de tiempo con el fin de conocer con antelación el comportamiento del tráfico. Para el trabajo con series de datos correlacionadas, es común realizar predicciones usando la Metodología Box-Jenkins (Box et al., 2016). Las redes neuronales artificiales (RNA) han surgido como una excelente alternativa al pronóstico de series de tiempo, debido en gran medida a que son no lineales (Velásquez H. et al., 2013) y llenan los vacíos dejados por los modelos estadísticos (Tealab, 2018).
En (Gopalakrishnan y Balakrishnan, 2017), se compara el rendimiento de diferentes enfoques para predecir retrasos en las redes de tráfico aéreo: el sistema lineal de salto de Markov (MJLS), los árboles de clasificación y regresión (CART), y RNA. En esta investigación se evidencia que el rendimiento de la predicción puede variar significativamente según la elección del modelo, del tipo de predicción, así como de las variables o características de predicción correctas para mejorar el rendimiento de estos algoritmos. Siguiendo esta misma línea, (Monmousseau et al., 2019) logra predecir y analizar los retrasos en el tráfico aéreo. Para lograr su objetivo, se emplean tres regresores de aprendizaje automático diferentes, árbol de decisión (DTR), bosque aleatorio (RFR) y aumento del gradiente (GBR).
Sin embargo, es más difícil predecir series de alta frecuencia debido a sus propiedades de regularidad matemática débil. Para aprovechar las auto-similitudes inherentes dentro de los componentes de alta frecuencia en una RNA; en (Li et al., 2019), estos componentes se dividirán en varios segmentos pequeños continuos, superpuestos. Esta estrategia de reagrupación puede ayudar a mejorar la precisión de la predicción de los componentes de alta frecuencia.
Por otro lado, se pronostica que la demanda del transporte aéreo desde, hacia y dentro de Cuba se duplicará en los próximos 20 años. Sin embargo, para que esto suceda, es esencial fortalecer y modernizar algunos aspectos claves dentro del sector de la aviación del país (IATA, 2019; OACI, 2016). La Empresa Cubana de Navegación Aérea (ECNA) es la responsable de brindar los servicios de navegación, vigilancia y gestión del tráfico aéreo para la FIR HAVANA, que gestiona todo el espacio aéreo del país. En la actualidad, cuando la afluencia de tránsito es extremadamente alta se toman diferentes medidas de último momento, conocidas como medidas de gestión de la afluencia del tránsito aéreo o medidas ATFM. Esto hace cada vez más imperativo poder conocer con antelación el comportamiento del tráfico aéreo en pequeños intervalos de tiempo. Esto permitirá contribuir a la toma de decisiones durante el proceso de control, logrando minimizar los tiempos de gestión y riesgos de accidentes.
Sin embargo, la previsión sobre la demanda de tráfico aéreo es uno de los campos en donde los errores son más frecuentes, debido a que nos encontramos ante situaciones de riesgo e incertidumbre que en la mayoría de las ocasiones no son plenamente controlables (Rochel, 2000) . Por esto, el proceso de selección del modelo predictivo y sus parámetros es tan riguroso. Esta predicción podría contribuir a determinar los sectores y las horas de riesgo, donde la cantidad de vuelos excede el límite de seguridad.
Teniendo esto en cuenta, puede plantearse como objetivo de la siguiente investigación desarrollar un algoritmo para predecir el tráfico aéreo basado en un modelo de redes neuronales, que ofrezca mejores resultados en el menor tiempo posible.
El presente documento se encuentra estructurado de la siguiente forma: una primera sección dedicada a exponer los principales elementos implicados en el desarrollo del estudio: los datos que conforman la serie de tiempo utilizada y la forma en que se fracciona dicha serie. También se presenta el modelo predictivo empleado, así como sus variantes y las métricas de rendimiento utilizadas. A continuación, una segunda sección donde se expone el algoritmo desarrollado. Finalmente se analizan los resultados experimentales obtenidos y se muestran las conclusiones del trabajo.
Métodos o Metodología Computacional
Series de tiempo
La mayoría de los datos del mundo real tienen un componente temporal, ya sean mediciones de procesos naturales, como el clima, ondas sonoras; o artificiales, mercado de valores, robótica (Längkvist et al., 2014). Una serie de tiempo es un conjunto secuencial de observaciones, medidas comúnmente en periodos de tiempos sucesivos equidistantes. Entre sus características diferenciantes está su dependencia estricta del tiempo, la presencia de autocorrelación y la existencia de tendencia en sus observaciones. Estás características hacen que su análisis y modelación sean más complejos.
Datos
Los datos empleados son una colaboración de la ECNA. Entre las fuentes que pudieron brindar información sobre el comportamiento del flujo de tráfico tras procesamiento, se encuentran los planes de vuelo FPL (del inglés Filed Flight Plan) y CPL (del inglés Current Flight Plan). Este tipo de mensajería maneja información útil como la fecha, origen, destino, tipo de aeronave, características de las aeronaves desde el punto de vista técnico, ruta propuesta, entre otras.
Se cuenta con registros de todos los vuelos que circulan por el espacio aéreo cubano desde enero del 2009 hasta diciembre de 2018, donde existen días con más de mil observaciones. Para poder trabajar con todo este volumen, se agrupan la cantidad de vuelos existentes por cada cuarto de hora.
Cuando se trabaja con series de tiempo, se suele dividir los datos en dos partes, el conjunto de entrenamiento y el de prueba. Las observaciones del primero, se utilizan para construir el modelo deseado. A menudo, una pequeña parte de este se conserva con fines de confirmación y se conoce como conjunto de validación; mientras que con el de prueba se analiza que tan efectiva es la solución encontrada (Adhikari y Agrawal, 2013).
Uno de los problemas es llegar a un equilibrio entre el tamaño de cada conjunto. En la práctica, mientras más datos de validación se posean mejor será la estimación del error cometido; y mientras mayor sea la cantidad datos de entrenamiento mejor se adaptará el clasificador al modelo a construir (Rojas Delgado, 2016). Se debe tener en cuenta, que los datos están ordenados cronológicamente y que las últimas mediciones suelen tener una mayor correlación con los datos futuros.
Por tanto, es conveniente seguir la siguiente estructura para particionar los conjuntos: 55-70% para entrenamiento, 10-15% para validación y un 20-30% para prueba. La elección de estos porcentajes se realiza desde la experiencia del investigador.
Modelo predictivo
Aunque en la presente investigación se opta por emplear RNA, es importante señalar que no hay un solo modelo para establecer pronósticos que sea el mejor, cada caso es único. Se deben tener en cuenta otros factores como: una información confiable, adecuadamente caracterizada, normalizada y almacenada. Esta información unida a la experiencia del investigador puede generar buenas estimaciones (Moreno Sarmiento, 2008). Teniendo en cuenta que la selección del modelo influye en gran medida en la calidad del resultado, es importante tener en cuenta las métricas de rendimiento o medición del error (Adhikari y Agrawal, 2013). Es decir, que además de seleccionar correctamente el modelo predictivo, se deben garantizar otros elementos que condicionan el éxito de la predicción.
Métricas de rendimiento en el proceso de predicción
Para poder definir la precisión de un proceso de predicción cualquiera, es necesario establecer una medida del error cometido, que siempre va a existir, pero debe ser el mínimo posible. Muchas son las variantes existentes, dependen de la naturaleza de la clasificación a realizar. La mayoría de las métricas para modelos predictivos, con sutiles diferencias entre ellas, van a centrarse en medir lo cerca (o lejos) que están las predicciones de los valores reales.
En problemas de predicción suelen usarse el error cuadrático medio (MSE), el error absoluto medio (MAE) y el error raíz del error cuadrático medio (RMSE). Por ejemplo (Pavlyuk, 2019) y (Peiris, 2016) los emplean para elegir el mejor modelo porque la precisión es su objetivo principal. Otros son más exigentes, como (Colás Herrera, 2019) que recurre a varias métricas: el error absoluto medio (MAE), el error cuadrático medio (MSE) y el error porcentual absoluto medio (MAPE). Por otro lado, como cada medida de error puede conducir a la evaluación inexacta de los resultados de predicción, es recomendable nunca elegir sólo una. En su lugar, complementar las deficiencias de una con las ventajas de otra (Rodríguez Rivero, 2016).
En el experimento realizado se opta por emplear el RMSE puesto que magnifica los errores grandes, MSE pues usa las mismas unidades que la variable objetivo y hace su comprensión más fácil y el MAE porque presenta el error en la misma escala que los valores reales, sin distinguir entre positivos y negativos.
Redes Neuronales Recurrentes RNN
La RNN es un algoritmo de aprendizaje profundo y un tipo de arquitectura de RNA que se especializa en el procesamiento de datos secuenciales donde el tamaño puede variar. RNN mantiene la memoria interna, por lo que son muy eficientes para problemas de aprendizaje automático que involucran datos secuenciales y series de tiempo (Fernández Salguero, 2021). La principal ventaja de utilizar RNN en lugar de redes neuronales estándar es que comparten sus características. Los pesos se comparten a lo largo del tiempo en RNN, pueden recordar sus entradas anteriores, toma información histórica para su cálculo. En RNN, la función de pérdida se define en función de la pérdida en cada paso de tiempo, es decir, para generar una salida o activación emplean la entrada actual y, además, la activación generada en la iteración previa. Se emplea la retropropagación en el entrenamiento para lograr ajustar los pesos. Para calcular la nueva salida, se le aplica una función de activación, generalmente sigmoide logística o tangente hiperbólica, como se muestra en la Ecuación 2 (Campos-Taberner et al., 2020, Karim et al., 2019):
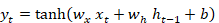 (2)
(2)
Donde  y
y 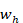 son los pesos de entrada y recurrentes respectivamente,
son los pesos de entrada y recurrentes respectivamente,  es la entrada en el instante t,
es la entrada en el instante t, 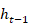 la salida o estado oculto (activación) previo y b es el sesgo.
la salida o estado oculto (activación) previo y b es el sesgo.
Estas redes tienen un problema, a pesar de que en teoría deberían retener información en un tiempo 't' sobre entradas procesadas varios pasos temporales atrás, en la práctica, dichas dependencias a largo plazo resultan imposibles de aprender. (Campos-Taberner et al., 2020) A este problema se lo conoce como desvanecimiento del gradiente. Para solventar esta limitación, se desarrolla una red con mayor selectividad y capacidad de memoria.
Redes Neuronales de memoria de largo y corto plazo LSTM
LSTM es un algoritmo de aprendizaje profundo muy popular para modelos de secuencia y para predicciones de series de tiempo y tareas de clasificación de texto. Siri de Apple y la búsqueda por voz de Google son algunos ejemplos del mundo real que han utilizado el algoritmo LSTM (Fok et al., 2018), que está detrás del éxito de esas aplicaciones. Puede capturar dependencias de largo alcance, tener memoria sobre entradas anteriores durante períodos de tiempo extendidos (Fernández Salguero, 2021).
El objetivo de esta red es darle solución al problema del desvanecimiento del gradiente de las RNN. Para ello utiliza tres puertas en cada una de las celdas LSTM donde controla la propagación del gradiente en la memoria de la red recurrente.
Puerta de entrada: agrega información útil adicional al estado de la celda.
Puerta de olvido: elimina la información que ya no es útil en el estado de la celda.
Puerta de salida: a partir del procesamiento de los resultados de las compuertas de entrada y olvido devuelve el cálculo final de la célula (Cabezón Manchado, 2018).
Este mecanismo de activación de LSTM ha permitido que la red conozca las condiciones para cuándo olvidar, ignorar o mantener información en la celda de memoria. Las tres puertas son unidades sumatorias no lineales que recopilan activaciones desde dentro y fuera del bloque y controlan la activación de la celda a través de multiplicaciones (Graves, 2012). La información en la memoria se actualiza mediante la suma de las salidas de la puerta de entrada y de olvido (Campos-Taberner et al., 2020). Finalmente, el estado oculto saliente 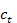 se obtiene mediante la multiplicación de la información proveniente de la puerta de salida y la memoria actualizada a través de una función, generalmente tangente hiperbólica (Campos-Taberner et al., 2020) como se observa en la figura 4.
se obtiene mediante la multiplicación de la información proveniente de la puerta de salida y la memoria actualizada a través de una función, generalmente tangente hiperbólica (Campos-Taberner et al., 2020) como se observa en la figura 4.
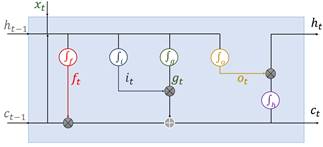
Esta nueva variante de redes recurrentes permite una mejor manipulación de datos correlacionados, almacenando en cada celda los valores que faciliten el entrenamiento. Sin embargo, este proceso puede ser más costoso computacionalmente, debido a que realiza cuatro operaciones en cada celda de la red.
Algoritmo predictivo basado en RNA
En términos de predicción las redes también predicen el valor futuro a partir de valores pasados. Toman 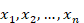 y determinar el valor de
y determinar el valor de 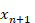 ajustando los pesos de las conexiones hasta que el valor obtenido sea el más parecido al valor real.
ajustando los pesos de las conexiones hasta que el valor obtenido sea el más parecido al valor real.
Como primera opción se propone un modelo simple con una estructura secuencial conformado por una capa de entrada y una capa oculta con 96 neuronas y función de activación tangente hiperbólica puesto que los valores están normalizados entre -1 y 1. Se utilizó como optimizador Adam, como métrica de pérdida, MAE, para calcular el acuracy se empleó MSE y para saber si mejora con el entrenamiento se dispone de 15 épocas. Como segunda opción se opta por una LTSM bastante similar, pero con una capa oculta LSTM. Es por esto que se emplea el mismo algoritmo 1 en ambos modelos.

Del paso 1 al 3 se preparan los datos de entrada, son transformados a los valores con la estructura idónea para el entrenamiento de la red. En los pasos del 4 al 9 se inicializa modelo, agregando las capas necesarias. El modelo se crea en el paso 10 y en el 11 se procede a realizar el ajuste del mismo empleando los datos de entrenamiento. Este es el paso más costoso, donde se entrena el modelo y se ajustan los miles de parámetros presentes en la red. En el paso 12 se predicen los valores de ambos conjuntos. Nótese que estos valores se emplearán en el paso 13 para poder calcular los distintos errores de acuerdo a las métricas seleccionadas. Finalmente, se devuelve un arreglo con los errores calculados.
Resultados y discusión
En esta sección se describe un grupo de pruebas realizadas para seleccionar los mejores parámetros y la red que ofrece los mejores resultados en cuanto a precisión y eficiencia.
Para entrenar las redes se cuenta con registros de todos los vuelos que circulan por el espacio aéreo cubano desde enero del 2009 hasta diciembre de 2018, donde existen días con más de mil observaciones. Para poder trabajar con este volumen se agrupan por cada cuarto de hora, es decir 96 mediciones por cada uno de los 3652 días. El conjunto no cuenta con valores nulos ni atípicos, varían de 0 a 56 vuelos como máximo, para un promedio de 8,16 vuelos por cuarto de hora. Se opta por emplear los valores de 2009 a 2017 para el entrenamiento, validación y optimización de cada red. El resto, los más actuales, se utilizan en las pruebas del modelo final.
Al emplear esta serie en redes neuronales, se normaliza entre -1 y 1, garantizando que todos los valores estén dentro de este rango. Además, se crean vectores de entrada para cada una de las redes implementadas de acuerdo al número de capas iniciales. Las pruebas se realizaron empleando, como primera opción, una RNA perceptrón multicapa con una estructura secuencial conformado por una capa de entrada de tipo Dense y una capa oculta Flatten con 96 neuronas y 1 unidad de salida para un total de 9407 parámetros. Como segunda opción se opta por una LTSM bastante similar, pero con una capa oculta LSTM y un número mayor de parámetros, 96 unidades de entrada en la primera capa input, 96 en la segunda y 96 unidades de salida para obtener un total de 23 136 parámetros.
Para elegir la mejor variante del algoritmo propuesto, se comparan las siguientes variables:
Precisión. La variable es operacionalizada teniendo en cuenta el error del modelo una vez finalizado el proceso de entrenamiento. La variable se encuentra definida por dos dimensiones: error de entrenamiento y error de validación, dados por las métricas mencionadas anteriormente.
Eficiencia. La variable es operacionalizada teniendo en cuenta el tiempo de ejecución en segundos que necesita el algoritmo para ser entrenado.
Tabla 1 Métricas de precisión para el conjunto de entrenamiento y validación.
| MAE | 0.078 | 0.125 | ||
| MSE | 0.010 | 0.027 | ||
| RMSE | 0.099 | 0.165 | ||
Para la evaluación de la precisión del entrenamiento de los distintos modelos se comparan las métricas seleccionadas. En la tabla 1 se observan los resultados experimentales. Se puede observar que los resultados son similares para ambas redes y que los errores en el conjunto de entrenamiento son más bajos. Para la medición del tiempo de ejecución se tiene en cuenta la cantidad de segundos que demora el proceso de entrenamiento. En la tabla 2 se muestran los distintos tiempos para cada entrenamiento. Es importante destacar que este tiempo suele cambiar con cada nueva ejecución, pero se mantienen en el mismo rango de valores. Se puede observar que los valores de cada red difieren en mayor grado.
Luego de comparar ambas redes, se opta por emplear para realizar el pronóstico futuro, el RNA, debido a que posee una buena precisión y el mejor tiempo. Para esta elección se le dio relevancia a la precisión en el conjunto de validación y al tiempo de ejecución, puesto que es el elemento que presenta una mayor diferencia.
En la figura 5 se muestran las gráficas del comportamiento de a) el error MSE y b) la función de pérdida en el conjunto de entrenamiento y de validación durante las 15 épocas de entrenamiento de la RNA. En ella se observa que la línea roja presenta un ligero descenso constante después de la primera época de entrenamiento, no ocurriendo así en la línea azul. La línea roja representa el comportamiento de los valores MSE y LOSS en el conjunto de entrenamiento y la azul, en el conjunto de validación.
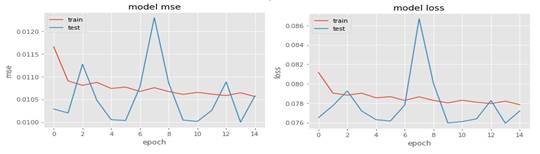
Para comprobar el comportamiento del algoritmo, se procede a predecir los valores para el último año disponible. En la tabla 3 se observan los valores de las distintas métricas de desempeño empleadas para el entrenamiento. Los valores de precisión son un poco mayores que los de los conjuntos de entrenamiento y validación, lo que refleja un buen funcionamiento de la red. Mientras que el tiempo es mucho mejor pues la red esta entrenada y solo debe predecir los valores futuros.
Tabla 3 Métricas de desempeño par la RNA en el conjunto de prueba.
| Métricas | MAE | MSE | RMSE | Tiempo |
|---|---|---|---|---|
| RNA | 0.085 | 0.013 | 0.115 | 46.052 |
En la figura 6 se observa la predicción de los primeros 20 días del año 2017. Se puede observar el comportamiento similar entre ambas gráficas.

Conclusiones
Las series temporales son una estructura de datos que requiere un tratamiento diferente, su dependencia del tiempo y su comportamiento estacionarios, dificultan el proceso predictivo, sobre todo en modelos lineales. Los valores de métricas de rendimiento y tiempo de ejecución suelen ser inversamente proporcionales. Los algoritmos predictivos basados en RNA, permiten realizar los entrenamientos con precisión, aunque pueden tener un tiempo de ejecución mayor. El análisis de las métricas de precisión y tiempo de ejecución, de cada algoritmo, permitió comprobar que el basado en RNA presenta los mejores resultados, por tanto, será el utilizado en la propuesta de solución para la predicción de la afluencia de tránsito aéreo.
A pesar de haber obtenido buenos resultados con las redes neuronales, es pertinente continuar el estudio y análisis de otros modelos como los de regresión, los ARIMA y las Máquinas de Soporte Vectorial (SVM). Las redes son muy versátiles y muchas son las posibilidades que existen para poder emplearlas de conjunto con otros modelos, maximizando sus ventajas. Motivo por el cual, este estudio puede aumentar las opciones y contribuir a mejorar los resultados.

