










 Custom services
Custom services Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
Los radares son dispositivos dedicados comúnmente a la detección y rastreo de objetivos próximos en ambientes terrestres, marítimos y aéreos (William and James, 2014). En su forma básica, un sistema de radar consta de cinco elementos: un transmisor de radio; un receptor de radio sintonizado con la frecuencia del transmisor; dos antenas; y una pantalla, como muestra la Figura 1.
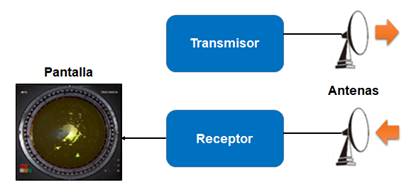
Para detectar la presencia de un objeto (objetivo), el transmisor genera ondas de radio, las cuales son irradiadas por una de las antenas en forma de haz colimado o enfocado. El receptor, mientras tanto, escucha los ecos de estas ondas de radio, que son captadas por la otra antena. Si se detecta un objetivo, en la pantalla aparece un indicador luminoso que indica su ubicación (George et al., 2014). El PPI es una pantalla en la que los ecos del objetivo se muestran en la posición del plano, con la distancia radial desde el centro que representa el rango y con el ángulo del vector de radio que representa el ángulo de acimut (IEEE, 2017).
Existen diversos tipos de radares, y entre los más comunes se encuentran los de búsqueda y los de seguimiento. Los primeros son utilizados principalmente para la detección inicial de objetivos en un volumen de interés particular, mientras que los segundos tienen como función principal el seguimiento automático de objetivos (IEEE, 2017). Una de las características que marcan las diferencias entre los diferentes tipos de radares, es el período de actualización de la información; por ejemplo, los radares de búsqueda lo realizan en el orden de los segundos, mientras que los radares de seguimiento lo hacen en décimas de milisegundos (George et al., 2014).
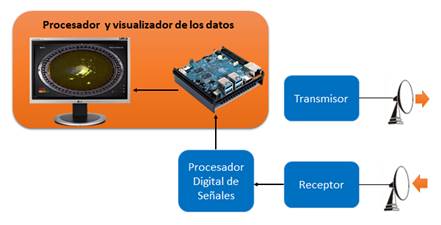
En la actualidad los radares modernos emplean la conversión de la señal analógica en digital (George et al., 2014). Para la modernización de los radares analógicos se le añaden otros elementos a los ya observados en la Figura 1, entre los que se encuentran: Procesador Digital de Señales, Procesador de Datos y Visualizador.
El Procesador Digital de Señales se encarga de procesar los ecos de los blancos y de las señales de interferencias recibidas del receptor, con el objetivo de incrementar el nivel de señal y suprimir las interferencias, mientras que el procesador de datos tiene dentro de sus funciones almacenar y procesar los datos con la localización de los blancos detectados para su posterior representación en el visualizador digital.
El procesamiento de los datos y la representación en pantalla digital de la información en los sistemas de radar han sido abordados por disímiles autores en el transcurso de los años, cuyas propuestas se cometan a continuación.
En las propuestas analizadas en (Manasa and Hemalatha, 2015, Kavyashree et al., 2017, Pezhgorski and Lazarova, 2017, Ravindra et al., 2017, Miao et al., 2018, Saputera et al., 2019), no se documenta el algoritmo usado para el procesamiento y representación de los datos. Estas propuestas no presentan un estudio experimental que permita analizar el comportamiento en el uso de los recursos de cómputo en el dispositivo con respecto a los volúmenes de datos procesados. No se especifican las exigencias de tiempo de actualización de la información de los radares a los cuales va dirigida la solución. Además, se evidencia esencialmente el empleo de la programación secuencial en dichas literaturas.
En las soluciones propuestas en (Manasa and Hemalatha, 2015, Kavyashree et al., 2017, Ravindra et al., 2017, Miao et al., 2018) hicieron uso del lenguaje de programación de alto nivel C++, mientras que en (Pezhgorski and Lazarova, 2017, Saputera et al., 2019) se emplea en lenguaje de nivel medio C, por el rendimiento que ofrecen dichos lenguajes con respecto a otros de alto nivel. Se empleó IDE Qt Creator en (Manasa and Hemalatha, 2015, Kavyashree et al., 2017, Ravindra et al., 2017, Saputera et al., 2019), lo que posibilitó obtener un programa que puede ser ejecutado en diferentes sistemas operativos y plataformas de hardware. Para la visualización de la información del radar en pantalla se aprovecharon las potencialidades que brinda la clase QPainter (QtCompanyLtd., 2021a) y QCustomplot (Eichhammer, 2021) pertenecientes al IDE Qt Creator (Ravindra et al., 2017), mientras que los autores de (Pezhgorski and Lazarova, 2017, Miao et al., 2018) utilizaron para el procesamiento de imágenes la Interfaz de Programación de Aplicaciones (API) OpenGL (Open Graphics Library) (Hearn et al., 2004).
En (Pezhgorski and Lazarova, 2017) utilizaron el principio de programación paralela para garantizar una aceleración basada en la Unidad de Procesamiento Gráfico (GPU, siglas en inglés), lo que permitió la adquisición y conversión en tiempo real de datos de un radar de alta resolución. Los autores en (Manasa and Hemalatha, 2015, Pezhgorski and Lazarova, 2017, Ravindra et al., 2017, Miao et al., 2018, Saputera et al., 2019) usaron como plataforma de hardware computadoras de propósito general, mientras que en (), además de éstas, se utilizó un Procesador Digital de Señal (DSP, siglas en inglés). Para la comunicación, los autores de (Manasa and Hemalatha, 2015, Kavyashree et al., 2017, Ravindra et al., 2017) emplearon la interfaz Ethernet mediante el Protocolo de Datagrama de Usuario (UDP, siglas en inglés) para el envío y recepción de los datos en tiempo real.
En la actualidad, una parte de los radares de seguimiento en Cuba se sustentan con bloques de procesamiento completamente analógicos y realizan la visualización en monitores de Tubos de Rayos Católicos (TRC). Dichos componentes analógicos son altos consumidores de energía, ocupan gran espacio, generan mucho calor, además de la obsolescencia de las piezas de repuesto e incapacidad de adquirir las mismas en el mercado. Adicionalmente, están sometidos a largos períodos de mantenimiento al presentar inestabilidad durante su funcionamiento.
A partir de la situación planteada, surge la necesidad de desarrollar una solución dirigida a los radares de seguimiento analógicos, que permita el procesamiento y representación de los datos en una pantalla digital, que cumpla con el tiempo máximo de actualización de la información de 40 milisegundos y supere las cualidades del radar analógico. La principal contribución de este trabajo es el desarrollo de un algoritmo para procesamiento y representación de los datos de un radar de seguimiento, que cumple con las exigencias de tiempo empleando la placa Odroid-N2, y supera las cualidades del radar analógico en cuanto a: bajo costo, alto rendimiento, bajo consumo de potencia y fácil implementación.
Métodos o Metodología Computacional
Para desarrollar el algoritmo de procesamiento y visualización de los datos, es necesario tener en cuenta varios elementos tecnológicos, entre los que se encuentran los recursos de hardware tales como: computadoras convencionales, FPGA (Field Programmable Gate Arrays, en lengua inglesa), DSP (Digital Signal Processor, en lengua inglesa), Computadoras de Placa Reducida (SBC, siglas en inglés), entre otras opciones de hardware (Manasa and Hemalatha, 2015, Kavyashree et al., 2017, Pezhgorski and Lazarova, 2017, Ravindra et al., 2017, Miao et al., 2018, Saputera et al., 2019).
Los SBC son computadoras construidas en una sola placa de circuito, con microprocesador(es), memoria, periféricos de entrada / salida (E / S) y otras características requeridas de una computadora funcional. Presentan una amplia gama de características que satisfacen los requisitos planteados por las aplicaciones modernas (Sagkriotis et al., 2019). Estos dispositivos son lo suficientemente potentes para ejecutar sistemas operativos convencionales (Johnston et al., 2018). Su uso ha aumentado de forma vertiginosa en los últimos años debido principalmente a su bajo costo, alto rendimiento, bajo consumo de potencia y fácil implementación (Wazir et al., 2020).
Para la selección de la herramienta de hardware a emplear, se le realizaron pruebas de rendimiento a los SBC con los que se contaba, dígase Odroid-N2 (), Jetson Nano () y Raspberry Pi 4 Modelo B (). Las pruebas de rendimiento o benchmarking fueron de gran importancia para comparar los dispositivos, lo que permitió observar la respuesta de estos ante distintas cargas de trabajo. Atendiendo a que el procesamiento y representación de los datos de un radar son operaciones computacionalmente muy exigentes, las pruebas se enfocaron principalmente en la unidad central de procesamiento mediante la herramienta Sysbench (Kopytov, 2012).
Las pruebas de rendimiento a la unidad central de procesamiento de las computadoras de placa reducida, consistió en realizar los chequeos de primalidad para 14000 números primos con uno y cuatro subprocesos de trabajo, respectivamente.
Del análisis de los resultados de las pruebas del CPU se llegó a la conclusión de que tanto el Jetson Nano como el Odroid-N2 tuvieron un mejor rendimiento con respecto a la Raspberry Pi 4. Dado que el Jetson Nano y el Odroid-N2 no se distinguen notablemente en sus desempeños en tiempo de ejecución, se seleccionó este último que es el de menor precio, teniendo en cuenta un escenario en que fuera necesario fabricar varios prototipos.
Diseño de la solución
En la Figura 2 se muestra el diseño estructural de la solución propuesta, donde se muestra enmarcado en color naranja el bloque funcional desarrollado, conformado por el Odroid-N2 para el procesamiento de los datos y su posterior representación en la pantalla digital PPI, cumpliendo con las exigencias de tiempo de 40 milisegundos impuestas por el radar en cuestión.
El algoritmo secuencial propuesto para el procesamiento en el Odroid-N2 y la visualización de los datos en la pantalla digital, consta de un proceso dividido en tres etapas: recepción de los datos, procesamiento y representación en la pantalla PPI.
Implementación de la solución
Para la implementación de la solución se instaló el Sistema Operativo Ubuntu 18.04 en el Odrioid-N2. El software fue desarrollado en el IDE Qt Creator y en el lenguaje de programación C++. De dicho IDE se utilizaron algunas clases propias, entre las que se encuentran: QPainter para el dibujo en Interfaces Gráficas de Usuario (GUI), QUDPSocket para recibir los datagramas mediante el protocolo UDP del módulo de procesamiento digital y la clase QThread para la gestión de los hilos dentro del programa. En el caso del lenguaje C++ se tuvo en cuenta para su empleo su alto rendimiento y compatibilidad con la API OpenMP (Open MultiProcessing, en lengua inglesa), lo que permitió añadir concurrencia al algoritmo, mediante la programación multiproceso de la memoria compartida en la plataforma de hardware seleccionada.
Recepción de los datos
La recepción de los datos provenientes del bloque funcional Procesador Digital de Señales se realizó a través del adaptador gigabit Ethernet del Odroid-N2 empleando el protocolo de comunicación UDP. Para esto se utilizó la clase QUdpSocket del IDE Qt Creator que permite enviar y recibir datagramas UDP (QtCompanyLtd., 2021b). Se reciben de dicho bloque funcional digital 13320 bytes cada 500 microsegundos (μs) durante 36 milisegundos, siendo este último el tiempo de duración de la exploración de la antena del sistema de radar en cuestión.
Procesamiento de los datos
Para el procesamiento de los datos recibidos se tuvo en cuenta la resolución de pantalla a utilizar en la representación en el indicador, siendo en esta solución de 1920x1080 px que es la máxima resolución del monitor empleado. A partir de lo antes planteado, se realizó la selección del radio de la pantalla PPI tomando como diámetro el valor 1080 de los pixeles verticales, arrojando como resultado que el radio para la resolución propuesta puede tener un valor máximo de 540 px. Teniendo en consideración lo mencionado anteriormente y atendiendo a que además de la circunferencia de la pantalla PPI se visualizarán otras informaciones del radar, se seleccionó un radio de 444 px.
Como la cantidad de muestras a procesar cada 500 ms es mayor que el radio de la pantalla, se tuvieron en cuenta varios métodos para realizar la integración de las muestras y determinar el valor de cada pixel. En este caso como la cantidad de muestras es de 13320 y el radio es de 444 px, el valor de intensidad de cada pixel es el resultado de la integración de 30 muestras. Para dicha integración se analizaron tres métodos: promedio, valor máximo y valor máximo de promedios (Trujillo et al., 2020, Guevara Trujillo et al., 2021). El primero consiste en tomar el valor máximo de las 30 muestras; en el segundo el promedio de todas las muestras y en el tercero se dividen las 30 muestras que representan un píxel, en seis subgrupos de 5 muestras promediados de manera independiente. Luego se escoge el mayor de esos seis valores de promedios, el cual sería el valor de intensidad del píxel. Para asignar el valor 5 a la cantidad de muestras por subgrupo en el método máximo de promedios, se tuvo en cuenta la cantidad de muestras por pulso (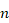 ) que compone un objetivo, sea
) que compone un objetivo, sea 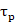 el ancho del pulso del radar de 200 nanosegundos,
el ancho del pulso del radar de 200 nanosegundos, 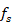 la frecuencia de muestreo de 25 MHz y
la frecuencia de muestreo de 25 MHz y 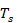 el período de muestreo. Se define
el período de muestreo. Se define  según (1) y según (2), obteniéndose como resultados:
según (1) y según (2), obteniéndose como resultados: 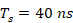 y
y 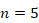 .
.
 (1)
(1)
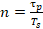 (2)
(2)
Para la selección del método empleado en la integración de las muestras por pixel se realizaron simulaciones en la herramienta LabView (Bitter et al., 2017), con el objetivo de observar el comportamiento del nivel de ruido y del blanco en cada uno de los métodos. En los resultados de la simulación, se observó que el método de promedio tiene como ventaja que disminuye la influencia de los picos de ruido, pero tiene como desventaja que disminuye el nivel del blanco. El método valor máximo tiene como aspecto positivo que mejora el nivel del blanco, pero pueden existir picos de ruido que pueden confundirse con un blanco. El método valor máximo de promedio, a pesar de que los valores no llegan a los extremos de los métodos anteriores, tiene como ventaja que disminuye la influencia de los picos de ruido y por ende se observa mejor el blanco. Atendiendo a lo antes mencionado se seleccionó este último para la integración de las muestras por pixel, generando como resultado 444 bytes que son representados en los 444 px de radio de la pantalla PPI que equivalen a una distancia de 40 km.
Representación en pantalla PPI
Para la representación gráfica en la pantalla PPI se empleó la clase QPainter del IDE Qt Creator proporcionando funciones altamente optimizadas para realizar programas con GUI de dibujo (QtCompanyLtd., 2021a). Como se cuenta con el acimut (θ) y la distancia (ρ) de las muestras en la dirección donde se encuentra explorando la antena del radar, para la representación se realiza la conversión tradicional de coordenadas polares a cartesianas según 3 y 4.
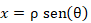 (3)
(3)
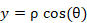 (4)
(4)
Los pares ordenados (x,y) representan coordenadas, que en conjunto con las intensidades que se generaron en el procesamiento de los datos son introducidas como parámetros en las funciones de graficado de la clase QPainter.
Con la culminación de la representación de la información en pantalla se le realizaron pruebas de rendimiento al software para verificar su correcto funcionamiento y así observar los tiempos de respuesta en la placa Odroid-N2. Los resultados de las pruebas antes mencionadas arrojaron que al ejecutar de forma secuencial las etapas de recepción, procesamiento y visualización de los datos, la aplicación tuvo una demora en tiempo de 54 milisegundos, por lo que no cumplió con la exigencia de tiempo de actualización de la información de 40 milisegundos.
Mejora del rendimiento del algoritmo
Al no cumplir el software secuencial con la exigencia de tiempo planteada, se procedió a identificar los puntos del programa de mayor consumo de tiempo mediante la herramienta de creación de perfiles Gprof (Fenlason and Stallman, 1988, Suau et al., 2021). Del perfil estadístico generado por la herramienta Gprof se concluyó que las funciones que tienen un mayor consumo de tiempo en el programa son: la que se encarga de la recepción de datos, que representó un 52% del tiempo total, seguido de la función de procesamiento de los datos con un 18% y la de representación en la pantalla PPI un 12%.
Paralelización del algoritmo secuencial
Todas las computadoras modernas admiten el paralelismo en el hardware a través de al menos una función paralela, incluidas instrucciones vectoriales, núcleos multiproceso, núcleos de múltiples procesadores, procesadores múltiples, motores gráficos y coprocesadores paralelos (McCool et al., 2012). Una manera de diseñar e implementar de manera eficiente los algoritmos paralelos es a través del uso de patrones de computación paralela y distribuida (McCool et al., 2012). Dichos patrones son construcciones abstractas no sujetos a arquitecturas, lenguajes de programación o sistemas (McCool et al., 2012).
De los patrones estudiados se seleccionó el patrón Segmentación del Cauce. Este consiste en una cadena de procesos conectados de forma tal que la salida de cada elemento en la cadena es la entrada del próximo. Los datos son adquiridos de forma segmentada. Estos pasan por todas las etapas desde la primera hasta la última. Cada etapa realiza una transformación de los datos. Más de una etapa puede estar activa al mismo tiempo, por lo que puede ocurrir paralelismo de tareas (McCool et al., 2012).
Para la implementación del patrón Segmentación del Cauce se utilizó la API OpenMP (Open MultiProcessing). Esta API ha sido ampliamente adoptada por la comunidad científica informática (Castillo Reyes et al., 2016). Como se observó con anterioridad, el algoritmo secuencial cuenta con tres etapas, de las cuales se conoce que la recepción es la que tiene un mayor consumo de tiempo en la ejecución, seguido del procesamiento y la representación de los datos, con un 52%, 18% y 12%, respectivamente. Teniendo en cuenta lo antes expuesto se paralelizó el código mediante el patrón Segmentación del Cauce, dividiendo el algoritmo en dos etapas, dígase recepción en la primera, mientras que procesamiento y representación en la segunda etapa. El paralelismo que se logra cuando se pone en práctica este patrón se muestra en la Figura 3 donde través del análisis de la figura se podría manejar la hipótesis que el algoritmo paralelo permitirá disminuir los tiempos de ejecución con respecto a su variante secuencial.
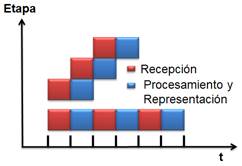
La paralelización del algoritmo secuencial consistió primeramente en lograr la recepción de los datos en la primera etapa del patrón Segmentación del Cauce, siendo esta la de mayor consumo de tiempo, y en paralelo que se ejecute la segunda etapa formada por el procesamiento y la representación de los datos en la pantalla PPI. Se decidió implementar dicho patrón en sólo dos etapas, atendiendo a que la velocidad de este se verá limitada por el tiempo que demore la ejecución de la etapa más lenta del algoritmo, siendo la de recepción la que demora y condiciona al resto, por lo que, al ejecutar el procesamiento y la representación secuencial en la segunda etapa, que suman un 30% del consumo total del tiempo, no superan el tiempo de la etapa de recepción que es de un 52%.
Resultados y discusión
Se realizó un experimento bajo el principio de repetición para minimizar el error experimental, donde se hicieron 10 ejecuciones a la versión secuencial y paralela, con el objetivo de comprobar si se lograron disminuir los tiempos de ejecución del mismo. Se ejecutaron bajo un escenario de experimentación con las mismas condiciones, dígase SBC Odroid-N2, con Sistema Operativo Ubuntu 18.4, memoria RAM DDR4 de 2 GB, memoria de almacenamiento eMMC de 32 GB e igual señal patrón a procesar y representar en pantalla. Como resultado del experimento se obtuvo que el valor promedio para las 10 ejecuciones de la versión secuencial y paralela fue de 54.97 y 24.3 respectivamente.
El desempeño mostrado por un programa puede tener distintas medidas de evaluación. La medida más común y que resulta más importante dependiendo del fin que tenga el programa, es el tiempo de ejecución, cuanto menos tiempo requiera para ejecutarse, mejor será el rendimiento. Además del tiempo de ejecución como medida de rendimiento, también existen otras métricas como la aceleración (Speed Up) y la eficiencia, las cuales se definen a continuación.
La aceleración se define como la relación que existe entre el tiempo de ejecución de un algoritmo empleando un solo procesador y su tiempo de ejecución empleando varios procesadores. Es una métrica que determina cuán rápido es un programa paralelo en comparación con su variante secuencial. Matemáticamente se define como se muestra en la ecuación (5):
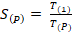 (5)
(5)
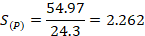
Donde:
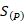 : Aceleración utilizando P procesadores.
: Aceleración utilizando P procesadores.
: Tiempo requerido por el sistema con un procesador para resolver el problema en cuestión.
: Tiempo requerido por el sistema con P procesadores para resolver el problema en cuestión.
La eficiencia es definida como la fracción del tiempo que el procesador consume haciendo trabajo útil. Esta muestra cuán bien se ha utilizado los procesadores en la solución de un problema. La fórmula para calcularla se define en (6):
 (6)
(6)
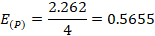
Donde:
: Eficiencia.
: Aceleración utilizando P procesadores.
La aceleración obtenida en los experimentos significa que la variante paralela es 2.262 veces más rápida que la variante secuencial, obteniéndose una mejora de aproximadamente un 55.79 %. La eficiencia obtenida es de 0.5655 lo que implica que se aprovecha un 56.55 % los recursos del procesador.
Conclusiones
El algoritmo paralelo propuesto en este trabajo garantiza el procesamiento y la representación de la información de un radar de seguimiento en el tiempo establecido. Los experimentos realizados demostraron que la solución propuesta en su variante paralela, disminuye los tiempos de ejecución del mismo y se ejecuta en el tiempo esperado atendiendo al periodo de actualización de la información del radar. El diseño de la solución teniendo en cuenta los principios de programación paralela empleando el patrón Segmentación de cauce con la API OpenMP, propició una mejora de aproximadamente un 55.79 % y un aprovechamiento de un 56.55 % de los recursos de cómputo del Odroid-N2, con respecto al algoritmo secuencial. Dicho diseño paralelo en conjunto con la Computadora de Placa Reducida antes mencionada propició obtener una solución de bajo costo, alto rendimiento, bajo consumo de potencia y fácil implementación.

